Veridicality and Utterance Meaning
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Empirical Base of Linguistics: Grammaticality Judgments and Linguistic Methodology
UCLA UCLA Previously Published Works Title The empirical base of linguistics: Grammaticality judgments and linguistic methodology Permalink https://escholarship.org/uc/item/05b2s4wg ISBN 978-3946234043 Author Schütze, Carson T Publication Date 2016-02-01 DOI 10.17169/langsci.b89.101 Data Availability The data associated with this publication are managed by: Language Science Press, Berlin Peer reviewed eScholarship.org Powered by the California Digital Library University of California The empirical base of linguistics Grammaticality judgments and linguistic methodology Carson T. Schütze language Classics in Linguistics 2 science press Classics in Linguistics Chief Editors: Martin Haspelmath, Stefan Müller In this series: 1. Lehmann, Christian. Thoughts on grammaticalization 2. Schütze, Carson T. The empirical base of linguistics: Grammaticality judgments and linguistic methodology 3. Bickerton, Derek. Roots of language ISSN: 2366-374X The empirical base of linguistics Grammaticality judgments and linguistic methodology Carson T. Schütze language science press Carson T. Schütze. 2019. The empirical base of linguistics: Grammaticality judgments and linguistic methodology (Classics in Linguistics 2). Berlin: Language Science Press. This title can be downloaded at: http://langsci-press.org/catalog/book/89 © 2019, Carson T. Schütze Published under the Creative Commons Attribution 4.0 Licence (CC BY 4.0): http://creativecommons.org/licenses/by/4.0/ ISBN: 978-3-946234-02-9 (Digital) 978-3-946234-03-6 (Hardcover) 978-3-946234-04-3 (Softcover) 978-1-523743-32-2 -

Sentential Negation and Negative Concord
Sentential Negation and Negative Concord Published by LOT phone: +31.30.2536006 Trans 10 fax: +31.30.2536000 3512 JK Utrecht email: [email protected] The Netherlands http://wwwlot.let.uu.nl/ Cover illustration: Kasimir Malevitch: Black Square. State Hermitage Museum, St. Petersburg, Russia. ISBN 90-76864-68-3 NUR 632 Copyright © 2004 by Hedde Zeijlstra. All rights reserved. Sentential Negation and Negative Concord ACADEMISCH PROEFSCHRIFT ter verkrijging van de graad van doctor aan de Universiteit van Amsterdam op gezag van de Rector Magnificus Prof. Mr P.F. van der Heijden ten overstaan van een door het College voor Promoties ingestelde commissie, in het openbaar te verdedigen in de Aula der Universiteit op woensdag 15 december 2004, te 10:00 uur door HEDZER HUGO ZEIJLSTRA geboren te Rotterdam Promotiecommissie: Promotores: Prof. Dr H.J. Bennis Prof. Dr J.A.G. Groenendijk Copromotor: Dr J.B. den Besten Leden: Dr L.C.J. Barbiers (Meertens Instituut, Amsterdam) Dr P.J.E. Dekker Prof. Dr A.C.J. Hulk Prof. Dr A. von Stechow (Eberhard Karls Universität Tübingen) Prof. Dr F.P. Weerman Faculteit der Geesteswetenschappen Voor Petra Table of Contents TABLE OF CONTENTS ............................................................................................ I ACKNOWLEDGEMENTS .......................................................................................V 1 INTRODUCTION................................................................................................1 1.1 FOUR ISSUES IN THE STUDY OF NEGATION.......................................................1 -

