Essays in Labour and Urban Economics by Nicolas Gendron-Carrier a Thesis Submitted in Conformity with the Requirements for the D
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Tehran Stock Exchange (TSE) Indices Base Year: 1369 1396 1397 Percentage Change
Table 1 Tehran Stock Exchange (TSE) Indices base year: 1369 1396 1397 Percentage change First seven First seven Mehr 1397 to Mehr 1397 to 1397 to 1396 Year-end Shahrivar Mehr months months Shahrivar 1397 1396 year-end (First seven months) Tehran Stock Exchange Price Index (TEPIX) 86,480 96,290 165,359 187,779 187,779 13.6 95.0 117.1 Financial index 128,475 119,176 160,538 185,201 185,201 15.4 55.4 44.2 Industrial index 75,559 86,082 146,264 171,782 171,782 17.4 99.6 127.3 Top 50 performers index 3,469 4,036 6,872 8,316 8,316 21.0 106.0 139.7 First market index 60,215 68,124 118,527 140,512 140,512 18.5 106.3 133.4 Second market index 190,581 206,487 318,496 363,537 363,537 14.1 76.1 90.8 Value of trading (billion rials) 277,312 539,075 167,533 294,769 801,562 75.9 − 189.0 First market 161,846 312,160 103,825 204,891 506,139 97.3 − 212.7 Second market 115,466 226,915 63,708 89,878 295,423 41.1 − 155.9 Number of shares traded (million shares) 120,088 250,607 63,025 90,502 294,041 43.6 − 144.9 First market 74,415 144,137 43,710 67,925 199,663 55.4 − 168.3 Second market 45,673 106,471 19,315 22,577 94,378 16.9 − 106.6 Number of listed companies 327 326 325 325 325 0.0 -0.3 -0.6 Market capitalization (trillion rials) 3,463 3,824 6,124 7,163 7,163 17.0 87.3 106.8 Number of trading days 140 241 20 22 140 10.0 − 0.0 Source: TSE, Market Management Monthly Report. -

Rail Profilesrail Ferrovia -Railway
Acoustic Isolation & Vibration Control Vibration & Isolation Acoustic Rail Profiles Ferrovia - Railway RAIL PROFILS Professionalità e consolidata esperienza fanno delle soluzioni Isolgomma PROTRACK una scelta affidabile ed altamente performante. I profili in Professionalism and consolidated experience gomma PROTRACK sono adatti a tutti i tipi di ro- make Isolgomma PROTRACK solutions a reliable taie e scambi in ambito ferrotranviario. and high-performance choice. PROTRACK rubber profiles are suitable for all types of rails and turnouts used for rail transport. 2 Embedded Il sistema embedded PROTRACK SET è una soluzione per armamento tramviario e metropolitano innovativo dove il profilo in gomma, che avvolge la rotaia, ha il fondamentale ruolo, non solo di elemento antivibrante ma anche di supporto strutturale per la realizzazione delle vie guidate. Attraverso la ricerca, la progettazione e la sperimentazione la società Isolgomma ha brevettato i profili Rail Profiles Rail embbeded PROTRACK SET dalla geometria esclusiva per garantire la migliore adesione al c.a. e la stabilità delle performance nel tempo. The PROTRACK SET embedded system is an innovative type of track suitable for tram and metro rail transport systems in which the rubber profile that encloses the rail performs a fundamental role, not just as a vibration damping device, but also as a structural support for the track. Through research, design and experimentation, Isolgomma has patented its PROTRACK SET embedded profiles with exclusive geometries that ensure optimum adhesion to reinforced concrete as well as stability and performance over time. Classic Il sistema con profili lateraliPROTRACK CLASSIC è una soluzione per armamento tramviario e metropolitano dove i profilI in gomma vengono installati sui fianchi della rotaia in modo tale da creare un elemento elastico di discontinuità tra la rotaia stessa e l’esterno. -
