Generating Adversarial Examples for Discrete Data
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Circus Friends Association Collection Finding Aid
Circus Friends Association Collection Finding Aid University of Sheffield - NFCA Contents Poster - 178R472 Business Records - 178H24 412 Maps, Plans and Charts - 178M16 413 Programmes - 178K43 414 Bibliographies and Catalogues - 178J9 564 Proclamations - 178S5 565 Handbills - 178T40 565 Obituaries, Births, Death and Marriage Certificates - 178Q6 585 Newspaper Cuttings and Scrapbooks - 178G21 585 Correspondence - 178F31 602 Photographs and Postcards - 178C108 604 Original Artwork - 178V11 608 Various - 178Z50 622 Monographs, Articles, Manuscripts and Research Material - 178B30633 Films - 178D13 640 Trade and Advertising Material - 178I22 649 Calendars and Almanacs - 178N5 655 1 Poster - 178R47 178R47.1 poster 30 November 1867 Birmingham, Saturday November 30th 1867, Monday 2 December and during the week Cattle and Dog Shows, Miss Adah Isaacs Menken, Paris & Back for £5, Mazeppa’s, equestrian act, Programme of Scenery and incidents, Sarah’s Young Man, Black type on off white background, Printed at the Theatre Royal Printing Office, Birmingham, 253mm x 753mm Circus Friends Association Collection 178R47.2 poster 1838 Madame Albertazzi, Mdlle. H. Elsler, Mr. Ducrow, Double stud of horses, Mr. Van Amburgh, animal trainer Grieve’s New Scenery, Charlemagne or the Fete of the Forest, Black type on off white backgound, W. Wright Printer, Theatre Royal, Drury Lane, 205mm x 335mm Circus Friends Association Collection 178R47.3 poster 19 October 1885 Berlin, Eln Mexikanermanöver, Mr. Charles Ducos, Horaz und Merkur, Mr. A. Wells, equestrian act, C. Godiewsky, clown, Borax, Mlle. Aguimoff, Das 3 fache Reck, gymnastics, Mlle. Anna Ducos, Damen-Jokey-Rennen, Kohinor, Mme. Bradbury, Adgar, 2 Black type on off white background with decorative border, Druck von H. G. -

The Tarzan Series of Edgar Rice Burroughs
I The Tarzan Series of Edgar Rice Burroughs: Lost Races and Racism in American Popular Culture James R. Nesteby Submitted to the Graduate College of Bowling Green State University in partial fulfillment of the requirements for the degree in Doctor of Philosophy August 1978 Approved: © 1978 JAMES RONALD NESTEBY ALL RIGHTS RESERVED ¡ ¡ in Abstract The Tarzan series of Edgar Rice Burroughs (1875-1950), beginning with the All-Story serialization in 1912 of Tarzan of the Apes (1914 book), reveals deepseated racism in the popular imagination of early twentieth-century American culture. The fictional fantasies of lost races like that ruled by La of Opar (or Atlantis) are interwoven with the realities of racism, particularly toward Afro-Americans and black Africans. In analyzing popular culture, Stith Thompson's Motif-Index of Folk-Literature (1932) and John G. Cawelti's Adventure, Mystery, and Romance (1976) are utilized for their indexing and formula concepts. The groundwork for examining explanations of American culture which occur in Burroughs' science fantasies about Tarzan is provided by Ray R. Browne, publisher of The Journal of Popular Culture and The Journal of American Culture, and by Gene Wise, author of American Historical Explanations (1973). The lost race tradition and its relationship to racism in American popular fiction is explored through the inner earth motif popularized by John Cleves Symmes' Symzonla: A Voyage of Discovery (1820) and Edgar Allan Poe's The narrative of A. Gordon Pym (1838); Burroughs frequently uses the motif in his perennially popular romances of adventure which have made Tarzan of the Apes (Lord Greystoke) an ubiquitous feature of American culture. -

