Verbs in the Written English of Chinese Learners
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Booxter Export Page 1
Cover Title Authors Edition Volume Genre Format ISBN Keywords The Museum of Found Mirjam, LINSCHOOTEN Exhibition Soft cover 9780968546819 Objects: Toronto (ed.), Sameer, FAROOQ Catalogue (Maharaja and - ) (ed.), Haema, SIVANESAN (Da bao)(Takeout) Anik, GLAUDE (ed.), Meg, Exhibition Soft cover 9780973589689 Chinese, TAYLOR (ed.), Ruth, Catalogue Canadian art, GASKILL (ed.), Jing Yuan, multimedia, 21st HUANG (trans.), Xiao, century, Ontario, OUYANG (trans.), Mark, Markham TIMMINGS Piercing Brightness Shezad, DAWOOD. (ill.), Exhibition Hard 9783863351465 film Gerrie, van NOORD. (ed.), Catalogue cover Malenie, POCOCK (ed.), Abake 52nd International Art Ming-Liang, TSAI (ill.), Exhibition Soft cover film, mixed Exhibition - La Biennale Huang-Chen, TANG (ill.), Catalogue media, print, di Venezia - Atopia Kuo Min, LEE (ill.), Shih performance art Chieh, HUANG (ill.), VIVA (ill.), Hongjohn, LIN (ed.) Passage Osvaldo, YERO (ill.), Exhibition Soft cover 9780978241995 Sculpture, mixed Charo, NEVILLE (ed.), Catalogue media, ceramic, Scott, WATSON (ed.) Installaion China International Arata, ISOZAKI (ill.), Exhibition Soft cover architecture, Practical Exhibition of Jiakun, LIU (ill.), Jiang, XU Catalogue design, China Architecture (ill.), Xiaoshan, LI (ill.), Steven, HOLL (ill.), Kai, ZHOU (ill.), Mathias, KLOTZ (ill.), Qingyun, MA (ill.), Hrvoje, NJIRIC (ill.), Kazuyo, SEJIMA (ill.), Ryue, NISHIZAWA (ill.), David, ADJAYE (ill.), Ettore, SOTTSASS (ill.), Lei, ZHANG (ill.), Luis M. MANSILLA (ill.), Sean, GODSELL (ill.), Gabor, BACHMAN (ill.), Yung -

Introduction
Introduction Thefocusofthe present thesis isthe passivevoice,perceivedfromasemantico- syntactic pointofview.Myprimaryaimistoexplore theuseandfunctionsofthe passivevoiceinEnglish,examiningthereasons whichmotivateanauthortopreferthe passiveformtotheactiveone.Secondaryinterestisdevotedtothefunctionandtheuse ofthe passivevoice inCzech.AsresearchmaterialIhavechosentheshortstories by theAmericanwriterO.HenryandtheirCzechtranslations byStanislavKlíma.The reasonswhyIhavechosenthegenreofashortstoryare that itisnotedfortheunityof time,placeandaction.I believethat duetothisfact,theresultsof myresearchwillgive higherevidenceoftheuseofthe passivevoicesincethe basis forcomparisonisunified andcompactcontraryto,forexample,anovel.Forthesamereasonofevidence,I explore just thetranslationsofonetranslator,sinceeveryone hashis/her personal style anddifferentwayofthinkingandunderstandingoforiginal text. Iaminterestedinthe issueofinformationpackaging,especiallyinthedifferent waysofexpressingone andthesamerealityinthetwolanguages:when bothactive and passiveversionsareformallypermitted,whatfactorsfavour thechoiceofoneover other?The passivevoice isa phenomenonwhichisinvolvedbothinEnglishandin Czechbutinunlikeextent.Asfaras Iknow,the passivevoiceisafavouritemeansof expressioninEnglishwhereas inCzechitsusageisnotsopopular.Inviewofthisfact,I supposethattheresults willworkthisway. Thethesisisdividedintotwomainpartswhichareinterlinked,andcomplement eachother.Thefirst partdealswiththetheoreticalknowledgeaboutthe passivevoicein EnglishaswellasinCzech,whereas inthesecondpartI -

