Eludamos.Org
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Rogue-Gym: a New Challenge for Generalization in Reinforcement Learning
Rogue-Gym: A New Challenge for Generalization in Reinforcement Learning Yuji Kanagawa Tomoyuki Kaneko Graduate School of Arts and Sciences Interfaculty Initiative in Information Studies The University of Tokyo The University of Tokyo Tokyo, Japan Tokyo, Japan [email protected] [email protected] Abstract—In this paper, we propose Rogue-Gym, a simple and or designated areas but need to perform safely in real world classic style roguelike game built for evaluating generalization in situations that are similar to but different from their training reinforcement learning (RL). Combined with the recent progress environments. For agents to act appropriately in unknown of deep neural networks, RL has successfully trained human- level agents without human knowledge in many games such as situations, they need to properly generalize their policies that those for Atari 2600. However, it has been pointed out that agents they learned from the training environment. Generalization is trained with RL methods often overfit the training environment, also important in transfer learning, where the goal is to transfer and they work poorly in slightly different environments. To inves- a policy learned in a training environment to another similar tigate this problem, some research environments with procedural environment, called the target environment. We can use this content generation have been proposed. Following these studies, we propose the use of roguelikes as a benchmark for evaluating method to reduce the training time in many applications of the generalization ability of RL agents. In our Rogue-Gym, RL. For example, we can imagine a situation in which we agents need to explore dungeons that are structured differently train an enemy in an action game through experience across each time they start a new game. -

First Person Shooting (FPS) Game
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056 Volume: 05 Issue: 04 | Apr-2018 www.irjet.net p-ISSN: 2395-0072 Thunder Force - First Person Shooting (FPS) Game Swati Nadkarni1, Panjab Mane2, Prathamesh Raikar3, Saurabh Sawant4, Prasad Sawant5, Nitesh Kuwalekar6 1 Head of Department, Department of Information Technology, Shah & Anchor Kutchhi Engineering College 2 Assistant Professor, Department of Information Technology, Shah & Anchor Kutchhi Engineering College 3,4,5,6 B.E. student, Department of Information Technology, Shah & Anchor Kutchhi Engineering College ----------------------------------------------------------------***----------------------------------------------------------------- Abstract— It has been found in researches that there is an have challenged hardware development, and multiplayer association between playing first-person shooter video games gaming has been integral. First-person shooters are a type of and having superior mental flexibility. It was found that three-dimensional shooter game featuring a first-person people playing such games require a significantly shorter point of view with which the player sees the action through reaction time for switching between complex tasks, mainly the eyes of the player character. They are unlike third- because when playing fps games they require to rapidly react person shooters in which the player can see (usually from to fast moving visuals by developing a more responsive mind behind) the character they are controlling. The primary set and to shift back and forth between different sub-duties. design element is combat, mainly involving firearms. First person-shooter games are also of ten categorized as being The successful design of the FPS game with correct distinct from light gun shooters, a similar genre with a first- direction, attractive graphics and models will give the best person perspective which uses light gun peripherals, in experience to play the game. -

Weighing the Trade-Offs of a Direct Presence in Japan's Rare And
Special Report Weighing the Trade-offs of a Direct Presence in Japan’s Rare and Orphan Drug Market January 2020 Contents Summary ................................................................2 Background on increasing interest in Japan among rare and orphan biopharma companies ....................3 Attractive market fundamentals at the heart of the opportunity ............................................................4 Retaining control helps avoid poor partnering outcomes and entanglements ..................................6 The market is not without its challenges ...................7 A direct presence will not make business sense for everyone ............................................................. 10 Checklist for prospective Japan entrants ................. 11 Endnotes/About the Authors ................................. 12 About L.E.K. Consulting L.E.K. Consulting is a global management consulting firm that uses deep industry expertise and rigorous analysis to help business leaders achieve practical results with real impact. We are uncompromising in our approach to helping clients consistently make better decisions and deliver improved performance. The firm advises and supports organizations that are leaders in their sectors, including the largest private and public sector organizations, private equity firms, and emerging entrepreneurial businesses. Founded in 1983, L.E.K. employs more than 1,600 professionals across the Americas, Asia-Pacific and Europe. For more information, go to www.lek.com. 1 Summary Japan has long sought to foster an attractive market for orphan you consider the benefits of avoiding entanglement with a drugs, with specific provisions made to encourage the development partner and the challenges of managing relationships with of therapies for rare and orphan diseases as early as 1972.1 The potential licensing partners. measures and incentives that followed made the orphan and rare • But setting up a direct presence in Japan is not for model economically viable in Japan, yet companies operating in everyone. -

