Intel® Itanium® Assembler User's Guide
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Design and Implementation of Pentium-M Based Floswitch for Intracluster Communication Veerappa Chikkagoudar, Dr
Design and Implementation of Pentium-M Based Floswitch for Intracluster Communication Veerappa chikkagoudar, Dr. U. N. Sinha, Prof. B. L. Desai. [email protected], [email protected], [email protected] Department of Electronics and Communication B. V. Bhoomaraddi college of Engg. And Tech. Hubli-580031 Abstract: aero dynamical problems, [1].Since 1986, six Flosolver MK6 is a Parallel processing system, generations of Flosolver machine have evolved based on distributed memory concept and built namely Flosolver MK-1, MK-2, MK-3, MK-4, MK-5 around Pentium-III processors, which acts as and MK-6. processing elements (PEs). Communication Flosolver MK-6 is the latest of the parallel between processing elements is very important, computer based on 128 Pentium III processors which is done through hardware switch called (which act as processing elements, PEs) in 64 dual Floswitch. Floswitch supports both message processor boards each with 1GB RAM and 80 GB passing as well as message processing. Message HDD. It is essentially a distributed memory system. processing is a unique feature of Floswitch. A group of four Dual processor boards with a Floswitch and an optical module is a natural cluster. In existing MK-6 system, communication 16 such clusters form the system. Processing between PEs is done through the Intel 486-based elements (PEs) communicate through Floswitch (a Floswitch, which operates at 32MHz and has 32- communication switch) using PCI-DPM interface bit wide data path. The data transfer rate and card. Clusters communicate through Optical module. floating point computation of existing switch need to be increased. -

Inside Intel® Core™ Microarchitecture Setting New Standards for Energy-Efficient Performance
White Paper Inside Intel® Core™ Microarchitecture Setting New Standards for Energy-Efficient Performance Ofri Wechsler Intel Fellow, Mobility Group Director, Mobility Microprocessor Architecture Intel Corporation White Paper Inside Intel®Core™ Microarchitecture Introduction Introduction 2 The Intel® Core™ microarchitecture is a new foundation for Intel®Core™ Microarchitecture Design Goals 3 Intel® architecture-based desktop, mobile, and mainstream server multi-core processors. This state-of-the-art multi-core optimized Delivering Energy-Efficient Performance 4 and power-efficient microarchitecture is designed to deliver Intel®Core™ Microarchitecture Innovations 5 increased performance and performance-per-watt—thus increasing Intel® Wide Dynamic Execution 6 overall energy efficiency. This new microarchitecture extends the energy efficient philosophy first delivered in Intel's mobile Intel® Intelligent Power Capability 8 microarchitecture found in the Intel® Pentium® M processor, and Intel® Advanced Smart Cache 8 greatly enhances it with many new and leading edge microar- Intel® Smart Memory Access 9 chitectural innovations as well as existing Intel NetBurst® microarchitecture features. What’s more, it incorporates many Intel® Advanced Digital Media Boost 10 new and significant innovations designed to optimize the Intel®Core™ Microarchitecture and Software 11 power, performance, and scalability of multi-core processors. Summary 12 The Intel Core microarchitecture shows Intel’s continued Learn More 12 innovation by delivering both greater energy efficiency Author Biographies 12 and compute capability required for the new workloads and usage models now making their way across computing. With its higher performance and low power, the new Intel Core microarchitecture will be the basis for many new solutions and form factors. In the home, these include higher performing, ultra-quiet, sleek and low-power computer designs, and new advances in more sophisticated, user-friendly entertainment systems. -

