Planet Candidate Validation in K2 Crowded Fields by Rayna Rampalli
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Mathématiques Et Espace
Atelier disciplinaire AD 5 Mathématiques et Espace Anne-Cécile DHERS, Education Nationale (mathématiques) Peggy THILLET, Education Nationale (mathématiques) Yann BARSAMIAN, Education Nationale (mathématiques) Olivier BONNETON, Sciences - U (mathématiques) Cahier d'activités Activité 1 : L'HORIZON TERRESTRE ET SPATIAL Activité 2 : DENOMBREMENT D'ETOILES DANS LE CIEL ET L'UNIVERS Activité 3 : D'HIPPARCOS A BENFORD Activité 4 : OBSERVATION STATISTIQUE DES CRATERES LUNAIRES Activité 5 : DIAMETRE DES CRATERES D'IMPACT Activité 6 : LOI DE TITIUS-BODE Activité 7 : MODELISER UNE CONSTELLATION EN 3D Crédits photo : NASA / CNES L'HORIZON TERRESTRE ET SPATIAL (3 ème / 2 nde ) __________________________________________________ OBJECTIF : Détermination de la ligne d'horizon à une altitude donnée. COMPETENCES : ● Utilisation du théorème de Pythagore ● Utilisation de Google Earth pour évaluer des distances à vol d'oiseau ● Recherche personnelle de données REALISATION : Il s'agit ici de mettre en application le théorème de Pythagore mais avec une vision terrestre dans un premier temps suite à un questionnement de l'élève puis dans un second temps de réutiliser la même démarche dans le cadre spatial de la visibilité d'un satellite. Fiche élève ____________________________________________________________________________ 1. Victor Hugo a écrit dans Les Châtiments : "Les horizons aux horizons succèdent […] : on avance toujours, on n’arrive jamais ". Face à la mer, vous voyez l'horizon à perte de vue. Mais "est-ce loin, l'horizon ?". D'après toi, jusqu'à quelle distance peux-tu voir si le temps est clair ? Réponse 1 : " Sans instrument, je peux voir jusqu'à .................. km " Réponse 2 : " Avec une paire de jumelles, je peux voir jusqu'à ............... km " 2. Nous allons maintenant calculer à l'aide du théorème de Pythagore la ligne d'horizon pour une hauteur H donnée. -

The AAVSO DSLR Observing Manual
The AAVSO DSLR Observing Manual AAVSO 49 Bay State Road Cambridge, MA 02138 email: [email protected] Version 1.2 Copyright 2014 AAVSO Foreword This manual is a basic introduction and guide to using a DSLR camera to make variable star observations. The target audience is first-time beginner to intermediate level DSLR observers, although many advanced observers may find the content contained herein useful. The AAVSO DSLR Observing Manual was inspired by the great interest in DSLR photometry witnessed during the AAVSO’s Citizen Sky program. Consumer-grade imaging devices are rapidly evolving, so we have elected to write this manual to be as general as possible and move the software and camera-specific topics to the AAVSO DSLR forums. If you find an area where this document could use improvement, please let us know. Please send any feedback or suggestions to [email protected]. Most of the content for these chapters was written during the third Citizen Sky workshop during March 22-24, 2013 at the AAVSO. The persons responsible for creation of most of the content in the chapters are: Chapter 1 (Introduction): Colin Littlefield, Paul Norris, Richard (Doc) Kinne, Matthew Templeton Chapter 2 (Equipment overview): Roger Pieri, Rebecca Jackson, Michael Brewster, Matthew Templeton Chapter 3 (Software overview): Mark Blackford, Heinz-Bernd Eggenstein, Martin Connors, Ian Doktor Chapters 4 & 5 (Image acquisition and processing): Robert Buchheim, Donald Collins, Tim Hager, Bob Manske, Matthew Templeton Chapter 6 (Transformation): Brian Kloppenborg, Arne Henden Chapter 7 (Observing program): Des Loughney, Mike Simonsen, Todd Brown Various figures: Paul Valleli Clear skies, and Good Observing! Arne Henden, Director Rebecca Turner, Operations Director Brian Kloppenborg, Editor Matthew Templeton, Science Director Elizabeth Waagen, Senior Technical Assistant American Association of Variable Star Observers Cambridge, Massachusetts June 2014 i Index 1. -

