Worksheet #18 Answers
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Comparison of Parallel and Pipelined CORDIC Algorithm Using RCA and CSA
Comparison of Parallel and Pipelined CORDIC algorithm using RCA and CSA Diego Barragan´ Guerrero Lu´ıs Geraldo P. Meloni FEEC - UNICAMP FEEC - UNICAMP Campinas, Sao˜ Paulo, Brazil, 13083-852 Campinas, Sao˜ Paulo, Brazil, 13083-852 +5519 9308-9952 +5519 9778-1523 [email protected] [email protected] Abstract— This paper presents an implementation of the algorithm has two modes of operation: the rotational mode CORDIC algorithm in digital hardware using two types of (RM) where the vector (xi; yi) is rotated by an angle θ to algebraic adders: Ripple-Carry Adder (RCA) and Carry-Select obtain a new vector (x ; y ), and the vectoring mode (VM) Adder (CSA), both in parallel and pipelined architectures. Anal- N N ysis of time performance and resources utilization was carried in which the algorithm computes the modulus R and phase α out by changing the algorithm number of iterations. These results from the x-axis of the vector (x0; y0). The basic principle of demonstrate the efficiency in operating frequency of the pipelined the algorithm is shown in Figure 1. architecture with respect to the parallel architecture. Also it is shown that the use of CSA reduce the timing processing without significantly increasing the slice use. The code was synthesized us- ing FPGA development tools for the Xilinx Spartan-3E xc3s500e ' ' E N y family. N E N Index Terms— CORDIC, pipelined, parallel, RCA, CSA, y N trigonometrics functions. Rotação Pseudo-rotação R N I. INTRODUCTION E i In Digital Signal Processing with FPGA, trigonometric y i R i functions are used in many signal algorithms, for instance N synchronization and equalization [12]. -

Basics of Logic Design Arithmetic Logic Unit (ALU) Today's Lecture
Basics of Logic Design Arithmetic Logic Unit (ALU) CPS 104 Lecture 9 Today’s Lecture • Homework #3 Assigned Due March 3 • Project Groups assigned & posted to blackboard. • Project Specification is on Web Due April 19 • Building the building blocks… Outline • Review • Digital building blocks • An Arithmetic Logic Unit (ALU) Reading Appendix B, Chapter 3 © Alvin R. Lebeck CPS 104 2 Review: Digital Design • Logic Design, Switching Circuits, Digital Logic Recall: Everything is built from transistors • A transistor is a switch • It is either on or off • On or off can represent True or False Given a bunch of bits (0 or 1)… • Is this instruction a lw or a beq? • What register do I read? • How do I add two numbers? • Need a method to reason about complex expressions © Alvin R. Lebeck CPS 104 3 Review: Boolean Functions • Boolean functions have arguments that take two values ({T,F} or {0,1}) and they return a single or a set of ({T,F} or {0,1}) value(s). • Boolean functions can always be represented by a table called a “Truth Table” • Example: F: {0,1}3 -> {0,1}2 a b c f1f2 0 0 0 0 1 0 0 1 1 1 0 1 0 1 0 0 1 1 0 0 1 0 0 1 0 1 1 0 0 1 1 1 1 1 1 © Alvin R. Lebeck CPS 104 4 Review: Boolean Functions and Expressions F(A, B, C) = (A * B) + (~A * C) ABCF 0000 0011 0100 0111 1000 1010 1101 1111 © Alvin R. Lebeck CPS 104 5 Review: Boolean Gates • Gates are electronics devices that implement simple Boolean functions Examples a a AND(a,b) OR(a,b) a NOT(a) b b a XOR(a,b) a NAND(a,b) b b a NOR(a,b) a XNOR(a,b) b b © Alvin R. -

