Feynman Diagram Sampling for Quantum Field Theories on the QPACE 2 Supercomputer
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

QCD Theory 6Em2pt Formation of Quark-Gluon Plasma In
QCD theory Formation of quark-gluon plasma in QCD T. Lappi University of Jyvaskyl¨ a,¨ Finland Particle physics day, Helsinki, October 2017 1/16 Outline I Heavy ion collision: big picture I Initial state: small-x gluons I Production of particles in weak coupling: gluon saturation I 2 ways of understanding glue I Counting particles I Measuring gluon field I For practical phenomenology: add geometry 2/16 A heavy ion event at the LHC How does one understand what happened here? 3/16 Concentrate here on the earliest stage Heavy ion collision in spacetime The purpose in heavy ion collisions: to create QCD matter, i.e. system that is large and lives long compared to the microscopic scale 1 1 t L T > 200MeV T T t freezefreezeout out hadronshadron in eq. gas gluonsquark-gluon & quarks in eq. plasma gluonsnonequilibrium & quarks out of eq. quarks, gluons colorstrong fields fields z (beam axis) 4/16 Heavy ion collision in spacetime The purpose in heavy ion collisions: to create QCD matter, i.e. system that is large and lives long compared to the microscopic scale 1 1 t L T > 200MeV T T t freezefreezeout out hadronshadron in eq. gas gluonsquark-gluon & quarks in eq. plasma gluonsnonequilibrium & quarks out of eq. quarks, gluons colorstrong fields fields z (beam axis) Concentrate here on the earliest stage 4/16 Color charge I Charge has cloud of gluons I But now: gluons are source of new gluons: cascade dN !−1−O(αs) d! ∼ Cascade of gluons Electric charge I At rest: Coulomb electric field I Moving at high velocity: Coulomb field is cloud of photons -

Effective Quantum Field Theories Thomas Mannel Theoretical Physics I (Particle Physics) University of Siegen, Siegen, Germany
Generating Functionals Functional Integration Renormalization Introduction to Effective Quantum Field Theories Thomas Mannel Theoretical Physics I (Particle Physics) University of Siegen, Siegen, Germany 2nd Autumn School on High Energy Physics and Quantum Field Theory Yerevan, Armenia, 6-10 October, 2014 T. Mannel, Siegen University Effective Quantum Field Theories: Lecture 1 Generating Functionals Functional Integration Renormalization Overview Lecture 1: Basics of Quantum Field Theory Generating Functionals Functional Integration Perturbation Theory Renormalization Lecture 2: Effective Field Thoeries Effective Actions Effective Lagrangians Identifying relevant degrees of freedom Renormalization and Renormalization Group T. Mannel, Siegen University Effective Quantum Field Theories: Lecture 1 Generating Functionals Functional Integration Renormalization Lecture 3: Examples @ work From Standard Model to Fermi Theory From QCD to Heavy Quark Effective Theory From QCD to Chiral Perturbation Theory From New Physics to the Standard Model Lecture 4: Limitations: When Effective Field Theories become ineffective Dispersion theory and effective field theory Bound Systems of Quarks and anomalous thresholds When quarks are needed in QCD É. T. Mannel, Siegen University Effective Quantum Field Theories: Lecture 1 Generating Functionals Functional Integration Renormalization Lecture 1: Basics of Quantum Field Theory Thomas Mannel Theoretische Physik I, Universität Siegen f q f et Yerevan, October 2014 T. Mannel, Siegen University Effective Quantum -

