Circuit Switching in the Internet
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
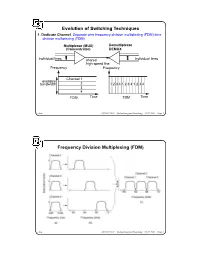
Evolution of Switching Techniques Frequency Division Multiplexing
Evolution of Switching Techniques 1. Dedicate Channel. Separate wire frequency division multiplexing (FDM) time division multiplexing (TDM) Multiplexor (MUX) Demultiplexor (Concentrator) DEMUX individual lines shared individual lines high speed line Frequency Frequency Channel 1 available bandwidth 2 1 2 3 4 1 2 3 4 1 2 3 4 3 4 FDM Time TDM Time chow CS522 F2001—Multiplexing and Switching—10/17/2001—Page 1 Frequency Division Multiplexing (FDM) chow CS522 F2001—Multiplexing and Switching—10/17/2001—Page 2 Wavelength Division Multiplexing chow CS522 F2001—Multiplexing and Switching—10/17/2001—Page 3 Impact of WDM z Many big organizations are starting projects to design WDM system or DWDN (Dense Wave Division Mutiplexing Network). We may see products appear in next three years.In Fujitsu and CCL/Taiwan, 128 different wavelengthes on the same strand of fiber was reported working in the lab. z We may have optical routers between end systems that can take one wavelenght signal, covert to different wavelenght, send it out on different links. Some are designing traditional routers that covert optical signal to electronical signal, and use time slot interchange based on high speed memory to do the switching, the convert the electronic signal back to optical signal. z With this type of optical networks, we will have a virtual circuit network, where each connection is assigned some wave length. Each connection can have 2.4 gbps tremedous bandwidth. z With inital 128 different wavelength, we can have about 10 end users. If each pair of end users needs to communicate simultaneously, it will use 10*10=100 different wavelength. -

Lecture 8: Overview of Computer Networking Roadmap
Lecture 8: Overview of Computer Networking Slides adapted from those of Computer Networking: A Top Down Approach, 5th edition. Jim Kurose, Keith Ross, Addison-Wesley, April 2009. Roadmap ! what’s the Internet? ! network edge: hosts, access net ! network core: packet/circuit switching, Internet structure ! performance: loss, delay, throughput ! media distribution: UDP, TCP/IP 1 What’s the Internet: “nuts and bolts” view PC ! millions of connected Mobile network computing devices: server Global ISP hosts = end systems wireless laptop " running network apps cellular handheld Home network ! communication links Regional ISP " fiber, copper, radio, satellite access " points transmission rate = bandwidth Institutional network wired links ! routers: forward packets (chunks of router data) What’s the Internet: “nuts and bolts” view ! protocols control sending, receiving Mobile network of msgs Global ISP " e.g., TCP, IP, HTTP, Skype, Ethernet ! Internet: “network of networks” Home network " loosely hierarchical Regional ISP " public Internet versus private intranet Institutional network ! Internet standards " RFC: Request for comments " IETF: Internet Engineering Task Force 2 A closer look at network structure: ! network edge: applications and hosts ! access networks, physical media: wired, wireless communication links ! network core: " interconnected routers " network of networks The network edge: ! end systems (hosts): " run application programs " e.g. Web, email " at “edge of network” peer-peer ! client/server model " client host requests, receives -
Circuit-Switched Coherence
Circuit-Switched Coherence ‡Natalie Enright Jerger, ‡Mikko Lipasti, and ?Li-Shiuan Peh ‡Electrical and Computer Engineering Department, University of Wisconsin-Madison ?Department of Electrical Engineering, Princeton University Abstract—Circuit-switched networks can significantly lower contention, overall system performance can degrade by 20% the communication latency between processor cores, when or more. This latency sensitivity coupled with low link uti- compared to packet-switched networks, since once circuits are set up, communication latency approaches pure intercon- lization motivates our exploration of circuit-switched fabrics nect delay. However, if circuits are not frequently reused, the for CMPs. long set up time and poorer interconnect utilization can hurt Our investigations show that traditional circuit-switched overall performance. To combat this problem, we propose a hybrid router design which intermingles packet-switched networks do not perform well, as circuits are not reused suf- flits with circuit-switched flits. Additionally, we co-design a ficiently to amortize circuit setup delay. This observation prediction-based coherence protocol that leverages the exis- motivates a network with a hybrid router design that sup- tence of circuits to optimize pair-wise sharing between cores. The protocol allows pair-wise sharers to communicate di- ports both circuit and packet switching with very fast circuit rectly with each other via circuits and drives up circuit reuse. reconfiguration (setup/teardown). Our preliminary results Circuit-switched coherence provides overall system perfor- show this leading to up to 8% improvement in overall system mance improvements of up to 17% with an average improve- performance over a packet-switched fabric. ment of 10% and reduces network latency by up to 30%. -

