Proceedings of the Twenty-Third Midwest Artificial Intelligence and Cognitive Science Conference
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Discover Linear Algebra Incomplete Preliminary Draft
Discover Linear Algebra Incomplete Preliminary Draft Date: November 28, 2017 L´aszl´oBabai in collaboration with Noah Halford All rights reserved. Approved for instructional use only. Commercial distribution prohibited. c 2016 L´aszl´oBabai. Last updated: November 10, 2016 Preface TO BE WRITTEN. Babai: Discover Linear Algebra. ii This chapter last updated August 21, 2016 c 2016 L´aszl´oBabai. Contents Notation ix I Matrix Theory 1 Introduction to Part I 2 1 (F, R) Column Vectors 3 1.1 (F) Column vector basics . 3 1.1.1 The domain of scalars . 3 1.2 (F) Subspaces and span . 6 1.3 (F) Linear independence and the First Miracle of Linear Algebra . 8 1.4 (F) Dot product . 12 1.5 (R) Dot product over R ................................. 14 1.6 (F) Additional exercises . 14 2 (F) Matrices 15 2.1 Matrix basics . 15 2.2 Matrix multiplication . 18 2.3 Arithmetic of diagonal and triangular matrices . 22 2.4 Permutation Matrices . 24 2.5 Additional exercises . 26 3 (F) Matrix Rank 28 3.1 Column and row rank . 28 iii iv CONTENTS 3.2 Elementary operations and Gaussian elimination . 29 3.3 Invariance of column and row rank, the Second Miracle of Linear Algebra . 31 3.4 Matrix rank and invertibility . 33 3.5 Codimension (optional) . 34 3.6 Additional exercises . 35 4 (F) Theory of Systems of Linear Equations I: Qualitative Theory 38 4.1 Homogeneous systems of linear equations . 38 4.2 General systems of linear equations . 40 5 (F, R) Affine and Convex Combinations (optional) 42 5.1 (F) Affine combinations . -

Download Special Issue
Scientific Programming Scientific Programming Techniques and Algorithms for Data-Intensive Engineering Environments Lead Guest Editor: Giner Alor-Hernandez Guest Editors: Jezreel Mejia-Miranda and José María Álvarez-Rodríguez Scientific Programming Techniques and Algorithms for Data-Intensive Engineering Environments Scientific Programming Scientific Programming Techniques and Algorithms for Data-Intensive Engineering Environments Lead Guest Editor: Giner Alor-Hernández Guest Editors: Jezreel Mejia-Miranda and José María Álvarez-Rodríguez Copyright © 2018 Hindawi. All rights reserved. This is a special issue published in “Scientific Programming.” All articles are open access articles distributed under the Creative Com- mons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Editorial Board M. E. Acacio Sanchez, Spain Christoph Kessler, Sweden Danilo Pianini, Italy Marco Aldinucci, Italy Harald Köstler, Germany Fabrizio Riguzzi, Italy Davide Ancona, Italy José E. Labra, Spain Michele Risi, Italy Ferruccio Damiani, Italy Thomas Leich, Germany Damian Rouson, USA Sergio Di Martino, Italy Piotr Luszczek, USA Giuseppe Scanniello, Italy Basilio B. Fraguela, Spain Tomàs Margalef, Spain Ahmet Soylu, Norway Carmine Gravino, Italy Cristian Mateos, Argentina Emiliano Tramontana, Italy Gianluigi Greco, Italy Roberto Natella, Italy Autilia Vitiello, Italy Bormin Huang, USA Francisco Ortin, Spain Jan Weglarz, Poland Chin-Yu Huang, Taiwan Can Özturan, Turkey -

Autocoding Methods for Networked Embedded Systems
University of Warwick institutional repository: http://go.warwick.ac.uk/wrap A Thesis Submitted for the Degree of PhD at the University of Warwick http://go.warwick.ac.uk/wrap/36892 This thesis is made available online and is protected by original copyright. Please scroll down to view the document itself. Please refer to the repository record for this item for information to help you to cite it. Our policy information is available from the repository home page. Innovation Report AUTOCODING METHODS FOR NETWORKED EMBEDDED SYSTEMS Submitted in partial fulfilment of the Engineering Doctorate By James Finney, 0117868 November 2009 Academic Supervisors: Dr. Peter Jones, Ross McMurran Industrial Supervisor: Dr. Paul Faithfull Declaration I have read and understood the rules on cheating, plagiarism and appropriate referencing as outlined in my handbook and I declare that the work contained in this submission is my own, unless otherwise acknowledged. Signed: …………………………………………………………………….James Finney ii Acknowledgements I would like to thank Rapicore Ltd and the EPSRC for funding this project. I would also like to offer special thanks to my supervisors: Dr. R.P. Jones, Dr. P. Faithfull, and R. McMurran, for their time, support, and guidance throughout this project. iii Table of Contents Declaration ....................................................................................................................... ii Acknowledgements ......................................................................................................... iii Figures -