2006 2012 2013 2014 Introducing HALO® 2 Fused-Core®
Introducing HALO® 2 Fused-Core® UHPLC Columns From Advanced Materials Technology Rugged ∙ High Efficiency ∙ Low Back Pressure HALO 2 Fused-Core particles are designed to address the disadvantages inherent in existing sub-2 micron non-core UHPLC columns. HALO 2 UHPLC columns have all of the advantages of sub-2 µm non-core particle columns and will deliver 300,000 plates per meter efficiency (higher than existing non-core sub-2 µm columns). Manufactured with 1.0 µm frits on the column inlet, HALO 2 columns are less susceptible to column plugging. These columns can be used up to 1,000 bar (14,500 psi), but will actually produce ~20% lower back pressure than most commercially available sub-2 µm UHPLC columns under the same conditions. 1 Advantages of HALO 2 Fused-Core Columns vs. Sub-2 µm Non-core UHPLC Columns · Fused-Core UHPLC columns with ~300K plates per meter · All of the advantages of sub-2 µm non-core particles at lower - Higher efficiency than existing non-core sub-2 µm columns operating pressures · Longer column lifetime – more injections, less downtime - High speed and efficiency with short columns - Due to Fused-Core 2 micron particle architecture, 1 micron - Improved productivity from faster analyses frits can be used on the column inlet - Less solvent usage from shorter analysis times - 1 micron frits are less likely to be plugged by UHPLC samples - High resolution and peak capacity in longer columns or mobile phase contaminants than typical 0.2 – 0.5 µm - Sharper, taller peaks = better sensitivity and lower LOD frits on sub-2 -

Action Video-Game Training and Its Effects on Perception and Attentional Control
Action Video-Game Training and Its Effects on Perception and Attentional Control C. Shawn Green , Thomas Gorman , and Daphne Bavelier Introduction Over the past 40 years, video game play has grown from a niche activity into a pervasive and abundant part of modern life. Over half of the United States popula- tion now plays video games, with over 130 million of these individuals being con- sidered “regular” video game players (i.e., playing more than 3 h of video games per week—ESA 2015 ). And although video games were originally, and for the most part continue to be, an entertainment medium, there has nonetheless been signifi - cant scientifi c interest in the possibility that video gaming may have signifi cant effects on the human brain and human behavior . While much of this research has focused on potential negative outcomes (e.g., effects related to aggression or addic- tion—Anderson et al. 2010 ), there exists a growing body of research outlining posi- tive effects of video game play as well. This chapter will specifi cally focus on the positive impact that playing one particular type of video game, known as “action video games,” has on perceptual and attentional skills. The “ Curse of Specifi city” Before discussing the various effects associated with action video game play, it is worth considering why it is interesting in the fi rst place that something like video game play could alter core perceptual or attentional abilities. Indeed, one’s fi rst C. S. Green (*) • T. Gorman Department of Psychology , University of Wisconsin-Madison , Madison , WI , USA e-mail: [email protected]; [email protected] D. -

Game Enforcer Is Just a Group of People Providing You with Information and Telling You About the Latest Games
magazine you will see the coolest ads and Letter from The the most legit info articles you can ever find. Some of the ads include Xbox 360 skins Editor allowing you to customize your precious baby. Another ad is that there is an amazing Ever since I decided to do a magazine I ad on Assassins Creed Brotherhood and an already had an idea in my head and that idea amazing ad on Clash Of Clans. There is is video games. I always loved video games articles on a strategy game called Sid Meiers it gives me something to do it entertains me Civilization 5. My reason for this magazine and it allows me to think and focus on that is to give you fans of this magazine a chance only. Nowadays the best games are the ones to learn more about video games than any online ad can tell you and also its to give you a chance to see the new games coming out or what is starting to be making. Game Enforcer is just a group of people providing you with information and telling you about the latest games. We have great ads that we think you will enjoy and we hope you enjoy them so much you buy them and have fun like so many before. A lot of the games we with the best graphics and action. Everyone likes video games so I thought it would be good to make a magazine on video games. Every person who enjoys video games I expect to buy it and that is my goal get the most sales and the best ratings than any other video game magazine. -