Medium Access Control Layer
Telematics Chapter 5: Medium Access Control Sublayer User Server watching with video Beispielbildvideo clip clips Application Layer Application Layer Presentation Layer Presentation Layer Session Layer Session Layer Transport Layer Transport Layer Network Layer Network Layer Network Layer Univ.-Prof. Dr.-Ing. Jochen H. Schiller Data Link Layer Data Link Layer Data Link Layer Computer Systems and Telematics (CST) Physical Layer Physical Layer Physical Layer Institute of Computer Science Freie Universität Berlin http://cst.mi.fu-berlin.de Contents ● Design Issues ● Metropolitan Area Networks ● Network Topologies (MAN) ● The Channel Allocation Problem ● Wide Area Networks (WAN) ● Multiple Access Protocols ● Frame Relay (historical) ● Ethernet ● ATM ● IEEE 802.2 – Logical Link Control ● SDH ● Token Bus (historical) ● Network Infrastructure ● Token Ring (historical) ● Virtual LANs ● Fiber Distributed Data Interface ● Structured Cabling Univ.-Prof. Dr.-Ing. Jochen H. Schiller ▪ cst.mi.fu-berlin.de ▪ Telematics ▪ Chapter 5: Medium Access Control Sublayer 5.2 Design Issues Univ.-Prof. Dr.-Ing. Jochen H. Schiller ▪ cst.mi.fu-berlin.de ▪ Telematics ▪ Chapter 5: Medium Access Control Sublayer 5.3 Design Issues ● Two kinds of connections in networks ● Point-to-point connections OSI Reference Model ● Broadcast (Multi-access channel, Application Layer Random access channel) Presentation Layer ● In a network with broadcast Session Layer connections ● Who gets the channel? Transport Layer Network Layer ● Protocols used to determine who gets next access to the channel Data Link Layer ● Medium Access Control (MAC) sublayer Physical Layer Univ.-Prof. Dr.-Ing. Jochen H. Schiller ▪ cst.mi.fu-berlin.de ▪ Telematics ▪ Chapter 5: Medium Access Control Sublayer 5.4 Network Types for the Local Range ● LLC layer: uniform interface and same frame format to upper layers ● MAC layer: defines medium access .. -

F. Circuit Switching
CSE 3461: Introduction to Computer Networking and Internet Technologies Circuit Switching Presentation F Study: 10.1, 10.2, 8 .1, 8.2 (without SONET/SDH), 8.4 10-02-2012 A Closer Look At Network Structure: • network edge: applications and hosts • network core: —routers —network of networks • access networks, physical media: communication links d. xuan 2 1 The Network Core • mesh of interconnected routers • the fundamental question: how is data transferred through net? —circuit switching: dedicated circuit per call: telephone net —packet-switching: data sent thru net in discrete “chunks” d. xuan 3 Network Layer Functions • transport packet from sending to receiving hosts application transport • network layer protocols in network data link network physical every host, router network data link network data link physical data link three important functions: physical physical network data link • path determination: route physical network data link taken by packets from source physical to dest. Routing algorithms network network data link • switching: move packets from data link physical physical router’s input to appropriate network data link application router output physical transport network data link • call setup: some network physical architectures require router call setup along path before data flows d. xuan 4 2 Network Core: Circuit Switching End-end resources reserved for “call” • link bandwidth, switch capacity • dedicated resources: no sharing • circuit-like (guaranteed) performance • call setup required d. xuan 5 Circuit Switching • Dedicated communication path between two stations • Three phases — Establish (set up connection) — Data Transfer — Disconnect • Must have switching capacity and channel capacity to establish connection • Must have intelligence to work out routing • Inefficient — Channel capacity dedicated for duration of connection — If no data, capacity wasted • Set up (connection) takes time • Once connected, transfer is transparent • Developed for voice traffic (phone) g. -