Songs by Title
Karaoke Song Book Songs by Title Title Artist Title Artist #1 Nelly 18 And Life Skid Row #1 Crush Garbage 18 'til I Die Adams, Bryan #Dream Lennon, John 18 Yellow Roses Darin, Bobby (doo Wop) That Thing Parody 19 2000 Gorillaz (I Hate) Everything About You Three Days Grace 19 2000 Gorrilaz (I Would Do) Anything For Love Meatloaf 19 Somethin' Mark Wills (If You're Not In It For Love) I'm Outta Here Twain, Shania 19 Somethin' Wills, Mark (I'm Not Your) Steppin' Stone Monkees, The 19 SOMETHING WILLS,MARK (Now & Then) There's A Fool Such As I Presley, Elvis 192000 Gorillaz (Our Love) Don't Throw It All Away Andy Gibb 1969 Stegall, Keith (Sitting On The) Dock Of The Bay Redding, Otis 1979 Smashing Pumpkins (Theme From) The Monkees Monkees, The 1982 Randy Travis (you Drive Me) Crazy Britney Spears 1982 Travis, Randy (Your Love Has Lifted Me) Higher And Higher Coolidge, Rita 1985 BOWLING FOR SOUP 03 Bonnie & Clyde Jay Z & Beyonce 1985 Bowling For Soup 03 Bonnie & Clyde Jay Z & Beyonce Knowles 1985 BOWLING FOR SOUP '03 Bonnie & Clyde Jay Z & Beyonce Knowles 1985 Bowling For Soup 03 Bonnie And Clyde Jay Z & Beyonce 1999 Prince 1 2 3 Estefan, Gloria 1999 Prince & Revolution 1 Thing Amerie 1999 Wilkinsons, The 1, 2, 3, 4, Sumpin' New Coolio 19Th Nervous Breakdown Rolling Stones, The 1,2 STEP CIARA & M. ELLIOTT 2 Become 1 Jewel 10 Days Late Third Eye Blind 2 Become 1 Spice Girls 10 Min Sorry We've Stopped Taking Requests 2 Become 1 Spice Girls, The 10 Min The Karaoke Show Is Over 2 Become One SPICE GIRLS 10 Min Welcome To Karaoke Show 2 Faced Louise 10 Out Of 10 Louchie Lou 2 Find U Jewel 10 Rounds With Jose Cuervo Byrd, Tracy 2 For The Show Trooper 10 Seconds Down Sugar Ray 2 Legit 2 Quit Hammer, M.C. -

Songs by Title
Songs by Title Title Artist Versions Title Artist Versions #1 Crush Garbage SC 1999 Prince PI SC #Selfie Chainsmokers SS 2 Become 1 Spice Girls DK MM SC (Can't Stop) Giving You Up Kylie Minogue SF 2 Hearts Kylie Minogue MR (Don't Take Her) She's All I Tracy Byrd MM 2 Minutes To Midnight Iron Maiden SF Got 2 Stars Camp Rock DI (I Don't Know Why) But I Clarence Frogman Henry MM 2 Step DJ Unk PH Do 2000 Miles Pretenders, The ZO (I'll Never Be) Maria Sandra SF 21 Guns Green Day QH SF Magdalena 21 Questions (Feat. Nate 50 Cent SC (Take Me Home) Country Toots & The Maytals SC Dogg) Roads 21st Century Breakdown Green Day MR SF (This Ain't) No Thinkin' Trace Adkins MM Thing 21st Century Christmas Cliff Richard MR + 1 Martin Solveig SF 21st Century Girl Willow Smith SF '03 Bonnie & Clyde (Feat. Jay-Z SC 22 Lily Allen SF Beyonce) Taylor Swift MR SF ZP 1, 2 Step Ciara BH SC SF SI 23 (Feat. Miley Cyrus, Wiz Mike Will Made-It PH SP Khalifa And Juicy J) 10 Days Late Third Eye Blind SC 24 Hours At A Time Marshall Tucker Band SG 10 Million People Example SF 24 Hours From Tulsa Gene Pitney MM 10 Minutes Until The Utilities UT 24-7 Kevon Edmonds SC Karaoke Starts (5 Min 24K Magic Bruno Mars MR SF Track) 24's Richgirl & Bun B PH 10 Seconds Jazmine Sullivan PH 25 Miles Edwin Starr SC 10,000 Promises Backstreet Boys BS 25 Minutes To Go Johnny Cash SF 100 Percent Cowboy Jason Meadows PH 25 Or 6 To 4 Chicago BS PI SC 100 Years Five For Fighting SC 26 Cents Wilkinsons, The MM SC SF 100% Chance Of Rain Gary Morris SC 26 Miles Four Preps, The SA 100% Pure Love Crystal Waters PI SC 29 Nights Danni Leigh SC 10000 Nights Alphabeat MR SF 29 Palms Robert Plant SC SF 10th Avenue Freeze Out Bruce Springsteen SG 3 Britney Spears CB MR PH 1-2-3 Gloria Estefan BS SC QH SF Len Barry DK 3 AM Matchbox 20 MM SC 1-2-3 Redlight 1910 Fruitgum Co. -
