Computational Modelling and Quantitative Analysis of Dynamics in Performed Music
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Second Grade Music Curriculum
Second Grade General Music Units September: October: November: December: January: Music Elements Music Elements Composition Performance Performance Rhythm Meter Rhythmic Composition Rhythmic Composition Performance Rhythmic Notation Intro to Meter Compose 8 measure Continue work on Practice using drum Top number rhythmic rhythmic Sticks& Pads Rhythmic Values Bottom number composition composition Counting Procedures -Mrs. Music May I? Bar Lines Review Dynamics Class work Practice performing -Rhythmic Pac Man Measure Add Dynamics original rhythmic -Musical Math Musical Rest to composition compositions Measure Completion Review Rough Performance Add other rhythm band Performance Draft with teacher Special Celebrations; instruments Special Celebrations: Performance Final draft (Songs & Activities) Perform composition (Song & activities) Special Celebrations: Graded Project Hanukkah for class Welcome Back songs (Songs & Activities) Kwanzaa Graded performance Character Ed Songs Fire Safety Songs Performance Christmas Performance Apple Songs Columbus Songs (Special Celebrations) Character Ed Special Celebrations: Butterfly Cycle Halloween Songs -Hiawatha Rhythm (Songs & Activities) th September 11 -Patriot Red Ribbon Songs Story -Month of the Year Rap Day Rhythm Pumpkin Patch -Thanksgiving Songs -Bundled Up September 17th- -I’m Thankful… -Martin Luther King Songs Constitution Day -Character Ed -Winter Songs February: March: April: May: June: Performance Music In Our Schools Music Elements Music Elements Performance Performance -

Timothy Bonenfant CV 2020-21
Timothy Bonenfant, D.M.A., Clarinetist Carr Education Fine-Arts Building, Room 217 ASU Station #10906; San Angelo, TX 76909-0906 (325) 486-6029 | [email protected] TEACHING EXPERIENCE 2005-present Professor of Music Angelo State University: San Angelo, TX Teach single reed studio (clarinet and saxophone) and advise students within the studio. Direct ASU Jazz Ensemble. Teach classes in Improvisation, Woodwind Methods, Jazz History, Introduction to Music and Survey of Rock and Roll. Direct/coach small woodwind ensembles (saxophone quartet, clarinet choir). 2017-2018 Adjunct Professor of Music Hardin Simmons University: Abilene, TX Taught saxophone studio while a search for a permanent replacement was conducted. 1996-2005 Instructor Las Vegas Academy for the Fine and Performing Arts: Las Vegas, NV Taught private lessons, fundamentals of music, and coached woodwind sectionals. 1993-2005 Lecturer University of Nevada, Las Vegas Taught Jazz Appreciation, Music Appreciation, History of Rock and Roll, History of American Popular Music, Finale: An Introduction, Music Fundamentals (for non-majors), Remedial Music Theory/Ear-Training. Also taught private lessons for clarinet and saxophone students. Developed new courses for the department; History of American Popular Music, and Finale: An Introduction. UNIVERSITY CLASSES TAUGHT Applied Music: Clarinet/Saxophone Woodwind Chamber Music Jazz Ensemble Improvisation Survey of Rock and Roll History of Jazz History of American Popular Music Introduction to Music Woodwind Methods Senior Recital Finale™ -