Diplomarbeit Fossile Galaxiensysteme
DIPLOMARBEIT Titel der Diplomarbeit Fossile Galaxiensysteme angestrebter akademischer Grad Magistra der Naturwissenschaften (Mag. rer. nat.) Verfasser: Eveline Glaßner Matrikel-Nummer: 9500110 Studienrichtung: Astronomie A413 Betreuer: Ao. Univ.-Prof. Dr. Werner Zeilinger Wien, Juni 2009 Zusammenfassung In meiner Arbeit wurden dynamische Endstadien von Galaxiensystemen, sog. Fos- sile Galaxiensysteme untersucht. Sie zeichnen sich durch eine massereiche zentrale Elliptische Galaxie aus, die von deutlich leuchtkraftschw¨acheren Galaxien umgeben ist. Diese Galaxien sind in einen diffusen, r¨aumlich ausgedehnten R¨ontgenhalo ein- gebettet, der auf ein ehemaliges Galaxiensystem schließen l¨asst. Insgesamt wurden 49 solcher Systeme untersucht, wobei nur 45 die Definition eines Fossilen Systems erfullen.¨ Die Auswahl setzt sich aus zwei Katalogen zusammen. Der erste Katalog stellt eine Zusammenfassung aller entdeckten Fossilen Systeme bis 2005 dar, der zweite stammt aus der Suche in der Sloan Digital Sky Survey im Jahre 2007. Als Erstes wurde die zentrale Elliptische Galaxie nach ihren photometrischen Eigen- schaften untersucht. Dies umfasst ein Fl¨achenhelligkeitsprofil, die Elliptizit¨at, den Positionswinkel und die Fourier-Koeffizienten h¨oherer Ordnung der Isophoten, die fur¨ die Bestimmung der Form (boxy bzw. disky) der Elliptischen Galaxie herange- zogen wurden. Es zeigt sich eine etwa gleichm¨aßige Aufteilung zwischen boxy und disky Elliptischen Galaxien. Der zweite Teil umfasst die spektrale Analyse der Elliptischen Galaxien. Weniger als die H¨alfte aller Elliptischen Galaxien zeigen nukleare Aktivit¨aten. Der dritte Schwerpunkt befasst sich mit der Analyse der Umgebung Fossiler Sys- teme. Bis zu einem Radius von 5 Mpc ausgehend von der zentralen Elliptischen Galaxie wurde nach weiteren Galaxien mit spektral bestimmten Rotverschiebungen gesucht. Dasselbe erfolgte auch fur¨ benachbarte Galaxiensysteme. -
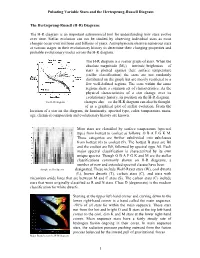
Plotting Variable Stars on the H-R Diagram Activity
Pulsating Variable Stars and the Hertzsprung-Russell Diagram The Hertzsprung-Russell (H-R) Diagram: The H-R diagram is an important astronomical tool for understanding how stars evolve over time. Stellar evolution can not be studied by observing individual stars as most changes occur over millions and billions of years. Astrophysicists observe numerous stars at various stages in their evolutionary history to determine their changing properties and probable evolutionary tracks across the H-R diagram. The H-R diagram is a scatter graph of stars. When the absolute magnitude (MV) – intrinsic brightness – of stars is plotted against their surface temperature (stellar classification) the stars are not randomly distributed on the graph but are mostly restricted to a few well-defined regions. The stars within the same regions share a common set of characteristics. As the physical characteristics of a star change over its evolutionary history, its position on the H-R diagram The H-R Diagram changes also – so the H-R diagram can also be thought of as a graphical plot of stellar evolution. From the location of a star on the diagram, its luminosity, spectral type, color, temperature, mass, age, chemical composition and evolutionary history are known. Most stars are classified by surface temperature (spectral type) from hottest to coolest as follows: O B A F G K M. These categories are further subdivided into subclasses from hottest (0) to coolest (9). The hottest B stars are B0 and the coolest are B9, followed by spectral type A0. Each major spectral classification is characterized by its own unique spectra. -