Difficulties in Learning and Producing Passive Voice
International Conference on Linguistics, Literature and Culture Difficulties in Learning and Producing Passive Voice Fitnete Martinaj Faculty of Foreign Languages, AAB College Prishtina Abstract This study examines how learners learning English produce and judge English passive voice structures. The ultimate goal of this study is to contribute to an understanding of the extent, nature and sources of learners' persistent difficulties with some syntactic properties of the language they are acquiring. It is to examine whether word order errors in the production of English passive voice by L2 learners stem from lack of knowledge or from difficulties with automatic implementation of L2 procedures. To examine whether errors in the production of English passive voice by L2 learners (in our case, English) can be attributed to transfer of L1 (in our case, Albanian) properties and vice versa, Albanian and English patterns are compared. Taken together, the facts indicate that difficulties with English passive voice structures are a consistent phenomenon in L2 acquisition, and do not follow in a direct way from properties of the L1. Furthermore, the facts show that learners' errors are associated with some syntactic configurations, suggesting that L2 learners divert similar grammatical hypotheses and make use of similar mechanisms for language acquisition. Keywords: transfer, compare, similarities, interference Introduction The English passive is an English language structure that is used in many reading passages, particularly in academic and scientific texts, when it is not necessary to be mentioned the responsibility of the doer. Therefore, it is obvious that English passive is included in English instruction in most education levels. During my teaching experiences, I have found that a large number of Albanian EFL learners, at university level, cannot use the English passive correctly, although they have been taught this structure since secondary schools. -

Recent Publications in Music 2009
Fontes Artis Musicae, Vol. 56/4 (2009) RECENT PUBLICATIONS IN MUSIC R1 RECENT PUBLICATIONS IN MUSIC 2009 On behalf of the International Association of Music Libraries Archives and Documentation Centres / Pour le compte l'Association Internationale des Bibliothèques, Archives et Centres de Documentation Musicaux / Im Auftrag der Die Internationale Vereinigung der Musikbibliotheken, Musikarchive und Musikdokumentationszentren This list contains citations to literature about music in print and other media, emphasizing reference materials and works of research interest that appeared in 2008. Reporters who contribute regularly provide citations mainly or only from the year preceding the year this list is published in the IAML journal Fontes Artis Musicae. However, reporters may also submit retrospective lists cumulating publications from up to the previous five years. In the hope that geographic coverage of this list can be expanded, the compiler welcomes inquiries from bibliographers in countries not presently represented. Compiled and edited by Geraldine E. Ostrove Reporters: Austria: Thomas Leibnitz Canada: Marlene Wehrle China, Hong Kong, Taiwan: Katie Lai Croatia: Zdravko Blaţeković Czech Republic: Pavel Kordík Estonia: Katre Rissalu Finland: Ulla Ikaheimo, Tuomas Tyyri France: Cécile Reynaud Germany: Wolfgang Ritschel Ghana: Santie De Jongh Greece: Alexandros Charkiolakis Hungary: Szepesi Zsuzsanna Iceland: Bryndis Vilbergsdóttir Ireland: Roy Stanley Italy: Federica Biancheri Japan: Sekine Toshiko Namibia: Santie De Jongh The Netherlands: Joost van Gemert New Zealand: Marilyn Portman Russia: Lyudmila Dedyukina South Africa: Santie De Jongh Spain: José Ignacio Cano, Maria José González Ribot Sweden Turkey: Paul Alister Whitehead, Senem Acar United States: Karen Little, Liza Vick. With thanks for assistance with translations and transcriptions to Kersti Blumenthal, D. -

