Application of Retrograde Analysis to Fighting Games
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Rogue-Gym: a New Challenge for Generalization in Reinforcement Learning
Rogue-Gym: A New Challenge for Generalization in Reinforcement Learning Yuji Kanagawa Tomoyuki Kaneko Graduate School of Arts and Sciences Interfaculty Initiative in Information Studies The University of Tokyo The University of Tokyo Tokyo, Japan Tokyo, Japan [email protected] [email protected] Abstract—In this paper, we propose Rogue-Gym, a simple and or designated areas but need to perform safely in real world classic style roguelike game built for evaluating generalization in situations that are similar to but different from their training reinforcement learning (RL). Combined with the recent progress environments. For agents to act appropriately in unknown of deep neural networks, RL has successfully trained human- level agents without human knowledge in many games such as situations, they need to properly generalize their policies that those for Atari 2600. However, it has been pointed out that agents they learned from the training environment. Generalization is trained with RL methods often overfit the training environment, also important in transfer learning, where the goal is to transfer and they work poorly in slightly different environments. To inves- a policy learned in a training environment to another similar tigate this problem, some research environments with procedural environment, called the target environment. We can use this content generation have been proposed. Following these studies, we propose the use of roguelikes as a benchmark for evaluating method to reduce the training time in many applications of the generalization ability of RL agents. In our Rogue-Gym, RL. For example, we can imagine a situation in which we agents need to explore dungeons that are structured differently train an enemy in an action game through experience across each time they start a new game. -

The Development and Validation of the Game User Experience Satisfaction Scale (Guess)
THE DEVELOPMENT AND VALIDATION OF THE GAME USER EXPERIENCE SATISFACTION SCALE (GUESS) A Dissertation by Mikki Hoang Phan Master of Arts, Wichita State University, 2012 Bachelor of Arts, Wichita State University, 2008 Submitted to the Department of Psychology and the faculty of the Graduate School of Wichita State University in partial fulfillment of the requirements for the degree of Doctor of Philosophy May 2015 © Copyright 2015 by Mikki Phan All Rights Reserved THE DEVELOPMENT AND VALIDATION OF THE GAME USER EXPERIENCE SATISFACTION SCALE (GUESS) The following faculty members have examined the final copy of this dissertation for form and content, and recommend that it be accepted in partial fulfillment of the requirements for the degree of Doctor of Philosophy with a major in Psychology. _____________________________________ Barbara S. Chaparro, Committee Chair _____________________________________ Joseph Keebler, Committee Member _____________________________________ Jibo He, Committee Member _____________________________________ Darwin Dorr, Committee Member _____________________________________ Jodie Hertzog, Committee Member Accepted for the College of Liberal Arts and Sciences _____________________________________ Ronald Matson, Dean Accepted for the Graduate School _____________________________________ Abu S. Masud, Interim Dean iii DEDICATION To my parents for their love and support, and all that they have sacrificed so that my siblings and I can have a better future iv Video games open worlds. — Jon-Paul Dyson v ACKNOWLEDGEMENTS Althea Gibson once said, “No matter what accomplishments you make, somebody helped you.” Thus, completing this long and winding Ph.D. journey would not have been possible without a village of support and help. While words could not adequately sum up how thankful I am, I would like to start off by thanking my dissertation chair and advisor, Dr. -

First Person Shooting (FPS) Game
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056 Volume: 05 Issue: 04 | Apr-2018 www.irjet.net p-ISSN: 2395-0072 Thunder Force - First Person Shooting (FPS) Game Swati Nadkarni1, Panjab Mane2, Prathamesh Raikar3, Saurabh Sawant4, Prasad Sawant5, Nitesh Kuwalekar6 1 Head of Department, Department of Information Technology, Shah & Anchor Kutchhi Engineering College 2 Assistant Professor, Department of Information Technology, Shah & Anchor Kutchhi Engineering College 3,4,5,6 B.E. student, Department of Information Technology, Shah & Anchor Kutchhi Engineering College ----------------------------------------------------------------***----------------------------------------------------------------- Abstract— It has been found in researches that there is an have challenged hardware development, and multiplayer association between playing first-person shooter video games gaming has been integral. First-person shooters are a type of and having superior mental flexibility. It was found that three-dimensional shooter game featuring a first-person people playing such games require a significantly shorter point of view with which the player sees the action through reaction time for switching between complex tasks, mainly the eyes of the player character. They are unlike third- because when playing fps games they require to rapidly react person shooters in which the player can see (usually from to fast moving visuals by developing a more responsive mind behind) the character they are controlling. The primary set and to shift back and forth between different sub-duties. design element is combat, mainly involving firearms. First person-shooter games are also of ten categorized as being The successful design of the FPS game with correct distinct from light gun shooters, a similar genre with a first- direction, attractive graphics and models will give the best person perspective which uses light gun peripherals, in experience to play the game. -