Memory Capacity of Neural Turing Machines with Matrix Representation
Memory Capacity of Neural Turing Machines with Matrix Representation Animesh Renanse * [email protected] Department of Electronics & Electrical Engineering Indian Institute of Technology Guwahati Assam, India Rohitash Chandra * [email protected] School of Mathematics and Statistics University of New South Wales Sydney, NSW 2052, Australia Alok Sharma [email protected] Laboratory for Medical Science Mathematics RIKEN Center for Integrative Medical Sciences Yokohama, Japan *Equal contributions Editor: Abstract It is well known that recurrent neural networks (RNNs) faced limitations in learning long- term dependencies that have been addressed by memory structures in long short-term memory (LSTM) networks. Matrix neural networks feature matrix representation which inherently preserves the spatial structure of data and has the potential to provide better memory structures when compared to canonical neural networks that use vector repre- sentation. Neural Turing machines (NTMs) are novel RNNs that implement notion of programmable computers with neural network controllers to feature algorithms that have copying, sorting, and associative recall tasks. In this paper, we study augmentation of mem- arXiv:2104.07454v1 [cs.LG] 11 Apr 2021 ory capacity with matrix representation of RNNs and NTMs (MatNTMs). We investigate if matrix representation has a better memory capacity than the vector representations in conventional neural networks. We use a probabilistic model of the memory capacity us- ing Fisher information and investigate how the memory capacity for matrix representation networks are limited under various constraints, and in general, without any constraints. In the case of memory capacity without any constraints, we found that the upper bound on memory capacity to be N 2 for an N ×N state matrix. -

A Bibliography of O'reilly & Associates and O
A Bibliography of O'Reilly & Associates and O'Reilly Media. Inc. Publishers Nelson H. F. Beebe University of Utah Department of Mathematics, 110 LCB 155 S 1400 E RM 233 Salt Lake City, UT 84112-0090 USA Tel: +1 801 581 5254 FAX: +1 801 581 4148 E-mail: [email protected], [email protected], [email protected] (Internet) WWW URL: http://www.math.utah.edu/~beebe/ 08 February 2021 Version 3.67 Title word cross-reference #70 [1263, 1264]. #70-059 [1263]. #70-068 [1264]. 2 [949]. 2 + 2 = 5986 [1456]. 3 [1149, 1570]. *# [1221]. .Mac [1940]. .NET [1860, 22, 186, 342, 441, 503, 591, 714, 716, 721, 730, 753, 786, 998, 1034, 1037, 1038, 1043, 1049, 1089, 1090, 1091, 1119, 1256, 1468, 1858, 1859, 1863, 1899, 1900, 1901, 1917, 1997, 2029]. '05 [461, 1532]. 08 [1541]. 1 [1414]. 1.0 [1009]. 1.1 [59]. 1.2 [1582]. 1000 [1511]. 1000D [1073]. 10g [711, 710]. 10th [2109]. 11 [1385]. 1 2 2 [53, 209, 269, 581, 2134, 919, 940, 1515, 1521, 1530, 2023, 2045]. 2.0 [2, 55, 203, 394, 666, 941, 1000, 1044, 1239, 1276, 1504, 1744, 1801, 2073]. 2.1 [501]. 2.2 [201]. 2000 [38, 202, 604, 610, 669, 927, 986, 1087, 1266, 1358, 1359, 1656, 1751, 1781, 1874, 1959, 2069]. 2001 [96]. 2003 [70, 71, 72, 73, 74, 279, 353, 364, 365, 789, 790, 856, 987, 1146, 1960, 2026]. 2003-2013 [1746]. 2004 [1195]. 2005 [84, 151, 755, 756, 1001, 1041, 1042, 1119, 1122, 1467, 2120, 2018, 2056]. 2006 [152, 153]. 2007 [618, 726, 727, 728, 1123, 1125, 1126, 1127, 2122, 1973, 1974, 2030]. -