Digital Electronic Circuits
DIGITAL ELECTRONIC CIRCUITS SUBJECT CODE: PEI4I103 B.Tech, Fourth Semester Prepared By Dr. Kanhu Charan Bhuyan Asst. Professor Instrumentation and Electronics Engineering COLLEGE OF ENGINEERING AND TECHNOLOGY BHUBANESWAR B.Tech (E&IE/AE&I) detail Syllabus for Admission Batch 2015-16 PEI4I103- DIGITAL ELECTRONICS University level 80% MODULE – I (12 Hours)1. Number System: Introduction to various number systems and their Conversion. Arithmetic Operation using 1’s and 2`s Compliments, Signed Binary and Floating Point Number Representation Introduction to Binary codes and their applications. (5 Hours) 2. Boolean Algebra and Logic Gates: Boolean algebra and identities, Complete Logic set, logic gates and truth tables. Universal logic gates, Algebraic Reduction and realization using logic gates (3 Hours) 3. Combinational Logic Design: Specifying the Problem, Canonical Logic Forms, Extracting Canonical Forms, EX-OR Equivalence Operations, Logic Array, K-Maps: Two, Three and Four variable K-maps, NAND and NOR Logic Implementations. (4 Hours) MODULE – II (14 Hours) 4. Logic Components: Concept of Digital Components, Binary Adders, Subtraction and Multiplication, An Equality Detector and comparator, Line Decoder, encoders, Multiplexers and De-multiplexers. (5 Hours) 5. Synchronous Sequential logic Design: sequential circuits, storage elements: Latches (SR,D), Storage elements: Flip-Flops inclusion of Master-Slave, characteristics equation and state diagram of each FFs and Conversion of Flip-Flops. Analysis of Clocked Sequential circuits and Mealy and Moore Models of Finite State Machines (6 Hours) 6. Binary Counters: Introduction, Principle and design of synchronous and asynchronous counters, Design of MOD-N counters, Ring counters. Decade counters, State Diagram of binary counters (4 hours) MODULE – III (12 hours) 7. -

Binary Counter
Systems I: Computer Organization and Architecture Lecture 8: Registers and Counters Registers • A register is a group of flip-flops. – Each flip-flop stores one bit of data; n flip-flops are required to store n bits of data. – There are several different types of registers available commercially. – The simplest design is a register consisting only of flip- flops, with no other gates in the circuit. • Loading the register – transfer of new data into the register. • The flip-flops share a common clock pulse (frequently using a buffer to reduce power requirements). • Output could be sampled at any time. • Clearing the flip-flop (placing zeroes in all its bit) can be done through a special terminal on the flip-flop. 1 4-bit Register I0 D Q A0 Clock C I1 D Q A1 C I D Q 2 A2 C D Q A I3 3 C Clear Registers With Parallel Load • The clock usually provides a steady stream of pulses which are applied to all flip-flops in the system. • A separate control system is needed to determine when to load a particular register. • The Register with Parallel Load has a separate load input. – When it is cleared, the register receives it output as input. – When it is set, it received the load input. 2 4-bit Register With Parallel Load Load D Q A0 I0 C D Q A1 C I1 D Q A2 I2 C D Q A3 I3 C Clock Shift Registers • A shift register is a register which can shift its data in one or both directions. -

Design and Analysis of Power Efficient PTL Half Subtractor Using 120Nm Technology
International Journal of Computer Trends and Technology (IJCTT) – volume 7 number 4– Jan 2014 Design and Analysis of Power Efficient PTL Half Subtractor Using 120nm Technology 1 2 Pranshu Sharma , Anjali Sharma 1(Department of Electronics & Communication Engineering, APG Shimla University, India) 2(Department of Electronics & Communication Engineering, APG Shimla University, India) ABSTRACT : In the designing of any VLSI System, There are a number of logic styles by which a circuit can arithmetic circuits play a vital role, subtractor circuit is be implemented some of them used in this paper are one among them. In this paper a Power efficient Half- CMOS, TG, PTL. CMOS logic styles are robust against Subtractor has been designed using the PTL technique. voltage scaling and transistor sizing and thus provide a Subtractor circuit using this technique consumes less reliable operation at low voltages and arbitrary transistor power in comparison to the CMOS and TG techniques. sizes. In CMOS style input signals are connected to The proposed Half-Subtractor circuit using the PTL transistor gates only, which facilitate the usage and technique consists of 6 NMOS and 4 PMOS. The characterization of logic cells. Due to the complementary proposed PTL Half-Subtractor is designed and simulated transistor pairs the layout of CMOS gates is not much using DSCH 3.1 and Microwind 3.1 on 120nm. The complicated and is power efficient. The large number of power estimation and simulation of layout has been done PMOS transistors used in complementary CMOS logic for the proposed PTL half-Subtractor design. Power style is one of its major disadvantages and it results in comparison on BSIM-4 and LEVEL-3 has been high input loads [3]. -