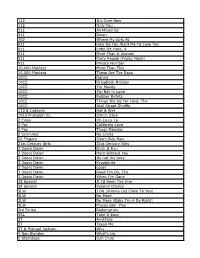
112 It's Over Now 112 Only You 311 All Mixed up 311 Down
112 It's Over Now 112 Only You 311 All Mixed Up 311 Down 702 Where My Girls At 911 How Do You Want Me To Love You 911 Little Bit More, A 911 More Than A Woman 911 Party People (Friday Night) 911 Private Number 10,000 Maniacs More Than This 10,000 Maniacs These Are The Days 10CC Donna 10CC Dreadlock Holiday 10CC I'm Mandy 10CC I'm Not In Love 10CC Rubber Bullets 10CC Things We Do For Love, The 10CC Wall Street Shuffle 112 & Ludacris Hot & Wet 1910 Fruitgum Co. Simon Says 2 Evisa Oh La La La 2 Pac California Love 2 Pac Thugz Mansion 2 Unlimited No Limits 20 Fingers Short Dick Man 21st Century Girls 21st Century Girls 3 Doors Down Duck & Run 3 Doors Down Here Without You 3 Doors Down Its not my time 3 Doors Down Kryptonite 3 Doors Down Loser 3 Doors Down Road I'm On, The 3 Doors Down When I'm Gone 38 Special If I'd Been The One 38 Special Second Chance 3LW I Do (Wanna Get Close To You) 3LW No More 3LW No More (Baby I'm A Do Right) 3LW Playas Gon' Play 3rd Strike Redemption 3SL Take It Easy 3T Anything 3T Tease Me 3T & Michael Jackson Why 4 Non Blondes What's Up 5 Stairsteps Ooh Child 50 Cent Disco Inferno 50 Cent If I Can't 50 Cent In Da Club 50 Cent In Da Club 50 Cent P.I.M.P. (Radio Version) 50 Cent Wanksta 50 Cent & Eminem Patiently Waiting 50 Cent & Nate Dogg 21 Questions 5th Dimension Aquarius_Let the sunshine inB 5th Dimension One less Bell to answer 5th Dimension Stoned Soul Picnic 5th Dimension Up Up & Away 5th Dimension Wedding Blue Bells 5th Dimension, The Last Night I Didn't Get To Sleep At All 69 Boys Tootsie Roll 8 Stops 7 Question -

Tarzan Ape Man Movie Free Download
Tarzan Ape Man Movie Free Download 1 / 4 Tarzan Ape Man Movie Free Download 2 / 4 3 / 4 Watch Tarzan the Ape Man Online Full Movie, tarzan the ape man full hd with English subtitle. ... Download. Watch Tarzan the Ape Man 4K FOR FREE ... While on an African expedition with her father, Jane Parker meets Tarzan, and the two .... John Derek directed this 1981 vanity production of the Tarzan tale as a ... By opting to have your ticket verified for this movie, you are allowing us to check the .... Based on MGM's original 1932 movie, the new version tells Jane's story in a lusty, romantic tale of a determined woman who finds adventure and romance.. movies. Tarzan the Ape Man trailer. by: W.S. Van Dyke. Publication date: 1932. Usage: Attribution 3.0. Topics: Adventure, Romance. Publisher .... Tarzan the Ape Man movie download Download Tarzan the Ape Man Tarzan the Ape Man (1932) - IMDb James Parker and Harry Holt are on an expedition in .... This book is available for free download in a number of formats - including epub, pdf, ... king ape Kerchak, Clayton is renamed Tarzan (''White Skin'' in the ape language) .... An exciting read to reawaken the "wild man" in all of us! ... You will note many differences from the many movie adaptations, though a few come close.. Tarzan... the Ape Man watch movie free download... Tarzan... the Ape Man watch... Tarzan... the Ape Man free... Tarzan... the Ape Man .... While on an African expedition with her father, Jane Parker meets Tarzan, and the two ... Bo Derek and C.J. -

Songs by Artist