Application of Retrograde Analysis on Fighting Games
Application of Retrograde Analysis on Fighting Games Kristen Yu Nathan R. Sturtevant Computer Science Department Computer Science Department University of Denver University of Alberta Denver, USA Edmonton, Canada [email protected] [email protected] Abstract—With the advent of the fighting game AI competition, optimal AI. This work opens the door for deeper study of there has been recent interest in two-player fighting games. both optimal and suboptimal play, as well as options related Monte-Carlo Tree-Search approaches currently dominate the to game design, where the impact of design choices in a game competition, but it is unclear if this is the best approach for all fighting games. In this paper we study the design of two- can be studied. player fighting games and the consequences of the game design on the types of AI that should be used for playing the game, as II.R ELATED WORK well as formally define the state space that fighting games are A variety of approaches have been used for fighting game AI based on. Additionally, we also characterize how AI can solve the in both industry and academia. One approach in industry has game given a simultaneous action game model, to understand the characteristics of the solved AI and the impact it has on game game AI being built using N-grams as a prediction algorithm design. to help the AI become better at playing the game [30]. Another common technique is using decision trees to model I.I NTRODUCTION AI behavior [30]. This creates a rule set with which an agent can react to decisions that a player makes. -

Law in the Virtual World: Should the Surreal World of Online Communities Be Brought Back to Earth by Real World Laws
Volume 16 Issue 1 Article 5 2009 Law in the Virtual World: Should the Surreal World of Online Communities be Brought Back to Earth by Real World Laws David Assalone Follow this and additional works at: https://digitalcommons.law.villanova.edu/mslj Part of the Entertainment, Arts, and Sports Law Commons, and the Internet Law Commons Recommended Citation David Assalone, Law in the Virtual World: Should the Surreal World of Online Communities be Brought Back to Earth by Real World Laws, 16 Jeffrey S. Moorad Sports L.J. 163 (2009). Available at: https://digitalcommons.law.villanova.edu/mslj/vol16/iss1/5 This Comment is brought to you for free and open access by Villanova University Charles Widger School of Law Digital Repository. It has been accepted for inclusion in Jeffrey S. Moorad Sports Law Journal by an authorized editor of Villanova University Charles Widger School of Law Digital Repository. Assalone: Law in the Virtual World: Should the Surreal World of Online Comm Comments LAW IN THE VIRTUAL WORLD: SHOULD THE SURREAL WORLD OF ONLINE COMMUNITIES BE BROUGHT BACK TO EARTH BY REAL WORLD LAWS?' I. INTRODUCTION In 2003, the world of online interaction changed forever with the advent of the online community of Second Life. 2 Prior to Sec- ond Life and other massive multiplayer online role-playing games ("MMORPGs"), online communications were primarily restricted to e-mail, instant messenger and chat rooms. 3 Though thousands of Internet users could, among other things, engage in online sales of goods at websites such as Amazon.com, no system gave users the ability to personally interact with one another.4 With game de- signer Linden Lab's introduction of Second Life, however, users now have an Internet platform through which they can truly com- municate on a face-to-face basis.5 The online virtual world of Sec- 1. -
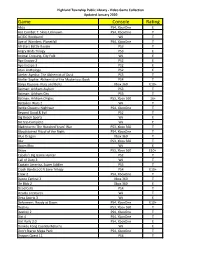
Game Console Rating
Highland Township Public Library - Video Game Collection Updated January 2020 Game Console Rating Abzu PS4, XboxOne E Ace Combat 7: Skies Unknown PS4, XboxOne T AC/DC Rockband Wii T Age of Wonders: Planetfall PS4, XboxOne T All-Stars Battle Royale PS3 T Angry Birds Trilogy PS3 E Animal Crossing, City Folk Wii E Ape Escape 2 PS2 E Ape Escape 3 PS2 E Atari Anthology PS2 E Atelier Ayesha: The Alchemist of Dusk PS3 T Atelier Sophie: Alchemist of the Mysterious Book PS4 T Banjo Kazooie- Nuts and Bolts Xbox 360 E10+ Batman: Arkham Asylum PS3 T Batman: Arkham City PS3 T Batman: Arkham Origins PS3, Xbox 360 16+ Battalion Wars 2 Wii T Battle Chasers: Nightwar PS4, XboxOne T Beyond Good & Evil PS2 T Big Beach Sports Wii E Bit Trip Complete Wii E Bladestorm: The Hundred Years' War PS3, Xbox 360 T Bloodstained Ritual of the Night PS4, XboxOne T Blue Dragon Xbox 360 T Blur PS3, Xbox 360 T Boom Blox Wii E Brave PS3, Xbox 360 E10+ Cabela's Big Game Hunter PS2 T Call of Duty 3 Wii T Captain America, Super Soldier PS3 T Crash Bandicoot N Sane Trilogy PS4 E10+ Crew 2 PS4, XboxOne T Dance Central 3 Xbox 360 T De Blob 2 Xbox 360 E Dead Cells PS4 T Deadly Creatures Wii T Deca Sports 3 Wii E Deformers: Ready at Dawn PS4, XboxOne E10+ Destiny PS3, Xbox 360 T Destiny 2 PS4, XboxOne T Dirt 4 PS4, XboxOne T Dirt Rally 2.0 PS4, XboxOne E Donkey Kong Country Returns Wii E Don't Starve Mega Pack PS4, XboxOne T Dragon Quest 11 PS4 T Highland Township Public Library - Video Game Collection Updated January 2020 Game Console Rating Dragon Quest Builders PS4 E10+ Dragon -

