Supplementary Table 1
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Genetic Variation Across the Human Olfactory Receptor Repertoire Alters Odor Perception
bioRxiv preprint doi: https://doi.org/10.1101/212431; this version posted November 1, 2017. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. Genetic variation across the human olfactory receptor repertoire alters odor perception Casey Trimmer1,*, Andreas Keller2, Nicolle R. Murphy1, Lindsey L. Snyder1, Jason R. Willer3, Maira Nagai4,5, Nicholas Katsanis3, Leslie B. Vosshall2,6,7, Hiroaki Matsunami4,8, and Joel D. Mainland1,9 1Monell Chemical Senses Center, Philadelphia, Pennsylvania, USA 2Laboratory of Neurogenetics and Behavior, The Rockefeller University, New York, New York, USA 3Center for Human Disease Modeling, Duke University Medical Center, Durham, North Carolina, USA 4Department of Molecular Genetics and Microbiology, Duke University Medical Center, Durham, North Carolina, USA 5Department of Biochemistry, University of Sao Paulo, Sao Paulo, Brazil 6Howard Hughes Medical Institute, New York, New York, USA 7Kavli Neural Systems Institute, New York, New York, USA 8Department of Neurobiology and Duke Institute for Brain Sciences, Duke University Medical Center, Durham, North Carolina, USA 9Department of Neuroscience, University of Pennsylvania School of Medicine, Philadelphia, Pennsylvania, USA *[email protected] ABSTRACT The human olfactory receptor repertoire is characterized by an abundance of genetic variation that affects receptor response, but the perceptual effects of this variation are unclear. To address this issue, we sequenced the OR repertoire in 332 individuals and examined the relationship between genetic variation and 276 olfactory phenotypes, including the perceived intensity and pleasantness of 68 odorants at two concentrations, detection thresholds of three odorants, and general olfactory acuity. -

Table S4. RAE Analysis of Dedifferentiated Liposarcoma
Table S4. RAE analysis of dedifferentiated liposarcoma Model Chromosome Region start Region end Size q value freqX0* # genes genes Amp 1 57809872 60413476 2603605 0.00026 34.6 10 DAB1,RPS26P15,OMA1,TACSTD2,MYSM1,JUN,FGGY,HOOK1,CYP2J2,C1orf87 Amp 1 158619146 158696968 77823 0.053 25 1 VANGL2 Amp 1 158883523 158922841 39319 0.081 23.1 2 SLAMF1,CD48 Amp 1 162042586 162118557 75972 0.072 25 0 [Nearest:NUF2] Amp 1 162272460 162767627 495168 0.017 26.9 0 [Nearest:PBX1] Amp 1 165486554 165532374 45821 0.057 25 1 POU2F1 Amp 1 167138282 167483267 344986 0.024 26.9 2 ATP1B1,NME7 Amp 1 167612872 167708844 95973 0.041 25 3 BLZF1,C1orf114,SLC19A2 Amp 1 167728199 167808161 79963 0.076 21.2 1 F5 Amp 1 168436370 169233893 797524 0.018 26.9 3 GORAB,PRRX1,C1orf129 Amp 1 169462231 170768440 1306210 1.3E-06 38.5 10 FMO1,FMO4,TOP1P1,BAT2D1,MYOC,VAMP4,METTL13,DNM3,C1orf105,PIGC Amp 1 171026247 171291427 265181 0.015 26.9 1 TNFSF18 Del 1 201860394 202299299 438906 0.0047 25 6 ATP2B4,SNORA77,LAX1,ZC3H11A,SNRPE,C1orf157 Del 1 210909187 212021116 1111930 0.017 19.2 8 BATF3,NSL1,TATDN3,C1orf227,FLVCR1,VASH2,ANGEL2,RPS6KC1 Del 1 215937857 216049214 111358 0.079 23.1 1 SPATA17 Del 1 218237257 218367476 130220 0.0063 26.9 3 EPRS,BPNT1,IARS2 Del 1 222100886 222727238 626353 5.2E-05 32.7 5 FBXO28,DEGS1,NVL,CNIH4,WDR26 Del 1 223166548 224519805 1353258 0.0063 26.9 15 DNAH14,LBR,ENAH,SRP9,EPHX1,TMEM63A,LEFTY1,PYCR2,LEFTY2,C1orf55,H3F3A,LOC440926 ,ACBD3,MIXL1,LIN9 Del 1 225283136 225374166 91031 0.054 23.1 1 CDC42BPA Del 1 227278990 229012661 1733672 0.091 21.2 13 RAB4A,SPHAR,C1orf96,ACTA1,NUP133,ABCB10,TAF5L,URB2,GALNT2,PGBD5,COG2,AGT,CAP -