Catching up with Barnard's Star. Dave Eagle Within the Constellation Of
Catching Up with Barnard’s Star. Dave Eagle Within the constellation of Ophiuchus lies Barnard’s Star. It is a fairly faint red dwarf star of magnitude 9.53, six light years from Earth, so is fairly close to us. Its luminosity is 1/2,500th that of the Sun and 16% its mass. The diameter is estimated at about 140,000 miles, so it’s quite a small, faint star and well below naked eye visibility. So why is this star so well known? In 1916 Edward Barnard looked at a photographic plate of the area. When he compared this to a similar plate made in 1894, he noticed that one of the stars had moved between the time of the two plates being taken. Although all the stars in the sky in reality are all moving quite fast, from our remote vantage point on Earth most stars appear to appear virtually static during our lifetime as their apparent motion is extremely small. Barnard’s star, being so close and moving so fast, is one of the stars that bucks this trend. So fast indeed that it will subtend the apparent diameter equivalent to the Moon or Sun in about 176 years. So compared to other stars it is really shifting. The star is travelling at 103 miles per second and is approaching us at about 87 miles per second. In about 8,000 years it will become the closest star to us, at just under 4 light years and will have brightened to magnitude 8.6. Peter van de Camp caused great excitement in the 1960’s when he claimed to have discovered a planet (or more) around the star, due to wobbles superimposed on its movement. -

Light Curve Analysis of Variable Stars Using Fourier Decomposition and Principal Component Analysis
A&A 507, 1729–1737 (2009) Astronomy DOI: 10.1051/0004-6361/200912851 & c ESO 2009 Astrophysics Light curve analysis of variable stars using Fourier decomposition and principal component analysis S. Deb1 andH.P.Singh1,2 1 Department of Physics & Astrophysics, University of Delhi, Delhi 110007, India e-mail: [email protected],[email protected] 2 CRAL-Observatoire de Lyon, CNRS UMR 142, 69561 Saint-Genis Laval, France Received 8 July 2009 / Accepted 1 September 2009 ABSTRACT Context. Ongoing and future surveys of variable stars will require new techniques to analyse their light curves as well as to tag objects according to their variability class in an automated way. Aims. We show the use of principal component analysis (PCA) and Fourier decomposition (FD) method as tools for variable star light curve analysis and compare their relative performance in studying the changes in the light curve structures of pulsating Cepheids and in the classification of variable stars. Methods. We have calculated the Fourier parameters of 17 606 light curves of a variety of variables, e.g., RR Lyraes, Cepheids, Mira Variables and extrinsic variables for our analysis. We have also performed PCA on the same database of light curves. The inputs to the PCA are the 100 values of the magnitudes for each of these 17 606 light curves in the database interpolated between phase 0 to 1. Unlike some previous studies, Fourier coefficients are not used as input to the PCA. Results. We show that in general, the first few principal components (PCs) are enough to reconstruct the original light curves compared to the FD method where 2 to 3 times more parameters are required to satisfactorily reconstruct the light curves. -

100 Closest Stars Designation R.A
100 closest stars Designation R.A. Dec. Mag. Common Name 1 Gliese+Jahreis 551 14h30m –62°40’ 11.09 Proxima Centauri Gliese+Jahreis 559 14h40m –60°50’ 0.01, 1.34 Alpha Centauri A,B 2 Gliese+Jahreis 699 17h58m 4°42’ 9.53 Barnard’s Star 3 Gliese+Jahreis 406 10h56m 7°01’ 13.44 Wolf 359 4 Gliese+Jahreis 411 11h03m 35°58’ 7.47 Lalande 21185 5 Gliese+Jahreis 244 6h45m –16°49’ -1.43, 8.44 Sirius A,B 6 Gliese+Jahreis 65 1h39m –17°57’ 12.54, 12.99 BL Ceti, UV Ceti 7 Gliese+Jahreis 729 18h50m –23°50’ 10.43 Ross 154 8 Gliese+Jahreis 905 23h45m 44°11’ 12.29 Ross 248 9 Gliese+Jahreis 144 3h33m –9°28’ 3.73 Epsilon Eridani 10 Gliese+Jahreis 887 23h06m –35°51’ 7.34 Lacaille 9352 11 Gliese+Jahreis 447 11h48m 0°48’ 11.13 Ross 128 12 Gliese+Jahreis 866 22h39m –15°18’ 13.33, 13.27, 14.03 EZ Aquarii A,B,C 13 Gliese+Jahreis 280 7h39m 5°14’ 10.7 Procyon A,B 14 Gliese+Jahreis 820 21h07m 38°45’ 5.21, 6.03 61 Cygni A,B 15 Gliese+Jahreis 725 18h43m 59°38’ 8.90, 9.69 16 Gliese+Jahreis 15 0h18m 44°01’ 8.08, 11.06 GX Andromedae, GQ Andromedae 17 Gliese+Jahreis 845 22h03m –56°47’ 4.69 Epsilon Indi A,B,C 18 Gliese+Jahreis 1111 8h30m 26°47’ 14.78 DX Cancri 19 Gliese+Jahreis 71 1h44m –15°56’ 3.49 Tau Ceti 20 Gliese+Jahreis 1061 3h36m –44°31’ 13.09 21 Gliese+Jahreis 54.1 1h13m –17°00’ 12.02 YZ Ceti 22 Gliese+Jahreis 273 7h27m 5°14’ 9.86 Luyten’s Star 23 SO 0253+1652 2h53m 16°53’ 15.14 24 SCR 1845-6357 18h45m –63°58’ 17.40J 25 Gliese+Jahreis 191 5h12m –45°01’ 8.84 Kapteyn’s Star 26 Gliese+Jahreis 825 21h17m –38°52’ 6.67 AX Microscopii 27 Gliese+Jahreis 860 22h28m 57°42’ 9.79, -