Before the FEDERAL COMMUNICATIONS COMMISSION Washington, D.C
Before the FEDERAL COMMUNICATIONS COMMISSION Washington, D.C. 20554 In the Maller of ) ) Global Crossing Limited and Level 3 ) Communications, Inc., Application for ) Consent to Transfer Control ofAuthority to ) Provide Global facilities-Based and Global ) IB Docket No. I 1-78 Resale International Telecommunications ) Services and ofDomestic Common Carrier ) Transmission Lines, Pursuant to Section 214 ) of the Communications Act, as Amended ) ) Level 3 Communications, Inc., Petition for ) Declaratory Ruling Under Section 31 0(b)(4) ) Ofthe Communications Act of 1934, as ) AJnended ) DECLARATION OF MARCELLUS NIXON I. My name is Marcellus I ixon. I am the Director ofIP Network Planning at XO Communications, LLC. (XO). My business address is 13865 Sunrise Valley Drive, Hcrndon, VA 20171. 2. I have bcen employed at XO since 2002, initially as an IP Network Engineer. I have been in my current position as Dircctor ofIP Network Planning since 2008. My career with IP nctworks began in the US Army. I have also held networking positions with the NASD and internet MCT. I hold a Bachelor ofInterdisciplinary Studies from the University of Virginia. 3. In my current position, I am responsible for all strategic aspects of IP network planning, and I am the peering coordinator for XO. In that capacity, I manage relationships with other Tier I and lower tier Internet Backbone Providers (lI3Ps), including detennining wbere peering occurs, evaluating network arcbitecture needs such as capacity requirements, routing requirements, and the impact of technological changes on the peering arrangement. I also am responsible for negotiating interconnection (peering) agreements. To date, I have negotiated on behalf ofXO forty-seven (47) peering agreements. -

Networking and the Internet
Networking and Today’s lecture the Internet History of the Internet How the Internet works Lecture 4 – COMPSCI111/111G S2 2018 Network protocols The telephone WWII and the Cold War 1876: first successful bi-directional Computer technology played an important role transmission of clear speech in code-breaking during WW2 by Alexander Bell and Thomas Watson Cold War between US and USSR led to a technology and arms race Peaked with the launch of Sputnik in 1957 1958: Advanced Research Projects Agency (ARPA) 1940: first successful transmission established of digital data through over telegraph wires by George Stibitz April 1969: construction of ARPANET begins, a packet-switching network Circuit-switching network Packet-switching network Nodes are connected physically via a central Data is broken into packets, which are then sent node on the best route in the network Used by the telephone network Each node on the route sends the packet onto its next destination, avoiding congested or broken Originally, switchboard operators had to nodes manually connect phone calls, today this is done electronically B A ARPANET ARPANET in 1977 October 1969: ARPANET is completed with four nodes 1973: Norway connects to ARPANET via satellite, followed by London via a terrestrial link ARPANET ARPANET to the Internet 1983: TCP/IP implemented in ARPANET Networks similar to ARPANET sprang up around the USA and in other countries 1990: ARPANET is formally decommissioned 1984: domain name system (DNS) implemented 1985: NSFNET was established 1989: Waikato University connects to NSFNET 1991: World Wide Web (WWW) created at CERN (European Organization for Nuclear Research) by Tim Berners-Lee 1995: NSFNET is retired WWW vs Internet Internet growth The Internet is a global system of interconnected computer networks. -

