Supplementary Materials: Figure S1. the Effect of PROX1 Silencing on the Cell Cycle, the Proliferation and the Survival of CGTH
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Supplementary Materials: Evaluation of Cytotoxicity and Α-Glucosidase Inhibitory Activity of Amide and Polyamino-Derivatives of Lupane Triterpenoids
Supplementary Materials: Evaluation of cytotoxicity and α-glucosidase inhibitory activity of amide and polyamino-derivatives of lupane triterpenoids Oxana B. Kazakova1*, Gul'nara V. Giniyatullina1, Akhat G. Mustafin1, Denis A. Babkov2, Elena V. Sokolova2, Alexander A. Spasov2* 1Ufa Institute of Chemistry of the Ufa Federal Research Centre of the Russian Academy of Sciences, 71, pr. Oktyabrya, 450054 Ufa, Russian Federation 2Scientific Center for Innovative Drugs, Volgograd State Medical University, Novorossiyskaya st. 39, Volgograd 400087, Russian Federation Correspondence Prof. Dr. Oxana B. Kazakova Ufa Institute of Chemistry of the Ufa Federal Research Centre of the Russian Academy of Sciences 71 Prospeсt Oktyabrya Ufa, 450054 Russian Federation E-mail: [email protected] Prof. Dr. Alexander A. Spasov Scientific Center for Innovative Drugs of the Volgograd State Medical University 39 Novorossiyskaya st. Volgograd, 400087 Russian Federation E-mail: [email protected] Figure S1. 1H and 13C of compound 2. H NH N H O H O H 2 2 Figure S2. 1H and 13C of compound 4. NH2 O H O H CH3 O O H H3C O H 4 3 Figure S3. Anticancer screening data of compound 2 at single dose assay 4 Figure S4. Anticancer screening data of compound 7 at single dose assay 5 Figure S5. Anticancer screening data of compound 8 at single dose assay 6 Figure S6. Anticancer screening data of compound 9 at single dose assay 7 Figure S7. Anticancer screening data of compound 12 at single dose assay 8 Figure S8. Anticancer screening data of compound 13 at single dose assay 9 Figure S9. Anticancer screening data of compound 14 at single dose assay 10 Figure S10. -

CCT3 Rabbit Pab
Leader in Biomolecular Solutions for Life Science CCT3 Rabbit pAb Catalog No.: A6547 3 Publications Basic Information Background Catalog No. The protein encoded by this gene is a molecular chaperone that is a member of the A6547 chaperonin containing TCP1 complex (CCT), also known as the TCP1 ring complex (TRiC). This complex consists of two identical stacked rings, each containing eight different Observed MW proteins. Unfolded polypeptides enter the central cavity of the complex and are folded 60kDa in an ATP-dependent manner. The complex folds various proteins, including actin and tubulin. Alternate transcriptional splice variants have been characterized for this gene. Calculated MW In addition, a pseudogene of this gene has been found on chromosome 8. 56kDa/60kDa Category Primary antibody Applications WB,IHC,IF Cross-Reactivity Human, Mouse, Rat Recommended Dilutions Immunogen Information WB 1:500 - 1:2000 Gene ID Swiss Prot 7203 P49368 IHC 1:50 - 1:200 Immunogen 1:50 - 1:200 IF Recombinant fusion protein containing a sequence corresponding to amino acids 1-300 of human CCT3 (NP_005989.3). Synonyms CCT3;CCT-gamma;CCTG;PIG48;TCP-1-gamma;TRIC5 Contact Product Information www.abclonal.com Source Isotype Purification Rabbit IgG Affinity purification Storage Store at -20℃. Avoid freeze / thaw cycles. Buffer: PBS with 0.02% sodium azide,50% glycerol,pH7.3. Validation Data Western blot analysis of extracts of various cell lines, using CCT3 antibody (A6547) at 1:1000 dilution. Secondary antibody: HRP Goat Anti-Rabbit IgG (H+L) (AS014) at 1:10000 dilution. Lysates/proteins: 25ug per lane. Blocking buffer: 3% nonfat dry milk in TBST. -