The Will to Keep Winning Download Free (EPUB, PDF)
The Will To Keep Winning Download Free (EPUB, PDF) "No matter what your life plan is, no matter what your project, a close reading of the life and thoughts of Daigo will give you deep insight into how to be successful and help you reach your goals."—Frank Lantz, Director, NYU Game Center"When Daigo wins, he does not simply elevate his own status, he elevates the entire genre alongside him. Through his play, and through his approach to life, Daigo changes the way people think about the game, and inspires even his enemies to new heights. This is what separates a mere winner from an all-time great."—Seth Killian, Lead Game Designer at Riot Games"Daigo and I started an international journey to showcase Street Fighter competition in 1998. Today, he is the Grand Master of fighting games and true inspiration to players worldwide.â€â€”Alex Valle, CaliPower, Mr. Street Fighter“It’s almost impossible to overstate the significance of The Beast for the practice and culture of gaming; as Bruce Lee was for the Martial Arts, so Daigo Umehara is for Fighting Games.â€â€”Prof. Chris Goto-Jones, Professor of Comparative Philosophy & Political Thought, Leiden University"I’m a professional fighting gamer. I was first crowned World Champion at seventeen in 1998, and I was recognized as “the most successful player in major tournaments of Street Fighter†by Guinness World Records in August 2010.This is my chance to tell you how I became World Champion and share insights as only a multiple time World Champion can. -

Action Video-Game Training and Its Effects on Perception and Attentional Control
Action Video-Game Training and Its Effects on Perception and Attentional Control C. Shawn Green , Thomas Gorman , and Daphne Bavelier Introduction Over the past 40 years, video game play has grown from a niche activity into a pervasive and abundant part of modern life. Over half of the United States popula- tion now plays video games, with over 130 million of these individuals being con- sidered “regular” video game players (i.e., playing more than 3 h of video games per week—ESA 2015 ). And although video games were originally, and for the most part continue to be, an entertainment medium, there has nonetheless been signifi - cant scientifi c interest in the possibility that video gaming may have signifi cant effects on the human brain and human behavior . While much of this research has focused on potential negative outcomes (e.g., effects related to aggression or addic- tion—Anderson et al. 2010 ), there exists a growing body of research outlining posi- tive effects of video game play as well. This chapter will specifi cally focus on the positive impact that playing one particular type of video game, known as “action video games,” has on perceptual and attentional skills. The “ Curse of Specifi city” Before discussing the various effects associated with action video game play, it is worth considering why it is interesting in the fi rst place that something like video game play could alter core perceptual or attentional abilities. Indeed, one’s fi rst C. S. Green (*) • T. Gorman Department of Psychology , University of Wisconsin-Madison , Madison , WI , USA e-mail: [email protected]; [email protected] D. -

Download the Catalog
WE SERVE BUSINESSES OF ALL SIZES WHO WE ARE We are an ambitious laser tag design and manufacturing company with a passion for changing the way people EXPERIENCE LIVE-COMBAT GAMING. We PROVIDE MANUFACTURING and support to businesses both big or small, around the world! With fresh thinking and INNOVATIVE GAMING concepts, our reputation has made us a leader in the live-action gaming space. One of the hallmarks of our approach to DESIGN & manufacturing is equipment versatility. Whether operating an indoor arena, outdoor battleground, mobile business, or a special entertainment OUR PRODUCTS HAVE THE HIGHEST REPLAY attraction our equipment can be CUSTOMIZED TO FIT your needs. Battle Company systems will expand your income opportunities and offer possibilities where the rest of the industry can only provide VALUE IN THE LASER TAG INDUSTRY limitations. Our products are DESIGNED AND TESTED at our 13-acre property headquarters. We’ve put the equipment into action in our 5,000 square-foot indoor laser tag facility as well as our newly constructed outdoor battlefield. This is to ensure the highest level of design quality across the different types of environments where laser tag is played. Using Agile development methodology and manufacturing that is ISO 9001 CERTIFIED, we are the fastest manufacturer in the industry when it comes to bringing new products and software to market. Battle Company equipment has a strong competitive advantage over other brands and our COMMITMENT TO R&D is the reason why we are leading the evolution of the laser tag industry! 3 OUT OF 4 PLAYERS WHO USE BATTLE COMPANY BUSINESSES THAT CHOOSE US TO POWER THEIR EXPERIENCE EQUIPMENT RETURN TO PLAY AGAIN! WE SERVE THE MILITARY 3 BIG ATTRACTION SMALL FOOTPRINT Have a 10ft x 12.5ft space not making your facility much money? Remove the clutter and fill that area with the Battle Cage. -