Cross Architectural Power Modelling
Cross Architectural Power Modelling Kai Chen1, Peter Kilpatrick1, Dimitrios S. Nikolopoulos2, and Blesson Varghese1 1Queen’s University Belfast, UK; 2Virginia Tech, USA E-mail: [email protected]; [email protected]; [email protected]; [email protected] Abstract—Existing power modelling research focuses on the processor are extensively explored using a cumbersome trial model rather than the process for developing models. An auto- and error approach after which a suitable few are selected [7]. mated power modelling process that can be deployed on different Such an approach does not easily scale for various processor processors for developing power models with high accuracy is developed. For this, (i) an automated hardware performance architectures since a different set of hardware counters will be counter selection method that selects counters best correlated to required to model power for each processor. power on both ARM and Intel processors, (ii) a noise filter based Currently, there is little research that develops automated on clustering that can reduce the mean error in power models, and (iii) a two stage power model that surmounts challenges in methods for selecting hardware counters to capture proces- using existing power models across multiple architectures are sor power over multiple processor architectures. Automated proposed and developed. The key results are: (i) the automated methods are required for easily building power models for a hardware performance counter selection method achieves compa- collection of heterogeneous processors as seen in traditional rable selection to the manual method reported in the literature, data centers that host multiple generations of server proces- (ii) the noise filter reduces the mean error in power models by up to 55%, and (iii) the two stage power model can predict sors, or in emerging distributed computing environments like dynamic power with less than 8% error on both ARM and Intel fog/edge computing [8] and mobile cloud computing (in these processors, which is an improvement over classic models. -

Implementation of Carry Tree Adders and Compare with RCA and CSLA
International Journal of Emerging Engineering Research and Technology Volume 4, Issue 1, January 2016, PP 1-11 ISSN 2349-4395 (Print) & ISSN 2349-4409 (Online) Implementation of Carry Tree Adders and Compare with RCA and CSLA 1 2 G. Venkatanaga Kumar , C.H Pushpalatha Department of ECE, GONNA INSTITUTE OF TECHNOLOGY, Vishakhapatnam, India (PG Scholar) Department of ECE, GONNA INSTITUTE OF TECHNOLOGY, Vishakhapatnam, India (Associate Professor) ABSTRACT The binary adder is the critical element in most digital circuit designs including digital signal processors (DSP) and microprocessor data path units. As such, extensive research continues to be focused on improving the power delay performance of the adder. In VLSI implementations, parallel-prefix adders are known to have the best performance. Binary adders are one of the most essential logic elements within a digital system. In addition, binary adders are also helpful in units other than Arithmetic Logic Units (ALU), such as multipliers, dividers and memory addressing. Therefore, binary addition is essential that any improvement in binary addition can result in a performance boost for any computing system and, hence, help improve the performance of the entire system. Parallel-prefix adders (also known as carry-tree adders) are known to have the best performance in VLSI designs. This paper investigates three types of carry-tree adders (the Kogge- Stone, sparse Kogge-Stone, Ladner-Fischer and spanning tree adder) and compares them to the simple Ripple Carry Adder (RCA) and Carry Skip Adder (CSA). In this project Xilinx-ISE tool is used for simulation, logical verification, and further synthesizing. This algorithm is implemented in Xilinx 13.2 version and verified using Spartan 3e kit. -
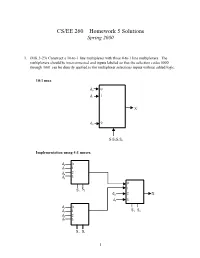
CS/EE 260 – Homework 5 Solutions Spring 2000
CS/EE 260 – Homework 5 Solutions Spring 2000 1. (MK 3-23) Construct a 10-to-1 line multiplexer with three 4-to-1 line multiplexers. The multiplexers should be interconnected and inputs labeled so that the selection codes 0000 through 1001 can be directly applied to the multiplexer selections inputs without added logic. 10:1 mux d0 0 1 d1 1 X d9 9 S3S2S1S0 Implementation using 4:1 muxes. d0 0 d2 1 d4 2 d6 3 0 S 1 S2 1 d8 2 X d9 3 d 0 1 S S d3 1 3 0 d5 2 d7 3 S2 S1 1 2. (MK 3-27) Implement a binary full adder with a dual 4-to-1 line multiplexer and a single inverter. AB Ci S Co 00 0 0 0 C 0 00 1 1 i 0 01 0 1 0 C ´ C 01 1 0 i 1 i 10 0 1 0 10 1 0Ci´ 1 Ci 11 0 0 1 C 1 11 1 1 i 1 0 C 1 i 4:1 2 S 3 mux S1 S0 A B 0 0 1 4:1 Co 2 mux 1 3 S1S0 2 3. (MK 3-34) Design a combinational circuit that forms the 2-bit binary sum S1S0 of two 2-bit numbers A1A0 and B1B0 and has both input C0 and a carry output C2. Do not use half adders or full adders, but instead use a two-level circuit plus inverters for the input variables, as needed. Design the circuit by starting with the following equations for each of the two bits of the adder. -