Application Note: 2-Cell Test Environment
Application Note 2-cell Test Environment MD8475A Signalling Tester 1. Background to LTE Rollout Mobile phones appearing in the late 1980s soon experienced rapid evolution of functions from 1990 to 2000 and also spread worldwide as key communications infrastructure. The mobile phone is not limited to just two-way communications between two people but also supports sending and receiving of Short Message Services (SMS), web browsing using the Internet, application and video download, etc., and has become a popular and key cultural tool supporting a fuller lifestyle for many people. Figure 1. Evolution on UE According to one research company, total mobile phone (terminal) shipments at the end of 2010 were valued at $38 billion split between 45% for 2G phones and 49% for 3G. Table 1. Mobile Terminal Shipments Mobile Terminal Shipments ($38 billion total) LTE 1.3% WiMAX 4.0% W-CDMA 40.0% CDMA 9.3% GSM 45.4% 1 MD8475A-E-F-1 The purpose of the shift from 2G to 3G systems was to make more efficient use of frequency bandwidths and was closely related to the explosive growth of the Internet. While still maintaining the easy portability of a mobile phone, users were able to access the information they needed easily at any time and place using the Internet. Similarly to growth of 3G technology, the requirements of LTE systems, which is are positioned in the market as 3.9G to maintain competitiveness with coming 4G systems, are being examined. Connectivity with IP-based core networks must be maintained to support multimedia applications and ubiquitous networks using the packet domain. -

The Internet ! Based on Slides Originally Published by Thomas J
15-292 History of Computing The Internet ! Based on slides originally published by Thomas J. Cortina in 2004 for a course at Stony Brook University. Revised in 2013 by Thomas J. Cortina for a computing history course at Carnegie Mellon University. A Vision of Connecting the World – the Memex l Proposed by Vannevar Bush l first published in the essay "As We May Think" in Atlantic Monthly in 1945 and subsequently in Life Magazine. l "a device in which an individual stores all his books, records, and communications, and which is mechanized so that it may be consulted with exceeding speed and flexibility" l also indicated the idea that would become hypertext l Bush’s work was influential on all Internet pioneers The Memex The Impetus to Act l 1957 - U.S.S.R. launches Sputnik I into space l 1958 - U.S. Department of Defense responds by creating ARPA l Advanced Research Projects Agency l “mission is to maintain the technological superiority of the U.S. military” l “sponsoring revolutionary, high-payoff research that bridges the gap between fundamental discoveries and their military use.” l Name changed to DARPA (Defense) in 1972 ARPANET l The Advanced Research Projects Agency Network (ARPANET) was the world's first operational packet switching network. l Project launched in 1968. l Required development of IMPs (Interface Message Processors) by Bolt, Beranek and Newman (BBN) l IMPs would connect to each other over leased digital lines l IMPs would act as the interface to each individual host machine l Used packet switching concepts published by Leonard Kleinrock, most famous for his subsequent books on queuing theory Early work Baran (L) and Davies (R) l Paul Baran began working at the RAND corporation on secure communications technologies in 1959 l goal to enable a military communications network to withstand a nuclear attack. -

Research on Super 3G Technology
03-10E_T-Box_3.3 06.12.26 10:07 AM ページ 55 NTT DoCoMo Technical Journal Vol. 8 No.3 Part 2: Research on Super 3G Technology In this part 2 of the Super 3G research that is being conducted to achieve a smooth transition from 3G to 4G, we present technology that is currently being studied for standardization as technical details. Sadayuki Abeta, Minami Ishii, Yasuhiro Kato and Kenichi Higuchi At the RAN WG1 meeting of November 2005, there was 1. Introduction agreement by many companies that high commonality is As explained in part1, Super 3G, the so-called Evolved extremely important and wireless access should be the same for URAN and UTRAN or Long term evolution by the 3rd FDD (paired spectrum) and TDD (unpaired spectrum). As this Generation Partnership Project (3GPP) has been extensively common wireless access system for FDD and TDD, Orthogonal studied since 2005. Agreement on the requirement was reached Frequency Division Multiple Access (OFDMA), which features in June of 2005 to begin investigation of specific technologies. highly efficient frequency utilization was approved for the In June 2006, it was agreed that investigation of the feasibility downlink and Single-Carrier Frequency Division Multiple of the basic approach for satisfying the requirements was essen- Access (SC-FDMA) was approved for the uplink at the tially completed, and effort shifted to the work item phase to December 2005 Plenary Meeting. start the detailed specifications work. Here, we explain technol- The features of the wireless access system are described in ogy that has been proposed as study items. -