Like, Hedging and Mirativity. a Unified Account
Like, hedging and mirativity. A unified account. Abstract (4) Never thought I would say this, but Lil’ Wayne, is like. smart. We draw a connection between ‘hedging’ (5) My friend I used to hang out with is like use of the discourse particle like in Amer- . rich now. ican English and its use as a mirative marker of surprise. We propose that both (6) Whoa! I like . totally won again! uses of like widen the size of a pragmati- cally restricted set – a pragmatic halo vs. a In (4), the speaker is signaling that they did not doxastic state. We thus derive hedging and expect to discover that Lil Wayne is smart; in (5) surprise effects in a unified way, outlining the speaker is surprised to learn that their former an underlying link between the semantics friend is now rich; and in (6) the speaker is sur- of like and the one of other mirative mark- prised by the fact that they won again. ers cross-linguistically. After presenting several diagnostics that point to a genuine empirical difference between these 1 Introduction uses, we argue that they do in fact share a core grammatical function: both trigger the expansion Mirative expressions, which mark surprising in- of a pragmatically restricted set: the pragmatic formation (DeLancey 1997), are often expressed halo of an expression for the hedging variant; and through linguistic markers that are also used to en- the doxastic state of the speaker for the mirative code other, seemingly unrelated meanings – e.g., use. We derive hedging and mirativity as effects evidential markers that mark lack of direct evi- of the particular type of object to which like ap- dence (Turkish: Slobin and Aksu 1982; Peterson plies. -

Negation and Polarity: an Introduction
Nat Lang Linguist Theory (2010) 28: 771–786 DOI 10.1007/s11049-010-9114-0 Negation and polarity: an introduction Doris Penka · Hedde Zeijlstra Accepted: 9 September 2010 / Published online: 26 November 2010 © The Author(s) 2010. This article is published with open access at Springerlink.com Abstract This introduction addresses some key issues and questions in the study of negation and polarity. Focussing on negative polarity and negative indefinites, it summarizes research trends and results. Special attention is paid to the issues of syn- chronic variation and diachronic change in the realm of negative polarity items, which figure prominently in the articles and commentaries contained in this special issue. Keywords Negative polarity · Negative indefinites · n-words · Negative concord · Synchronic variation · Diachronic change 1 Background This special issue takes its origin in the workshop on negation and polarity (Neg- Pol07) that was held at the University of Tübingen in March 2007. The workshop was hosted by the Collaborative Research Centre 441 “Linguistic Data Structures” and funded by the German Research Council (DFG). Its aim was to bring together researchers working on theoretical aspects of negation and polarity items as well as the empirical basis surrounding these phenomena. One of the reasons to organize this workshop, and to put together this special is- sue, is that after several decades of generative research it is now generally felt that quite some progress has been made in understanding the general mechanics and mo- tivations behind negation and polarity items. At the same time, it becomes more and D. Penka () Zukunftskolleg and Department of Linguistics, University of Konstanz, Box 216, 78457 Konstanz, Germany e-mail: [email protected] H. -

(2019). the Nature of Morphosyntactic Processing During Language
1 The Nature of Morphosyntactic Processing during Language Perception. Evidence from an Additional-Task Study in Spanish and German. Annette Hohlfelda, Manuel Martín-Loechesa, and Werner Sommerb aCenter for Human Evolution and Behavior, UCM-ISCIII, Madrid bHumboldt-University at Berlin Address correspondence to: Annette Hohlfeld Neurologic Rehabilitation Center Wolletzsee Language Therapy Department Zur Welse 2, 16278 Wolletz Tel.: ++49-(0)33337-49-453 E-Mail: [email protected] 2 Abstract (250 words) The present study investigates in how far morphosyntactic processing is affected by an additional non-verbal task and whether this effect differs between German and Spanish, two languages with differences in processing grammatical gender (lexical vs. cue-based processing). By manipulating task load and language we aimed at getting an insight into subprocesses of morphosyntax and their dependence on resources of general and verbal working memory, respectively. In more general terms, this study contributes to the debate on the modularity of morphosyntax. Written German or Spanish sentences with or without gender violations were presented word by word to native speakers. The critical words temporally overlapped in different degrees with a non-linguistic stimulus (a high or low tone). In a single task (Experiment 1) participants judged sentence acceptability and ignored the tones. Experiment 2 required a response to the tones. Left-anterior negativity (LAN) and P600 components were analyzed in the ERPs to critical words. Whereas the LAN was not affected by any of the experimental manipulations, the P600 was modulated as a function of language during the single task conditions (Experiment 1). In Experiment 2 the additional task did not add up with this effect; instead, the differences between language groups vanished. -

