The Development of Graphic Representation in Abugida Writing: the Akshara’S Grammar
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

BIBLIOGRAPHY N Most Diacritic Letters ( C, I, Ö, ˙ S, Etc.) Are
BIBLIOGRAPHY Notes Most diacritic letters (ˇc,ı, ö, s, etc.) are alphabetized as separate letters after ˙ the base letter. The abbreviation “ms. NAN KR” stands for “manuscript in the Archives of the National Center for Manasology and Artistic Culture of the National Academy of Sciences of the Kyrgyz Republic,” followed by the archival shelf number. In the Commentary and footnotes, the form of some of the bibliographic citations of mid-nineteenth century Kirghiz epics (recorded by Radlof from anonymous bards, published under separate headings in his Obraztsy/ Proben [1885], and re-edited by Hatto in The Manas of Wilhelm Radlof [1990]) is nearly identical to the citations of analytical articles on the texts that Hatto published in various journals. These are the references to the Radlovian epic texts, which were coincidentally published by Hatto in his re-edition: “Almambet, Er Kökˇcöand Ak-Erkeˇc”;“Birth of Manas”; “Birth of Semetey”; “Bok-Murun”; “Köz-Kaman”; and “Semetey.” Hatto’s articles are cited as: Hatto, “Almambet, Er Kökˇcöand Ak Erkeˇc”;Hatto, “Birth of Manas”; Hatto, “Köz-Kaman”; Hatto, “Semetey.” Listed below by language are references to the main bibliographic entries of the dictionaries, grammars, and other aids used, sometimes without citation, in the preparation of this edition: Arabic Baranov, Arabsko–russkii slovar’ Steingass, A Learner’s Arabic–English Dictionary Baˇskir Akhmerov, Bashkirsko–russkii slovar’ Chaghatay Budagov, Sravnitel’nyi slovar’ turetsko–tatarskikh narechii Shcherbak, Grammatika starouzbekskogo iazyka Radlov, Opyt/Versuch Eastern Turki Jarring, An Eastern Turki–English Dialect Dictionary (Uyghur) Nadzhip, Uigursko–russkii slovar’ Kalmyk Ramstedt, Kalmückisches Wörterbuch Kirghiz Batmanov, Sovremennyi kirgizskii iazyk Hu and Imart, A Kirghiz Reader Imart, Le kirghiz Iudakhin, Kirgizsko–russkii slovar’ ———, Russko–kirgizskii slovar’ 374 bibliography Kirghiz (cont.) Muqambaev, Qır ˙gıztilinin dialektologiyalıq sözdügü, vol. -

Similarities and Dissimilarities of English and Arabic Alphabets in Phonetic and Phonology: a Comparative Study
Similarities and dissimilarities of English and Arabic 94 Similarities and dissimilarities of English and Arabic Alphabets in Phonetic and Phonology: A Comparative Study MD YEAQUB Research Scholar Aligarh Muslim University, India Email: [email protected] Abstract: This paper will focus on a comparative study about similarities and dissimilarities of the pronunciation between the syllables of English and Arabic with the help of phonetic and phonological tools i.e. manner of articulation, point of articulation and their distribution at different positions in English and Arabic Alphabets. A phonetic and phonological analysis of the alphabets of English and Arabic can be useful in overcoming the hindrances for those want to improve the pronunciation of both English and Arabic languages. We all know that Arabic is a Semitic language from the Afro-Asiatic Language Family. On the other hand, English is a West Germanic language from the Indo- European Language Family. Both languages show many linguistic differences at all levels of linguistic analysis, i.e. phonology, morphology, syntax, semantics, etc. For this we will take into consideration, the segmental features only, i.e. the consonant and vowel system of the two languages. So, this is better and larger to bring about pedagogical changes that can go a long way in improving pronunciation and ensuring the occurrence of desirable learners’ outcomes. Keywords: Arabic Alphabets, English Alphabets, Pronunciations, Phonetics, Phonology, manner of articulation, point of articulation. Introduction: We all know that sounds are generally divided into two i.e. consonants and vowels. A consonant is a speech sound, which obstruct the flow of air through the vocal tract. -