Pentium II Processor Performance Brief
PentiumÒ II Processor Performance Brief January 1998 Order Number: 243336-004 Information in this document is provided in connection with Intel products. No license, express or implied, by estoppel or otherwise, to any intellectual property rights is granted by this document. Except as provided in Intel’s Terms and Conditions of Sale for such products, Intel assumes no liability whatsoever, and Intel disclaims any express or implied warranty, relating to sale and/or use of Intel products including liability or warranties relating to fitness for a particular purpose, merchantability, or infringement of any patent, copyright or other intellectual property right. Intel products are not intended for use in medical, life saving, or life sustaining applications. Intel may make changes to specifications and product descriptions at any time, without notice. Designers must not rely on the absence or characteristics of any features or instructions marked "reserved" or "undefined." Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. The Pentium® II processor may contain design defects or errors known as errata. Current characterized errata are available on request. MPEG is an international standard for video compression/decompression promoted by ISO. Implementations of MPEG CODECs, or MPEG enabled platforms may require licenses from various entities, including Intel Corporation. Contact your local Intel sales office or your distributor to obtain the latest specifications and before placing your product order. Copies of documents which have an ordering number and are referenced in this document, or other Intel literature, may be obtained from by calling 1-800-548-4725 or by visiting Intel’s website at http://www.intel.com. -

2. Instruction Set Architecture
!1 2. ISA Gebotys ECE 222 2. Instruction Set Architecture “Ideally, your initial instruction set should be an exemplar, …” " Instruction set architecture (ISA) defines the interface between the hardware and software# " instruction set is the language of the computer# " RISCV instructions are 32-bits, instruction[31:0]# " RISC-V assembly1 language notation # " uses 64-bit registers, 64-bits refer to double word, 32-bits refers to word (8-bits is byte).# " there are 32 registers, namely x0-x31, where x0 is always zero # " to perform arithmetic operations (add, sub, shift, logical) data must always be in registers # " the number of variables in programs is typically larger than 32, hence ‘less frequently used’ [or those used later] variables are ‘spilled’ into memory [spilling registers]# " registers are faster and more energy e$cient than memory# " for embedded applications where code size is important, a 16-bit instruction set exists, RISC-V compressed (e.g. others exist also ARM Thumb and Thumb2)# " byte addressing is used, little endian (where address of 64-bit word refers to address of ‘little' or rightmost byte, [containing bit 0 of word]) so sequential double word accesses di%er by 8 e.g. byte address 0 holds the first double word and byte address 8 holds next double word. (Byte addressing allows the supports of two byte instructions)# " memory contains 261 memory words - using load/store instructions e.g. 64-bits available (bits 63 downto 0, 3 of those bits are used for byte addressing, leaving 61 bits)# " Program counter register (PC) -

Intel Architecture Optimization Manual
Intel Architecture Optimization Manual Order Number 242816-003 1997 5/5/97 11:38 AM FRONT.DOC Information in this document is provided in connection with Intel products. No license, express or implied, by estoppel or otherwise, to any intellectual property rights is granted by this document. Except as provided in Intel's Terms and Conditions of Sale for such products, Intel assumes no liability whatsoever, and Intel disclaims any express or implied warranty, relating to sale and/or use of Intel products including liability or warranties relating to fitness for a particular purpose, merchantability, or infringement of any patent, copyright or other intellectual property right. Intel products are not intended for use in medical, life saving, or life sustaining applications. Intel may make changes to specifications and product descriptions at any time, without notice. Designers must not rely on the absence or characteristics of any features or instructions marked "reserved" or "undefined." Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. The Pentium®, Pentium Pro and Pentium II processors may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Such errata are not covered by Intel’s warranty. Current characterized errata are available on request. Contact your local Intel sales office or your distributor to obtain the latest specifications before placing your product order. Copies of documents which have an ordering number and are referenced in this document, or other Intel literature, may be obtained from: Intel Corporation P.O. -

Unit – I Computer Architecture and Operating System – Scs1315
SCHOOL OF ELECTRICAL AND ELECTRONICS DEPARTMENT OF ELECTRONICS AND COMMMUNICATION ENGINEERING UNIT – I COMPUTER ARCHITECTURE AND OPERATING SYSTEM – SCS1315 UNIT.1 INTRODUCTION Central Processing Unit - Introduction - General Register Organization - Stack organization -- Basic computer Organization - Computer Registers - Computer Instructions - Instruction Cycle. Arithmetic, Logic, Shift Microoperations- Arithmetic Logic Shift Unit -Example Architectures: MIPS, Power PC, RISC, CISC Central Processing Unit The part of the computer that performs the bulk of data-processing operations is called the central processing unit CPU. The CPU is made up of three major parts, as shown in Fig.1 Fig 1. Major components of CPU. The register set stores intermediate data used during the execution of the instructions. The arithmetic logic unit (ALU) performs the required microoperations for executing the instructions. The control unit supervises the transfer of information among the registers and instructs the ALU as to which operation to perform. General Register Organization When a large number of registers are included in the CPU, it is most efficient to connect them through a common bus system. The registers communicate with each other not only for direct data transfers, but also while performing various microoperations. Hence it is necessary to provide a common unit that can perform all the arithmetic, logic, and shift microoperations in the processor. A bus organization for seven CPU registers is shown in Fig.2. The output of each register is connected to two multiplexers (MUX) to form the two buses A and B. The selection lines in each multiplexer select one register or the input data for the particular bus. The A and B buses form the inputs to a common arithmetic logic unit (ALU). -