View the Manual
I NTROt>U(TION Get ready for the Epic Adventure of a lifetime. You are Hercules, battling through a series of action-packed levels in order to prove yourself a True Hero on Earth and take your rightful place as a god on Mount Olympus! However, before you can face your first monster, you'll have to convince Phil, Herc's temperamental trainer, that you've got what it takes to be a True Hero. Once you've sharpened your skills, rescued a few "Damsels in Distress:• and shown Phil you've got what it takes, you'll be ready to set offfor some REAL adventure! If you're able to make your way through the deadly Centaur Forest, survive the chaotic "Big Olive," and defeat the fearsome Hydra you'll think you've got this hero stuff wired! But that's just the beginning. Hades, dark lord of the Underworld, is carrying out his evil plan. He's enlisted the Titans - elemental creatures of Ice, Wind, Lava and Rock - as well as a monstrous brood of fire-breathing Griffins,razor beaked Harpies, and a whole army of Skeleton Warriors to help him. To foil Hades' plan Hercules is going to have to use every bit of his training, strength and skill. So guzzle some Herculade, sharpen your sword, and see if you have what it takes to go the distance, and become a TRUE HERO! NOTE: The default setting of this game is "Medium Difficulty". Beginning players might want to start on the "Beginner Difficulty" setting to practice, but just be aware that you will not be able to play the last two levels of the game . -

Game Engine Prepares for the Future by Optimizing
Success Story Intel® Software Partner Program Game Engine Prepares for the Gaming Focus Future by Optimizing for Multi-Core Intel® Processors The Intel® Software Partner Program guides The Game Creators toward the multi-core future for their FPS Creator X10* development environment. The Game Creators, based in Lancashire, United Kingdom, helps independent “DirectX* 10 lets games game developers cut down the time required to make new titles and reduce render hundreds of enemy characters, each with their the complexity of supporting the latest hardware. Intuitive, drag-and-drop own individual behaviors. interfaces automate otherwise-tedious details for the developer. While high- That kind of scenario is quality 3-D games can be created in this fashion without writing a line of incredibly CPU-intensive, code, the FPS Creator X10* product also provides the capability to modify so it’s critical to have very solid multi-threading built game elements by means of a simple scripting language. By building optimized into the engine.” support for the latest PC hardware into the platform, The Game Creators - Lee Bamber, CEO and FPS Creator relieves game developers from difficult tasks like multi-threading, which X10* Lead Engineer, The Game Creators allows them to focus on their games instead of performance details. Challenge: Prepare the FPS Creator* game- Meeting the needs of independent game developers development environment to create titles that take better advantage of FPS Creator X10* provides building blocks for assembling high-quality first-person shooter games without current and future generations of coding. Multi-threading within the platform enables the finished product to make good use of multiple PC hardware. -

Intersomatic Awareness in Game Design
The London School of Economics and Political Science Intersomatic Awareness in Game Design Siobhán Thomas A thesis submitted to the Department of Management of the London School of Economics for the degree of Doctor of Philosophy. London, June 2015 1 Declaration I certify that the thesis I have presented for examination for the PhD degree of the London School of Economics and Political Science is solely my own work. The copyright of this thesis rests with the author. Quotation from it is permitted, provided that full acknowledgement is made. This thesis may not be reproduced without my prior written consent. I warrant that this authorisation does not, to the best of my belief, infringe the rights of any third party. I declare that my thesis consists of 66,515 words. 2 Abstract The aim of this qualitative research study was to develop an understanding of the lived experiences of game designers from the particular vantage point of intersomatic awareness. Intersomatic awareness is an interbodily awareness based on the premise that the body of another is always understood through the body of the self. While the term intersomatics is related to intersubjectivity, intercoordination, and intercorporeality it has a specific focus on somatic relationships between lived bodies. This research examined game designers’ body-oriented design practices, finding that within design work the body is a ground of experiential knowledge which is largely untapped. To access this knowledge a hermeneutic methodology was employed. The thesis presents a functional model of intersomatic awareness comprised of four dimensions: sensory ordering, sensory intensification, somatic imprinting, and somatic marking.