Gnomad Lof Supplement
1 gnomAD supplement gnomAD supplement 1 Data processing 4 Alignment and read processing 4 Variant Calling 4 Coverage information 5 Data processing 5 Sample QC 7 Hard filters 7 Supplementary Table 1 | Sample counts before and after hard and release filters 8 Supplementary Table 2 | Counts by data type and hard filter 9 Platform imputation for exomes 9 Supplementary Table 3 | Exome platform assignments 10 Supplementary Table 4 | Confusion matrix for exome samples with Known platform labels 11 Relatedness filters 11 Supplementary Table 5 | Pair counts by degree of relatedness 12 Supplementary Table 6 | Sample counts by relatedness status 13 Population and subpopulation inference 13 Supplementary Figure 1 | Continental ancestry principal components. 14 Supplementary Table 7 | Population and subpopulation counts 16 Population- and platform-specific filters 16 Supplementary Table 8 | Summary of outliers per population and platform grouping 17 Finalizing samples in the gnomAD v2.1 release 18 Supplementary Table 9 | Sample counts by filtering stage 18 Supplementary Table 10 | Sample counts for genomes and exomes in gnomAD subsets 19 Variant QC 20 Hard filters 20 Random Forest model 20 Features 21 Supplementary Table 11 | Features used in final random forest model 21 Training 22 Supplementary Table 12 | Random forest training examples 22 Evaluation and threshold selection 22 Final variant counts 24 Supplementary Table 13 | Variant counts by filtering status 25 Comparison of whole-exome and whole-genome coverage in coding regions 25 Variant annotation 30 Frequency and context annotation 30 2 Functional annotation 31 Supplementary Table 14 | Variants observed by category in 125,748 exomes 32 Supplementary Figure 5 | Percent observed by methylation. -

Supplementary Data
SUPPLEMENTARY METHODS 1) Characterisation of OCCC cell line gene expression profiles using Prediction Analysis for Microarrays (PAM) The ovarian cancer dataset from Hendrix et al (25) was used to predict the phenotypes of the cell lines used in this study. Hendrix et al (25) analysed a series of 103 ovarian samples using the Affymetrix U133A array platform (GEO: GSE6008). This dataset comprises clear cell (n=8), endometrioid (n=37), mucinous (n=13) and serous epithelial (n=41) primary ovarian carcinomas and samples from 4 normal ovaries. To build the predictor, the Prediction Analysis of Microarrays (PAM) package in R environment was employed (http://rss.acs.unt.edu/Rdoc/library/pamr/html/00Index.html). When more than one probe described the expression of a given gene, we used the probe with the highest median absolute deviation across the samples. The dataset from Hendrix et al. (25) and the dataset of OCCC cell lines described in this manuscript were then overlaid on the basis of 11536 common unique HGNC gene symbols. Only the 99 primary ovarian cancers samples and the four normal ovary samples were used to build the predictor. Following leave one out cross-validation, a predictor based upon 126 genes was able to identify correctly the four distinct phenotypes of primary ovarian tumour samples with a misclassification rate of 18.3%. This predictor was subsequently applied to the expression data from the 12 OCCC cell lines to determine the likeliest phenotype of the OCCC cell lines compared to primary ovarian cancers. Posterior probabilities were estimated for each cell line in comparison to the following phenotypes: clear cell, endometrioid, mucinous and serous epithelial. -