UNIT 8B a Full Adder
UNIT 8B Computer Organization: Levels of Abstraction 15110 Principles of Computing, 1 Carnegie Mellon University - CORTINA A Full Adder C ABCin Cout S in 0 0 0 A 0 0 1 0 1 0 B 0 1 1 1 0 0 1 0 1 C S out 1 1 0 1 1 1 15110 Principles of Computing, 2 Carnegie Mellon University - CORTINA 1 A Full Adder C ABCin Cout S in 0 0 0 0 0 A 0 0 1 0 1 0 1 0 0 1 B 0 1 1 1 0 1 0 0 0 1 1 0 1 1 0 C S out 1 1 0 1 0 1 1 1 1 1 ⊕ ⊕ S = A B Cin ⊕ ∧ ∨ ∧ Cout = ((A B) C) (A B) 15110 Principles of Computing, 3 Carnegie Mellon University - CORTINA Full Adder (FA) AB 1-bit Cout Full Cin Adder S 15110 Principles of Computing, 4 Carnegie Mellon University - CORTINA 2 Another Full Adder (FA) http://students.cs.tamu.edu/wanglei/csce350/handout/lab6.html AB 1-bit Cout Full Cin Adder S 15110 Principles of Computing, 5 Carnegie Mellon University - CORTINA 8-bit Full Adder A7 B7 A2 B2 A1 B1 A0 B0 1-bit 1-bit 1-bit 1-bit ... Cout Full Full Full Full Cin Adder Adder Adder Adder S7 S2 S1 S0 AB 8 ⁄ ⁄ 8 C 8-bit C out FA in ⁄ 8 S 15110 Principles of Computing, 6 Carnegie Mellon University - CORTINA 3 Multiplexer (MUX) • A multiplexer chooses between a set of inputs. D1 D 2 MUX F D3 D ABF 4 0 0 D1 AB 0 1 D2 1 0 D3 1 1 D4 http://www.cise.ufl.edu/~mssz/CompOrg/CDAintro.html 15110 Principles of Computing, 7 Carnegie Mellon University - CORTINA Arithmetic Logic Unit (ALU) OP 1OP 0 Carry In & OP OP 0 OP 1 F 0 0 A ∧ B 0 1 A ∨ B 1 0 A 1 1 A + B http://cs-alb-pc3.massey.ac.nz/notes/59304/l4.html 15110 Principles of Computing, 8 Carnegie Mellon University - CORTINA 4 Flip Flop • A flip flop is a sequential circuit that is able to maintain (save) a state. -