Cell Death Via Lipid Peroxidation and Protein Aggregation Diseases
biology Review Cell Death via Lipid Peroxidation and Protein Aggregation Diseases Katsuya Iuchi * , Tomoka Takai and Hisashi Hisatomi Department of Materials and Life Science, Faculty of Science and Technology, Seikei University, 3-3-1 Kichijojikitamachi, Musashino-shi, Tokyo 180-8633, Japan; [email protected] (T.T.); [email protected] (H.H.) * Correspondence: [email protected] or [email protected]; Tel.: +81-422-37-3523 Simple Summary: It is essential for cellular homeostasis that biomolecules, such as DNA, proteins, and lipids, function properly. Disturbance of redox homeostasis produces aberrant biomolecules, including oxidized lipids and misfolded proteins, which increase in cells. Aberrant biomolecules are removed by excellent cellular clearance systems. However, when excess aberrant biomolecules remain in the cell, they disrupt organelle and cellular functions, leading to cell death. These aberrant molecules aggregate and cause apoptotic and non-apoptotic cell death, leading to various protein aggregation diseases. Thus, we investigated the cell-death cross-linking between lipid peroxidation and protein aggregation. Abstract: Lipid peroxidation of cellular membranes is a complicated cellular event, and it is both the cause and result of various diseases, such as ischemia-reperfusion injury, neurodegenerative diseases, and atherosclerosis. Lipid peroxidation causes non-apoptotic cell death, which is associated with cell fate determination: survival or cell death. During the radical chain reaction of lipid peroxidation, Citation: Iuchi, K.; Takai, T.; various oxidized lipid products accumulate in cells, followed by organelle dysfunction and the Hisatomi, H. Cell Death via Lipid induction of non-apoptotic cell death. Highly reactive oxidized products from unsaturated fatty acids Peroxidation and Protein are detected under pathological conditions. -

Analysis of Gene Expression Data for Gene Ontology
ANALYSIS OF GENE EXPRESSION DATA FOR GENE ONTOLOGY BASED PROTEIN FUNCTION PREDICTION A Thesis Presented to The Graduate Faculty of The University of Akron In Partial Fulfillment of the Requirements for the Degree Master of Science Robert Daniel Macholan May 2011 ANALYSIS OF GENE EXPRESSION DATA FOR GENE ONTOLOGY BASED PROTEIN FUNCTION PREDICTION Robert Daniel Macholan Thesis Approved: Accepted: _______________________________ _______________________________ Advisor Department Chair Dr. Zhong-Hui Duan Dr. Chien-Chung Chan _______________________________ _______________________________ Committee Member Dean of the College Dr. Chien-Chung Chan Dr. Chand K. Midha _______________________________ _______________________________ Committee Member Dean of the Graduate School Dr. Yingcai Xiao Dr. George R. Newkome _______________________________ Date ii ABSTRACT A tremendous increase in genomic data has encouraged biologists to turn to bioinformatics in order to assist in its interpretation and processing. One of the present challenges that need to be overcome in order to understand this data more completely is the development of a reliable method to accurately predict the function of a protein from its genomic information. This study focuses on developing an effective algorithm for protein function prediction. The algorithm is based on proteins that have similar expression patterns. The similarity of the expression data is determined using a novel measure, the slope matrix. The slope matrix introduces a normalized method for the comparison of expression levels throughout a proteome. The algorithm is tested using real microarray gene expression data. Their functions are characterized using gene ontology annotations. The results of the case study indicate the protein function prediction algorithm developed is comparable to the prediction algorithms that are based on the annotations of homologous proteins. -

Molecular and Physiological Basis for Hair Loss in Near Naked Hairless and Oak Ridge Rhino-Like Mouse Models: Tracking the Role of the Hairless Gene
University of Tennessee, Knoxville TRACE: Tennessee Research and Creative Exchange Doctoral Dissertations Graduate School 5-2006 Molecular and Physiological Basis for Hair Loss in Near Naked Hairless and Oak Ridge Rhino-like Mouse Models: Tracking the Role of the Hairless Gene Yutao Liu University of Tennessee - Knoxville Follow this and additional works at: https://trace.tennessee.edu/utk_graddiss Part of the Life Sciences Commons Recommended Citation Liu, Yutao, "Molecular and Physiological Basis for Hair Loss in Near Naked Hairless and Oak Ridge Rhino- like Mouse Models: Tracking the Role of the Hairless Gene. " PhD diss., University of Tennessee, 2006. https://trace.tennessee.edu/utk_graddiss/1824 This Dissertation is brought to you for free and open access by the Graduate School at TRACE: Tennessee Research and Creative Exchange. It has been accepted for inclusion in Doctoral Dissertations by an authorized administrator of TRACE: Tennessee Research and Creative Exchange. For more information, please contact [email protected]. To the Graduate Council: I am submitting herewith a dissertation written by Yutao Liu entitled "Molecular and Physiological Basis for Hair Loss in Near Naked Hairless and Oak Ridge Rhino-like Mouse Models: Tracking the Role of the Hairless Gene." I have examined the final electronic copy of this dissertation for form and content and recommend that it be accepted in partial fulfillment of the requirements for the degree of Doctor of Philosophy, with a major in Life Sciences. Brynn H. Voy, Major Professor We have read this dissertation and recommend its acceptance: Naima Moustaid-Moussa, Yisong Wang, Rogert Hettich Accepted for the Council: Carolyn R. -