(Non)Veridicality and Mood Choice: Subjunctive, Polarity, and Time
(Non)veridicality and mood choice: subjunctive, polarity, and time Anastasia Giannakidou University of Chicago February 2009 Abstract In this paper, I consider the lexical parameters determining mood choice in Greek. The main questions to be addressed are: In what sense is the subjunctive dependent in main and embedded clauses? What is the meaning of the subjunctive itself, and how is this meaning compatible with the lexical property that licenses the subjunctive? In examining these questions we look at the patterns of mood choice in embedded clauses and adjuncts such as prin “before’ and xoris ‘without’, as well as what appears to be non-canonical “triggering” of the subjunctive, e.g. in relative clauses, and in the so-called polarity subjunctive after negation and other polarity contexts. I propose that nonveridicality allows us to capture both selection and triggering as lexical sensitivity to nonveridicality. Building on Giannakidou 2009 I further argue that we can explain the dependency of the subjunctive to nonveridicality if we assume that its tense is non- deictic, i.e. it cannot make reference to a contextually specified time, which is what ‘regular’ tenses normally do. 1 What is grammatical mood? The study of grammatical mood has a venerable tradition. In the study of classical languages, i.e. Ancient Greek and Latin, we talk about a number of moods: indicative, subjunctive, optative, imperative, at least— and these appear in main as well as embedded clauses. The indicative is typically the mood of assertions, and in this sense -
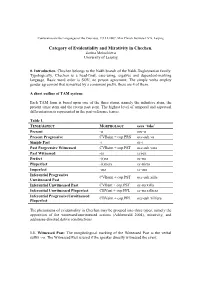
Category of Evidentiality and Mirativity in Chechen. Zarina Molochieva University of Leipzig
Conference on the Languages of the Caucasus, 7-9.12.2007, Max Planck Institute EVA, Leipzig Category of Evidentiality and Mirativity in Chechen. Zarina Molochieva University of Leipzig 0. Introduction. Chechen belongs to the Nakh branch of the Nakh-Daghestanian family. Typologically, Chechen is a head-final, case-using, ergative and dependent-marking language. Basic word order is SOV; no person agreement. The simple verbs employ gender agreement that is marked by a consonant prefix, there are 4 of them. A short outline of TAM system: Each TAM form is based upon one of the three stems, namely the infinitive stem, the present tense stem and the recent past stem. The highest level of temporal and aspectual differentiation is represented in the past-reference tenses. Table 1. TENSE/ASPECT MORPHOLOGY eeca ‘take’ Present -u oec-u Present Progressive CVBsim + cop.PRS oec-ush vu Simple Past -i ec-i Past Progressive Witnessed CVBsim + cop.PST oec-ush vara Past Witnessed -ra eci-ra Perfect -(i)na ec-na Pluperfect -(i)niera ec-niera Imperfect -ura ec-ura Inferential Progressive CVBsim + cop.PST oec-ush xilla Unwitnessed Past Inferential Unwitnessed Past CVBant + cop.PST ec-na xilla Inferential Unwitnessed Pluperfect CBVant + cop.PPL ec-na xilliera Inferential ProgressiveUnwitnessed CBVsim + cop.PPL oec-ush xilliera Pluperfect The phenomena of evidentiality in Chechen may be grouped into three types, namely the opposition of the witnessed/unwitnessed actions (Aikhenvald 2004), mirativity, and addressee-directed dative constructions. 1.1. Witnessed Past: The morphological marking of the Witnessed Past is the verbal suffix -ra. The Witnessed Past is used if the speaker directly witnessed the event. -