S.D.M COLLEGE of ENGINEERING and TECHNOLOGY Sridhar Y
VISVESVARAYA TECHNOLOGICAL UNIVERSITY S.D.M COLLEGE OF ENGINEERING AND TECHNOLOGY A seminar report on CUDA Submitted by Sridhar Y 2sd06cs108 8th semester DEPARTMENT OF COMPUTER SCIENCE ENGINEERING 2009-10 Page 1 VISVESVARAYA TECHNOLOGICAL UNIVERSITY S.D.M COLLEGE OF ENGINEERING AND TECHNOLOGY DEPARTMENT OF COMPUTER SCIENCE ENGINEERING CERTIFICATE Certified that the seminar work entitled “CUDA” is a bonafide work presented by Sridhar Y bearing USN 2SD06CS108 in a partial fulfillment for the award of degree of Bachelor of Engineering in Computer Science Engineering of the Visvesvaraya Technological University, Belgaum during the year 2009-10. The seminar report has been approved as it satisfies the academic requirements with respect to seminar work presented for the Bachelor of Engineering Degree. Staff in charge H.O.D CSE Name: Sridhar Y USN: 2SD06CS108 Page 2 Contents 1. Introduction 4 2. Evolution of GPU programming and CUDA 5 3. CUDA Structure for parallel processing 9 4. Programming model of CUDA 10 5. Portability and Security of the code 12 6. Managing Threads with CUDA 14 7. Elimination of Deadlocks in CUDA 17 8. Data distribution among the Thread Processes in CUDA 14 9. Challenges in CUDA for the Developers 19 10. The Pros and Cons of CUDA 19 11. Conclusions 21 Bibliography 21 Page 3 Abstract Parallel processing on multi core processors is the industry’s biggest software challenge, but the real problem is there are too many solutions. One of them is Nvidia’s Compute Unified Device Architecture (CUDA), a software platform for massively parallel high performance computing on the powerful Graphics Processing Units (GPUs). -