Seq2pathway Vignette
seq2pathway Vignette Bin Wang, Xinan Holly Yang, Arjun Kinstlick May 19, 2021 Contents 1 Abstract 1 2 Package Installation 2 3 runseq2pathway 2 4 Two main functions 3 4.1 seq2gene . .3 4.1.1 seq2gene flowchart . .3 4.1.2 runseq2gene inputs/parameters . .5 4.1.3 runseq2gene outputs . .8 4.2 gene2pathway . 10 4.2.1 gene2pathway flowchart . 11 4.2.2 gene2pathway test inputs/parameters . 11 4.2.3 gene2pathway test outputs . 12 5 Examples 13 5.1 ChIP-seq data analysis . 13 5.1.1 Map ChIP-seq enriched peaks to genes using runseq2gene .................... 13 5.1.2 Discover enriched GO terms using gene2pathway_test with gene scores . 15 5.1.3 Discover enriched GO terms using Fisher's Exact test without gene scores . 17 5.1.4 Add description for genes . 20 5.2 RNA-seq data analysis . 20 6 R environment session 23 1 Abstract Seq2pathway is a novel computational tool to analyze functional gene-sets (including signaling pathways) using variable next-generation sequencing data[1]. Integral to this tool are the \seq2gene" and \gene2pathway" components in series that infer a quantitative pathway-level profile for each sample. The seq2gene function assigns phenotype-associated significance of genomic regions to gene-level scores, where the significance could be p-values of SNPs or point mutations, protein-binding affinity, or transcriptional expression level. The seq2gene function has the feasibility to assign non-exon regions to a range of neighboring genes besides the nearest one, thus facilitating the study of functional non-coding elements[2]. Then the gene2pathway summarizes gene-level measurements to pathway-level scores, comparing the quantity of significance for gene members within a pathway with those outside a pathway. -