The Positons of the Three Quarks Composing the Proton Are Illustrated
The posi1ons of the three quarks composing the proton are illustrated by the colored spheres. The surface plot illustrates the reduc1on of the vacuum ac1on density in a plane passing through the centers of the quarks. The vector field illustrates the gradient of this reduc1on. The posi1ons in space where the vacuum ac1on is maximally expelled from the interior of the proton are also illustrated by the tube-like structures, exposing the presence of flux tubes. a key point of interest is the distance at which the flux-tube formaon occurs. The animaon indicates that the transi1on to flux-tube formaon occurs when the distance of the quarks from the center of the triangle is greater than 0.5 fm. again, the diameter of the flux tubes remains approximately constant as the quarks move to large separaons. • Three quarks indicated by red, green and blue spheres (lower leb) are localized by the gluon field. • a quark-an1quark pair created from the gluon field is illustrated by the green-an1green (magenta) quark pair on the right. These quark pairs give rise to a meson cloud around the proton. hEp://www.physics.adelaide.edu.au/theory/staff/leinweber/VisualQCD/Nobel/index.html Nucl. Phys. A750, 84 (2005) 1000000 QCD mass 100000 Higgs mass 10000 1000 100 Mass (MeV) 10 1 u d s c b t GeV HOW does the rest of the proton mass arise? HOW does the rest of the proton spin (magnetic moment,…), arise? Mass from nothing Dyson-Schwinger and Lattice QCD It is known that the dynamical chiral symmetry breaking; namely, the generation of mass from nothing, does take place in QCD. -

On Topological Vertex Formalism for 5-Brane Webs with O5-Plane
DIAS-STP-20-10 More on topological vertex formalism for 5-brane webs with O5-plane Hirotaka Hayashi,a Rui-Dong Zhub;c aDepartment of Physics, School of Science, Tokai University, 4-1-1 Kitakaname, Hiratsuka-shi, Kanagawa 259-1292, Japan bInstitute for Advanced Study & School of Physical Science and Technology, Soochow University, Suzhou 215006, China cSchool of Theoretical Physics, Dublin Institute for Advanced Studies 10 Burlington Road, Dublin, Ireland E-mail: [email protected], [email protected] Abstract: We propose a concrete form of a vertex function, which we call O-vertex, for the intersection between an O5-plane and a 5-brane in the topological vertex formalism, as an extension of the work of [1]. Using the O-vertex it is possible to compute the Nekrasov partition functions of 5d theories realized on any 5-brane web diagrams with O5-planes. We apply our proposal to 5-brane webs with an O5-plane and compute the partition functions of pure SO(N) gauge theories and the pure G2 gauge theory. The obtained results agree with the results known in the literature. We also compute the partition function of the pure SU(3) gauge theory with the Chern-Simons level 9. At the end we rewrite the O-vertex in a form of a vertex operator. arXiv:2012.13303v2 [hep-th] 12 May 2021 Contents 1 Introduction1 2 O-vertex 3 2.1 Topological vertex formalism with an O5-plane3 2.2 Proposal for O-vertex6 2.3 Higgsing and O-planee 9 3 Examples 11 3.1 SO(2N) gauge theories 11 3.1.1 Pure SO(4) gauge theory 12 3.1.2 Pure SO(6) and SO(8) Theories 15 3.2 SO(2N -

Quantum Electrodynamics in Strong Magnetic Fields. 111* Electron-Photon Interactions
Aust. J. Phys., 1983, 36, 799-824 Quantum Electrodynamics in Strong Magnetic Fields. 111* Electron-Photon Interactions D. B. Melrose and A. J. Parle School of Physics, University of Sydney. Sydney, N.S.W. 2006. Abstract A version of QED is developed which allows one to treat electron-photon interactions in the magnetized vacuum exactly and which allows one to calculate the responses of a relativistic quantum electron gas and include these responses in QED. Gyromagnetic emission and related crossed processes, and Compton scattering and related processes are discussed in some detail. Existing results are corrected or generalized for nonrelativistic (quantum) gyroemission, one-photon pair creation, Compton scattering by electrons in the ground state and two-photon excitation to the first Landau level from the ground state. We also comment on maser action in one-photon pair annihilation. 1. Introduction A full synthesis of quantum electrodynamics (QED) and the classical theory of plasmas requires that the responses of the medium (plasma + vacuum) be included in the photon properties and interactions in QED and that QED be used to calculate the responses of the medium. It was shown by Melrose (1974) how this synthesis could be achieved in the unmagnetized case. In the present paper we extend the synthesized theory to include the magnetized case. Such a synthesized theory is desirable even when the effects of a material medium are negligible. The magnetized vacuum is birefringent with a full hierarchy of nonlinear response tensors, and for many purposes it is convenient to treat the magnetized vacuum as though it were a material medium. -