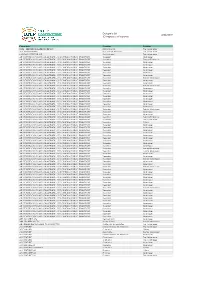
Delegate List (Congress Participants) 6/06/2019
Delegate List 6/06/2019 (Congress participants) Company Country Position 9292 - REISINFORMATIEGROEP B.V. Netherlands Top Manager A+S TRANSPROEKT Russian Federation Top Manager AARGAU VERKEHR AG Switzerland Top Manager AB STORSTOCKHOLMS LOKALTRAFIK - STOCKHOLM PUBLIC TRANSPORT Sweden Manager AB STORSTOCKHOLMS LOKALTRAFIK - STOCKHOLM PUBLIC TRANSPORT Sweden Expert/Engineer AB STORSTOCKHOLMS LOKALTRAFIK - STOCKHOLM PUBLIC TRANSPORT Sweden Manager AB STORSTOCKHOLMS LOKALTRAFIK - STOCKHOLM PUBLIC TRANSPORT Sweden Manager AB STORSTOCKHOLMS LOKALTRAFIK - STOCKHOLM PUBLIC TRANSPORT Sweden Manager AB STORSTOCKHOLMS LOKALTRAFIK - STOCKHOLM PUBLIC TRANSPORT Sweden Manager AB STORSTOCKHOLMS LOKALTRAFIK - STOCKHOLM PUBLIC TRANSPORT Sweden Manager AB STORSTOCKHOLMS LOKALTRAFIK - STOCKHOLM PUBLIC TRANSPORT Sweden Manager AB STORSTOCKHOLMS LOKALTRAFIK - STOCKHOLM PUBLIC TRANSPORT Sweden Senior Manager AB STORSTOCKHOLMS LOKALTRAFIK - STOCKHOLM PUBLIC TRANSPORT Sweden Manager AB STORSTOCKHOLMS LOKALTRAFIK - STOCKHOLM PUBLIC TRANSPORT Sweden Manager AB STORSTOCKHOLMS LOKALTRAFIK - STOCKHOLM PUBLIC TRANSPORT Sweden Senior Manager AB STORSTOCKHOLMS LOKALTRAFIK - STOCKHOLM PUBLIC TRANSPORT Sweden Manager AB STORSTOCKHOLMS LOKALTRAFIK - STOCKHOLM PUBLIC TRANSPORT Sweden Manager AB STORSTOCKHOLMS LOKALTRAFIK - STOCKHOLM PUBLIC TRANSPORT Sweden Manager AB STORSTOCKHOLMS LOKALTRAFIK - STOCKHOLM PUBLIC TRANSPORT Sweden Manager AB STORSTOCKHOLMS LOKALTRAFIK - STOCKHOLM PUBLIC TRANSPORT Sweden Manager AB STORSTOCKHOLMS LOKALTRAFIK - STOCKHOLM PUBLIC TRANSPORT Sweden -

The Evaluation of Constitutive Models in Prediction of Surface Settlements in Cohesive Soils – a Case Study: Mashhad Metro Line 2
The Evaluation of Constitutive Models in Prediction of Surface Settlements in Cohesive Soils – A Case Study: Mashhad Metro Line 2 Behnam Eslami, M. Sc. Of Geotechnics Engineering, Faculty of Civil and Environmental Eng., Tarbiat Modares University (Tehran, Iran), email: [email protected] Aliakbar Golshani, Associate Prof. Geotechnics Engineering, Faculty of Civil and Environmental Eng., Tarbiat Modares University (Tehran, Iran), email: [email protected] Sina Arefizadeh, M. Sc. Of Transportation Engineering, Faculty of Civil and Environmental Eng., Sharif University (Tehran, Iran), email: [email protected] ABSTRACT: The current study is aimed at investigating the basic soil behavior involved in a TBM-EPB excavation and the capability of the Modify Cam Clay (MCC) model is verified for the analysis of the soil settlement in cohesive soils. Tunnel excavation in urban areas can engender considerable ground movements, which is known as one of the complicated issues that may have negative effects on the extant structures. In this paper, the construction of the second line of the Mashhad metro is considered as a case study. Each section of the ground was modeled by two constitutive models, namely MCC and Mohr-Coulomb (MC). Afterwards, the results of numerical analyses and monitoring data were compared with each other. In addition, real parameters of soil, such as volume loss and the inflection point, were obtained via empirical approaches verified by tunnel monitoring. Numerical modeling was performed by FLAC3D software. Based on the transverse and longitudinal sections settlement, the MCC model showed high capabilities of predicting the surface settlement in comparison to the MC model. -

