Cse352 DECISION TREE CLASSIFICATION
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

How to Find out the IP Address of an Omron
Communications Middleware/Network Browser How to find an Omron Controller’s IP address Valin Corporation | www.valin.com Overview • Many Omron PLC’s have Ethernet ports or Ethernet port options • The IP address for a PLC is usually changed by the programmer • Most customers do not mark the controller with IP address (label etc.) • Very difficult to communicate to the PLC over Ethernet if the IP address is unknown. Valin Corporation | www.valin.com Simple Ethernet Network Basics IP address is up to 12 digits (4 octets) Ex:192.168.1.1 For MOST PLC programming applications, the first 3 octets are the network address and the last is the node address. In above example 192.168.1 is network address, 1 is node address. For devices to communicate on a simple network: • Every device IP Network address must be the same. • Every device node number must be different. Device Laptop EX: Omron PLC 192.168.1.1 192.168.1.1 Device Laptop EX: Omron PLC 127.27.250.5 192.168.1.1 Device Laptop EX: Omron PLC 192.168.1.3 192.168.1.1 Valin Corporation | www.valin.com Omron Default IP Address • Most Omron Ethernet devices use one of the following IP addresses by default. Omron PLC 192.168.250.1 OR 192.168.1.1 Valin Corporation | www.valin.com PING Command • PING is a way to check if the device is connected (both virtually and physically) to the network. • Windows Command Prompt command. • PC must use the same network number as device (See previous) • Example: “ping 172.21.90.5” will test to see if a device with that IP address is connected to the PC. -

Disk Clone Industrial
Disk Clone Industrial USER MANUAL Ver. 1.0.0 Updated: 9 June 2020 | Contents | ii Contents Legal Statement............................................................................... 4 Introduction......................................................................................4 Cloning Data.................................................................................................................................... 4 Erasing Confidential Data..................................................................................................................5 Disk Clone Overview.......................................................................6 System Requirements....................................................................................................................... 7 Software Licensing........................................................................................................................... 7 Software Updates............................................................................................................................. 8 Getting Started.................................................................................9 Disk Clone Installation and Distribution.......................................................................................... 12 Launching and initial Configuration..................................................................................................12 Navigating Disk Clone.....................................................................................................................14 -

Problem Solving and Unix Tools
Problem Solving and Unix Tools Command Shell versus Graphical User Interface • Ease of use • Interactive exploration • Scalability • Complexity • Repetition Example: Find all Tex files in a directory (and its subdirectories) that have not changed in the past 21 days. With an interactive file roller, it is easy to sort files by particular characteristics such as the file extension and the date. But this sorting does not apply to files within subdirectories of the current directory, and it is difficult to apply more than one sort criteria at a time. A command line interface allows us to construct a more complex search. In unix, we find the files we are after by executing the command, find /home/nolan/ -mtime +21 -name ’*.tex’ To find out more about a command you can read the online man pages man find or you can execute the command with the –help option. In this example, the standard output to the screen is piped into the more command which formats it to dispaly one screenful at a time. Hitting the space bar displays the next page of output, the return key displays the next line of output, and the ”q” key quits the display. find --help | more Construct Solution in Pieces • Solve a problem by breaking down into pieces and building back up • Typing vs automation • Error messages - experimentation 1 Example: Find all occurrences of a particular string in several files. The grep command searches the contents of files for a regular expression. In this case we search for the simple character string “/stat141/FINAL” in all files in the directory WebLog that begin with the filename “access”. -

