Word-Final Consonant and Cluster Acquisition in Indian English(Es)*
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Phonetics of Contrastive Phonation in Gujarati$
Journal of Phonetics ] (]]]]) ]]]–]]] Contents lists available at SciVerse ScienceDirect Journal of Phonetics journal homepage: www.elsevier.com/locate/phonetics The phonetics of contrastive phonation in Gujarati$ Sameer ud Dowla Khan n Department of Linguistics, Reed College, 3203 SE Woodstock Boulevard, Portland, OR 97202-8199, USA article info abstract Article history: The current study examines (near-)minimal pairs of breathy and modal phonation produced by ten Received 20 December 2011 native speakers of Gujarati in connected speech, across different vowel qualities and separated by nine Received in revised form equal timepoints of vowel duration. The results identify five spectral measures (i.e. H1–H2, H2–H4, 3 July 2012 H1–A1, H1–A2, H1–A3), four noise measures (i.e. cepstral peak prominence and three measures of Accepted 9 July 2012 harmonics-to-noise ratio), and one electroglottographic measure (i.e. CQ) as reliable indicators of breathy phonation, revealing a considerably larger inventory of cues to breathy phonation than what had previously been reported for the language. Furthermore, while the spectral measures are consistently distinct for breathy and modal vowels when averaging across timepoints, the efficacy of the four noise measures in distinguishing phonation categories is localized to the midpoint of the vowel’s duration. This indicates that the magnitude of breathiness, especially in terms of aperiodicity, changes as a function of time. The current study supports that breathy voice in Gujarati is a dynamic, multidimensional -

Origin and Development of the Meitei Language
International Journal of Multidisciplinary Research and Modern Education (IJMRME) ISSN (Online): 2454 - 6119 (www.rdmodernresearch.org) Volume II, Issue I, 2016 ORIGIN AND DEVELOPMENT OF THE MEITEI LANGUAGE Khongbantabam Naobi Devi Ph.D Scholar, Department of English, Ethiraj College for Women, Chennai, Tamilnadu Abstract: Meitei language is an Indo-Aryan language. The Indo- Aryans came to Manipur and settled in the Manipur from the 4th century B.C. onwards. The noted historian and scholar R.K. Jhalajit Singh present his views on the topic to Dr. Suniti Kumar Chatterjee, the great scholar and experts on language. He expressed as Meitei language may not belong to the Kuki- Chin sub-group of the Tibeto-Burman branch; but belongs to the Sino-Tibetan family of language. All the language that belongs to the Tibeto-Burman, a sub-branch of the Sino- Tibetan family of languages, is mono- syllabic. The Meiteis language is not a monosyllabic language; it is a polysyllabic language. In meiteis language, majority of words have more than one syllable. A language should be classified because of grammar. This is the universal principle accepted on all. A language cannot be classified according to vocabulary. If we begin to classify a language according to its vocabulary, the results will be incorrect. The first settlers of the Indo-Aryans in Manipur spoke Sanskrit. Later settlers spoke Prakrit. When Prakrit was removed as spoken language, they spoke Apabhransha.. The combination of Apabhransha and Mongoloid languages gave birth to the Manipuri language by about 1074 A.D. In the olden days of the Meitei language, which was formed by the interaction of Apabhransha and Mongoloid languages, the most important words were taken from Sanskrit. -