Grammatica Et Verba Glamor and Verve
“GippertOVprint” — 2014/4/24 — 22:14 — page 81 —#1 Grammatica et verba Glamor and verve Studies in South Asian, historical, and Indo-European linguistics in honor of Hans Henrich Hock on the occasion of his seventy-fifth birthday edited by Shu-Fen Chen and Benjamin Slade Beech Stave Press Ann Arbor New York • “GippertOVprint” — 2014/4/24 — 22:14 — page 82 —#2 © Beech Stave Press, Inc. All rights reserved. No part of this publication may be reproduced, translated, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording or otherwise, without prior written permission from the publisher. Typeset with LATEX using the Galliard typeface designed by Matthew Carter and Greek Old Face by Ralph Hancock. The typeface on the cover is Post Hock by Steve Peter. Library of Congress Cataloging-in-Publication Data Grammatica et verba : glamor and verve : studies in South Asian, historical, and Indo- European linguistics in honor of Hans Henrich Hock on the occasion of his seventy- fifth birthday / edited by Shu-Fen Chen and Benjamin Slade. pages cm Includes bibliographical references. ISBN ---- (alk. paper) . Indo-European languages. Lexicography. Historical linguistics. I. Hock, Hans Henrich, - honoree. II. Chen, Shu-Fen, editor of compilation. III. Slade, Ben- jamin, editor of compilation. –dc Printed in the United States of America “GippertOVprint” — 2014/4/24 — 22:14 — page 83 —#3 TableHHHHHH ofHHHHHHHHHHHHHHH ContentsHHHHHHHHHHHH Preface . vii Bibliography of Hans Henrich Hock . ix List of Contributors . xxi , Traces of Archaic Human Language Structure Anvita Abbi in the Great Andamanese Language. , A Study of Punctuation Errors in the Chinese Diamond Sutra Shu-Fen Chen Based on Sanskrit Texts . -

The Festvox Indic Frontend for Grapheme-To-Phoneme Conversion
The Festvox Indic Frontend for Grapheme-to-Phoneme Conversion Alok Parlikar, Sunayana Sitaram, Andrew Wilkinson and Alan W Black Carnegie Mellon University Pittsburgh, USA aup, ssitaram, aewilkin, [email protected] Abstract Text-to-Speech (TTS) systems convert text into phonetic pronunciations which are then processed by Acoustic Models. TTS frontends typically include text processing, lexical lookup and Grapheme-to-Phoneme (g2p) conversion stages. This paper describes the design and implementation of the Indic frontend, which provides explicit support for many major Indian languages, along with a unified framework with easy extensibility for other Indian languages. The Indic frontend handles many phenomena common to Indian languages such as schwa deletion, contextual nasalization, and voicing. It also handles multi-script synthesis between various Indian-language scripts and English. We describe experiments comparing the quality of TTS systems built using the Indic frontend to grapheme-based systems. While this frontend was designed keeping TTS in mind, it can also be used as a general g2p system for Automatic Speech Recognition. Keywords: speech synthesis, Indian language resources, pronunciation 1. Introduction in models of the spectrum and the prosody. Another prob- lem with this approach is that since each grapheme maps Intelligible and natural-sounding Text-to-Speech to a single “phoneme” in all contexts, this technique does (TTS) systems exist for a number of languages of the world not work well in the case of languages that have pronun- today. However, for low-resource, high-population lan- ciation ambiguities. We refer to this technique as “Raw guages, such as languages of the Indian subcontinent, there Graphemes.” are very few high-quality TTS systems available. -

ISO Basic Latin Alphabet
ISO basic Latin alphabet The ISO basic Latin alphabet is a Latin-script alphabet and consists of two sets of 26 letters, codified in[1] various national and international standards and used widely in international communication. The two sets contain the following 26 letters each:[1][2] ISO basic Latin alphabet Uppercase Latin A B C D E F G H I J K L M N O P Q R S T U V W X Y Z alphabet Lowercase Latin a b c d e f g h i j k l m n o p q r s t u v w x y z alphabet Contents History Terminology Name for Unicode block that contains all letters Names for the two subsets Names for the letters Timeline for encoding standards Timeline for widely used computer codes supporting the alphabet Representation Usage Alphabets containing the same set of letters Column numbering See also References History By the 1960s it became apparent to thecomputer and telecommunications industries in the First World that a non-proprietary method of encoding characters was needed. The International Organization for Standardization (ISO) encapsulated the Latin script in their (ISO/IEC 646) 7-bit character-encoding standard. To achieve widespread acceptance, this encapsulation was based on popular usage. The standard was based on the already published American Standard Code for Information Interchange, better known as ASCII, which included in the character set the 26 × 2 letters of the English alphabet. Later standards issued by the ISO, for example ISO/IEC 8859 (8-bit character encoding) and ISO/IEC 10646 (Unicode Latin), have continued to define the 26 × 2 letters of the English alphabet as the basic Latin script with extensions to handle other letters in other languages.[1] Terminology Name for Unicode block that contains all letters The Unicode block that contains the alphabet is called "C0 Controls and Basic Latin". -