What Is UNIX? the Directory Structure Basic Commands Find
What is UNIX? UNIX is an operating system like Windows on our computers. By operating system, we mean the suite of programs which make the computer work. It is a stable, multi-user, multi-tasking system for servers, desktops and laptops. The Directory Structure All the files are grouped together in the directory structure. The file-system is arranged in a hierarchical structure, like an inverted tree. The top of the hierarchy is traditionally called root (written as a slash / ) Basic commands When you first login, your current working directory is your home directory. In UNIX (.) means the current directory and (..) means the parent of the current directory. find command The find command is used to locate files on a Unix or Linux system. find will search any set of directories you specify for files that match the supplied search criteria. The syntax looks like this: find where-to-look criteria what-to-do All arguments to find are optional, and there are defaults for all parts. where-to-look defaults to . (that is, the current working directory), criteria defaults to none (that is, select all files), and what-to-do (known as the find action) defaults to ‑print (that is, display the names of found files to standard output). Examples: find . –name *.txt (finds all the files ending with txt in current directory and subdirectories) find . -mtime 1 (find all the files modified exact 1 day) find . -mtime -1 (find all the files modified less than 1 day) find . -mtime +1 (find all the files modified more than 1 day) find . -

Linux Command Line Cheat Sheet by Davechild
Linux Command Line Cheat Sheet by DaveChild Bash Commands ls Options Nano Shortcuts uname -a Show system and kernel -a Show all (including hidden) Files head -n1 /etc/issue Show distribution -R Recursive list Ctrl-R Read file mount Show mounted filesystems -r Reverse order Ctrl-O Save file date Show system date -t Sort by last modified Ctrl-X Close file uptime Show uptime -S Sort by file size Cut and Paste whoami Show your username -l Long listing format ALT-A Start marking text man command Show manual for command -1 One file per line CTRL-K Cut marked text or line -m Comma-separated output CTRL-U Paste text Bash Shortcuts -Q Quoted output Navigate File CTRL-c Stop current command ALT-/ End of file Search Files CTRL-z Sleep program CTRL-A Beginning of line CTRL-a Go to start of line grep pattern Search for pattern in files CTRL-E End of line files CTRL-e Go to end of line CTRL-C Show line number grep -i Case insensitive search CTRL-u Cut from start of line CTRL-_ Go to line number grep -r Recursive search CTRL-k Cut to end of line Search File grep -v Inverted search CTRL-r Search history CTRL-W Find find /dir/ - Find files starting with name in dir !! Repeat last command ALT-W Find next name name* !abc Run last command starting with abc CTRL-\ Search and replace find /dir/ -user Find files owned by name in dir !abc:p Print last command starting with abc name More nano info at: !$ Last argument of previous command find /dir/ - Find files modifed less than num http://www.nano-editor.org/docs.php !* All arguments of previous command mmin num minutes ago in dir Screen Shortcuts ^abc^123 Run previous command, replacing abc whereis Find binary / source / manual for with 123 command command screen Start a screen session. -

Node and Edge Attributes
Cytoscape User Manual Table of Contents Cytoscape User Manual ........................................................................................................ 3 Introduction ...................................................................................................................... 48 Development .............................................................................................................. 4 License ...................................................................................................................... 4 What’s New in 2.7 ....................................................................................................... 4 Please Cite Cytoscape! ................................................................................................. 7 Launching Cytoscape ........................................................................................................... 8 System requirements .................................................................................................... 8 Getting Started .......................................................................................................... 56 Quick Tour of Cytoscape ..................................................................................................... 12 The Menus ............................................................................................................... 15 Network Management ................................................................................................. 18 The -