Margaret P. Fay, Doctor of Music 101 Walnut Street, London, on N6H 1C3 [email protected] 226-224-8377
Margaret P. Fay, Doctor of Music 101 Walnut Street, London, ON N6H 1C3 [email protected] 226-224-8377 www.margaretpfay.ca CURRICULUM VITAE Education Western University PhD in Music Theory Doctoral Candidate as of August 2018 • Entered program with Advanced Standing due to doctoral level music theory courses previously taken at Indiana University • Graduate ResearcH ScHolarsHip • Teaching Assistant for Studies in Music Theory I and II (See TeacHing Experience for details.) • Graduate courses in Set THeory and Transformational Analysis Indiana University Doctor of Music in Bassoon Performance December 2017 • Bassoon studies witH Professor William Ludwig and Professor KatHleen McLean • Minor in Music THeory • Taught as Associate Instructor in the Music Theory Department for six semesters while completing doctoral course work (See Teaching Experience for details.) • Piano lessons witH Professor Reiko Neriki • Master’s and doctoral courses in College Music TeacHing, Music THeory Pedagogy, Woodwind Literature, ScHenkerian Analysis, RhytHm and Meter, History of Music THeory, Readings in Music THeory, MoZart Operas University of British Columbia Master of Arts in Music Theory August 2010 • Master’s tHesis entitled: “Using single-line instruments as a means of reinforcing concepts of harmony: a discussion of exercises for use in individual and group settings” • Composition lessons witH Dr. StepHen Chatman • Bassoon lessons with Professor Jesse Read and Professor Julia Lockhart • Graduate courses in ScHenkerian Analysis, Post-tonal Analysis, Classical Form, Analysis of Late Romantic Works, BraHms CHamber Music Ithaca College Master of Music in Bassoon Performance June 2009 • Bassoon studies witH Professor Lee Goodhew Romm • Piano lessons witH Professor Phiroze Mehta • Composition lessons witH Dr. -

Four Distinctions for the Auditory ``Wastebasket'' of Timbre
OPINION published: 04 October 2017 doi: 10.3389/fpsyg.2017.01747 Four Distinctions for the Auditory “Wastebasket” of Timbre1 Kai Siedenburg 1, 2* and Stephen McAdams 1 1 Centre for Interdisciplinary Research in Music Media and Technology, Schulich School of Music, McGill University, Montreal, QC, Canada, 2 Department of Medical Physics and Acoustics, University of Oldenburg, Oldenburg, Germany Keywords: timbre perception, music cognition, psychoacoustics, conceptual framework, definitions 1. INTRODUCTION If there is one thing about timbre that researchers in psychoacoustics and music psychology agree on, it is the claim that it is a poorly understood auditory attribute. One facet of this commonplace conception is that it is not only the complexity of the subject matter that complicates research, but also that timbre is hard to define (cf., Krumhansl, 1989). Perhaps for lack of a better alternative, one can observe a curious habit in introductory sections of articles on timbre, namely to cite a definition from the American National Standards Institute (ANSI) and to elaborate on its shortcomings. For the sake of completeness (and tradition!) we recall: “Timbre. That attribute of auditory sensation which enables a listener to judge that two nonidentical sounds, similarly presented and having the same loudness and pitch, are dissimilar [sic]. NOTE-Timbre depends primarily upon the frequency spectrum, although it also depends upon the sound pressure and the temporal characteristics of the sound.” (ANSI, 1994, p. 35) One of the strongest criticisms of this conceptual framing was given by Bregman (1990), Edited by: commenting, Mari Tervaniemi, University of Helsinki, Finland “This is, of course, no definition at all. -