New Approaches to Functional Process Discovery in HPV 16-Associated Cervical Cancer Cells by Gene Ontology
Cancer Research and Treatment 2003;35(4):304-313 New Approaches to Functional Process Discovery in HPV 16-Associated Cervical Cancer Cells by Gene Ontology Yong-Wan Kim, Ph.D.1, Min-Je Suh, M.S.1, Jin-Sik Bae, M.S.1, Su Mi Bae, M.S.1, Joo Hee Yoon, M.D.2, Soo Young Hur, M.D.2, Jae Hoon Kim, M.D.2, Duck Young Ro, M.D.2, Joon Mo Lee, M.D.2, Sung Eun Namkoong, M.D.2, Chong Kook Kim, Ph.D.3 and Woong Shick Ahn, M.D.2 1Catholic Research Institutes of Medical Science, 2Department of Obstetrics and Gynecology, College of Medicine, The Catholic University of Korea, Seoul; 3College of Pharmacy, Seoul National University, Seoul, Korea Purpose: This study utilized both mRNA differential significant genes of unknown function affected by the display and the Gene Ontology (GO) analysis to char- HPV-16-derived pathway. The GO analysis suggested that acterize the multiple interactions of a number of genes the cervical cancer cells underwent repression of the with gene expression profiles involved in the HPV-16- cancer-specific cell adhesive properties. Also, genes induced cervical carcinogenesis. belonging to DNA metabolism, such as DNA repair and Materials and Methods: mRNA differential displays, replication, were strongly down-regulated, whereas sig- with HPV-16 positive cervical cancer cell line (SiHa), and nificant increases were shown in the protein degradation normal human keratinocyte cell line (HaCaT) as a con- and synthesis. trol, were used. Each human gene has several biological Conclusion: The GO analysis can overcome the com- functions in the Gene Ontology; therefore, several func- plexity of the gene expression profile of the HPV-16- tions of each gene were chosen to establish a powerful associated pathway, identify several cancer-specific cel- cervical carcinogenesis pathway. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -
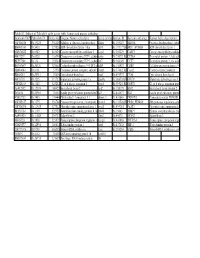
Table S3: Subset of Zebrafish Early Genes with Human And
Table S3: Subset of Zebrafish early genes with human and mouse orthologs Genbank ID(ZFZebrafish ID Entrez GenUnigene Name (zebrafish) Gene symbo Human ID Humann ortholog Human Gene description AW116838 Dr.19225 336425 Aldolase a, fructose-bisphosphate aldoa Hs.155247 ALDOA Fructose-bisphosphate aldola BM005100 Dr.5438 327026 ADP-ribosylation factor 1 like arf1l Hs.119177||HsARF1_HUMAN ADP-ribosylation factor 1 AW076882 Dr.6582 403025 Cancer susceptibility candidate 3 casc3 Hs.350229 CASC3 Cancer susceptibility candidat AI437239 Dr.6928 116994 Chaperonin containing TCP1, subun cct6a Hs.73072||Hs.CCT6A T-complex protein 1, zeta sub BE557308 Dr.134 192324 Chaperonin containing TCP1, subun cct7 Hs.368149 CCT7 T-complex protein 1, eta subu BG303647 Dr.26326 321602 Cyclin-dependent kinase 9 (CDC2-recdk9 Hs.150423 CDK9 Cell division protein kinase 9 AB040044 Dr.8161 57970 Coatomer protein complex, subunit zcopz1 Hs.37482||Hs.Copz2 Coatomer zeta-2 subunit BI888253 Dr.20911 30436 Eyes absent homolog 1 eya1 Hs.491997 EYA4 Eyes absent homolog 4 AI878758 Dr.3225 317737 Glutamate dehydrogenase 1a glud1a Hs.368538||HsGLUD1 Glutamate dehydrogenase 1, AW128619 Dr.1388 325284 G1 to S phase transition 1 gspt1 Hs.59523||Hs.GSPT1 G1 to S phase transition prote AF412832 Dr.12595 140427 Heat shock factor 2 hsf2 Hs.158195 HSF2 Heat shock factor protein 2 D38454 Dr.20916 30151 Insulin gene enhancer protein Islet3 isl3 Hs.444677 ISL2 Insulin gene enhancer protein AY052752 Dr.7485 170444 Pbx/knotted 1 homeobox 1.1 pknox1.1 Hs.431043 PKNOX1 Homeobox protein PKNOX1 -

Genetic and Genomic Analysis of Hyperlipidemia, Obesity and Diabetes Using (C57BL/6J × TALLYHO/Jngj) F2 Mice
University of Tennessee, Knoxville TRACE: Tennessee Research and Creative Exchange Nutrition Publications and Other Works Nutrition 12-19-2010 Genetic and genomic analysis of hyperlipidemia, obesity and diabetes using (C57BL/6J × TALLYHO/JngJ) F2 mice Taryn P. Stewart Marshall University Hyoung Y. Kim University of Tennessee - Knoxville, [email protected] Arnold M. Saxton University of Tennessee - Knoxville, [email protected] Jung H. Kim Marshall University Follow this and additional works at: https://trace.tennessee.edu/utk_nutrpubs Part of the Animal Sciences Commons, and the Nutrition Commons Recommended Citation BMC Genomics 2010, 11:713 doi:10.1186/1471-2164-11-713 This Article is brought to you for free and open access by the Nutrition at TRACE: Tennessee Research and Creative Exchange. It has been accepted for inclusion in Nutrition Publications and Other Works by an authorized administrator of TRACE: Tennessee Research and Creative Exchange. For more information, please contact [email protected]. Stewart et al. BMC Genomics 2010, 11:713 http://www.biomedcentral.com/1471-2164/11/713 RESEARCH ARTICLE Open Access Genetic and genomic analysis of hyperlipidemia, obesity and diabetes using (C57BL/6J × TALLYHO/JngJ) F2 mice Taryn P Stewart1, Hyoung Yon Kim2, Arnold M Saxton3, Jung Han Kim1* Abstract Background: Type 2 diabetes (T2D) is the most common form of diabetes in humans and is closely associated with dyslipidemia and obesity that magnifies the mortality and morbidity related to T2D. The genetic contribution to human T2D and related metabolic disorders is evident, and mostly follows polygenic inheritance. The TALLYHO/ JngJ (TH) mice are a polygenic model for T2D characterized by obesity, hyperinsulinemia, impaired glucose uptake and tolerance, hyperlipidemia, and hyperglycemia. -