Languages and Peoples of the Eastern Himalayan Region (LPEHR)
Languages and Peoples of the Eastern Himalayan Region (LPEHR) Deictic motion in Hakhun Tangsa Krishna Boro Gauhati University ABSTRACT This paper provides a detailed description of how deictic motion events are encoded in a Tangsa variety called Hakhun, spoken in Arunachal Pradesh and Assam in India, and in Sagaing Region in Myanmar. Deictic motion events in Hakhun are encoded by a set of two motion verbs, their serial or versatile verb counterparts, and a set of two ventive particles. Impersonal deictic motion events are encoded by the motion verbs alone, which orient the motion with reference to a center of interest. Motion events with an SAP figure or ground are simultaneously encoded by the motion verbs and ventive particles. These motion events evoke two frames of reference: a home base and the speech-act location. The motion verbs anchor the motion with reference to the home base of the figure, and the ventives (or their absence) anchor the motion with reference to the location of the speaker, the addressee, or the speech-act. When the motion verbs are concatenated with other verbs, they specify motion associated with the action denoted by the other verb(s). KEYWORDS Hakhun, Tibeto-Burman, deictic motion, motion verbs, ventive This is a contribution from Himalayan Linguistics Vol 19(2) Languages and Peoples of the Eastern Himalayan Region: 9 29. ISSN 1544-7502 © 2020. All rights reserved. This Portable Document Format (PDF) file may not be altered in any way. Tables of contents, abstracts, and submission guidelines are available at escholarship.org/uc/himalayanlinguistics Himalayan Linguistics Vol 19(2) Languages and Peoples of the Eastern Himalayan Region © CC by-nc-nd-4.0 2020 ISSN 1544-7502 Deictic motion in Hakhun Tangsa1 Krishna Boro Gauhati University 1 Introduction This paper describes how deictic motion events are encoded and contextually anchored in the speech situation in Hakhun, a variety of Tangsa or Tangshang (Ethnologue ISO 639-3 nst) spoken in the states of Arunachal Pradesh and Assam, India, and in Sagaing Region, Myanmar. -

The State and Identities in NE India
1 Working Paper no.79 EXPLAINING MANIPUR’S BREAKDOWN AND MANIPUR’S PEACE: THE STATE AND IDENTITIES IN NORTH EAST INDIA M. Sajjad Hassan Development Studies Institute, LSE February 2006 Copyright © M.Sajjad Hassan, 2006 Although every effort is made to ensure the accuracy and reliability of material published in this Working Paper, the Development Research Centre and LSE accept no responsibility for the veracity of claims or accuracy of information provided by contributors. All rights reserved. No part of this publication may be reproduced, stored in a retrieval system or transmitted in any form or by any means without the prior permission in writing of the publisher nor be issued to the public or circulated in any form other than that in which it is published. Requests for permission to reproduce this Working Paper, of any part thereof, should be sent to: The Editor, Crisis States Programme, Development Research Centre, DESTIN, LSE, Houghton Street, London WC2A 2AE. 1 Crisis States Programme Explaining Manipur’s Breakdown and Mizoram’s Peace: the State and Identities in North East India M.Sajjad Hassan Development Studies Institute, LSE Abstract Material from North East India provides clues to explain both state breakdown as well as its avoidance. They point to the particular historical trajectory of interaction of state-making leaders and other social forces, and the divergent authority structure that took shape, as underpinning this difference. In Manipur, where social forces retained their authority, the state’s autonomy was compromised. This affected its capacity, including that to resolve group conflicts. Here powerful social forces politicized their narrow identities to capture state power, leading to competitive mobilisation and conflicts. -

UNIVERSITY of CALIFORNIA Los Angeles Prefix
UNIVERSITY OF CALIFORNIA Los Angeles Prefix independence: typology and theory A thesis submitted in partial satisfaction of the requirements for the degree Master of Arts in Linguistics by Noah Eli Elkins 2020 © Copyright by Noah Eli Elkins 2020 ABSTRACT OF THE THESIS Prefix independence: typology and theory by Noah Eli Elkins Master of Arts in Linguistics University of California, Los Angeles, 2020 Professor Bruce Hayes, Co-Chair Professor Kie Zuraw, Co-Chair The prefix-suffix asymmetry is an imbalance in the application of phonological processes whereby prefixes are less phonologically cohering to their roots than suffixes. This thesis presents a large- scale typological survey of processes which are sensitive to this asymmetry. Results suggest that prefixes’ relative phonological aloofness (independence) constitutes a widespread and robust generalization, perhaps more so than previously realized. In terms of analysis, I argue that the key concept is the special prominence of initial syllables, supported by much evidence from phonetics, psycholinguistics, and phonology itself. My formal treatment consists of constraint families that serve to support such prominence. I propose that a highly-ranked CRISPEDGE constraint (Itô & Mester 1999) relativized to the left edge of root-initial syllables can account for much of the typological data. This proposal rests on the fact that root-initial syllables constitute a privileged position in phonological grammars (e.g. ii Beckman 1998, Becker et al. 2012), and so to maximize the efficacy of the root-initial percept, segments are hesitant to share their features leftward to target prefixes – and vice versa – as this would blur the strong root-initial boundary. -