Second Grade Music Choice Boards
Second Grade Music Choice Boards 1) Select 2 of the following 9 choice boards for the entire quarter 2) Make a list, take a picture, or record yourself demonstrating the 2 activities of your choice 3) Share the document with me, either in Google classroom, Gmail, or my school email address Have fun and be musical! Music Choice Boards Information Music will be a recorded lesson in Google classroom that students can view at any time. Students are encouraged to watch and participate to the best of their ability. In addition to watching the videos and participating, students will be given Choice Boards that they may select 2 activities of their choice to complete for the quarter. You can write, type, take a picture, or send a video of yourself completing the activity to your music teacher. The first activity is due October 2. The second activity is due November 13. Any questions, please reach out. Music Choice Boards #1-3 1 Dynamics 2 Tempo 3 Pitch Pick 10 sounds and use the Pick 10 sounds and/or items and following music words to describe use the following music words to Pick 10 sounds and use the them: describe them: following music words to Piano - soft Forte - Loud describe them: Largo - very slow Pianissimo - Very Soft Presto - very fast Fortissimo - Very Loud Treble - high Bass - Low Adagio - slow Allegro - fast Submit your listing of sounds and Submit your listing of sounds their dynamics to your teacher. and their pitch to your Submit your listing of sounds teacher. and their tempo to your teacher. -
Outcome 3 – Communication CWA Measurable Criteria Measurement Tool Time Frame 1
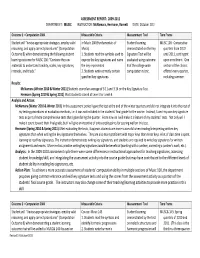
ASSESSMENT REPORT: 2009‐2011 DEPARTMENT: MUSIC INSTRUCTOR: McNamara, Hermann, Barnett DATE: October 2011 Outcome 1 – Computation CWA Measurable Criteria Measurement Tool Time Frame Student will “devise appropriate strategies, employ valid In Music 100 (Fundamentals of Student learning MUSC 100: Consecutive reasoning, and apply correct procedures” (Computation Music) demonstrated on the Key quarters from 2010 Outcome B) when demonstrating the following student 1. Students read the symbols used to Signature Test will be until 2011, contingent learning outcome for MUSC 100: “Combine the raw express the key signatures and name evaluated using outcome upon enrollment. One materials to understand tonality, scales, key signatures, the key represented. B of the college‐wide section of the class is intervals, and triads.” 2. Students write correctly certain computation rubric. offered every quarter, specified key signatures. including summer. Results: McNamara (Winter 2010 & Winter 2011) Students scored an average of 3.11 and 3.14 on the Key Signature Test. Hermann (Spring 2010 & Spring 2011) Most students scored at Level 3 or Level 4. Analysis and Action: McNamara (Winter 2010 & Winter 2011) In this assessment period I gave the test at the end of the winter quarters and did not integrate it into the rest of my testing procedures or evaluation methods, i.e. it was not included in the students’ final grade for the course. Instead, I used my own key signature tests as part of more comprehensive tests that I gave during the quarter. From now on I will make it a feature of my students’ tests. Not only will I make it count toward their final grade, but I will give an incentive of extra credit points for scoring well on this test. -

The Controversy Over Bach's Trills: Towards a Reconciliation
INFORMATION TO USERS This manuscript has been reproduced from the microfilm master. UMI films the text diret.'tly from the original or copy submitted. Thus, some thesis and dissertation copies are in typewriter face, while others may be from any type of computer printer. The quality of this reproduction is dependent upon the quality of the copy submitted. Broken or indistinct print, colored or poor quality illustrations and photographs, print bleedthrough, substandard margins, and improper alignment can adversely affect reproduction. In the unlikely event that the author did not send UMI a complete manuscript and there are missing pages, these will be noted. .AJso, if unauthorized copyright material had to be removed, a note will indicate the deletion. Oversize materials (e.g., maps, drawings, charts) are reproduced by sectioning the original, beginning at the upper left-hand corner and continuing from left to right in equal sections with small overlaps. Each original is also photographed in one exposure and is included in reduced form at the back of the book. Photographs included in the original manuscript have been reproduced xerographically in this copy. Higher quality 6" x 9" black and white photographic prints are available for any photographs or illustrations appearing tJ. this copy for an additional charge. Contact UMI directly to order. U·M·I University Microfilms International A Bell & Howell tnformat1on Company 300 North Zeeb Road. Ann Arbor. M148106-1346 USA 3131761-4700 800:521-0600 Order Number 9502692 The controversy over Bach's trills: Towards a reconciliation Polevoi, Randall Mark, D.M.A. The University of North Carolina at Greensboro, 1994 U·M·I 300 N. -