Us 2018 / 0305689 A1
US 20180305689A1 ( 19 ) United States (12 ) Patent Application Publication ( 10) Pub . No. : US 2018 /0305689 A1 Sætrom et al. ( 43 ) Pub . Date: Oct. 25 , 2018 ( 54 ) SARNA COMPOSITIONS AND METHODS OF plication No . 62 /150 , 895 , filed on Apr. 22 , 2015 , USE provisional application No . 62/ 150 ,904 , filed on Apr. 22 , 2015 , provisional application No. 62 / 150 , 908 , (71 ) Applicant: MINA THERAPEUTICS LIMITED , filed on Apr. 22 , 2015 , provisional application No. LONDON (GB ) 62 / 150 , 900 , filed on Apr. 22 , 2015 . (72 ) Inventors : Pål Sætrom , Trondheim (NO ) ; Endre Publication Classification Bakken Stovner , Trondheim (NO ) (51 ) Int . CI. C12N 15 / 113 (2006 .01 ) (21 ) Appl. No. : 15 /568 , 046 (52 ) U . S . CI. (22 ) PCT Filed : Apr. 21 , 2016 CPC .. .. .. C12N 15 / 113 ( 2013 .01 ) ; C12N 2310 / 34 ( 2013. 01 ) ; C12N 2310 /14 (2013 . 01 ) ; C12N ( 86 ) PCT No .: PCT/ GB2016 /051116 2310 / 11 (2013 .01 ) $ 371 ( c ) ( 1 ) , ( 2 ) Date : Oct . 20 , 2017 (57 ) ABSTRACT The invention relates to oligonucleotides , e . g . , saRNAS Related U . S . Application Data useful in upregulating the expression of a target gene and (60 ) Provisional application No . 62 / 150 ,892 , filed on Apr. therapeutic compositions comprising such oligonucleotides . 22 , 2015 , provisional application No . 62 / 150 ,893 , Methods of using the oligonucleotides and the therapeutic filed on Apr. 22 , 2015 , provisional application No . compositions are also provided . 62 / 150 ,897 , filed on Apr. 22 , 2015 , provisional ap Specification includes a Sequence Listing . SARNA sense strand (Fessenger 3 ' SARNA antisense strand (Guide ) Mathew, Si Target antisense RNA transcript, e . g . NAT Target Coding strand Gene Transcription start site ( T55 ) TY{ { ? ? Targeted Target transcript , e . -

MOL #82305 TITLE PAGE Title: Induced CYP3A4 Expression In
Downloaded from molpharm.aspetjournals.org at ASPET Journals on September 28, 2021 1 This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. The final version may differ from this version. This article has not been copyedited and formatted. -
Explorations in Olfactory Receptor Structure and Function by Jianghai
Explorations in Olfactory Receptor Structure and Function by Jianghai Ho Department of Neurobiology Duke University Date:_______________________ Approved: ___________________________ Hiroaki Matsunami, Supervisor ___________________________ Jorg Grandl, Chair ___________________________ Marc Caron ___________________________ Sid Simon ___________________________ [Committee Member Name] Dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Department of Neurobiology in the Graduate School of Duke University 2014 ABSTRACT Explorations in Olfactory Receptor Structure and Function by Jianghai Ho Department of Neurobiology Duke University Date:_______________________ Approved: ___________________________ Hiroaki Matsunami, Supervisor ___________________________ Jorg Grandl, Chair ___________________________ Marc Caron ___________________________ Sid Simon ___________________________ [Committee Member Name] An abstract of a dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Department of Neurobiology in the Graduate School of Duke University 2014 Copyright by Jianghai Ho 2014 Abstract Olfaction is one of the most primitive of our senses, and the olfactory receptors that mediate this very important chemical sense comprise the largest family of genes in the mammalian genome. It is therefore surprising that we understand so little of how olfactory receptors work. In particular we have a poor idea of what chemicals are detected by most of the olfactory receptors in the genome, and for those receptors which we have paired with ligands, we know relatively little about how the structure of these ligands can either activate or inhibit the activation of these receptors. Furthermore the large repertoire of olfactory receptors, which belong to the G protein coupled receptor (GPCR) superfamily, can serve as a model to contribute to our broader understanding of GPCR-ligand binding, especially since GPCRs are important pharmaceutical targets. -
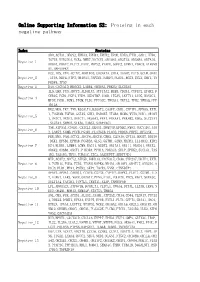
Online Supporting Information S2: Proteins in Each Negative Pathway
Online Supporting Information S2: Proteins in each negative pathway Index Proteins ADO,ACTA1,DEGS2,EPHA3,EPHB4,EPHX2,EPOR,EREG,FTH1,GAD1,HTR6, IGF1R,KIR2DL4,NCR3,NME7,NOTCH1,OR10S1,OR2T33,OR56B4,OR7A10, Negative_1 OR8G1,PDGFC,PLCZ1,PROC,PRPS2,PTAFR,SGPP2,STMN1,VDAC3,ATP6V0 A1,MAPKAPK2 DCC,IDS,VTN,ACTN2,AKR1B10,CACNA1A,CHIA,DAAM2,FUT5,GCLM,GNAZ Negative_2 ,ITPA,NEU4,NTF3,OR10A3,PAPSS1,PARD3,PLOD1,RGS3,SCLY,SHC1,TN FRSF4,TP53 Negative_3 DAO,CACNA1D,HMGCS2,LAMB4,OR56A3,PRKCQ,SLC25A5 IL5,LHB,PGD,ADCY3,ALDH1A3,ATP13A2,BUB3,CD244,CYFIP2,EPHX2,F CER1G,FGD1,FGF4,FZD9,HSD17B7,IL6R,ITGAV,LEFTY1,LIPG,MAN1C1, Negative_4 MPDZ,PGM1,PGM3,PIGM,PLD1,PPP3CC,TBXAS1,TKTL2,TPH2,YWHAQ,PPP 1R12A HK2,MOS,TKT,TNN,B3GALT4,B3GAT3,CASP7,CDH1,CYFIP1,EFNA5,EXTL 1,FCGR3B,FGF20,GSTA5,GUK1,HSD3B7,ITGB4,MCM6,MYH3,NOD1,OR10H Negative_5 1,OR1C1,OR1E1,OR4C11,OR56A3,PPA1,PRKAA1,PRKAB2,RDH5,SLC27A1 ,SLC2A4,SMPD2,STK36,THBS1,SERPINC1 TNR,ATP5A1,CNGB1,CX3CL1,DEGS1,DNMT3B,EFNB2,FMO2,GUCY1B3,JAG Negative_6 2,LARS2,NUMB,PCCB,PGAM1,PLA2G1B,PLOD2,PRDX6,PRPS1,RFXANK FER,MVD,PAH,ACTC1,ADCY4,ADCY8,CBR3,CLDN16,CPT1A,DDOST,DDX56 ,DKK1,EFNB1,EPHA8,FCGR3A,GLS2,GSTM1,GZMB,HADHA,IL13RA2,KIR2 Negative_7 DS4,KLRK1,LAMB4,LGMN,MAGI1,NUDT2,OR13A1,OR1I1,OR4D11,OR4X2, OR6K2,OR8B4,OXCT1,PIK3R4,PPM1A,PRKAG3,SELP,SPHK2,SUCLG1,TAS 1R2,TAS1R3,THY1,TUBA1C,ZIC2,AASDHPPT,SERPIND1 MTR,ACAT2,ADCY2,ATP5D,BMPR1A,CACNA1E,CD38,CYP2A7,DDIT4,EXTL Negative_8 1,FCER1G,FGD3,FZD5,ITGAM,MAPK8,NR4A1,OR10V1,OR4F17,OR52D1,O R8J3,PLD1,PPA1,PSEN2,SKP1,TACR3,VNN1,CTNNBIP1 APAF1,APOA1,CARD11,CCDC6,CSF3R,CYP4F2,DAPK1,FLOT1,GSTM1,IL2 -

Characterization of the Genomic Features and Expressed Fusion Genes In
1 SUPPLEMENTARY INFORMATION (ONLINE SUPPORTING INFORMATION) Characterization of the genomic features and expressed fusion genes in micropapillary carcinomas of the breast Natrajan et al. Supplementary Methods Supplementary Figures S1-S6 Supplementary Tables S1-S7 2 SUPPLEMENTARY METHODS Tumor samples Two cohorts of micropapillary carcinomas (MPCs) were analyzed; the first cohort comprised 16 consecutive formalin fixed paraffin embedded (FFPE) MPCs, 11 pure and 5 mixed, which were retrieved from the authors' institutions (Table 1), and a second, validation