Review of the Development and Reform of the Telecommunications Sector in China”, OECD Digital Economy Papers, No
Please cite this paper as: OECD (2003-03-13), “Review of the Development and Reform of the Telecommunications Sector in China”, OECD Digital Economy Papers, No. 69, OECD Publishing, Paris. http://dx.doi.org/10.1787/233204728762 OECD Digital Economy Papers No. 69 Review of the Development and Reform of the Telecommunications Sector in China OECD Unclassified DSTI/ICCP(2002)6/FINAL Organisation de Coopération et de Développement Economiques Organisation for Economic Co-operation and Development 13-Mar-2003 ___________________________________________________________________________________________ English text only DIRECTORATE FOR SCIENCE, TECHNOLOGY AND INDUSTRY COMMITTEE FOR INFORMATION, COMPUTER AND COMMUNICATIONS POLICY Unclassified DSTI/ICCP(2002)6/FINAL REVIEW OF THE DEVELOPMENT AND REFORM OF THE TELECOMMUNICATIONS SECTOR IN CHINA text only English JT00140818 Document complet disponible sur OLIS dans son format d'origine Complete document available on OLIS in its original format DSTI/ICCP(2002)6/FINAL FOREWORD The purpose of this report is to provide an overview of telecommunications development in China and to examine telecommunication policy developments and reform. The initial draft was examined by the Committee for Information, Computer and Communications Policy in March 2002. The report benefited from discussions with officials of the Chinese Ministry of Information Industry and several telecommunication service providers. The report was prepared by the Korea Information Society Development Institute (KISDI) under the direction of Dr. Inuk Chung. Mr. Dimitri Ypsilanti from the OECD Secretariat participated in the project. The report benefited from funding provided mainly by the Swedish government. KISDI also helped in the financing of the report. The report is published on the responsibility of the Secretary-General of the OECD. -

UMTS Core Network
UMTS Core Network V. Mancuso, I. Tinnirello GSM/GPRS Network Architecture Radio access network GSM/GPRS core network BSS PSTN, ISDN PSTN, MSC GMSC BTS VLR MS BSC HLR PCU AuC SGSN EIR BTS IP Backbone GGSN database Internet V. Mancuso, I. Tinnirello 3GPP Rel.’99 Network Architecture Radio access network Core network (GSM/GPRS-based) UTRAN PSTN Iub RNC MSC GMSC Iu CS BS VLR UE HLR Uu Iur AuC Iub RNC SGSN Iu PS EIR BS Gn IP Backbone GGSN database Internet V. Mancuso, I. Tinnirello 3GPP RelRel.’99.’99 Network Architecture Radio access network 2G => 3G MS => UE UTRAN (User Equipment), often also called (user) terminal Iub RNC New air (radio) interface BS based on WCDMA access UE technology Uu Iur New RAN architecture Iub RNC (Iur interface is available for BS soft handover, BSC => RNC) V. Mancuso, I. Tinnirello 3GPP Rel.’99 Network Architecture Changes in the core Core network (GSM/GPRS-based) network: PSTN MSC is upgraded to 3G MSC GMSC Iu CS MSC VLR SGSN is upgraded to 3G HLR SGSN AuC SGSN GMSC and GGSN remain Iu PS EIR the same Gn GGSN AuC is upgraded (more IP Backbone security features in 3G) Internet V. Mancuso, I. Tinnirello 3GPP Rel.4 Network Architecture UTRAN Circuit Switched (CS) core network (UMTS Terrestrial Radio Access Network) MSC GMSC Server Server SGW SGW PSTN MGW MGW New option in Rel.4: GERAN (GSM and EDGE Radio Access Network) PS core as in Rel.’99 V. Mancuso, I. Tinnirello 3GPP Rel.4 Network Architecture MSC Server takes care Circuit Switched (CS) core of call control signalling network The user connections MSC GMSC are set up via MGW Server Server (Media GateWay) SGW SGW PSTN “Lower layer” protocol conversion in SGW MGW MGW (Signalling GateWay) RANAP / ISUP PS core as in Rel.’99 SS7 MTP IP Sigtran V.