Networking TCP/IP Troubleshooting 7.1
IBM IBM i Networking TCP/IP troubleshooting 7.1 IBM IBM i Networking TCP/IP troubleshooting 7.1 Note Before using this information and the product it supports, read the information in “Notices,” on page 79. This edition applies to IBM i 7.1 (product number 5770-SS1) and to all subsequent releases and modifications until otherwise indicated in new editions. This version does not run on all reduced instruction set computer (RISC) models nor does it run on CISC models. © Copyright IBM Corporation 1997, 2008. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents TCP/IP troubleshooting ........ 1 Server table ............ 34 PDF file for TCP/IP troubleshooting ...... 1 Checking jobs, job logs, and message logs .. 63 Troubleshooting tools and techniques ...... 1 Verifying that necessary jobs exist .... 64 Tools to verify your network structure ..... 1 Checking the job logs for error messages Netstat .............. 1 and other indication of problems .... 65 Using Netstat from a character-based Changing the message logging level on job interface ............. 2 descriptions and active jobs ...... 65 Using Netstat from System i Navigator .. 4 Other job considerations ....... 66 Ping ............... 7 Checking for active filter rules ...... 67 Using Ping from a character-based interface 7 Verifying system startup considerations for Using Ping from System i Navigator ... 10 networking ............ 68 Common error messages ....... 13 Starting subsystems ........ 68 PING parameters ......... 14 Starting TCP/IP .......... 68 Trace route ............ 14 Starting interfaces ......... 69 Using trace route from a character-based Starting servers .......... 69 interface ............ 15 Timing considerations ........ 70 Using trace route from System i Navigator 15 Varying on lines, controllers, and devices . -

GNU Findutils Finding Files Version 4.8.0, 7 January 2021
GNU Findutils Finding files version 4.8.0, 7 January 2021 by David MacKenzie and James Youngman This manual documents version 4.8.0 of the GNU utilities for finding files that match certain criteria and performing various operations on them. Copyright c 1994{2021 Free Software Foundation, Inc. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.3 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts. A copy of the license is included in the section entitled \GNU Free Documentation License". i Table of Contents 1 Introduction ::::::::::::::::::::::::::::::::::::: 1 1.1 Scope :::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 1 1.2 Overview ::::::::::::::::::::::::::::::::::::::::::::::::::::::: 2 2 Finding Files ::::::::::::::::::::::::::::::::::::: 4 2.1 find Expressions ::::::::::::::::::::::::::::::::::::::::::::::: 4 2.2 Name :::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 4 2.2.1 Base Name Patterns ::::::::::::::::::::::::::::::::::::::: 5 2.2.2 Full Name Patterns :::::::::::::::::::::::::::::::::::::::: 5 2.2.3 Fast Full Name Search ::::::::::::::::::::::::::::::::::::: 7 2.2.4 Shell Pattern Matching :::::::::::::::::::::::::::::::::::: 8 2.3 Links ::::::::::::::::::::::::::::::::::::::::::::::::::::::::::: 8 2.3.1 Symbolic Links :::::::::::::::::::::::::::::::::::::::::::: 8 2.3.2 Hard Links ::::::::::::::::::::::::::::::::::::::::::::::: 10 2.4 Time -

Partition.Pdf
Linux Partition HOWTO Anthony Lissot Revision History Revision 3.5 26 Dec 2005 reorganized document page ordering. added page on setting up swap space. added page of partition labels. updated max swap size values in section 4. added instructions on making ext2/3 file systems. broken links identified by Richard Calmbach are fixed. created an XML version. Revision 3.4.4 08 March 2004 synchronized SGML version with HTML version. Updated lilo placement and swap size discussion. Revision 3.3 04 April 2003 synchronized SGML and HTML versions Revision 3.3 10 July 2001 Corrected Section 6, calculation of cylinder numbers Revision 3.2 1 September 2000 Dan Scott provides sgml conversion 2 Oct. 2000. Rewrote Introduction. Rewrote discussion on device names in Logical Devices. Reorganized Partition Types. Edited Partition Requirements. Added Recovering a deleted partition table. Revision 3.1 12 June 2000 Corrected swap size limitation in Partition Requirements, updated various links in Introduction, added submitted example in How to Partition with fdisk, added file system discussion in Partition Requirements. Revision 3.0 1 May 2000 First revision by Anthony Lissot based on Linux Partition HOWTO by Kristian Koehntopp. Revision 2.4 3 November 1997 Last revision by Kristian Koehntopp. This Linux Mini−HOWTO teaches you how to plan and create partitions on IDE and SCSI hard drives. It discusses partitioning terminology and considers size and location issues. Use of the fdisk partitioning utility for creating and recovering of partition tables is covered. The most recent version of this document is here. The Turkish translation is here. Linux Partition HOWTO Table of Contents 1. -