Intel® Processor Graphics: Architecture & Programming
Intel® Processor Graphics: Architecture & Programming Jason Ross – Principal Engineer, GPU Architect Ken Lueh – Sr. Principal Engineer, Compiler Architect Subramaniam Maiyuran – Sr. Principal Engineer, GPU Architect Agenda 1. Introduction (Jason) 2. Compute Architecture Evolution (Jason) 3. Chip Level Architecture (Jason) Subslices, slices, products 4. Gen Compute Architecture (Maiyuran) Execution units 5. Instruction Set Architecture (Ken) 6. Memory Sharing Architecture (Jason) 7. Mapping Programming Models to Architecture (Jason) 8. Summary 2 Compute Applications * “The Intel® Iris™ Pro graphics and the Intel® Core™ i7 processor are … allowing me to do all of this while the graphics and video * never stopping” Dave Helmly, Solution Consulting Pro Video/Audio, Adobe Adobe Premiere Pro demonstration: http://www.youtube.com/watch?v=u0J57J6Hppg “We are very pleased that Intel is fully supporting OpenCL. DirectX11.2 We think there is a bright future for this technology.” Michael Compute Shader Bryant, Director of Marketing, Sony Creative Software Vegas* Software Family by Sony* * Optimized with OpenCL and Intel® Processor Graphics http://www.youtube.com/watch?v=_KHVOCwTdno * “Implementing [OpenCL] in our award-winning video editor, * PowerDirector, has created tremendous value for our customers by enabling big gains in video processing speed and, consequently, a significant reduction in total video editing time.” Louis Chen, Assistant Vice President, CyberLink Corp. * "Capture One Pro introduces …optimizations for Haswell, enabling remarkably -
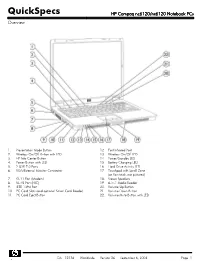
HP Compaq Nc6120/Nx6120 Notebook Pcs Overview
QuickSpecs HP Compaq nc6120/nx6120 Notebook PCs Overview 1. Presentation Mode Button 12. Fast Infrared Port 2. Wireless On/Off Button with LED 13. Wireless On/Off LED 3. HP Info Center Button 14. Power/Standby LED 4. Power Button with LED 15. Battery Charging LED 5. 2 USB 2.0 Ports 16 Hard Drive Activity LED 6. VGA/External Monitor Connector 17. Touchpad with Scroll Zone (or Pointstick, not pictured) 7. RJ-11 Port (Modem) 18. Stereo Speakers 8. RJ-45 Port (NIC) 19. 6-in-1 Media Reader 9. IEEE 1394 Port 20. Volume Up Button 10. PC Card Slots (and optional Smart Card Reader) 21. Volume Down Button 11. PC Card Eject Button 22. Volume Mute Button with LED DA - 12136 Worldwide — Version 26 — September 6, 2006 Page 1 QuickSpecs HP Compaq nc6120/nx6120 Notebook PCs Overview 1. Headphone Jack 6. Serial Port 2. Microphone Jack 7. Kensington Lock Slot 3. 2 USB 2.0 Ports 8. DC Power Connector 4. Optical Drive 9. Parallel Port 5. Optical Drive Button 10. S-Video TV Out At A Glance Genuine Windows XP Professional, Genuine Windows XP Home Edition (select countries), or FreeDOS Certified for Novell Linux Desktop 9 Intel® Pentium® M processors 730 to 770* or Intel Celeron® M processors 350J to 380* Sleek industrial design starting at 5.82 lb/2.64 kg and 1.2-inch/30.3 mm thin at front Mobile Intel 915GM Express Chipset 256-MB DDR SDRAM, upgradeable to 2048-MB maximum Up to 100-GB 5400 rpm hard drive Intel Graphics Media Accelerator 900 Optional Integrated 802.11a/b/g or 802.11b/g wireless LAN module Support for optional Intel Centrino™ mobile technology Optional integrated Bluetooth® 6-in-1 Media Reader NetXtreme Gigabit Ethernet Controller Choice of Touchpad with scroll zone or Pointstick Protected by one-year or three-year (depending on country and/or model) standard parts and labor warranty - certain restrictions and exclusions apply *Intel's numbering system is not a measurement of performance. -

The Microarchitecture of the Pentium 4 Processor
The Microarchitecture of the Pentium 4 Processor Glenn Hinton, Desktop Platforms Group, Intel Corp. Dave Sager, Desktop Platforms Group, Intel Corp. Mike Upton, Desktop Platforms Group, Intel Corp. Darrell Boggs, Desktop Platforms Group, Intel Corp. Doug Carmean, Desktop Platforms Group, Intel Corp. Alan Kyker, Desktop Platforms Group, Intel Corp. Patrice Roussel, Desktop Platforms Group, Intel Corp. Index words: Pentium® 4 processor, NetBurst™ microarchitecture, Trace Cache, double-pumped ALU, deep pipelining provides an in-depth examination of the features and ABSTRACT functions of the Intel NetBurst microarchitecture. This paper describes the Intel® NetBurst™ ® The Pentium 4 processor is designed to deliver microarchitecture of Intel’s new flagship Pentium 4 performance across applications where end users can truly processor. This microarchitecture is the basis of a new appreciate and experience its performance. For example, family of processors from Intel starting with the Pentium it allows a much better user experience in areas such as 4 processor. The Pentium 4 processor provides a Internet audio and streaming video, image processing, substantial performance gain for many key application video content creation, speech recognition, 3D areas where the end user can truly appreciate the applications and games, multi-media, and multi-tasking difference. user environments. The Pentium 4 processor enables real- In this paper we describe the main features and functions time MPEG2 video encoding and near real-time MPEG4 of the NetBurst microarchitecture. We present the front- encoding, allowing efficient video editing and video end of the machine, including its new form of instruction conferencing. It delivers world-class performance on 3D cache called the Execution Trace Cache. -