cohort comprised 14 additional consecutive FFPE MPCs, retrieved from Molinette Hospital, Turin, Italy. Frozen samples were available from five out of the 16 cases from the first cohort of MPCs. As a comparator for the results of the Sequenom mutation profiling, a cohort of 16 consecutive IC-NSTs matched to the first cohort of 16 MPCs according to ER and HER2 status and histological grade were retrieved from a series of breast cancers previously analyzed by aCGH[1]. In addition, 14 IC-NSTs matched according to grade, and ER and HER2 status to tumors from the second cohort of 14 MPCs, and 48 grade 3 IC-NSTs were retrieved from Hospital La Paz, Madrid, Spain[1] (Supplementary Table S1). Power calculation For power calculations, we have assumed that if MPCs were driven by a recurrent fusion gene in a way akin to secretory carcinomas (which harbor the ETV6-NTRK3 fusion gene in >95% of cases[2-4]) or adenoid cystic carcinomas of the breast (which harbor the MYB-NFIB fusion gene in >90% of cases[5]), a ‘pathognomonic’ driver event would be present in at least ≥70% of cases (an estimate that is conservative). -

Convergent Evolution of Chicken Z and Human X Chromosomes by Expansion and Gene Acquisition
Convergent Evolution of Chicken Z and Human X Chromosomes by Expansion and Gene Acquisition Daniel W. Bellott1, Helen Skaletsky1, Tatyana Pyntikova1, Elaine R. Mardis2, Tina Graves2, Colin Kremitzki2, Laura G. Brown1, Steve Rozen1, Wesley C. Warren2, Richard K. Wilson2 & David C Page1 1. Howard Hughes Medical Institute, Whitehead Institute, and Department of Biology, Massachusetts Institute of Technology, 9 Cambridge Center, Cambridge, Massachusetts 02142, USA 2. The Genome Center, Washington University School of Medicine, 4444 Forest Park Boulevard, St. Louis Missouri 63108, USA 2 In birds, as in mammals, one pair of chromosomes differs between the sexes. In birds, males are ZZ and females ZW. In mammals, males are XY and females XX. Like the mammalian XY pair, the avian ZW pair is believed to have evolved from autosomes, with most change occurring in the chromosomes found in only one sex – the W and Y chromosomes1-5. By contrast, the sex chromosomes found in both sexes – the Z and X chromosomes – are assumed to have diverged little from their autosomal progenitors2. Here we report findings that overturn this assumption for both the chicken Z and human X chromosomes. The chicken Z chromosome, which we sequenced essentially to completion, is less gene-dense than chicken autosomes but contains a massive tandem array containing hundreds of duplicated genes expressed in testes. A comprehensive comparison of the chicken Z chromosome to the finished sequence of the human X chromosome demonstrates that each evolved independently from different portions of the ancestral genome. Despite this independence, the chicken Z and human X chromosomes share features that distinguish them from autosomes: the acquisition and amplification of testis-expressed genes, as well as a low gene density resulting from an expansion of intergenic regions. -

Key Genes Associated with Diabetes Mellitus and Hepatocellular Carcinoma T ⁎ ⁎ Gao-Min Liu , Hua-Dong Zeng, Cai-Yun Zhang, Ji-Wei Xu