Noncommutative Spaces from Matrix Models Lei Lu Allen B Stern, Committee Chair Nobuchika Okada Benjamin Harms Gary Mankey Martyn
NONCOMMUTATIVE SPACES FROM MATRIX MODELS by LEI LU ALLEN B STERN, COMMITTEE CHAIR NOBUCHIKA OKADA BENJAMIN HARMS GARY MANKEY MARTYN DIXON A DISSERTATION Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Department of Physics and Astronomy in the Graduate School of The University of Alabama TUSCALOOSA, ALABAMA 2016 Copyright Lei Lu 2016 ALL RIGHTS RESERVED Abstract Noncommutative (NC) spaces commonly arise as solutions to matrix model equations of motion. They are natural generalizations of the ordinary commuta- tive spacetime. Such spaces may provide insights into physics close to the Planck scale, where quantum gravity becomes relevant. Although there has been much research in the literature, aspects of these NC spaces need further investigation. In this dissertation, we focus on properties of NC spaces in several different contexts. In particular, we study exact NC spaces which result from solutions to matrix model equations of motion. These spaces are associated with finite-dimensional Lie-algebras. More specifically, they are two-dimensional fuzzy spaces that arise from a three-dimensional Yang-Mills type matrix model, four-dimensional tensor- product fuzzy spaces from a tensorial matrix model, and Snyder algebra from a five-dimensional tensorial matrix model. In the first part of this dissertation, we study two-dimensional NC solutions to matrix equations of motion of extended IKKT-type matrix models in three- space-time dimensions. Perturbations around the NC solutions lead to NC field theories living on a two-dimensional space-time. The commutative limit of the solutions are smooth manifolds which can be associated with closed, open and static two-dimensional cosmologies. -
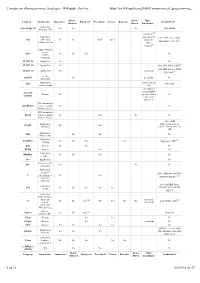
Comparison of Programming Languages - Wikipedia, the Free
Comparison of programming languages - Wikipedia, the free ... https://en.wikipedia.org/wiki/Comparison_of_programming_... Object- Event- Other Language Intended use Imperative Functional Procedural Generic Reflective Standardized? Oriented Driven Paradigm(s) Application, ActionScript 3.0 Yes Yes Yes 1996, ECMA client-side, Web concurrent,[4] [5] Application, distributed, 1983, 2005, 2012, ANSI, Ada embedded, Yes Yes Yes[2] Yes[3] imperative ISO, GOST 27831-88[7] realtime, system object- oriented[6] Highly domain- specific, Aldor Yes Yes Yes No symbolic computing ALGOL 58 Application Yes No ALGOL 60 Application Yes 1960, IFIP WG 2.1, ISO[8] 1968, IFIP WG 2.1, GOST ALGOL 68 Application Yes concurrent 27974-88,[9] Parallel Ateji PX Yes pi calculus No application Application, array-oriented, APL 1989, ISO data processing tacit any, syntax is usually highly Assembly General Yes specific, related No language to the target processor GUI automation AutoHotkey (macros), highly Yes No domain-specific GUI automation AutoIt (macros), highly Yes Yes Yes No domain-specific 1983, ANSI Application, (http://portal.acm.org BASIC Yes Yes education /citation.cfm?id=988221), ISO Application, BBj Yes Yes No business, Web Application, BeanShell Yes Yes Yes Yes [10] scripting In progress, JCP BitC System Yes Yes No BLISS System Yes No Application, BlitzMax Yes Yes Yes No game Boo Application No domain-specific, Bro Yes Yes No application Application, [11] system, 1989, ANSI C89, ISO C90, C general purpose, Yes Yes ISO C99, ISO C11[12] low-level operations 1998, ISO/IEC -

Metadefender Core V4.17.3
MetaDefender Core v4.17.3 © 2020 OPSWAT, Inc. All rights reserved. OPSWAT®, MetadefenderTM and the OPSWAT logo are trademarks of OPSWAT, Inc. All other trademarks, trade names, service marks, service names, and images mentioned and/or used herein belong to their respective owners. Table of Contents About This Guide 13 Key Features of MetaDefender Core 14 1. Quick Start with MetaDefender Core 15 1.1. Installation 15 Operating system invariant initial steps 15 Basic setup 16 1.1.1. Configuration wizard 16 1.2. License Activation 21 1.3. Process Files with MetaDefender Core 21 2. Installing or Upgrading MetaDefender Core 22 2.1. Recommended System Configuration 22 Microsoft Windows Deployments 22 Unix Based Deployments 24 Data Retention 26 Custom Engines 27 Browser Requirements for the Metadefender Core Management Console 27 2.2. Installing MetaDefender 27 Installation 27 Installation notes 27 2.2.1. Installing Metadefender Core using command line 28 2.2.2. Installing Metadefender Core using the Install Wizard 31 2.3. Upgrading MetaDefender Core 31 Upgrading from MetaDefender Core 3.x 31 Upgrading from MetaDefender Core 4.x 31 2.4. MetaDefender Core Licensing 32 2.4.1. Activating Metadefender Licenses 32 2.4.2. Checking Your Metadefender Core License 37 2.5. Performance and Load Estimation 38 What to know before reading the results: Some factors that affect performance 38 How test results are calculated 39 Test Reports 39 Performance Report - Multi-Scanning On Linux 39 Performance Report - Multi-Scanning On Windows 43 2.6. Special installation options 46 Use RAMDISK for the tempdirectory 46 3. -