Elizabeth Aleksander, D.M.A. A. Employment History B. Teaching
I. PERSONAL INFORMATION Elizabeth Aleksander, D.M.A. Associate Professor of Music Fine Arts 235 Martin, TN 38238 731.881.7413 [email protected] II. EDUCATIONAL CREDENTIALS 2008 Doctorate of Musical Arts in Clarinet Performance University of Nebraska (Lincoln, Nebraska) Related Area of Study: Music Theory Document: “Gustav Jenner’s Clarinet Sonata in G Major, opus 5: An Analysis and Performance Guide with Stylistic Comparison to the Clarinet Sonatas, opus 120 of His Teacher, Johannes Brahms” 2005 Master of Music in Clarinet Performance with distinction Northern Arizona University (Flagstaff, Arizona) 2003 Bachelor of Music in Clarinet Performance, Summa cum laude Ohio University (Athens, Ohio) III. EMPLOYMENT HISTORY AND TEACHING / ADVISING A. Employment History 2013-present University of Tennessee at Martin (Martin, Tennessee) Associate Professor (2017-present), Assistant Professor (2013-2017) 2014-present UTM Community Music Academy (Martin, Tennessee) Instructor of Clarinet 2016-present Paducah Symphony Orchestra (Paducah, Kentucky) Bass Clarinet 2014-2015 Jackson Symphony Orchestra (Jackson, Tennessee) Co-Principal Clarinet 2004-2014 Private Studio (Martin, Tennessee; Lincoln, Nebraska; and Flagstaff, Arizona) Instructor of Clarinet 2008-2013 Cornerstone Academy of Clarinet (Lincoln, Nebraska) Instructor of Clarinet 2009-2013 Southeast Community College (Lincoln, Nebraska) Instructor of Music 2007-2008 Midland University (Fremont, Nebraska) Instructor of Music B. Teaching Accomplishments 1. Courses Taught Clarinet MUAP 161, 162, 164, 362: Clarinet Lessons MUAP 495: Senior Recital MUEN 368: Clarinet Choir, Clarinet Quartet, and Wind Quintet Music Theory MUS 131: Music Theory I MUS 231: Music Theory III (formerly MUS 222: Music Theory IV) MUS 420: Form and Analysis Music Appreciation MUS 111: Masterpieces of Music MUS 112: Music In Our Time Aleksander Curriculum Vitae (Page 2) 2. -

COVID-19 Transmission Risks from Singing and Playing Wind Instruments – What We Know So
SYNOPSIS 11/18/2020 COVID-19 Transmission from Singing and Playing Wind Instruments – What We Know So Far Introduction Public Health Ontario (PHO) is actively monitoring, reviewing and assessing relevant information related to Coronavirus Disease 2019 (COVID-19). “What We Know So Far” documents provide a rapid review of the evidence related to a specific aspect or emerging issue related to COVID-19. Updates to our Latest Version In the latest version of COVID-19 Transmission from Singing and Playing Wind Instruments – What We Know So Far, we present results of an updated literature search and rapid review. The updated version provides additional evidence concerning potential COVID-19 transmission during singing and playing wind instruments, including the addition of 22 new articles. We identified 10 new studies on experimental transmission during singing or playing wind instruments; four additional articles reported observational studies on transmission during singing; and there were two reviews of transmission risks during performances. We identified six articles on transmission risks during performances from the grey literature. There have been no published reports on COVID-19 transmission from wind instruments. The findings from this updated rapid review do not change our previous assessment of COVID-19 transmission during singing and playing wind instruments. Key Findings Singing generates respiratory droplets and aerosols; however, the degree to which each of these particles contributes to COVID-19 transmission is unclear. The evidence supporting COVID-19 transmission during singing is limited to a small number of observational studies and experimental models. Thirteen of 1,548 (<1%) documented superspreading events have been associated with singing. -