Design of Adder / Subtractor Circuits Based On
ISSN (Print) : 2320 – 3765 ISSN (Online): 2278 – 8875 International Journal of Advanced Research in Electrical, Electronics and Instrumentation Engineering (An ISO 3297: 2007 Certified Organization) Vol. 2, Issue 8, August 2013 DESIGN OF ADDER / SUBTRACTOR CIRCUITS BASED ON REVERSIBLE GATES V.Kamalakannan1, Shilpakala.V2, Ravi.H.N3 Lecturer, Department of ECE, R.L.Jalappa Institute of Technology, Doddaballapur, Karnataka, India 1 Asst. Professor & HOD, Department of ECE, R.L.Jalappa Institute of Technology, Doddaballapur, Karnataka, India2 Lab Assistant, Dept. of ECE, U.V.C.E, Bangalore Karnataka, India3 ABSTRACT: Reversible logic has extensive applications in quantum computing, it is a unconventional form of computing where the computational process is reversible, i.e., time-invertible. The main motivation behind the study of this technology is aimed at implementing reversible computing where they offer what is predicted to be the only potential way to improve the energy efficiency of computers beyond von Neumann-Landauer limit. It is relatively new and emerging area in the field of computing that taught us to think physically about computation Quantum Computing will be a total change in how the computer will operate and function. The reversible arithmetic circuits are efficient in terms of number of reversible gates, garbage output and quantum cost. In this paper design Reversible Binary Adder- Subtractor- Mux, Adder-Subtractor- TR Gate., Adder-Subtractor- Hybrid are proposed. In all the three design approaches, the Adder and Subtractor are realized in a single unit as compared to only full adder/subtractor in the existing design. The performance analysis is verified using number reversible gates, Garbage input/outputs and Quantum Cost.The reversible 4-bit full adder/ subtractor design unit is compared with conventional ripple carry adder, carry look ahead adder, carry skip adder, Manchester carry adder based on their performance with respect to area, timing and power. -

Area and Power Optimized D-Flip Flop and Subtractor
IT in Industry, Vol. 9, No.1, 2021 Published Online 28-02-2021 AREA AND POWER OPTIMIZED D-FLIP FLOP AND SUBTRACTOR T. Subhashini1, M. Kamaraju2, K. Babulu3 1,2 Department of ECE, Gudlavalleru Engineering College, India 3Department of ECE, UCOE, JNTUK, Kakinada, India Abstract: Low power is essential in today’s technology. It LITERATURE SURVEY is most significant with high speed, small size and stability. So, power reduction is most important in modern In the era of microelectronics, power dissipation is technology using VLSI design techniques. Today most of limiting factor. In any CMOS technology, provides the market necessities require low power, long run time very low Static power dissipation. Due to the and market which also deserve small size and high speed. discharge of capacitance, during the switching In this paper several logic circuits DFF with 5 transistors operation, that cause a power dissipation. Which and sub tractor circuit using powerless XOR gate and increases with the clock frequency. Using Groundless XNOR gates are implemented. In the proposed Transmission Gate Technique Such unnecessary DFF, the area can be decreased by 62% & substarctor discharging can be prevented. Due to the resistance of circuit, area decreased by 80% and power consumption of switches, impartial losses may be occurred for any DFF and subtractor circuit are 15.4µW and 13.76µW logic operation. respectively, but these are very less as compared to existing techniques. To avoid these minor losses keep clock frequency to be small than the technological limit. There are Keyword: D FF, NMOS, PMOS, VLSI, P-XOR, G-XNOR different types of Transmission Gate logic families. -

Experiment No
1 LIST OF EXPERIMENTS 1. Study of logic gates. 2. Design and implementation of adders and subtractors using logic gates. 3. Design and implementation of code converters using logic gates. 4. Design and implementation of 4-bit binary adder/subtractor and BCD adder using IC 7483. 5. Design and implementation of 2-bit magnitude comparator using logic gates, 8- bit magnitude comparator using IC 7485. 6. Design and implementation of 16-bit odd/even parity checker/ generator using IC 74180. 7. Design and implementation of multiplexer and demultiplexer using logic gates and study of IC 74150 and IC 74154. 8. Design and implementation of encoder and decoder using logic gates and study of IC 7445 and IC 74147. 9. Construction and verification of 4-bit ripple counter and Mod-10/Mod-12 ripple counter. 10. Design and implementation of 3-bit synchronous up/down counter. 11. Implementation of SISO, SIPO, PISO and PIPO shift registers using flip-flops. KCTCET/2016-17/Odd/3rd/ETE/CSE/LM 2 EXPERIMENT NO. 01 STUDY OF LOGIC GATES AIM: To study about logic gates and verify their truth tables. APPARATUS REQUIRED: SL No. COMPONENT SPECIFICATION QTY 1. AND GATE IC 7408 1 2. OR GATE IC 7432 1 3. NOT GATE IC 7404 1 4. NAND GATE 2 I/P IC 7400 1 5. NOR GATE IC 7402 1 6. X-OR GATE IC 7486 1 7. NAND GATE 3 I/P IC 7410 1 8. IC TRAINER KIT - 1 9. PATCH CORD - 14 THEORY: Circuit that takes the logical decision and the process are called logic gates.