Songs by Artist Title Title (Hed) Planet Earth 2 Live Crew Bartender We Want Some Pussy Blackout 2 Pistols Other Side She Got It +44 You Know Me When Your Heart Stops Beating 20 Fingers 10 Years Short Dick Man Beautiful 21 Demands Through The Iris Give Me A Minute Wasteland 3 Doors Down 10,000 Maniacs Away From The Sun Because The Night Be Like That Candy Everybody Wants Behind Those Eyes More Than This Better Life, The These Are The Days Citizen Soldier Trouble Me Duck & Run 100 Proof Aged In Soul Every Time You Go Somebody's Been Sleeping Here By Me 10CC Here Without You I'm Not In Love It's Not My Time Things We Do For Love, The Kryptonite 112 Landing In London Come See Me Let Me Be Myself Cupid Let Me Go Dance With Me Live For Today Hot & Wet Loser It's Over Now Road I'm On, The Na Na Na So I Need You Peaches & Cream Train Right Here For You When I'm Gone U Already Know When You're Young 12 Gauge 3 Of Hearts Dunkie Butt Arizona Rain 12 Stones Love Is Enough Far Away 30 Seconds To Mars Way I Fell, The Closer To The Edge We Are One Kill, The 1910 Fruitgum Co. Kings And Queens 1, 2, 3 Red Light This Is War Simon Says Up In The Air (Explicit) 2 Chainz Yesterday Birthday Song (Explicit) 311 I'm Different (Explicit) All Mixed Up Spend It Amber 2 Live Crew Beyond The Grey Sky Doo Wah Diddy Creatures (For A While) Me So Horny Don't Tread On Me Song List Generator® Printed 5/12/2021 Page 1 of 334 Licensed to Chris Avis Songs by Artist Title Title 311 4Him First Straw Sacred Hideaway Hey You Where There Is Faith I'll Be Here Awhile Who You Are Love Song 5 Stairsteps, The You Wouldn't Believe O-O-H Child 38 Special 50 Cent Back Where You Belong 21 Questions Caught Up In You Baby By Me Hold On Loosely Best Friend If I'd Been The One Candy Shop Rockin' Into The Night Disco Inferno Second Chance Hustler's Ambition Teacher, Teacher If I Can't Wild-Eyed Southern Boys In Da Club 3LW Just A Lil' Bit I Do (Wanna Get Close To You) Outlaw No More (Baby I'ma Do Right) Outta Control Playas Gon' Play Outta Control (Remix Version) 3OH!3 P.I.M.P. -

Tarzan and His Mate
September 16, (VII:4) TARZAN AND HIS MATE (1934, CEDRIC GIBBONS: 23 MGM,116 minutes) March 1893, Dublin, Directed by Cedric Gibbons and Jack Ireland—26 July 1960, Conway (co-director, uncredited) Hollywood. This is the Writing Edgar Rice Burroughs only film directed by characters, Leon Gordon and Howard Cedric Gibbons, and he Emmet Rogers adaptation, James only directed the first few Kevin McGuinness screenplay weeks of it. Most of the Produced by Bernard H. Hyman work was done by Jack Cinematography Charles G. Clarke Conway, who wasn’t and Clyde De Vinna credited on the film. Film Editing Tom Held Gibbons is best known as an Art Direction A. Arnold Gillespie art director for MGM Special Effects James Basevi Photographic Visual Effects Irving G. films. He is the most important and influential art director in American film. Ries(uncredited) He did 1500 of them, he designed the Oscar statuette, he was nominated for 37 Johnny Weissmuller .... Tarzan Oscars and won it 11 times. Some of his more famous films: Lust for Life Maureen O'Sullivan .... Jane Parker (1956), High Society (1956), Forbidden Planet (1956), Blackboard Jungle Neil Hamilton .... Harry Holt (1955), Bad Day at Black Rock (1955), Brigadoon (1954), Singin' in the Paul Cavanagh .... Martin Arlington Rain (1952), An American in Paris, (1951), The Asphalt Jungle (1950), The Forrester Harvey .... Beamish Picture of Dorian Gray (1945), The Thin Man (1934), Grand Hotel (1932), Nathan Curry .... Saidi and The Unwritten Code (1919). Ray Corrigan .... double: Johnny Weissmuller (uncredited) JACK CONWAY (17 July 1887, Graceland, MN—11 October 1952, Pacific George Emerson... -