Rhythms of the World: Part 2 African Drumming
KSKS45 OCR AoS3 Rhythms of the World, part 2: Africa, and Central and South America David Guinane is by David Guinane Head of Music at Beaumont School in St Albans, and a freelance writer on music education. He RHYTHMS OF THE WORLD: PART 2 is the co-author of the accredited study In the last resource on OCR’s Rhythms of the World area of study (September 2017), we looked at the Indian guide for the OCR Subcontinent the eastern Mediterranean and the Middle East. GCSE music course. In this resource, we’ll look at the remaining styles and traditions included in the area of study: African drumming Calypso from Trinidad and Tobago Brazilian samba Once again, this resource contains required knowledge as well as details of musical activities that will deepen students’ understanding of the traditions. AFRICAN DRUMMING Africa is an immense continent, with a rich and diverse cultural and musical history. Of the huge number of musical styles and traditions to come from Africa, this AoS focuses on drumming styles popular in sub-Saharan Africa. DRUMMING TRADITIONS IN AFRICA When the term ‘African drumming’ is used in schools, it often refers to the use of djembes (often found in school classrooms, too often simply gathering dust). Since Africa has such a diverse and complex history, it’s difficult to narrow down what music is played in which part of Africa, and where each tradition begins and develops. However, it’s important that students don’t think all African music is African drumming, so some specific examples can be useful. -

Rebecca Prushinski Pecherek MUS 1000-01 1 October 2018
Rebecca Prushinski Pecherek MUS 1000-01 1 October 2018 Concert Review Going into this concert, I initially wasn’t too excited. I’ve never thoroughly enjoyed an instrumental concert. The memories I have of band concerts include my mom forcing me to go to my sister’s high school band concerts, and listening to the Princeton High School band while waiting to go on for choir. When I witnessed these concerts, the songs always felt too long and didn’t excite me. Because of these experiences, I had a negative outlook on instrumental concerts, but the symphony orchestra was completely different. Right when I saw the large string section I knew it was going to be different than the high school band concerts I had previously experienced. The first section was titled “Hollywood Film Music” which I was excited for because I knew I would recognize most of the music. The first song performed was “Themes from 007” which was different music from the James Bond movies. I think this song was a good opener because it started out strong and engaged all parts of the orchestra right from the start. I like that there is a steadiness in the rhythm for a majority of the song in the percussion while the strings carry the melody. The changing dynamics during the different movements of the medley kept the listener engaged so the music didn’t seem as repetitive and stayed interesting the whole number. The second piece was “Goldfinger” which brought out a guest singer to sing along side the orchestra. -

THE AMERICAN RECORDER SOCIETY 114 East 85Th Street, New York 28, N
THE AMERICAN RECORDER SOCIETY 114 East 85th Street, New York 28, N. Y. Founded in 1939 by Suzanne Bloch OFFICERS LaNOUE DAVENPORT, President I A.C. GLASSGOLO, Vice President I DONNA HILL, Secretary! YRSA DAMMANN GEIST, Asst. Secretary I MARVIN ROSENBERG, Treasurer I RALPH TAYLOR, Asst. Treasurer MARTHA BIXLER, Editor 359 East 68th Street No. 38 New York 21, N.Y. October 1959 Continuing the articles on Technique by A. Rowland Jones, the following is the tenth in +he series, reprinted with permission from The Recorder News of England. ORNAMENTATION It is not infrequent for the question ''how?" both the why and how of ornamentation, and to beg the question "why?". Ornamentation it is the purpose of this article to in- is a case. This series of articles on re- dicate those beginnings so that a player corder technique must therefore digress knows and can execute confidently a small into the more complex and fundamental and basically correct group of ornaments subject of musical interpretation. Much which he can (and should) modify as he of the best music written specifically for gains experience. The first essential in the recorder belongs to an age which orna- learning to ornament is to listen to as mentation was an integral and essential much sixteenth, seventeenth and eighteenth part of music and it was an accepted con- century music as time and opportunity al- vention that certain patterns of short lows--not just recorder music, but music notes should be written as one note, with for all instruments and voices. Even if or without an ornament sign above it, for it is impossible to undergo full-scale decoration was so stereotyped that the con- orientation by attending the Haslemere text of a note was sufficient to instruct Festival or other live concerts of old the player to execute a trill, shake, mor- music wireless programmes can always be dent, etc., or an extended improvisation listened to: performances by the London in the Carelli manner, as the occasion Harpsichord Ensemble, the Stuttgart Chamber might demand.