Sydney Go Journal Issue Date – February 2007
Author – David Mitchell on behalf of The Sydney Go Club Sydney Go Journal Issue Date – February 2007 Dr. Geoffrey Gray’s antique Go Ban (picture courtesy of Dr Gray) Up coming events Queensland Go Championship Saturday 17th and Sunday 18th February in Brisbane. Venue: Brisbane Bridge Centre Registration and other details on page 33 For the latest details visit www.uq.net.au/~zzjhardy/brisgo.html Contributions, comments and suggestions for the SGJ to: [email protected] Special thanks to Devon Bailey and Geoffrey Gray for proof reading this edition and correcting my mistakes. © Copyright 2007 – David Mitchell Page 1 February 2007 Author – David Mitchell on behalf of The Sydney Go Club Sydney Lightning Tournament report 3 Changqi Cup 4 3rd Changqi Cup – 1st Qualifier 6 3rd Changqi Cup – 2nd Qualifier 10 Problems 14 Handicap Strategy 15 Four Corners 29 Two page Joseki lesson 35 Answers 37 Korean Go Terms 39 The Sydney Go Club Meets Friday nights at :- At Philas House 17 Brisbane St Surry Hills From 5.00pm Entrance fee - $5 per head; Concession $3; Children free - includes tea and coffee. For further information from Robert [email protected] © Copyright 2007 – David Mitchell Page 2 February 2007 Lightning Tournament The lightning tournament was held on the January 12th and a good time was had by all, thanks to Robert Vadas organising skills. The final was between Max Latey and David Mitchell, the latter managing another lucky win. The following pictures tell the story David Mitchell (foreground); Max more eloquently than words. Latey (background); the two finalists Robert giving some sage advice. -
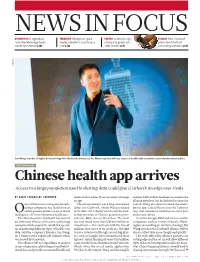
Chinese Health App Arrives Access to a Large Population Used to Sharing Data Could Give Icarbonx an Edge Over Rivals
NEWS IN FOCUS ASTROPHYSICS Legendary CHEMISTRY Deceptive spice POLITICS Scientists spy ECOLOGY New Zealand Arecibo telescope faces molecule offers cautionary chance to green UK plans to kill off all uncertain future p.143 tale p.144 after Brexit p.145 invasive predators p.148 ICARBONX Jun Wang, founder of digital biotechnology firm iCarbonX, showcases the Meum app that will use reams of health data to provide customized medical advice. BIOTECHNOLOGY Chinese health app arrives Access to a large population used to sharing data could give iCarbonX an edge over rivals. BY DAVID CYRANOSKI, SHENZHEN medical advice directly to consumers through another $400 million had been invested in the an app. alliance members, but he declined to name the ne of China’s most intriguing biotech- The announcement was a long-anticipated source. Wang also demonstrated the smart- nology companies has fleshed out an debut for iCarbonX, which Wang founded phone app, called Meum after the Latin for earlier quixotic promise to use artificial in October 2015 shortly after he left his lead- ‘my’, that customers would use to enter data Ointelligence (AI) to revolutionize health care. ership position at China’s genomics pow- and receive advice. The Shenzhen firm iCarbonX has formed erhouse, BGI, also in Shenzhen. The firm As well as Google, IBM and various smaller an ambitious alliance with seven technology has now raised more than US$600 million in companies, such as Arivale of Seattle, Wash- companies from around the world that special- investment — this contrasts with the tens of ington, are working on similar technology. But ize in gathering different types of health-care millions that most of its rivals are thought Wang says that the iCarbonX alliance will be data, said the company’s founder, Jun Wang, to have invested (although several big play- able to collect data more cheaply and quickly. -

Downloaded At
UC San Diego UC San Diego Electronic Theses and Dissertations Title Professionalizing Service Provision : The Field of Social Work in Urban China Permalink https://escholarship.org/uc/item/388729pv Author Han, Ling Publication Date 2015 Peer reviewed|Thesis/dissertation eScholarship.org Powered by the California Digital Library University of California UNIVERSITY OF CALIFORNIA, SAN DIEGO Professionalizing Service Provision: The Field of Social Work in Urban China A dissertation submitted in partial satisfaction of the requirements for the degree Doctor of Philosophy in Sociology by Ling Han Committee in charge: Professor Richard Madsen, Chair Professor Richard Biernacki Professor Kwai Ng Professor Paul Pickowicz Professor Nancy Postero Professor Christena Turner 2015 Copyright Ling Han, 2015 All rights reserved. The Dissertation of Ling Han is approved, and it is acceptable in quality and form for publication on microfilm and electronically: ________________________________________________________________ ________________________________________________________________ ________________________________________________________________ ________________________________________________________________ ________________________________________________________________ ________________________________________________________________ Chair University of California, San Diego 2015 iii DEDICATION For my parents iv TABLE OF CONTENTS Signature Page .................................................................................................................. -