Schwa Deletion: Investigating Improved Approach for Text-To-IPA System for Shiri Guru Granth Sahib
ISSN (Online) 2278-1021 ISSN (Print) 2319-5940 International Journal of Advanced Research in Computer and Communication Engineering Vol. 4, Issue 4, April 2015 Schwa Deletion: Investigating Improved Approach for Text-to-IPA System for Shiri Guru Granth Sahib Sandeep Kaur1, Dr. Amitoj Singh2 Pursuing M.E, CSE, Chitkara University, India 1 Associate Director, CSE, Chitkara University , India 2 Abstract: Punjabi (Omniglot) is an interesting language for more than one reasons. This is the only living Indo- Europen language which is a fully tonal language. Punjabi language is an abugida writing system, with each consonant having an inherent vowel, SCHWA sound. This sound is modifiable using vowel symbols attached to consonant bearing the vowel. Shri Guru Granth Sahib is a voluminous text of 1430 pages with 511,874 words, 1,720,345 characters, and 28,534 lines and contains hymns of 36 composers written in twenty-two languages in Gurmukhi script (Lal). In addition to text being in form of hymns and coming from so many composers belonging to different languages, what makes the language of Shri Guru Granth Sahib even more different from contemporary Punjabi. The task of developing an accurate Letter-to-Sound system is made difficult due to two further reasons: 1. Punjabi being the only tonal language 2. Historical and Cultural circumstance/period of writings in terms of historical and religious nature of text and use of words from multiple languages and non-native phonemes. The handling of schwa deletion is of great concern for development of accurate/ near perfect system, the presented work intend to report the state-of-the-art in terms of schwa deletion for Indian languages, in general and for Gurmukhi Punjabi, in particular. -
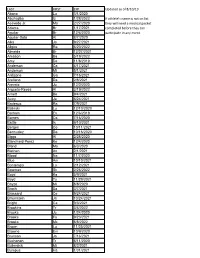
LAST FIRST EXP Updated As of 8/10/19 Abano Lu 3/1/2020 Abuhadba Iz 1/28/2022 If Athlete's Name Is Not on List Acevedo Jr
LAST FIRST EXP Updated as of 8/10/19 Abano Lu 3/1/2020 Abuhadba Iz 1/28/2022 If athlete's name is not on list Acevedo Jr. Ma 2/27/2020 they will need a medical packet Adams Br 1/17/2021 completed before they can Aguilar Br 12/6/2020 participate in any event. Aguilar-Soto Al 8/7/2020 Alka Ja 9/27/2021 Allgire Ra 6/20/2022 Almeida Br 12/27/2021 Amason Ba 5/19/2022 Amy De 11/8/2019 Anderson Ca 4/17/2021 Anderson Mi 5/1/2021 Ardizone Ga 7/16/2021 Arellano Da 2/8/2021 Arevalo Ju 12/2/2020 Argueta-Reyes Al 3/19/2022 Arnett Be 9/4/2021 Autry Ja 6/24/2021 Badeaux Ra 7/9/2021 Balinski Lu 12/10/2020 Barham Ev 12/6/2019 Barnes Ca 7/16/2020 Battle Is 9/10/2021 Bergen Co 10/11/2021 Bermudez Da 10/16/2020 Biggs Al 2/28/2020 Blanchard-Perez Ke 12/4/2020 Bland Ma 6/3/2020 Blethen An 2/1/2021 Blood Na 11/7/2020 Blue Am 10/10/2021 Bontempo Lo 2/12/2021 Bowman Sk 2/26/2022 Boyd Ka 5/9/2021 Boyd Ty 11/29/2021 Boyzo Mi 8/8/2020 Brach Sa 3/7/2021 Brassard Ce 9/24/2021 Braunstein Ja 10/24/2021 Bright Ca 9/3/2021 Brookins Tr 3/4/2022 Brooks Ju 1/24/2020 Brooks Fa 9/23/2021 Brooks Mc 8/8/2022 Brown Lu 11/25/2021 Browne Em 10/9/2020 Brunson Jo 7/16/2021 Buchanan Tr 6/11/2020 Bullerdick Mi 8/2/2021 Bumpus Ha 1/31/2021 LAST FIRST EXP Updated as of 8/10/19 Burch Co 11/7/2020 Burch Ma 9/9/2021 Butler Ga 5/14/2022 Byers Je 6/14/2021 Cain Me 6/20/2021 Cao Tr 11/19/2020 Carlson Be 5/29/2021 Cerda Da 3/9/2021 Ceruto Ri 2/14/2022 Chang Ia 2/19/2021 Channapati Di 10/31/2021 Chao Et 8/20/2021 Chase Em 8/26/2020 Chavez Fr 6/13/2020 Chavez Vi 11/14/2021 Chidambaram Ga 10/13/2019 -