A Two Dimensional Analysis of the Future: Modal Adverbs and Speaker’S Bias
A two dimensional analysis of the future: modal adverbs and speaker's bias Anastasia Giannakidou1∗and Alda Mari2 1 University of Chicago, Chicago USA [email protected] 2 Institut Jean Nicod (CNRS/ENS/EHESS, Paris, France [email protected] Abstract Whether future morphemes in languages are temporal or modal operators is a central question in the semantics of the future. Most analyses (with the exception of [14]; see its rebuttal in [14]), agree that future morphemes do convey modality, and do not always make reference to future times. We study here the temporal (future time) reading of the future (John will arrive at 5pm), which we call `predictive'. The modality of the predictive reading is often assumed to be purely metaphysical (e.g. [13]). Based on novel Greek and Italian data with modal adverbs, we argue that prediction involves both a metaphysical and an epistemic dimension, and we offer an analysis that relies on knowledge of the speaker at the utterance time t0. This knowledge restricts the set of the futures (metaphysical branches) only to reasonable ones (in the sense of [18]). In these branches the prejacent comes out true. We also propose that when predicting the speaker has a degree of bias that the actual world-to-come at t0 will be reasonable. This bias, to our knowledge not observed before, is reflected in the use of adverbs, and although by default it expresses high confidence, it can be quite variable, from very strong to relatively weak{ as is evidenced by the wide range of modal adverbs that can co-occur with the future morpheme. -

Evidentiality: Unifying Nominal and Propositional Domains
For Linguistics meets Philosophy (D. Altshuler, ed.), CUP (revised draft of November 2020) Evidentiality: unifying nominal and propositional domains Diti Bhadra University of Minnesota 1 Introduction An evidential is a linguistic marker of how an agent came across a piece of information (Chafe and Nichols 1986, Aikhenvald 2004). This ‘how’ is termed as the evidence for the information, and natural languages allow a variety of manners of evidence-collection, leading to a range of evidentials. The issue of evidence for a proposition has been viewed in both linguistics and philosophy as a complex issue. The cognitive processes that are involved in qualifying the content of an agent’s utterance with the source of the information are sensitive to several kinds of considerations: via what mechanism was the evidence collected (perceptual senses, inference from some observable consequences of an event, inference based on world knowledge, hearsay from a third party, hearsay from legends); when was the evidence made available to the agent temporally (when the event took place, or when the results were detected, or at a time distal/proximal to the time of the verbal report, and so on); how reliable is the source of the evidence (an agent may rank a third party source over their own inference in a judge of trustworthiness). Consider the sentence below from Jarawara (Dixon 2004): (1) [[mee tabori botee]-mete-moneha] otaaA awa-hamaro ama-ke 3nsg home:f old-fpnf-repf nsg.exc see-fpef extent-decf ‘We were seeing this in the far past what was reported to be their old camp from far past.’ This sentence has three dierent evidentials on dierent elements, marking dierent avors of evidence. -

Evidentiality, Egophoricity, and Engagement
Evidentiality, egophoricity, and engagement Edited by Henrik Bergqvist Seppo Kittilä language Studies in Diversity Linguistics 30 science press Studies in Diversity Linguistics Editor: Martin Haspelmath In this series: 1. Handschuh, Corinna. A typology of 18. Paggio, Patrizia and Albert Gatt (eds.). The markedS languages. languages of Malta. 2. Rießler, Michael. Adjective attribution. 19. Seržant, Ilja A. & Alena WitzlackMakarevich 3. Klamer, Marian (ed.). The AlorPantar (eds.). Diachrony of differential argument languages: History and typology. marking. 4. Berghäll, Liisa. A grammar of Mauwake 20. Hölzl, Andreas. A typology of questions in (Papua New Guinea). Northeast Asia and beyond: An ecological 5. Wilbur, Joshua. A grammar of Pite Saami. perspective. 6. Dahl, Östen. Grammaticalization in the 21. Riesberg, Sonja, Asako Shiohara & Atsuko North: Noun phrase morphosyntax in Utsumi (eds.). Perspectives on information Scandinavian vernaculars. structure in Austronesian languages. 7. Schackow, Diana. A grammar of Yakkha. 22. Döhler, Christian. A grammar of Komnzo. 8. Liljegren, Henrik. A grammar of Palula. 23. Yakpo, Kofi. A Grammar of Pichi. 9. Shimelman, Aviva. A grammar of Yauyos Quechua. 24. Guérin Valérie (ed.). Bridging constructions. 10. Rudin, Catherine & Bryan James Gordon 25. AguilarGuevara, Ana, Julia Pozas Loyo & (eds.). Advances in the study of Siouan Violeta VázquezRojas Maldonado *eds.). languages and linguistics. Definiteness across languages. 11. Kluge, Angela. A grammar of Papuan Malay. 26. Di Garbo, Francesca, Bruno Olsson & 12. Kieviet, Paulus. A grammar of Rapa Nui. Bernhard Wälchli (eds.). Grammatical 13. Michaud, Alexis. Tone in Yongning Na: gender and linguistic complexity: Volume I: Lexical tones and morphotonology. General issues and specific studies. 14. -