Modern Methods of Quantum Chromodynamics
Modern Methods of Quantum Chromodynamics Christian Schwinn Albert-Ludwigs-Universit¨atFreiburg, Physikalisches Institut D-79104 Freiburg, Germany Winter-Semester 2014/15 Draft: March 30, 2015 http://www.tep.physik.uni-freiburg.de/lectures/QCD-WS-14 2 Contents 1 Introduction 9 Hadrons and quarks . .9 QFT and QED . .9 QCD: theory of quarks and gluons . .9 QCD and LHC physics . 10 Multi-parton scattering amplitudes . 10 NLO calculations . 11 Remarks on the lecture . 11 I Parton Model and QCD 13 2 Quarks and colour 15 2.1 Hadrons and quarks . 15 Hadrons and the strong interactions . 15 Quark Model . 15 2.2 Parton Model . 16 Deep inelastic scattering . 16 Parton distribution functions . 18 2.3 Colour degree of freedom . 19 Postulate of colour quantum number . 19 Colour-SU(3).............................. 20 Confinement . 20 Evidence of colour: e+e− ! hadrons . 21 2.4 Towards QCD . 22 3 Basics of QFT and QED 25 3.1 Quantum numbers of relativistic particles . 25 3.1.1 Poincar´egroup . 26 3.1.2 Relativistic one-particle states . 27 3.2 Quantum fields . 32 3.2.1 Scalar fields . 32 3.2.2 Spinor fields . 32 3 4 CONTENTS Dirac spinors . 33 Massless spin one-half particles . 34 Spinor products . 35 Quantization . 35 3.2.3 Massless vector bosons . 35 Polarization vectors and gauge invariance . 36 3.3 QED . 37 3.4 Feynman rules . 39 3.4.1 S-matrix and Cross section . 39 S-matrix . 39 Poincar´einvariance of the S-matrix . 40 T -matrix and scattering amplitude . 41 Unitarity of the S-matrix . 41 Cross section . -

The Center Symmetry and Its Spontaneous Breakdown at High Temperatures
CORE Metadata, citation and similar papers at core.ac.uk Provided by CERN Document Server THE CENTER SYMMETRY AND ITS SPONTANEOUS BREAKDOWN AT HIGH TEMPERATURES KIERAN HOLLAND Institute for Theoretical Physics, University of Bern, CH-3012 Bern, Switzerland UWE-JENS WIESE Center for Theoretical Physics, Laboratory for Nuclear Science and Department of Physics, Massachusetts Institute of Technology, Cambridge, Massachusetts 02139, USA The Euclidean action of non-Abelian gauge theories with adjoint dynamical charges (gluons or gluinos) at non-zero temperature T is invariant against topologically non-trivial gauge transformations in the ZZ(N)c center of the SU(N) gauge group. The Polyakov loop measures the free energy of fundamental static charges (in- finitely heavy test quarks) and is an order parameter for the spontaneous break- down of the center symmetry. In SU(N) Yang-Mills theory the ZZ(N)c symmetry is unbroken in the low-temperature confined phase and spontaneously broken in the high-temperature deconfined phase. In 4-dimensional SU(2) Yang-Mills the- ory the deconfinement phase transition is of second order and is in the universality class of the 3-dimensional Ising model. In the SU(3) theory, on the other hand, the transition is first order and its bulk physics is not universal. When a chemical potential µ is used to generate a non-zero baryon density of test quarks, the first order deconfinement transition line extends into the (µ, T )-plane. It terminates at a critical endpoint which also is in the universality class of the 3-dimensional Ising model. At a first order phase transition the confined and deconfined phases coexist and are separated by confined-deconfined interfaces. -