Early-Alphabets-3.Pdf
Early Alphabets Alphabetic characteristics 1 Cretan Pictographs 11 Hieroglyphics 16 The Phoenician Alphabet 24 The Greek Alphabet 31 The Latin Alphabet 39 Summary 53 GDT-101 / HISTORY OF GRAPHIC DESIGN / EARLY ALPHABETS 1 / 53 Alphabetic characteristics 3,000 BCE Basic building blocks of written language GDT-101 / HISTORY OF GRAPHIC DESIGN / EARLY ALPHABETS / Alphabetic Characteristics 2 / 53 Early visual language systems were disparate and decentralized 3,000 BCE Protowriting, Cuneiform, Heiroglyphs and far Eastern writing all functioned differently Rebuses, ideographs, logograms, and syllabaries · GDT-101 / HISTORY OF GRAPHIC DESIGN / EARLY ALPHABETS / Alphabetic Characteristics 3 / 53 HIEROGLYPHICS REPRESENTING THE REBUS PRINCIPAL · BEE & LEAF · SEA & SUN · BELIEF AND SEASON GDT-101 / HISTORY OF GRAPHIC DESIGN / EARLY ALPHABETS / Alphabetic Characteristics 4 / 53 PETROGLYPHIC PICTOGRAMS AND IDEOGRAPHS · CIRCA 200 BCE · UTAH, UNITED STATES GDT-101 / HISTORY OF GRAPHIC DESIGN / EARLY ALPHABETS / Alphabetic Characteristics 5 / 53 LUWIAN LOGOGRAMS · CIRCA 1400 AND 1200 BCE · TURKEY GDT-101 / HISTORY OF GRAPHIC DESIGN / EARLY ALPHABETS / Alphabetic Characteristics 6 / 53 OLD PERSIAN SYLLABARY · 600 BCE GDT-101 / HISTORY OF GRAPHIC DESIGN / EARLY ALPHABETS / Alphabetic Characteristics 7 / 53 Alphabetic structure marked an enormous societal leap 3,000 BCE Power was reserved for those who could read and write · GDT-101 / HISTORY OF GRAPHIC DESIGN / EARLY ALPHABETS / Alphabetic Characteristics 8 / 53 What is an alphabet? Definition An alphabet is a set of visual symbols or characters used to represent the elementary sounds of a spoken language. –PM · GDT-101 / HISTORY OF GRAPHIC DESIGN / EARLY ALPHABETS / Alphabetic Characteristics 9 / 53 What is an alphabet? Definition They can be connected and combined to make visual configurations signifying sounds, syllables, and words uttered by the human mouth. -

2020 Language Need and Interpreter Use Study, As Required Under Chair, Executive and Planning Committee Government Code Section 68563 HON
JUDICIAL COUNCIL OF CALIFORNIA 455 Golden Gate Avenue May 15, 2020 San Francisco, CA 94102-3688 Tel 415-865-4200 TDD 415-865-4272 Fax 415-865-4205 www.courts.ca.gov Hon. Gavin Newsom Governor of California HON. TANI G. CANTIL- SAKAUYE State Capitol, First Floor Chief Justice of California Chair of the Judicial Council Sacramento, California 95814 HON. MARSHA G. SLOUGH Re: 2020 Language Need and Interpreter Use Study, as required under Chair, Executive and Planning Committee Government Code section 68563 HON. DAVID M. RUBIN Chair, Judicial Branch Budget Committee Chair, Litigation Management Committee Dear Governor Newsom: HON. MARLA O. ANDERSON Attached is the Judicial Council report required under Government Code Chair, Legislation Committee section 68563, which requires the Judicial Council to conduct a study HON. HARRY E. HULL, JR. every five years on language need and interpreter use in the California Chair, Rules Committee trial courts. HON. KYLE S. BRODIE Chair, Technology Committee The study was conducted by the Judicial Council’s Language Access Hon. Richard Bloom Services and covers the period from fiscal years 2014–15 through 2017–18. Hon. C. Todd Bottke Hon. Stacy Boulware Eurie Hon. Ming W. Chin If you have any questions related to this report, please contact Mr. Douglas Hon. Jonathan B. Conklin Hon. Samuel K. Feng Denton, Principal Manager, Language Access Services, at 415-865-7870 or Hon. Brad R. Hill Ms. Rachel W. Hill [email protected]. Hon. Harold W. Hopp Hon. Hannah-Beth Jackson Mr. Patrick M. Kelly Sincerely, Hon. Dalila C. Lyons Ms. Gretchen Nelson Mr. -