Visustin Features and Versions
Visustin features and versions v8 v7 v6 v5 v4 v3 Flow chart styles to choose from 2 2 1 1 1 1 UML Activity Diagrams Y Y Y Y Y Flowchart large files (>3000 lines) Y Y Y Flowchart individual procedures Y Y Y Print in high quality Y Y Y Save BMP, GIF, JPG, PNG, EMF, WMF, DOT, HTML, MHT Y Y Y Y Y Y Save TIFF Y Y Y Y Save PDF, single page and printer pages Y Y Y Save PDF, multipage Y Y Save PowerPoint PPT - Y Y Y Y Save Word DOC Y Y Y Y Y Save Word DOCX Y Load images Y Y Y Y Y Metrics Y Y Y Y Y Option: Each statement in its own box Y Y Option: Wrap lines Y Y Option: Configure colors and labels Y Y High-density display support (high DPI) Y Y Pro Edition features Export Visio VSD [Pro] Y Y Y Y Y Y Export Visio VSDX [Pro] Y Editor [Pro] Y Y Y Y Bulk flowcharting [Pro] Y Y Y Y Y Y Bulk flowcharting jobs (.vjb) [Pro] Y Y Y Y Bulk flowcharting individual procedures [Pro] Y Y Y Compatibility Windows version, newest supported 10 8 7 Vista 2003 2003 Office version, newest supported 2016 2013 2010 2007 2007 2003 Language support on next page. ©2016 Aivosto Oy www.aivosto.com Visustin language support v8 v7 v6 v5 v4 v3 ABAP Y Y ActionScript, MXML Y Y ActionScript, semicolon-less Y Ada Y Y Y Y Y Y Assembler: MASM, NASM, IAR/MSP430 Y Y Y Y Y ASP Y Y Y Y Y Y AutoIt Y Batch files Y Y C/C++ Y Y Y Y Y Y C# Y Y Y Y Y Y Clipper Y Y Y Y Y COBOL Y Y Y Y Y Y ColdFusion Y Y Y Y Fortran Y Y Y Y Y Y GW-BASIC Y (Y) HTML Y Java Y Y Y Y Y Y JavaScript Y Y Y Y Y Y JavaScript, semicolon-less Y JCL (MVS) Y Y Y JSP Y Y Y Y Y Y LotusScript Y Y Y Y Y MATLAB Y Y Y Pascal/Delphi Y Y Y Y Y Y Perl Y Y Y Y Y Y PHP Y Y Y Y Y Y PL/I Y Y Y PL/SQL Y Y Y Y Y Y PowerBASIC Y PowerScript (PowerBuilder) Y Y Y Y Y PureBasic Y Y Y Y Y Python Y Y Y Y Y QuickBASIC Y Y Y Y Y Y REALbasic Y Y Y Y Y Rexx Y Y Y RPG Y Ruby Y Y SAS Y Y Y Shell script (bash, csh, tcsh, ksh, sh) Y Y Tcl Y Y T-SQL Y Y Y Y Y Y VBScript Y Y Y (Y) (Y) (Y) Visual Basic, VBA Y Y Y Y Y Y Visual Basic .Net Y Y Y Y Y Y Visual FoxPro Y Y Y Y Y XML Y XSLT Y Y Y Y Languages have been updated to newer syntax from version to version. -