Application of Retrograde Analysis on Fighting Games
Application of Retrograde Analysis on Fighting Games Kristen Yu Nathan R. Sturtevant Computer Science Department Computer Science Department University of Denver University of Alberta Denver, USA Edmonton, Canada [email protected] [email protected] Abstract—With the advent of the fighting game AI competition, optimal AI. This work opens the door for deeper study of there has been recent interest in two-player fighting games. both optimal and suboptimal play, as well as options related Monte-Carlo Tree-Search approaches currently dominate the to game design, where the impact of design choices in a game competition, but it is unclear if this is the best approach for all fighting games. In this paper we study the design of two- can be studied. player fighting games and the consequences of the game design on the types of AI that should be used for playing the game, as II.R ELATED WORK well as formally define the state space that fighting games are A variety of approaches have been used for fighting game AI based on. Additionally, we also characterize how AI can solve the in both industry and academia. One approach in industry has game given a simultaneous action game model, to understand the characteristics of the solved AI and the impact it has on game game AI being built using N-grams as a prediction algorithm design. to help the AI become better at playing the game [30]. Another common technique is using decision trees to model I.I NTRODUCTION AI behavior [30]. This creates a rule set with which an agent can react to decisions that a player makes. -

Fighting Games, Performativity, and Social Game Play a Dissertation
The Art of War: Fighting Games, Performativity, and Social Game Play A dissertation presented to the faculty of the Scripps College of Communication of Ohio University In partial fulfillment of the requirements for the degree Doctor of Philosophy Todd L. Harper November 2010 © 2010 Todd L. Harper. All Rights Reserved. This dissertation titled The Art of War: Fighting Games, Performativity, and Social Game Play by TODD L. HARPER has been approved for the School of Media Arts and Studies and the Scripps College of Communication by Mia L. Consalvo Associate Professor of Media Arts and Studies Gregory J. Shepherd Dean, Scripps College of Communication ii ABSTRACT HARPER, TODD L., Ph.D., November 2010, Mass Communications The Art of War: Fighting Games, Performativity, and Social Game Play (244 pp.) Director of Dissertation: Mia L. Consalvo This dissertation draws on feminist theory – specifically, performance and performativity – to explore how digital game players construct the game experience and social play. Scholarship in game studies has established the formal aspects of a game as being a combination of its rules and the fiction or narrative that contextualizes those rules. The question remains, how do the ways people play games influence what makes up a game, and how those players understand themselves as players and as social actors through the gaming experience? Taking a qualitative approach, this study explored players of fighting games: competitive games of one-on-one combat. Specifically, it combined observations at the Evolution fighting game tournament in July, 2009 and in-depth interviews with fighting game enthusiasts. In addition, three groups of college students with varying histories and experiences with games were observed playing both competitive and cooperative games together. -

Deepcrawl: Deep Reinforcement Learning for Turn-Based Strategy Games
DeepCrawl: Deep Reinforcement Learning for Turn-based Strategy Games Alessandro Sestini,1 Alexander Kuhnle,2 Andrew D. Bagdanov1 1Dipartimento di Ingegneria dell’Informazione, Universita` degli Studi di Firenze, Florence, Italy 2Department of Computer Science and Technology, University of Cambridge, United Kingdom falessandro.sestini, andrew.bagdanovg@unifi.it Abstract super-human skills able to solve a variety of environments. However the main objective of DRL of this type is training In this paper we introduce DeepCrawl, a fully-playable Rogue- like prototype for iOS and Android in which all agents are con- agents to surpass human players in competitive play in clas- trolled by policy networks trained using Deep Reinforcement sical games like Go (Silver et al. 2016) and video games Learning (DRL). Our aim is to understand whether recent ad- like DOTA 2 (OpenAI 2019). The resulting, however, agents vances in DRL can be used to develop convincing behavioral clearly run the risk of being too strong, of exhibiting artificial models for non-player characters in videogames. We begin behavior, and in the end not being a fun gameplay element. with an analysis of requirements that such an AI system should Video games have become an integral part of our entertain- satisfy in order to be practically applicable in video game de- ment experience, and our goal in this work is to demonstrate velopment, and identify the elements of the DRL model used that DRL techniques can be used as an effective game design in the DeepCrawl prototype. The successes and limitations tool for learning compelling and convincing NPC behaviors of DeepCrawl are documented through a series of playability tests performed on the final game. -