Subways and Urban Air Pollution∗
Subways and Urban Air Pollution∗ Nicolas Gendron-Carrier McGill University † Marco Gonzalez-Navarro UC-Berkeley ‡ Stefano Polloni Mapdwell § Matthew A. Turner Brown University ¶ 18 November 2020 Abstract: We investigate the effect of subway system openings on urban air pollution. On average, particulate concentrations are unchanged by subway openings. For cities with higher initial pollution levels, subway openings reduce particulates by 4% in the area surrounding a city center. The effect decays with distance to city center and persists over the longest time horizon that we can measure with our data, about four years. For highly polluted cities, we estimate that a new subway system provides an external mortality benefit of about $1b per year. For less polluted cities, the effect is indistinguishable from zero. Back of the envelope cost estimates suggest that reduced mortality due to lower air pollution offsets a substantial share of the construction costs of subways. Key words: subways, public transit, air pollution, aerosol optical depth, externalities. jel classification: l91, r4, r11, r14 ∗We are grateful to Christopher Balette, Jessica Burley, Alejandra Hernandez, Tasnia Hussain, Andy Liu, Fern Ramoutar, Mahdy Saddradini, Mohamed Salat, David Valdes, Farhan Yahya, and Guan Yi for research assistance. Assistance from Lynn Carlson and Yi Qi with the MODIS data and from Windsor Jarrod with computing is gratefully acknowledged, as are helpful conversations with Ken Chay and Michelle Marcus, and comments from Leah Brooks, Gabriel Kreindler, Remi Jedwab and many seminar participants. This paper is part of a Global Research Program on Spatial Development of Cities, funded by the Multi-Donor Trust Fund on Sustainable Urbanization by the World Bank and supported by the UK Department for International Development. -

Pub201706098000-20968-Iran-Markt
Die vorliegende Broschüre ist ein Beitrag von Germany Trade & Invest zum Netzwerk Architekture xport NAX der Bundesarchitektenkammer, das seit 2002 deutsche Architekten auf ihrem Weg zu neuen Märkten in der ganzen Welt begleitet . Das NAX bringt grenzüberschreitend tätige Architekten zusammen und vermittelt Kontakte zwischen in - und ausländischen Ko ll egen, Bauherren und Investoren. Es informiert regelmäßig über wirtschaftliche und politische Entwicklungen des internationalen Bausektors. Die auf der Webseite des NAX frei zugängliche L änderdatenbank liefert wichtige Informationen zum Bauen und Planen i n über 100 Ländern, u.a. zu Themen wie Verträge, Honorar und Haftung. Darüber h inaus wirbt das N etzwerk Architekturexport im Ausland für Planungsqualität aus Deutschland. Bei vielfältig en Veranstaltungen präsentiert es die Kompetenzen deutscher Architekten aller Fachrichtungen, Ingenieure und spezialisierter Planer vor Vertretern aus Politik und Wirtschaft. Weitere Informationen zum NAX erhalten Sie unter www.nax.bak.de . In Iran wird die erwartete kräftige Belebung d er Bau wirtschaft zu einem wieder deutlich steigenden Bedarf an Architektur dienst leistungen führen . Zudem ist ein Transfer von ausländischem Know - how erforderlich. In dieser Broschüre von Germany Trade & Invest mit Unterstützung der Bundesarchitektenkammer sind die aktuell wichtigsten Informationen zu Irans Markt für Architektur dienst leistungen zusammengestellt. Chancen und Möglichkeiten für deutsche Planungs - und Architekturbüros werden ebenso aufgezeigt wie die Risiken und Probleme. N eben einer Darstellung der rechtlichen Rahmenbedingungen beinhaltet die Publikation Praxistipps aus dem Erfahrungsschatz iranischer sowie deutscher Architekten, die bereits vor Ort tätig sind. Seit 2012 steckt Irans Baubranche in einer schweren Rezession. Die Bauinvestitionen lagen 2015 auf dem Niveau von 2005. Auch 2016 setzte sich die Talfahrt fort, vorläufigen Angaben zufolge schrumpften die Bauinvestitionen um weitere 11%. -