In Defence of the Veridical Nature of Semantic Information
EUJAP VOL. 3 No. 2007 ORIGinal SCienTifiC papeR UDK: 65 :8 IN DEFENCE OF THE VERIDICAL NATURE OF SEMANTIC INFORMATION LUCIANO FLORIDI University of Hertfordshire University of Oxford ABSTRACT Cominius: “Where is that slave which told me they had beat you to your trenches? This paper contributes to the current debate on the nature of semantic information by offering Where is he? Call him hither.” a semantic argument in favour of the veridical Marcius (Coriolanus): “Let him alone; he thesis according to which p counts as informa- did inform the truth”. tion only if p is true. In the course of the analy- sis, the paper reviews some basic principles and Shakespeare, Coriolanus Act I, Scene VI. requirements for any theory of semantic infor- mation. Key words: Bar-Hillel-Carnap paradox; data; Introduction semantic information, veridical thesis In recent years, philosophical interest in the concept of information and its logi- cal analysis has been growing steadily. One of the current debates concerns the veridical nature of semantic informa- tion. The debate has been triggered by the definition of semantic information as well-formed, meaningful and veridical data, which I proposed a few years ago (see now Floridi 2004b). Such a defini- tion – according to which semantic infor- mation encapsulates truth, exactly as the concept of knowledge does – has attract- ed some criticism for being too strong.2 For an updated overview and guide to the literature see Floridi 2005b. 2 See for example the discussion in Fetzer 2004, with a 31 EUJAP Vol. 3 No. 2007 In this paper, I offer an argument, which I hope will be conclusive, in favour of the ve- ridicality thesis. -

Evidentiality and Mood: Grammatical Expressions of Epistemic Modality in Bulgarian
Evidentiality and mood: Grammatical expressions of epistemic modality in Bulgarian DISSERTATION Presented in Partial Fulfillment of the Requirements o the Degree Doctor of Philosophy in the Graduate School of The Ohio State University By Anastasia Smirnova, M.A. Graduate Program in Linguistics The Ohio State University 2011 Dissertation Committee: Brian Joseph, co-advisor Judith Tonhauser, co-advisor Craige Roberts Copyright by Anastasia Smirnova 2011 ABSTRACT This dissertation is a case study of two grammatical categories, evidentiality and mood. I argue that evidentiality and mood are grammatical expressions of epistemic modality and have an epistemic modal component as part of their meanings. While the empirical foundation for this work is data from Bulgarian, my analysis has a number of empirical and theoretical consequences for the previous work on evidentiality and mood in the formal semantics literature. Evidentiality is traditionally analyzed as a grammatical category that encodes information sources (Aikhenvald 2004). I show that the Bulgarian evidential has richer meaning: not only does it express information source, but also it has a temporal and a modal component. With respect to the information source, the Bulgarian evidential is compatible with a variety of evidential meanings, i.e. direct, inferential, and reportative, as long as the speaker has concrete perceivable evidence (as opposed to evidence based on a mental activity). With respect to epistemic commitment, the construction has different felicity conditions depending on the context: the speaker must be committed to the truth of the proposition in the scope of the evidential in a direct/inferential evidential context, but not in a reportative context.