RELG 357D1 Sanskrit 2, Fall 2020 Syllabus
RELG 357D1: Sanskrit 2 Fall 2020 McGill University School of Religious Studies Tuesdays & Thursdays, 10:05 – 11:25 am Instructor: Hamsa Stainton Email: [email protected] Office hours: by appointment via phone or Zoom Note: Due to COVID-19, this course will be offered remotely via synchronous Zoom class meetings at the scheduled time. If students have any concerns about accessibility or equity please do not hesitate to contact me directly. Overview This is a Sanskrit reading course in which intermediate Sanskrit students will prepare translations of Sanskrit texts and present them in class. While the course will review Sanskrit grammar when necessary, it presumes students have already completed an introduction to Sanskrit grammar. Readings: All readings will be made available on myCourses. If you ever have any issues accessing the readings, or there are problems with a PDF, please let me know immediately. You may also wish to purchase or borrow a hard copy of Charles Lanman’s A Sanskrit Reader (1884) for ease of reference, but the ebook will be on myCourses. The exact reading on a given day will depend on how far we progressed in the previous class. For the first half of the course, we will be reading selections from the Lanman’s Sanskrit Reader, and in the second half of the course we will read from the Bhagavadgītā. Assessment and grading: Attendance: 20% Class participation based on prepared translations: 20% Test #1: 25% Test #2: 35% For attendance and class participation, students are expected to have prepared translations of the relevant Sanskrit text. -

Review of Research
Review Of ReseaRch impact factOR : 5.7631(Uif) UGc appROved JOURnal nO. 48514 issn: 2249-894X vOlUme - 8 | issUe - 7 | apRil - 2019 __________________________________________________________________________________________________________________________ AN ANALYSIS OF CURRENT TRENDS FOR SANSKRIT AS A COMPUTER PROGRAMMING LANGUAGE Manish Tiwari1 and S. Snehlata2 1Department of Computer Science and Application, St. Aloysius College, Jabalpur. 2Student, Deparment of Computer Science and Application, St. Aloysius College, Jabalpur. ABSTRACT : Sanskrit is said to be one of the systematic language with few exception and clear rules discretion.The discussion is continued from last thirtythat language could be one of best option for computers.Sanskrit is logical and clear about its grammatical and phonetically laws, which are not amended from thousands of years. Entire Sanskrit grammar is based on only fourteen sutras called Maheshwar (Siva) sutra, Trimuni (Panini, Katyayan and Patanjali) are responsible for creation,explainable and exploration of these grammar laws.Computer as machine,requires such language to perform better and faster with less programming.Sanskrit can play important role make computer programming language flexible, logical and compact. This paper is focused on analysis of current status of research done on Sanskrit as a programming languagefor .These will the help us to knowopportunity, scope and challenges. KEYWORDS : Artificial intelligence, Natural language processing, Sanskrit, Computer, Vibhakti, Programming language. -

The Original Pronunciation of Sanskrit Devanàgará – Transliteration – IPA-Symbols
The Original Pronunciation of Sanskrit DevanÀgarÁ – Transliteration – IPA-Symbols $ a n$D À DØ i L Á LØ u X A Â XØ ? Ã `C C Å `CØ CØ Æ O C # e HØ #H ai DeØ, $DH o RØ $D( au DØe8 N{ k N R kh N+ J g J gh J+ Ç 1 F c WeÝ ' ch WeÝ+ M j GeÛ + jh GeÛ+ _ È × T Ê Þ 4 Êh Þ+ I Ë É ) Ëh É+ > É Ö W t W Z th W+ G{ d G [ dh G+ Q n Q S p S { ph S+ E b E bh E+ P m P \ y M U{ r `O l O Y v Y9 ] Ì Ý Í V s V K h Ù Drafted by Maciej Zieba and Ulrich Stiehl under the auspices of Manfred Mayrhofer. ! Ï [ Improvements by Jost Gippert, Madhav Deshpande, Sunder Hattangadi, John Smith and others. This chart is a compromise, since the original pronunciation of Sanskrit Î YDULRXV is not exactly known in every detail. – 06/09/2002/us. Notes: 1. $ seems to have been pronounced originally as [n] or as [], possibly never as [D]. Not even the pronunciation of this most often used letter $ is exactly known! 2. The original pronunciation of is not known. It occurs only in the verb dS(kÆp). 3. U{seems to have been pronounced as [`] or as [], and likewise the liquid seems to have been pronounced as syllabic [`C] (notation: [`]+ [ C]) or as syllabic [C]. 4. The pronunciation of the semi-vowel Y seems to have been either [Y] or [9].