Of Arts by Research
University of Huddersfield Repository Fadia, Safiyyah The influence of Gujarati on the VOT of English stops Original Citation Fadia, Safiyyah (2018) The influence of Gujarati on the VOT of English stops. Masters thesis, University of Huddersfield. This version is available at http://eprints.hud.ac.uk/id/eprint/34521/ The University Repository is a digital collection of the research output of the University, available on Open Access. Copyright and Moral Rights for the items on this site are retained by the individual author and/or other copyright owners. Users may access full items free of charge; copies of full text items generally can be reproduced, displayed or performed and given to third parties in any format or medium for personal research or study, educational or not-for-profit purposes without prior permission or charge, provided: • The authors, title and full bibliographic details is credited in any copy; • A hyperlink and/or URL is included for the original metadata page; and • The content is not changed in any way. For more information, including our policy and submission procedure, please contact the Repository Team at: [email protected]. http://eprints.hud.ac.uk/ Safiyyah Fadia THE INFLUENCE OF GUJARATI ON THE VOT OF ENGLISH STOPS Safiyyah Fadia Thesis submitted to the University of Huddersfield for the degree of Master of Arts by Research October 2017 1 Safiyyah Fadia ABSTRACT This thesis is an acoustic study of three generations of women from the Gujarati-English community in Batley, West Yorkshire (United Kingdom). The literature pertaining to Gujarati is very limited, hence this thesis aims to solve some unanswered queries regarding our understanding of the influence of Gujarati on English stop productions. -
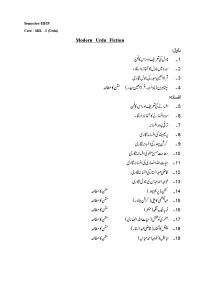
TDC Syllabus Under CBCS for Persian, Urdu, Bodo, Mizo, Nepali and Hmar
Proposed Scheme for Choice Based Credit System (CBCS) in B.A. (Honours) Persian 1 B.A. (Hons.): Persian is not merely a language but the life line of inter-disciplinary studies in the present global scenario as it is a fast growing subject being studied and offered as a major subject in the higher ranking educational institutions at world level. In view of it the proposed course is developed with the aims to equip the students with the linguistic, language and literary skills for meeting the growing demand of this discipline and promoting skill based education. The proposed course will facilitate self-discovery in the students and ensure their enthusiastic and effective participation in responding to the needs and challenges of society. The course is prepared with the objectives to enable students in developing skills and competencies needed for meeting the challenges being faced by our present society and requisite essential demand of harmony amongst human society as well and for his/her self-growth effectively. Therefore, this syllabus which can be opted by other Persian Departments of all Universities where teaching of Persian is being imparted is compatible and prepared keeping in mind the changing nature of the society, demand of the language skills to be carried with in the form of competencies by the students to understand and respond to the same efficiently and effectively. Teaching Method: The proposed course is aimed to inculcate and equip the students with three major components of Persian Language and Literature and Persianate culture which include the Indo-Persianate culture, the vital portion of our secular heritage. -