Naming the Extrasolar Planets
Naming the extrasolar planets W. Lyra Max Planck Institute for Astronomy, K¨onigstuhl 17, 69177, Heidelberg, Germany [email protected] Abstract and OGLE-TR-182 b, which does not help educators convey the message that these planets are quite similar to Jupiter. Extrasolar planets are not named and are referred to only In stark contrast, the sentence“planet Apollo is a gas giant by their assigned scientific designation. The reason given like Jupiter” is heavily - yet invisibly - coated with Coper- by the IAU to not name the planets is that it is consid- nicanism. ered impractical as planets are expected to be common. I One reason given by the IAU for not considering naming advance some reasons as to why this logic is flawed, and sug- the extrasolar planets is that it is a task deemed impractical. gest names for the 403 extrasolar planet candidates known One source is quoted as having said “if planets are found to as of Oct 2009. The names follow a scheme of association occur very frequently in the Universe, a system of individual with the constellation that the host star pertains to, and names for planets might well rapidly be found equally im- therefore are mostly drawn from Roman-Greek mythology. practicable as it is for stars, as planet discoveries progress.” Other mythologies may also be used given that a suitable 1. This leads to a second argument. It is indeed impractical association is established. to name all stars. But some stars are named nonetheless. In fact, all other classes of astronomical bodies are named. -

August 13 2016 7:00Pm at the Herrett Center for Arts & Science College of Southern Idaho
Snake River Skies The Newsletter of the Magic Valley Astronomical Society www.mvastro.org Membership Meeting President’s Message Saturday, August 13th 2016 7:00pm at the Herrett Center for Arts & Science College of Southern Idaho. Public Star Party Follows at the Colleagues, Centennial Observatory Club Officers It's that time of year: The City of Rocks Star Party. Set for Friday, Aug. 5th, and Saturday, Aug. 6th, the event is the gem of the MVAS year. As we've done every Robert Mayer, President year, we will hold solar viewing at the Smoky Mountain Campground, followed by a [email protected] potluck there at the campground. Again, MVAS will provide the main course and 208-312-1203 beverages. Paul McClain, Vice President After the potluck, the party moves over to the corral by the bunkhouse over at [email protected] Castle Rocks, with deep sky viewing beginning sometime after 9 p.m. This is a chance to dig into some of the darkest skies in the west. Gary Leavitt, Secretary [email protected] Some members have already reserved campsites, but for those who are thinking of 208-731-7476 dropping by at the last minute, we have room for you at the bunkhouse, and would love to have to come by. Jim Tubbs, Treasurer / ALCOR [email protected] The following Saturday will be the regular MVAS meeting. Please check E-mail or 208-404-2999 Facebook for updates on our guest speaker that day. David Olsen, Newsletter Editor Until then, clear views, [email protected] Robert Mayer Rick Widmer, Webmaster [email protected] Magic Valley Astronomical Society is a member of the Astronomical League M-51 imaged by Rick Widmer & Ken Thomason Herrett Telescope Shotwell Camera https://herrett.csi.edu/astronomy/observatory/City_of_Rocks_Star_Party_2016.asp Calendars for August Sun Mon Tue Wed Thu Fri Sat 1 2 3 4 5 6 New Moon City Rocks City Rocks Lunation 1158 Castle Rocks Castle Rocks Star Party Star Party Almo, ID Almo, ID 7 8 9 10 11 12 13 MVAS General Mtg. -