X86 Assembly Language Syllabus for Subject: Assembly (Machine) Language
VŠB - Technical University of Ostrava Department of Computer Science, FEECS x86 Assembly Language Syllabus for Subject: Assembly (Machine) Language Ing. Petr Olivka, Ph.D. 2021 e-mail: [email protected] http://poli.cs.vsb.cz Contents 1 Processor Intel i486 and Higher – 32-bit Mode3 1.1 Registers of i486.........................3 1.2 Addressing............................6 1.3 Assembly Language, Machine Code...............6 1.4 Data Types............................6 2 Linking Assembly and C Language Programs7 2.1 Linking C and C Module....................7 2.2 Linking C and ASM Module................... 10 2.3 Variables in Assembly Language................ 11 3 Instruction Set 14 3.1 Moving Instruction........................ 14 3.2 Logical and Bitwise Instruction................. 16 3.3 Arithmetical Instruction..................... 18 3.4 Jump Instructions........................ 20 3.5 String Instructions........................ 21 3.6 Control and Auxiliary Instructions............... 23 3.7 Multiplication and Division Instructions............ 24 4 32-bit Interfacing to C Language 25 4.1 Return Values from Functions.................. 25 4.2 Rules of Registers Usage..................... 25 4.3 Calling Function with Arguments................ 26 4.3.1 Order of Passed Arguments............... 26 4.3.2 Calling the Function and Set Register EBP...... 27 4.3.3 Access to Arguments and Local Variables....... 28 4.3.4 Return from Function, the Stack Cleanup....... 28 4.3.5 Function Example.................... 29 4.4 Typical Examples of Arguments Passed to Functions..... 30 4.5 The Example of Using String Instructions........... 34 5 AMD and Intel x86 Processors – 64-bit Mode 36 5.1 Registers.............................. 36 5.2 Addressing in 64-bit Mode.................... 37 6 64-bit Interfacing to C Language 37 6.1 Return Values.......................... -

Lecture 6: Instruction Set Architecture and the 80X86
Lecture 6: Instruction Set Architecture and the 80x86 Professor Randy H. Katz Computer Science 252 Spring 1996 RHK.S96 1 Review From Last Time • Given sales a function of performance relative to competition, tremendous investment in improving product as reported by performance summary • Good products created when have: – Good benchmarks – Good ways to summarize performance • If not good benchmarks and summary, then choice between improving product for real programs vs. improving product to get more sales=> sales almost always wins • Time is the measure of computer performance! • What about cost? RHK.S96 2 Review: Integrated Circuits Costs IC cost = Die cost + Testing cost + Packaging cost Final test yield Die cost = Wafer cost Dies per Wafer * Die yield Dies per wafer = p * ( Wafer_diam / 2)2 – p * Wafer_diam – Test dies Die Area Ö 2 * Die Area Defects_per_unit_area * Die_Area Die Yield = Wafer yield * { 1 + } 4 Die Cost is goes roughly with area RHK.S96 3 Review From Last Time Price vs. Cost 100% 80% Average Discount 60% Gross Margin 40% Direct Costs 20% Component Costs 0% Mini W/S PC 5 4.7 3.8 4 3.5 Average Discount 3 2.5 Gross Margin 2 1.8 Direct Costs 1.5 1 Component Costs 0 Mini W/S PC RHK.S96 4 Today: Instruction Set Architecture • 1950s to 1960s: Computer Architecture Course Computer Arithmetic • 1970 to mid 1980s: Computer Architecture Course Instruction Set Design, especially ISA appropriate for compilers • 1990s: Computer Architecture Course Design of CPU, memory system, I/O system, Multiprocessors RHK.S96 5 Computer Architecture? . the attributes of a [computing] system as seen by the programmer, i.e.