Sentiment Analysis in Chinese Master's Thesis Presented to The
Sentiment Analysis in Chinese Master's Thesis Presented to The Faculty of the Graduate School of Arts and Sciences Brandeis University Department of Computer Science Nianwen Xue, Advisor In Partial Fulfillment Of the Requirements for Master's Degree By Lin Pan February 2012 Copyright by Lin Pan © 2012 Abstract Sentiment Analysis in Chinese A thesis presented to the Department of Computer Science Graduate School of Arts and Sciences Brandeis University Waltham, Massachusetts By Lin Pan Sentiment analysis has been a rapidly growing research area since the advent of Web 2.0 when social networking, blogging, tweeting, web applications, and online shopping, etc., began to gain ever more popularity. The large amount of data from product reviews, blogging posts, tweets and customer feedbacks, etc., makes it necessary to automatically identify and classify sentiments from theses sources. This can potentially benefit not only businesses and organizations who need market intelligence but also individuals who are interested in iii purchasing/comparing products online. Sentiment analysis is performed on various levels from feature to document level. Supervised, semi-supervised, unsupervised and topic modeling techniques are used towards solving the problems. In this thesis, I explore linguistic features and structures unique to Chinese in a machine-learning context and experiment with document-level sentiment analysis using three Chinese corpora. Results from different feature sets and classifiers are reported in terms of accuracy, which shows the -

The English Passive: a Cognitive Construction Grammar Approach
Passive Constructions in Present-Day English Jérôme PUCKICA University Grenoble 3, France, LIDILEM (EA 609) In English grammars, voice is often presented as a system opposing two formally defined members expressing two different ways of viewing the event denoted by a (transitive) verb: the active voice (e.g. The chief manager fired the employee) and the passive voice (e.g. The employee was fired (by the chief manager)). While maintaining that voice is a category of the English verb, analysts generally note that voice in English is a clause or sentence-level phenomenon which concerns the way the semantic arguments of a verb are mapped onto syntactic functions, with subject selection being the central issue. The ‘BE + past participle’ construction is understandably the main focus of presentations of the passive voice in Present-Day English (PDE). Yet, the label ‘passive voice’ cannot be reduced to that single construction. A passive construction may involve a verb other than BE combined with a past participle, as in the case of the GET-passive, but it may also not involve any kind of ‘helping’ verb. In addition, there are reasonable grounds for arguing that a passive construction may not even contain a past participle. In this paper, we argue that two main kinds of passive constructions may be recognized in PDE: first, standard or ‘central’ passive constructions, which all involve a passive past participle form; second, ‘marginal’ passive constructions, which do not involve such a form. The first part of this paper (§1) deals with central passives. It provides several arguments for distinguishing between passive past participles and active (or perfect) ones and suggests a distinction between two subtypes of central passives, namely, simple or bare central passives and periphrastic central passives. -

Womadelaide 1992 – 2016 Artists Listed by Year/Festival
WOMADELAIDE 1992 – 2016 ARTISTS LISTED BY YEAR/FESTIVAL 2016 47SOUL (Palestine/Syria/Jordan) Ainslie Wills (Australia) Ajak Kwai (Sudan/Australia) All Our Exes Live in Texas (Australia) Alpine (Australia) Alsarah & the Nubatones (Sudan/USA) Angelique Kidjo (Benin) & the Adelaide Symphony Orchestra (Australia) APY Choir (Australia) Asha Bhosle (India) Asian Dub Foundation (UK) Australian Dance Theatre “The Beginning of Nature” (Australia) Calexico (USA) Cedric Burnside Project (USA) DakhaBrakha (Ukraine) Datakae – Electrolounge (Australia) De La Soul (USA) Debashish Bhattacharya (India) Diego el Cigala (Spain) Djuki Mala (Australia) Edmar Castañeda Trio (Colombia/USA) Eska (UK) – one show with Adelaide [big] String Ester Rada (Ethiopia/Israel) Hazmat Modine (USA) Husky (Australia) Ibeyi (Cuba/France) John Grant (USA) Kev Carmody (Australia) Ladysmith Black Mambazo (South Africa) Mahsa & Marjan Vahdat (Iran) Marcellus Pittman - DJ (USA) Marlon Williams & the Yarra Benders (NZ/Australia) Miles Cleret - DJ (UK) Mojo Juju (Australia) Mortisville vs The Chief – Electrolounge (Australia) Mountain Mocha Kilimanjaro (Japan) NO ZU (Australia) Orange Blossom (France/Egypt) Osunlade - DJ (USA) Problems - Electrolounge (Australia) Quarter Street (Australia) Radical Son (Tonga/Australia) Ripley (Australia) Sadar Bahar - DJ (USA) Sampa the Great (Zambia/Australia) Sarah Blasko (Australia) Savina Yannatou & Primavera en Salonico (Greece) Seun Kuti & Egypt 80 (Nigeria) Songhoy Blues (Mali) Spiro (UK) St Germain (France) Surahn (Australia) Tek Tek Ensemble -