1 Supporting Information for a Microrna Network Regulates
Supporting Information for A microRNA Network Regulates Expression and Biosynthesis of CFTR and CFTR-ΔF508 Shyam Ramachandrana,b, Philip H. Karpc, Peng Jiangc, Lynda S. Ostedgaardc, Amy E. Walza, John T. Fishere, Shaf Keshavjeeh, Kim A. Lennoxi, Ashley M. Jacobii, Scott D. Rosei, Mark A. Behlkei, Michael J. Welshb,c,d,g, Yi Xingb,c,f, Paul B. McCray Jr.a,b,c Author Affiliations: Department of Pediatricsa, Interdisciplinary Program in Geneticsb, Departments of Internal Medicinec, Molecular Physiology and Biophysicsd, Anatomy and Cell Biologye, Biomedical Engineeringf, Howard Hughes Medical Instituteg, Carver College of Medicine, University of Iowa, Iowa City, IA-52242 Division of Thoracic Surgeryh, Toronto General Hospital, University Health Network, University of Toronto, Toronto, Canada-M5G 2C4 Integrated DNA Technologiesi, Coralville, IA-52241 To whom correspondence should be addressed: Email: [email protected] (M.J.W.); yi- [email protected] (Y.X.); Email: [email protected] (P.B.M.) This PDF file includes: Materials and Methods References Fig. S1. miR-138 regulates SIN3A in a dose-dependent and site-specific manner. Fig. S2. miR-138 regulates endogenous SIN3A protein expression. Fig. S3. miR-138 regulates endogenous CFTR protein expression in Calu-3 cells. Fig. S4. miR-138 regulates endogenous CFTR protein expression in primary human airway epithelia. Fig. S5. miR-138 regulates CFTR expression in HeLa cells. Fig. S6. miR-138 regulates CFTR expression in HEK293T cells. Fig. S7. HeLa cells exhibit CFTR channel activity. Fig. S8. miR-138 improves CFTR processing. Fig. S9. miR-138 improves CFTR-ΔF508 processing. Fig. S10. SIN3A inhibition yields partial rescue of Cl- transport in CF epithelia. -

Genes with 5' Terminal Oligopyrimidine Tracts Preferentially Escape Global Suppression of Translation by the SARS-Cov-2 NSP1 Protein
Downloaded from rnajournal.cshlp.org on September 28, 2021 - Published by Cold Spring Harbor Laboratory Press Genes with 5′ terminal oligopyrimidine tracts preferentially escape global suppression of translation by the SARS-CoV-2 Nsp1 protein Shilpa Raoa, Ian Hoskinsa, Tori Tonna, P. Daniela Garciaa, Hakan Ozadama, Elif Sarinay Cenika, Can Cenika,1 a Department of Molecular Biosciences, University of Texas at Austin, Austin, TX 78712, USA 1Corresponding author: [email protected] Key words: SARS-CoV-2, Nsp1, MeTAFlow, translation, ribosome profiling, RNA-Seq, 5′ TOP, Ribo-Seq, gene expression 1 Downloaded from rnajournal.cshlp.org on September 28, 2021 - Published by Cold Spring Harbor Laboratory Press Abstract Viruses rely on the host translation machinery to synthesize their own proteins. Consequently, they have evolved varied mechanisms to co-opt host translation for their survival. SARS-CoV-2 relies on a non-structural protein, Nsp1, for shutting down host translation. However, it is currently unknown how viral proteins and host factors critical for viral replication can escape a global shutdown of host translation. Here, using a novel FACS-based assay called MeTAFlow, we report a dose-dependent reduction in both nascent protein synthesis and mRNA abundance in cells expressing Nsp1. We perform RNA-Seq and matched ribosome profiling experiments to identify gene-specific changes both at the mRNA expression and translation level. We discover that a functionally-coherent subset of human genes are preferentially translated in the context of Nsp1 expression. These genes include the translation machinery components, RNA binding proteins, and others important for viral pathogenicity. Importantly, we uncovered a remarkable enrichment of 5′ terminal oligo-pyrimidine (TOP) tracts among preferentially translated genes.