Tarzan Als Jane's Constructie Van Geluk De Oppositie Natuur/Cultuur in Een Drietal Tarzanfilms
Moniel Verhoeven Tarzan als Jane's constructie van geluk De oppositie natuur/cultuur in een drietal Tarzanfilms Sinds 1918 zijn er ruim veertig Tarzanfilms gemaakt in Hollywood. In deze films worden niet alleen avonturen van Tarzan en Jane geschil- derd; onder dit oppervlakte-niveau vertellen ze nog meer. Dit artikel beoogt de logica op te sporen van drie Tarzanfilms: TARZAN THE APE MAN, TARZAN AND HIS MATE en TARZAN FINDS A SON.' Het drietal wordt opgevat als een deel van de Tarzanmythe.9it is een mythe- complex waarin de verhouding tussen natuur en cultuur centraal staat. Op het eerste gezicht lijkt Tarzan natuur te representeren en Jane cul- tuur. Na grondige analyse blijkt echter dat in de loop van de films de oppositie natuur/cultuur transformeert en vervangen wordt door an- dere oppositieparen zoals wildlbeschaafd; het paar mannelijk/vrouwe- lijk neemt hierbij een bijzondere plaats in. Dit alles maakt deel uit van een paradigmatische keten. Door vergelijking van de 'Tarzanvarian- ten' kan op den duur wellicht het onderliggende paradigma van dit genre worden blootgelegd. De volgende analyse wil hiermee ecn eerste begin maken. De oppositie natuur/cultuur wordt onderzocht aan de hand van het koppelingsproces tussen Jane en Tarzan. Via hen wordt deze oppositie het duidelijkst verbeeld en worden de verschuivingen en nuanceringen van dit primaire oppositiepaar zichtbaar gemaakt. Het Hollywoodsys- teem werkt deze omzetting met name uit in verschillende ontmoe- tingen (tussen Jane en Tarzan, maar ook in hun ontmoetingen met andere personages). In de handelingen die de personages uitvoeren, de kleding die zij dragen, de wijze waarop zij met attributen omgaan en Met dank aan Arie de Ruyter, Heidi de Mare, Bernadette Klasen en Lisette Hilhorst voor hun commentaar. -

Capitalism Rejected Is Education Perfected: the Imperfect Examples of Tarzan’S New York Adventure and Captain Fantastic
Class, Race and Corporate Power Volume 5 Issue 1 Article 3 2017 Capitalism Rejected is Education Perfected: The Imperfect Examples of Tarzan’s New York Adventure and Captain Fantastic Steven E. Alford Nova Southeastern University, [email protected] Follow this and additional works at: https://digitalcommons.fiu.edu/classracecorporatepower Part of the Film and Media Studies Commons, and the Philosophy Commons Recommended Citation Alford, Steven E. (2017) "Capitalism Rejected is Education Perfected: The Imperfect Examples of Tarzan’s New York Adventure and Captain Fantastic," Class, Race and Corporate Power: Vol. 5 : Iss. 1 , Article 3. DOI: 10.25148/CRCP.5.1.001670 Available at: https://digitalcommons.fiu.edu/classracecorporatepower/vol5/iss1/3 This work is brought to you for free and open access by the College of Arts, Sciences & Education at FIU Digital Commons. It has been accepted for inclusion in Class, Race and Corporate Power by an authorized administrator of FIU Digital Commons. For more information, please contact [email protected]. Capitalism Rejected is Education Perfected: The Imperfect Examples of Tarzan’s New York Adventure and Captain Fantastic Abstract One of the more beguiling films of 2016 was Matt Ross’ Captain Fantastic, a tale about a father raising a brood of children in the Pacific Northwest woods, and the challenges the family faces when it emerges into “civilization” to confront a family crisis. A much earlier film, 1942’s Tarzan’s New York Adventure, shares its narrative structure: Tarzan and Jane must leave their jungle paradise and confront a threat to their family in the canyons of New York. -