Genealogical Classification of New Indo-Aryan Languages and Lexicostatistics
Anton I. Kogan Institute of Oriental Studies of the Russian Academy of Sciences (Russia, Moscow); [email protected] Genealogical classification of New Indo-Aryan languages and lexicostatistics Genetic relations among Indo-Aryan languages are still unclear. Existing classifications are often intuitive and do not rest upon rigorous criteria. In the present article an attempt is made to create a classification of New Indo-Aryan languages, based on up-to-date lexicosta- tistical data. The comparative analysis of the resulting genealogical tree and traditional clas- sifications allows the author to draw conclusions about the most probable genealogy of the Indo-Aryan languages. Keywords: Indo-Aryan languages, language classification, lexicostatistics, glottochronology. The Indo-Aryan group is one of the few groups of Indo-European languages, if not the only one, for which no classification based on rigorous genetic criteria has been suggested thus far. The cause of such a situation is neither lack of data, nor even the low level of its historical in- terpretation, but rather the existence of certain prejudices which are widespread among In- dologists. One of them is the belief that real genetic relations between the Indo-Aryan lan- guages cannot be clarified because these languages form a dialect continuum. Such an argu- ment can hardly seem convincing to a comparative linguist, since dialect continuum is by no means a unique phenomenon: it is characteristic of many regions, including those where Indo- European languages are spoken, e.g. the Slavic and Romance-speaking areas. Since genealogi- cal classifications of Slavic and Romance languages do exist, there is no reason to believe that the taxonomy of Indo-Aryan languages cannot be established. -

L a B P H O N 9, University of Illinois, 2004
L a b P h o n 9, University of Illinois, 2004 Ninth Conference on Laboratory Phonology Change in Phonology Thursday 24 June - Saturday 26 June, 2004 LabPhon 9 hosts Please follow this link to the visit the 10th Conference on Laboratory Phonology page: Variation, Detail and Representation Location Important Dates Welcome to the 9th Conference on Laboratory Phonology Program Committee LabPhon is an international forum for interdisciplinary research on the sound structure of languages. Conference Grants Participants in LabPhon seek to communicate across the traditional boundaries that separate phonology, as a branch of theoretical linguistics, from the study of speech production, speech perception, spoken Downloads language acquisition, computer speech processing, and other disciplines concerned with human speech. Schedule [pdf] The theme for LabPhon 9, Change in Phonology, addresses questions related to the evolution of Shuttle Service language within a speech community and the development of language within the individual Style Guidelines speaker/hearer, and includes issues of broad social interest, such as child language development, [pdf] language pedagogy, and technologies for human-computer interaction. Themes and Invited Participants Acquisition as change: L1 phonology LouAnn Gerken, University of Arizona , invited speaker Stefan Frisch, University of South Florida, discussant Phonological models of variation in computer speech processing Julia Hirschberg, Columbia University, invited speaker Carol Espy-Wilson, University of Maryland, -

Tone Systems of Dimasa and Rabha: a Phonetic and Phonological Study
TONE SYSTEMS OF DIMASA AND RABHA: A PHONETIC AND PHONOLOGICAL STUDY By PRIYANKOO SARMAH A DISSERTATION PRESENTED TO THE GRADUATE SCHOOL OF THE UNIVERSITY OF FLORIDA IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF DOCTOR OF PHILOSOPHY UNIVERSITY OF FLORIDA 2009 1 © 2009 Priyankoo Sarmah 2 To my parents and friends 3 ACKNOWLEDGMENTS The hardships and challenges encountered while writing this dissertation and while being in the PhD program are no way unlike anything experienced by other Ph.D. earners. However, what matters at the end of the day is the set of people who made things easier for me in the four years of my life as a Ph.D. student. My sincere gratitude goes to my advisor, Dr. Caroline Wiltshire, without whom I would not have even dreamt of going to another grad school to do a Ph.D. She has been a great mentor to me. Working with her for the dissertation and for several projects broadened my intellectual horizon and all the drawbacks in me and my research are purely due my own markedness constraint, *INTELLECTUAL. I am grateful to my co-chair, Dr. Ratree Wayland. Her knowledge and sharpness made me see phonetics with a new perspective. Not much unlike the immortal Sherlock Holmes I could often hear her echo: One's ideas must be as broad as Nature if they are to interpret Nature. I am indebted to my committee member Dr. Andrea Pham for the time she spent closely reading my dissertation draft and then meticulously commenting on it. Another committee member, Dr. -