Rare Astronomical Sights and Sounds
Jonathan Powell Rare Astronomical Sights and Sounds The Patrick Moore The Patrick Moore Practical Astronomy Series More information about this series at http://www.springer.com/series/3192 Rare Astronomical Sights and Sounds Jonathan Powell Jonathan Powell Ebbw Vale, United Kingdom ISSN 1431-9756 ISSN 2197-6562 (electronic) The Patrick Moore Practical Astronomy Series ISBN 978-3-319-97700-3 ISBN 978-3-319-97701-0 (eBook) https://doi.org/10.1007/978-3-319-97701-0 Library of Congress Control Number: 2018953700 © Springer Nature Switzerland AG 2018 This work is subject to copyright. All rights are reserved by the Publisher, whether the whole or part of the material is concerned, specifically the rights of translation, reprinting, reuse of illustrations, recitation, broadcasting, reproduction on microfilms or in any other physical way, and transmission or information storage and retrieval, electronic adaptation, computer software, or by similar or dissimilar methodology now known or hereafter developed. The use of general descriptive names, registered names, trademarks, service marks, etc. in this publication does not imply, even in the absence of a specific statement, that such names are exempt from the relevant protective laws and regulations and therefore free for general use. The publisher, the authors, and the editors are safe to assume that the advice and information in this book are believed to be true and accurate at the date of publication. Neither the publisher nor the authors or the editors give a warranty, express or implied, with respect to the material contained herein or for any errors or omissions that may have been made. -

The Heavens in August a Study of Short Period Variables
100 SCIENTIFIC,AMERlCAN July 31, 1915 The Heavens in August A Study of Short Period Variables By Prof. Henry Norris Russell, Ph.D. HE warm clear nights of summer offer the amateur which is marked on our map, .and the second lies about and but 18 minutes of arc apart, while Neptune is only T the best chance for star-gazing in all the year, and, two fifths of the way from this to () Ophiuchi (also a degree away on the other side. This simultaneous fortunately, he has one of the finest portions of the shown on the map) and is the only bright star near conjunction of three planets is rather remarkable, but, heavens at his command in the splendid region of the this line. The character of the variation is in both as they rise less than an hour earlier than the Sun, Milky Way, which stretches from Cassiopeia and cases very similar to that of the stars previously de Neptune will be utterly invisible, though the other two Cygnus through Aquila to Sagittarius and Scorpio, and scribed. w Sagittarii varies from magnitude 4.3 to 5.1 planets may easily be seen with a telescope (provided forms a vast circle right across the summit of the vault in a period of 7.595 days, the ris� in brightness taking with suitable finding circles ) even in broad daylight, of heaven. about half as long as the fall, and the maximum being and in the same low-power field. The veriest novice can learn in an hour to identify a little more than twice the minimum light. -

236. “Stelle E Costellazioni Del Cielo”
Progetto RaPHAEL (www.raphaelproject.com ) - Incontro nº 236 del 10/07/2005 - Colore Grigio verde 236. “Stelle e costellazioni del cielo” Una parte della natura umana è terrestre , ma un’altra parte è cosmica e stellare , volendo riscoprire la totalità della nostra vera natura è molto importante ritrovare la risonanza con le dimensioni trans-terrestri, facendo anche riemergere memorie di vite passate dove non avevamo un corpo umano e dove l’esistenza si svolgeva su altri continuum spazio-temporali. Abbiamo già visto come la Fantascienza sappia risvegliare questa risonanza (ved. incontro n° 212 ) e come ci permetta di concretizzare a livello mentale esperienze che qualcuno potrebbe aver difficoltà anche solo a concepire, adesso focalizziamo un attimo l’attenzione sull’incredibile fascino che ispirano le stelle ad ogni essere umano di animo sensibile... interiormente una parte di noi sa di originare dalle stelle ed è là che aspira a tornare! Una buona parte del nostro DNA origina da altri sistemi stellari, le leggende comparate delle varie tribù native americane raccontano che ben 12 razze galattiche hanno contribuito a creare il DNA dell’Homo sapiens. Ebbene noi suggeriamo di lasciarvi guidare dalla meditazione e dal ricordo immaginativo per recuperare i “circuiti” atemporali legati al piano cosmico , attraverso esercizi rilassati di rimpatrio energetico ed esperenziale (ed un respiro consapevole) molte esperienze possono riemergere… I nomi sotto riportati, con la posizione relativa rispetto alla costellazione di appartenenza (alfa= 1,