Pathology - Research and Practice 215 (2019) 152510 Contents lists available at ScienceDirect Pathology - Research and Practice journal homepage: www.elsevier.com/locate/prp Key genes associated with diabetes mellitus and hepatocellular carcinoma T ⁎ ⁎ Gao-Min Liu , Hua-Dong Zeng, Cai-Yun Zhang, Ji-Wei Xu Department of Hepatobiliary Surgery, Meizhou People’s Hospital, No. 38 Huangtang Road, Meizhou 514000, China ARTICLE INFO ABSTRACT Keywords: Accumulating evidence indicates a strong correlation between type 2 diabetes mellitus (T2DM) and hepato- Hepatocellular carcinoma cellular carcinoma (HCC), but the underlying pathophysiology is still elusive. We aimed to identify unrecognized Diabetes but important genes and pathways related to T2DM and HCC by bioinformatic analysis. The GSE64998 and TCGA GSE15653 datasets (for T2DM), the GSE121248 dataset and the Cancer Genome Atlas-Liver Hepatocellular GEO Carcinoma (TCGA-LIHC) dataset (for HCC) were downloaded. Differential expression analysis, functional and Bioinformatic pathway enrichment analysis, protein–protein interaction (PPI) network construction, survival analysis, tran- scription factor (TF) prediction, and correlation of gene expression with methylation and tumour-infiltrating immune cells were conducted. Nine genes, namely, CDNF, CRELD2, DNAJB11, DTL, GINS2, MANF, PDIA4, PDIA6, and VCP, were recognized as hub genes. Enrichment analysis revealed several enriched terms and pathways. Transcription factors such as Kruppel-like factor 6, abnormal methylation and immune dysregulation might help explain the dysregulation of hub genes. Our study identified nine hub genes that might play a critical role in both T2DM and HCC. However, more studies are warranted to clarify the mechanisms of these genes. 1. Introduction 2. Materials and methods Hepatocellular carcinoma (HCC) remains a great challenge in public 2.1. -

Supplementary Methods
doi: 10.1038/nature06162 SUPPLEMENTARY INFORMATION Supplementary Methods Cloning of human odorant receptors 423 human odorant receptors were cloned with sequence information from The Olfactory Receptor Database (http://senselab.med.yale.edu/senselab/ORDB/default.asp). Of these, 335 were predicted to encode functional receptors, 45 were predicted to encode pseudogenes, 29 were putative variant pairs of the same genes, and 14 were duplicates. We adopted the nomenclature proposed by Doron Lancet 1. OR7D4 and the six intact odorant receptor genes in the OR7D4 gene cluster (OR1M1, OR7G2, OR7G1, OR7G3, OR7D2, and OR7E24) were used for functional analyses. SNPs in these odorant receptors were identified from the NCBI dbSNP database (http://www.ncbi.nlm.nih.gov/projects/SNP) or through genotyping. OR7D4 single nucleotide variants were generated by cloning the reference sequence from a subject or by inducing polymorphic SNPs by site-directed mutagenesis using overlap extension PCR. Single nucleotide and frameshift variants for the six intact odorant receptors in the same gene cluster as OR7D4 were generated by cloning the respective genes from the genomic DNA of each subject. The chimpanzee OR7D4 orthologue was amplified from chimpanzee genomic DNA (Coriell Cell Repositories). Odorant receptors that contain the first 20 amino acids of human rhodopsin tag 2 in pCI (Promega) were expressed in the Hana3A cell line along with a short form of mRTP1 called RTP1S, (M37 to the C-terminal end), which enhances functional expression of the odorant receptors 3. For experiments with untagged odorant receptors, OR7D4 RT and S84N variants without the Rho tag were cloned into pCI.