The Problems of English Teaching and Learning in Mizoram
================================================================= Language in India www.languageinindia.com ISSN 1930-2940 Vol. 15:5 May 2015 ================================================================= The Problems of English Teaching and Learning in Mizoram Lalsangpuii, M.A. (English), B.Ed. ================================================================= Abstract This paper discusses the problems of English Language Teaching and Learning in Mizoram, a state in India’s North-Eastern region. Since the State is evolving to be a monolingual state, more and more people tend to use only the local language, although skill in English language use is very highly valued by the people. Problems faced by both the teachers and the students are listed. Deficiencies in the syllabus as well as the textbooks are also pointed out. Some methods to improve the skills of both the teachers and students are suggested. Key words: English language teaching and learning, Mizoram schools, problems faced by students and teachers. 1. Introduction In order to understand the conditions and problems of teaching-learning English in Mizoram, it is important to delve into the background of Mizoram - its geographical location, the origin of the people (Mizo), the languages of the people, and the various cultures and customs practised by the people. How and when English Language Teaching (ELT) was started in Mizoram or how English is perceived, studied, seen and appreciated in Mizoram is an interesting question. Its remoteness and location also create problems for the learners. 2. Geographical Location Language in India www.languageinindia.com ISSN 1930-2940 15:5 May 2015 Lalsangpuii, M.A. (English), B.Ed. The Problems of English Teaching and Learning in Mizoram 173 Figure 1 : Map of Mizoram Mizoram is a mountainous region which became the 23rd State of the Indian Union in February, 1987. -

Saurashtra University Library Service
CORE Metadata, citation and similar papers at core.ac.uk Provided by Etheses - A Saurashtra University Library Service Saurashtra University Re – Accredited Grade ‘B’ by NAAC (CGPA 2.93) Vyas, Ketan B., 2010, A Comparative Study of English and Gujarati Phonological Systems, thesis PhD, Saurashtra University http://etheses.saurashtrauniversity.edu/id/eprint/125 Copyright and moral rights for this thesis are retained by the author A copy can be downloaded for personal non-commercial research or study, without prior permission or charge. This thesis cannot be reproduced or quoted extensively from without first obtaining permission in writing from the Author. The content must not be changed in any way or sold commercially in any format or medium without the formal permission of the Author When referring to this work, full bibliographic details including the author, title, awarding institution and date of the thesis must be given. Saurashtra University Theses Service http://etheses.saurashtrauniversity.edu [email protected] © The Author A COMPARATIVE STUDY OF ENGLISH AND GUJARATI PHONOLOGICAL SYSTEMS DISSERTATION SUBMITTED TO SAURASHTRA UNIVERSITY RAJKOT FOR THE AWARD OF DOCTOR OF PHILOSOPHY IN ENGLISH Supervised by : Submitted by : Dr. Anupam R. Nagar Ketan B. Vyas Principal, Lecturer in English, Dr. V.R.G. College for Girls, Shri G. K. & C. K. Bosamia Porbandar. Arts & Commerce College, Jetpur. Registration No. 3606 2010 CERTIFICATE This is to certify that this dissertation on A COMPARATIVE STUDY OF ENGLISH AND GUJARATI PHONOLOGICAL SYSTEMS is submitted by Mr. Ketan B. Vyas for the degree of Doctor of Philosophy, in the faculty of Arts of Saurashtra University, Rajkot.