The Confinement Problem in Lattice Gauge Theory
The Confinement Problem in Lattice Gauge Theory J. Greensite 1,2 1Physics and Astronomy Department San Francisco State University San Francisco, CA 94132 USA 2Theory Group, Lawrence Berkeley National Laboratory Berkeley, CA 94720 USA February 1, 2008 Abstract I review investigations of the quark confinement mechanism that have been carried out in the framework of SU(N) lattice gauge theory. The special role of ZN center symmetry is emphasized. 1 Introduction When the quark model of hadrons was first introduced by Gell-Mann and Zweig in 1964, an obvious question was “where are the quarks?”. At the time, one could respond that the arXiv:hep-lat/0301023v2 5 Mar 2003 quark model was simply a useful scheme for classifying hadrons, and the notion of quarks as actual particles need not be taken seriously. But the absence of isolated quark states became a much more urgent issue with the successes of the quark-parton model, and the introduction, in 1972, of quantum chromodynamics as a fundamental theory of hadronic physics [1]. It was then necessary to suppose that, somehow or other, the dynamics of the gluon sector of QCD contrives to eliminate free quark states from the spectrum. Today almost no one seriously doubts that quantum chromodynamics confines quarks. Following many theoretical suggestions in the late 1970’s about how quark confinement might come about, it was finally the computer simulations of QCD, initiated by Creutz [2] in 1980, that persuaded most skeptics. Quark confinement is now an old and familiar idea, routinely incorporated into the standard model and all its proposed extensions, and the focus of particle phenomenology shifted long ago to other issues. -

Phenomenological Review on Quark–Gluon Plasma: Concepts Vs
Review Phenomenological Review on Quark–Gluon Plasma: Concepts vs. Observations Roman Pasechnik 1,* and Michal Šumbera 2 1 Department of Astronomy and Theoretical Physics, Lund University, SE-223 62 Lund, Sweden 2 Nuclear Physics Institute ASCR 250 68 Rez/Prague,ˇ Czech Republic; [email protected] * Correspondence: [email protected] Abstract: In this review, we present an up-to-date phenomenological summary of research developments in the physics of the Quark–Gluon Plasma (QGP). A short historical perspective and theoretical motivation for this rapidly developing field of contemporary particle physics is provided. In addition, we introduce and discuss the role of the quantum chromodynamics (QCD) ground state, non-perturbative and lattice QCD results on the QGP properties, as well as the transport models used to make a connection between theory and experiment. The experimental part presents the selected results on bulk observables, hard and penetrating probes obtained in the ultra-relativistic heavy-ion experiments carried out at the Brookhaven National Laboratory Relativistic Heavy Ion Collider (BNL RHIC) and CERN Super Proton Synchrotron (SPS) and Large Hadron Collider (LHC) accelerators. We also give a brief overview of new developments related to the ongoing searches of the QCD critical point and to the collectivity in small (p + p and p + A) systems. Keywords: extreme states of matter; heavy ion collisions; QCD critical point; quark–gluon plasma; saturation phenomena; QCD vacuum PACS: 25.75.-q, 12.38.Mh, 25.75.Nq, 21.65.Qr 1. Introduction Quark–gluon plasma (QGP) is a new state of nuclear matter existing at extremely high temperatures and densities when composite states called hadrons (protons, neutrons, pions, etc.) lose their identity and dissolve into a soup of their constituents—quarks and gluons. -
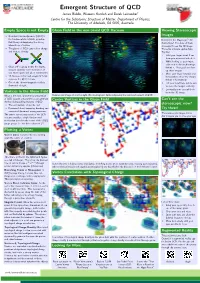
Emergent Structure Of
Emergent Structure of QCD James Biddle, Waseem Kamleh and Derek Leinwebery Centre for the Subatomic Structure of Matter, Department of Physics, The University of Adelaide, SA 5005, Australia Empty Space is not Empty Gluon Field in the non-trivial QCD Vacuum Viewing Stereoscopic Images Quantum Chromodynamics (QCD) is the fundamental relativistic quantum Remember the Magic Eye R 3D field theory underpinning the strong illustrations? You stare at them interactions of nature. cross-eyed to see the 3D image. The gluons of QCD carry colour charge The same principle applies here. and interact directly Try this! 1. Hold your finger about 5 cm from your nose and look at it. 2. While looking at your finger, take note of the double image Gluon self-coupling makes the empty behind it. Your goal is to line vacuum unstable to the formation of up those images. non-trivial quark and gluon condensates. 3. Move your finger forwards and 16 chromo-electric and -magnetic fields backwards to move the images compose the QCD vacuum. behind it horizontally. One of the chromo-magnetic fields is 4. Tilt your head from side to side illustrated at right. to move the images vertically. 5. Eventually your eyes will lock Vortices in the Gluon Field in on the 3D image. What is the most fundamental perspective Stereoscopic image of one the eight chromo-magnetic fields composing the nontrivial vacuum of QCD. of QCD vacuum structure that can generate Centre Vortices in the Gluon Field Can't see the the key distinguishing features of QCD stereoscopic view? The confinement of quarks, and Dynamical chiral symmetry breaking and Try these! associated dynamical-mass generation. -