Annual Reports, Town of Acton, Massachusetts
' t««tiAAA«T«A -*—*"*- - ANNUAL REPORT OF THE Several Official Boards OF THE TOWN OF ACTON MASSACHUSETTS For the Year Ending December 31 1944 L ,«—«„»- -«- -»- -»- -»- -«- -•- -•- -«- -»- -«- -- -»- -«- -»--•- -«-»»-«--»- -»- •- « ANNUAL REPORT OF THE Several Official Boards OF THE TOWN OF ACTON MASSACHUSETTS For the Year Ending December 31 1944 WAHineu) TOWN WARRANT COMMONWEALTH OF MASSACHUSETTS Middlesex ss. To either of the Constables of the Town of Acton, in said County, Greetings: In the name of the Commonwealth of Massachusetts, you are hereby directed to notify the legal voters of said Town of Acton, qualified to vote at town meetings for the transaction of town affairs, to meet in their respective pre- cincts, to wit: Precinct 1—Town Hall, Acton Center Precinct 2—Universalist Church, South Acton Precinct 3—Woman's Club House, West Acton at 12 o'clock noon, Monday, the fifth day of March, 1945, by posting a copy of this warrant, by you attested, at each of the places as directed by vote of the town, seven days at least before the fifth day of March. To bring in their votes on one ballot for the following town officers: Moderator, town clerk, town treasurer, collector of taxes, one selectman for three years; one assessor for three years ; one member of the board of public welfare for three years; four constables for one year; one cemetery commis- sioner for three years; two members of the school commit- tee for three years ; one member of the board of health for three years; one trustee Memorial Library for three years; and a tree warden. ' The polls will be open at 12 o'clock noon, and close at 8 o'clock p. -

Elberta Student Doodles for Google
Serving the greater NORTH, CENTRAL AND SOUTH BALDWIN communities Hot air ballon media flight PAGE 11 Lynn signs with CACC The Onlooker PAGE 13 Bay Minette MAY 9, 2018 | GulfCoastNewsToday.com | 75¢ police NTSB releases preliminary report from March bus crash By JOHN UNDERWOOD roadway, traveled into the me- apprehend [email protected] dian and down an embankment. The crash occurred approxi- shooting LOXLEY — The National mately three miles east of Wilcox Transportation Safety Board near the 57 mile marker and suspect is continuing its investigation landed in a ravine on Cowpen into the cause of a March bus Creek in the Wilcox community. crash on Interstate 10 in Baldwin All 46 passengers sustained BMPD RELEASE County, issuing a preliminary minor to serious injuries in the report on its website May 1. crash, according to the report. BAY MI- According to a release is- Killed in the crash was the bus NETTE — A sued by the Alabama Law En- driver, 65-year-old Harry Calig- suspect has forcement Agency, at 5:33 a.m. one of Houston. been appre- Tuesday, March 13, a tour bus NTSB investigators arrived hended by carrying students from Channel- were on scene the day following NTSB.GOV Bay Minette view, Texas, was traveling west Police after on Interstate 10 when it left the SEE CRASH, PAGE 2 An Alabama Department of Transportation photo shows the bus at final rest. he reportedly Stokes stole a vehicle and shot at several buildings in the early morning hours Friday in Satsuma before 14th Annual Gulf Coast Hot Air Balloon Festival soars traveling to Baldwin County Elberta via Interstate 65 where he reportedly shot at two more student occupied vehicles.