Comprehensibility of English Written Sentences Made by Non-Language University Students 181
Comprehensibility of English Written Sentences Made by Non-language University Students 181 COMPREHENSIBILITY OF ENGLISH WRITTEN SENTENCES MADE BY NON- LANGUAGE UNIVERSITY STUDENTS Patrisius Istiarto Djiwandono Faculty of Language and Arts Universitas Ma Chung, Malang, Indonesia [email protected] Abstract The study aimed to identify how an English native speaker and a highly proficient non-native speaker rated the comprehensibility of English sentences written by learners who were studying non-language majors. Nine essays written by students of Pharmacy and 14 essays written by students of Accounting were rated by the two raters. They were guided by a scoring rubric which emphasized mainly on the grammaticality and comprehensibility. Their ratings classified the sentences into two major categories: sentences with mistakes that potentially hinder comprehensibility, and sentences with mistakes that completely make them incomprehensible. Mistakes that make sentences partially comprehensible include wrong word order, coma splice, wrong auxiliary, wrong form of finite verb, wrong form of active sentences, the omission of verb be, intensifier, and introductory “there”. Mistakes that completely blocks comprehensibility are fragmented phrase, wrong collocations, mismatched markers, wrong part of speech, unfinished sentences, and excessively long sentences joined by a coordinator. A number of suggestions for the teaching of grammar, writing, and vocabulary are then proposed on the basis of the findings. Key words: Comprehensibility, errors, grammaticality, mistakes Comprehensibility is an important issue in communication. When messages are delivered in a language that is foreign to the speakers or writers, it becomes even more critical. These senders of the messages have to put their ideas in meaningful strings of sentences, with the right grammatical patterns, and preferably appropriate collocations. -

Passive Voice Usage in Undergraduate STEM Textbooks
University of Central Florida STARS Electronic Theses and Dissertations, 2004-2019 2018 Passive Voice Usage in Undergraduate STEM Textbooks Huiyuan Luo University of Central Florida Part of the Language and Literacy Education Commons Find similar works at: https://stars.library.ucf.edu/etd University of Central Florida Libraries http://library.ucf.edu This Doctoral Dissertation (Open Access) is brought to you for free and open access by STARS. It has been accepted for inclusion in Electronic Theses and Dissertations, 2004-2019 by an authorized administrator of STARS. For more information, please contact [email protected]. STARS Citation Luo, Huiyuan, "Passive Voice Usage in Undergraduate STEM Textbooks" (2018). Electronic Theses and Dissertations, 2004-2019. 5894. https://stars.library.ucf.edu/etd/5894 PASSIVE VOICE USAGE IN UNDERGRADUATE STEM TEXTBOOKS By Huiyuan “Tia” Luo B.A. Capital Normal University, 2011 M.A. University of Kansas, 2014 A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the College of Education and Human Performance at the University of Central Florida Orlando, Florida Spring Term 2018 Major Professor: Florin Mihai 2018 Huiyuan “Tia” Luo ii ABSTRACT The present study, a corpus-based quantitative analysis, investigated the use of passive voice in terms of percentage (percentage of total passive usage), constructions (the most commonly used passive forms), and dispersion (the verbs that tended to be associated with passive usage) in college STEM textbooks, more specifically in Science, Technology, Engineering, and Mathematics. The corpus consisted of twenty textbooks with over 1 million running words selected from the textbooks’ chapters.