View the Manual
I NTROt>U(TION Get ready for the Epic Adventure of a lifetime. You are Hercules, battling through a series of action-packed levels in order to prove yourself a True Hero on Earth and take your rightful place as a god on Mount Olympus! However, before you can face your first monster, you'll have to convince Phil, Herc's temperamental trainer, that you've got what it takes to be a True Hero. Once you've sharpened your skills, rescued a few "Damsels in Distress:• and shown Phil you've got what it takes, you'll be ready to set offfor some REAL adventure! If you're able to make your way through the deadly Centaur Forest, survive the chaotic "Big Olive," and defeat the fearsome Hydra you'll think you've got this hero stuff wired! But that's just the beginning. Hades, dark lord of the Underworld, is carrying out his evil plan. He's enlisted the Titans - elemental creatures of Ice, Wind, Lava and Rock - as well as a monstrous brood of fire-breathing Griffins,razor beaked Harpies, and a whole army of Skeleton Warriors to help him. To foil Hades' plan Hercules is going to have to use every bit of his training, strength and skill. So guzzle some Herculade, sharpen your sword, and see if you have what it takes to go the distance, and become a TRUE HERO! NOTE: The default setting of this game is "Medium Difficulty". Beginning players might want to start on the "Beginner Difficulty" setting to practice, but just be aware that you will not be able to play the last two levels of the game . -

REGAIN CONTROL, in the SUPERNATURAL ACTION-ADVENTURE GAME from REMEDY ENTERTAINMENT and 505 GAMES, COMING in 2019 World Premiere
REGAIN CONTROL, IN THE SUPERNATURAL ACTION-ADVENTURE GAME FROM REMEDY ENTERTAINMENT AND 505 GAMES, COMING IN 2019 World Premiere Trailer for Remedy’s “Most Ambitious Game Yet” Revealed at Sony E3 Conference Showcases Complex Sandbox-Style World CALABASAS, Calif. – June 11, 2018 – Internationally renowned developer Remedy Entertainment, Plc., along with its publishing partner 505 Games, have unveiled their highly anticipated game, previously known only by its codename, “P7.” From the creators of Max Payne and Alan Wake comes Control, a third-person action-adventure game combining Remedy’s trademark gunplay with supernatural abilities. Revealed for the first time at the official Sony PlayStation E3 media briefing in the worldwide exclusive debut of the first trailer, Control is set in a unique and ever-changing world that juxtaposes our familiar reality with the strange and unexplainable. Welcome to the Federal Bureau of Control: https://youtu.be/8ZrV2n9oHb4 After a secretive agency in New York is invaded by an otherworldly threat, players will take on the role of Jesse Faden, the new Director struggling to regain Control. This sandbox-style, gameplay- driven experience built on the proprietary Northlight engine challenges players to master a combination of supernatural abilities, modifiable loadouts and reactive environments while fighting through the deep and mysterious worlds Remedy is known and loved for. “Control represents a new exciting chapter for us, it redefines what a Remedy game is. It shows off our unique ability to build compelling worlds while providing a new player-driven way to experience them,” said Mikael Kasurinen, game director of Control. “A key focus for Remedy has been to provide more agency through gameplay and allow our audience to experience the story of the world at their own pace” “From our first meetings with Remedy we’ve been inspired by the vision and scope of Control, and we are proud to help them bring this game to life and get it into the hands of players,” said Neil Ralley, president of 505 Games. -
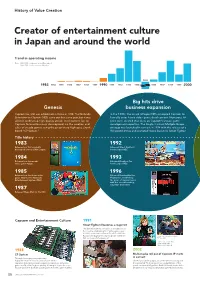
History of Value Creation
History of Value Creation Creator of entertainment culture in Japan and around the world Trend in operating income Note: 1983–1988: Fiscal years ended December 31 1989–2020: Fiscal years ended March 31 1995 1983 1984 1985 1986 1987 1988 1989 1990 1991 1992 1993 1994 1996 1997 1998 1999 2000 Big hits drive Genesis business expansion Capcom Co., Ltd. was established in Osaka in 1983. The Nintendo In the 1990s, the arrival of Super NES prompted Capcom to Entertainment System (NES) came out that same year, but it was formally enter home video game development. Numerous hit difficult to develop high-quality arcade-level content for, so titles were created that drew on Capcom’s arcade game Capcom focused business development on the creation and development expertise. The Single Content Multiple Usage sales of arcade games using the proprietary high-spec circuit strategy was launched in earnest in 1994 with the release of a board “CP System.” Hollywood movie and animated movie based on Street Fighter. Title history 1983 1992 Released our first originally Released Street Fighter II developed coin-op Little League. for the Super NES. 1984 1993 Released our first arcade Released Breath of Fire video game Vulgus. for the Super NES. 1985 1996 Released our first home video Released Resident Evil for game 1942 for the Nintendo PlayStation, establishing Entertainment System (NES). the genre of survival horror with this record-breaking, long-time best-seller. 1987 Released Mega Man for the NES. Capcom and Entertainment Culture 1991 Street Fighter II becomes a major hit The game became a sensation in arcades across the country, establishing the fighting game genre.