Partitioning Disks with Parted
Partitioning Disks with parted Author: Yogesh Babar Technical Reviewer: Chris Negus 10/6/2017 Storage devices in Linux (such as hard drives and USB drives) need to be structured in some way before use. In most cases, large storage devices are divided into separate sections, which in Linux are referred to as partitions. A popular tool for creating, removing and otherwise manipulating disk partitions in Linux is the parted command. Procedures in this tech brief step you through different ways of using the parted command to work with Linux partitions. UNDERSTANDING PARTED The parted command is particularly useful with large disk devices and many disk partitions. Differences between parted and the more common fdisk and cfdisk commands include: • GPT Format: The parted command can create can be used to create Globally Unique Identifiers Partition Tables (GPT), while fdisk and cfdisk are limited to msdos partition tables. • Larger disks: An msdos partition table can only format up to 2TB of disk space (although up to 16TB is possible in some cases). A GPT partition table, however, have the potential to address up to 8 zebibytes of space. • More partitions: Using primary and extended partitions, msdos partition tables allow only 16 partitions. With GPT, you get up to 128 partitions by default and can choose to have many more. • Reliability: Only one copy of the partition table is stored in an msdos partition. GPT keeps two copies of the partition table (at the beginning and end of the disk). The GPT also uses a CRC checksum to check the partition table's integrity (which is not done with msdos partitions). -

From DOS/Windows to Linux HOWTO from DOS/Windows to Linux HOWTO
From DOS/Windows to Linux HOWTO From DOS/Windows to Linux HOWTO Table of Contents From DOS/Windows to Linux HOWTO ........................................................................................................1 By Guido Gonzato, ggonza at tin.it.........................................................................................................1 1.Introduction...........................................................................................................................................1 2.For the Impatient...................................................................................................................................1 3.Meet bash..............................................................................................................................................1 4.Files and Programs................................................................................................................................1 5.Using Directories .................................................................................................................................2 6.Floppies, Hard Disks, and the Like ......................................................................................................2 7.What About Windows?.........................................................................................................................2 8.Tailoring the System.............................................................................................................................2 9.Networking: -
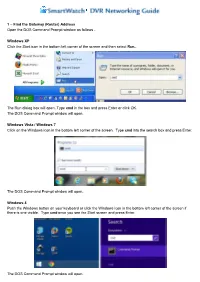
(Router) Address Open the DOS Command Prompt Window As Follows
1 – Find the Gateway (Router) Address Open the DOS Command Prompt window as follows - Windows XP Click the Start icon in the bottom left corner of the screen and then select Run... The Run dialog box will open. Type cmd in the box and press Enter or click OK. The DOS Command Prompt window will open. Windows Vista / Windows 7 Click on the Windows icon in the bottom left corner of the screen. Type cmd into the search box and press Enter. The DOS Command Prompt window will open. Windows 8 Push the Windows button on your keyboard or click the Windows icon in the bottom left corner of the screen if there is one visible. Type cmd once you see the Start screen and press Enter. The DOS Command Prompt window will open. In the DOS Command Prompt window, type ipconfig and then press Enter. You will see information relating to the computer’s network settings. The IPv4 Address is the local IP address of the computer you are using. The Gateway address is the router’s address. The DVR's IP address needs to be in the same range as these – i.e. the first three numbers need to be the same, but the last one different. If ipconfig returned a Gateway address of 10.10.0.1, the DVR would have an address of 10.10.0.xxx where xxx is between 2 and 254. In the above screenshot, the PC's IP address is 192.168.1.77, the Subnet Mask is 255.255.255.0 and the Gateway is 192.168.1.254.