Mathfest 2018
Abstracts of Papers Presented at MathFest 2018 Denver, CO August 1 – 4, 2018 Published and Distributed by The Mathematical Association of America Contents Invited Addresses 1 Earle Raymond Hedrick Lecture Series by Gigliola Staffilani . 1 Nonlinear Dispersive Equations and the Beautiful Mathematics That Comes with Them Lecture 1: Thursday, August 2, 11:00–11:50 AM, Plaza Ballroom A, B, & C, Plaza Building Lecture 2: Friday, August 3, 10:30–11:20 AM, Plaza Ballroom A, B, & C, Plaza Building Lecture 3: Saturday, August 4, 10:00–10:50 AM, Plaza Ballroom A, B, & C, Plaza Building . 1 AMS-MAA Joint Invited Address . 1 Gravity’s Action on Light: A Mathematical Journey by Arlie Petters Thursday, August 2, 10:00–10:50 AM, Plaza Ballroom A, B, & C, Plaza Building . 1 MAA Invited Address . 1 Inclusion-exclusion in Mathematics: Who Stays in, Who Falls out, Why It Happens, and What We Should Do About It by Eugenia Cheng Friday, August 3, 11:30–12:20 AM, Plaza Ballroom A, B, & C, Plaza Building . 1 Snow Business: Scientific Computing in the Movies and Beyond by Joseph Teran Saturday, August 4, 11:00–11:50 AM, Plaza Ballroom A, B, & C, Plaza Building . 1 Mathematical Medicine: Modeling Disease and Treatment by Lisette de Pillis Thursday, August 2, 9:00–9:50 AM, Plaza Ballroom A, B, & C, Plaza Building . 2 MAA James R.C. Leitzel Lecture . 2 The Relationship between Culture and the Learning of Mathematics by Talitha Washington Saturday, August 4, 9:00–9:50 AM, Plaza Ballroom A, B, & C, Plaza Building . -

Equivariant Reduction of Matrix Gauge Theories and Emergent Chaotic Dynamics a Thesis Submitted to the Graduate School of Natura
EQUIVARIANT REDUCTION OF MATRIX GAUGE THEORIES AND EMERGENT CHAOTIC DYNAMICS A THESIS SUBMITTED TO THE GRADUATE SCHOOL OF NATURAL AND APPLIED SCIENCES OF MIDDLE EAST TECHNICAL UNIVERSITY BY GÖKSU CAN TOGA˘ IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF MASTER OF SCIENCE IN PHYSICS JULY 2018 Approval of the thesis: EQUIVARIANT REDUCTION OF MATRIX GAUGE THEORIES AND EMERGENT CHAOTIC DYNAMICS submitted by GÖKSU CAN TOGA˘ in partial fulfillment of the requirements for the degree of Master of Science in Physics Department, Middle East Technical Uni- versity by, Prof. Dr. Halil Kalıpçılar Dean, Graduate School of Natural and Applied Sciences Prof. Dr. Altug˘ Özpineci Head of Department, Physics Prof. Dr. Seçkin Kürkçüoglu˘ Supervisor, Physics Department, METU Examining Committee Members: Prof. Dr. Ali Ulvi Yılmazer Physics Engineering Department, Ankara University Prof. Dr. Seçkin Kürkçüoglu˘ Physics Department, METU Assoc. Prof. Dr. Yusuf Ipeko˙ glu˘ Physics Department, METU Prof. Dr. Ismail˙ Turan Physics Department, METU Prof. Dr. Sadi Turgut Physics Department, METU Date: I hereby declare that all information in this document has been obtained and presented in accordance with academic rules and ethical conduct. I also declare that, as required by these rules and conduct, I have fully cited and referenced all material and results that are not original to this work. Name, Last Name: GÖKSU CAN TOGA˘ Signature : iv ABSTRACT EQUIVARIANT REDUCTION OF MATRIX GAUGE THEORIES AND EMERGENT CHAOTIC DYNAMICS Toga,˘ Göksu Can M.S., Department of Physics Supervisor : Prof. Dr. Seçkin Kürkçüoglu˘ July 2018, 74 pages In this thesis we focus on a massive deformation of a Yang-Mills matrix gauge the- ory. -

Comparative Programming Languages CM20253
We have briefly covered many aspects of language design And there are many more factors we could talk about in making choices of language The End There are many languages out there, both general purpose and specialist And there are many more factors we could talk about in making choices of language The End There are many languages out there, both general purpose and specialist We have briefly covered many aspects of language design The End There are many languages out there, both general purpose and specialist We have briefly covered many aspects of language design And there are many more factors we could talk about in making choices of language Often a single project can use several languages, each suited to its part of the project And then the interopability of languages becomes important For example, can you easily join together code written in Java and C? The End Or languages And then the interopability of languages becomes important For example, can you easily join together code written in Java and C? The End Or languages Often a single project can use several languages, each suited to its part of the project For example, can you easily join together code written in Java and C? The End Or languages Often a single project can use several languages, each suited to its part of the project And then the interopability of languages becomes important The End Or languages Often a single project can use several languages, each suited to its part of the project And then the interopability of languages becomes important For example, can you easily