Sum Rules and Vertex Corrections for Electron-Phonon Interactions
Sum rules and vertex corrections for electron-phonon interactions O. R¨osch,∗ G. Sangiovanni, and O. Gunnarsson Max-Planck-Institut f¨ur Festk¨orperforschung, Heisenbergstr. 1, D-70506 Stuttgart, Germany We derive sum rules for the phonon self-energy and the electron-phonon contribution to the electron self-energy of the Holstein-Hubbard model in the limit of large Coulomb interaction U. Their relevance for finite U is investigated using exact diagonalization and dynamical mean-field theory. Based on these sum rules, we study the importance of vertex corrections to the electron- phonon interaction in a diagrammatic approach. We show that they are crucial for a sum rule for the electron self-energy in the undoped system while a sum rule related to the phonon self-energy of doped systems is satisfied even if vertex corrections are neglected. We provide explicit results for the vertex function of a two-site model. PACS numbers: 63.20.Kr, 71.10.Fd, 74.72.-h I. INTRODUCTION the other hand, a sum rule for the phonon self-energy is fulfilled also without vertex corrections. This suggests that it can be important to include vertex corrections for Recently, there has been much interest in the pos- studying properties of cuprates and other strongly corre- sibility that electron-phonon interactions may play an lated materials. important role for properties of cuprates, e.g., for The Hubbard model with electron-phonon interaction 1–3 superconductivity. In particular, the interest has fo- is introduced in Sec. II. In Sec. III, sum rules for the cused on the idea that the Coulomb interaction U might electron and phonon self-energies are derived focusing on enhance effects of electron-phonon interactions, e.g., due the limit U and in Sec. -

The Electron Self-Energy in the Green's-Function Approach
ISSP Workshop/Symposium 2007 on FADFT The Electron Self-Energy in the Green’s-Function Approach: Beyond the GW Approximation Yasutami Takada Institute for Solid State Physics, University of Tokyo 5-1-5 Kashiwanoha, Kashiwa, Chiba 277-8581, Japan Seminar Room A615, Kashiwa, ISSP, University of Tokyo 14:00-15:00, 7 August 2007 ◎ Thanks to Professor Hiroshi Yasuhara for enlightening discussions for years Self-Energy beyond the GW Approximation (Takada) 1 Outline Preliminaries: Theoretical Background ○ One-particle Green’s function G and the self-energy Σ ○ Hedin’s theory: Self-consistent set of equations for G, Σ, W, Π, and Γ Part I. GWΓ Scheme ○ Introducing “the ratio function” ○ Averaging the irreducible electron-hole effective interaction ○ Exact functional form for Γ and an approximation scheme Part II. Illustrations ○ Localized limit: Single-site system with both electron-electron and electron-phonon interactions ○ Extended limit: Homogeneous electron gas Part III. Comparison with Experiment ○ ARPES and the problem of occupied bandwidth of the Na 3s band ○ High-energy electron escape depth Conclusion and Outlook for Future Self-Energy beyond the GW Approximation (Takada) 2 Preliminaries ● One-particle Green’s function G and the self-energy Σ ● Hedin’s theory: Self-consistent set of equations for G, Σ, W, Π, and Γ Self-Energy beyond the GW Approximation (Takada) 3 One-Electron Green’s Function Gσσ’(r,r’;t) Inject a bare electron with spin σ’ at site r’ at t=0; let it propage in the system until we observe the propability amplitude of a bare electron with spin σ at site r at t (>0) Æ Electron injection process Reverse process in time: Pull a bare electron with spin σ out at site r at t=0 first and then put a bare electron with spin σ’ back at site r’ at t.