Subways and Urban Air Pollution
NBER WORKING PAPER SERIES SUBWAYS AND URBAN AIR POLLUTION Nicolas Gendron-Carrier Marco Gonzalez-Navarro Stefano Polloni Matthew A. Turner Working Paper 24183 http://www.nber.org/papers/w24183 NATIONAL BUREAU OF ECONOMIC RESEARCH 1050 Massachusetts Avenue Cambridge, MA 02138 January 2018 We are grateful to Tasnia Hussain, Fern Ramoutar, Mahdy Saddradini, Mohamed Salat, Farhan Yahya, and Guan Yi for assistance compiling the subway data. Assistance from Lynn Carlson and Yi Qi with the MODIS data and from Windsor Jarrod with computing is gratefully acknowledged, as are helpful conversations with Ken Chay and Michelle Marcus, and comments from Leah Brooks, Gabriel Kreindler, Remi Jedwab and many seminar participants. This paper is part of a Global Research Program on Spatial Development of Cities, funded by the Multi Donor Trust Fund on Sustainable Urbanization by the World Bank and supported by the UK Department for International Development. The project was made possible through financial support from SSHRC under grant #224995, the International Growth Center under grant #89337, the Connaught Fund, and the Ontario Work Study program. The views expressed herein are those of the authors and do not necessarily reflect the views of the National Bureau of Economic Research. NBER working papers are circulated for discussion and comment purposes. They have not been peer-reviewed or been subject to the review by the NBER Board of Directors that accompanies official NBER publications. © 2018 by Nicolas Gendron-Carrier, Marco Gonzalez-Navarro, Stefano Polloni, and Matthew A. Turner. All rights reserved. Short sections of text, not to exceed two paragraphs, may be quoted without explicit permission provided that full credit, including © notice, is given to the source. -

20091117-111707-6015
METROPOLIS2005 Commission 4 Urban Mobility Management Safeguarding Mobility - Transforming Transportation Commission 4 Urban Mobility Management Safeguarding Mobility - Transforming Transportation Commission’s Report: Presidency Berlin: Ingebord Junge-Reyer Senator, Department for Urban Development Vicepresidency Paris Île-de-France: Jean-Paul Huchon President of the Regional Council of Île-de-France Cities: Abidjan, Barcelona, Belo Horizonte, Berlin, Brazzaville, Brussels, Gwangju, Istanbul, Lisbon, London, Mashhad, Mexico City, Montreal, Moscow, Omsk, Paris, Rio de Janeiro, Santiago de Chile, Sofia,Tehran Berlin Working Group in the Senate Department for Urban Development: Cornelia Poczka Dr. Friedemann Kunst Bernd Milde Peter Kühnel Autors: Dipl. Ing. Hans-Joachim Becker Dipl. Ing. Diana Runge Technical University Berlin, Department for Integrated Transport Planning (España) ipl. Ing. Diana Runge Metropolis Secretariat General Ajuntament de Barcelona Avinyó, 15 08002 Barcelona (Spain) [email protected] www.metropolis.org Edición: marzo 2005 Diseño gráfico: Dario Grossi Impresión:Treballs Gràfics, SA Santander, 74 08020 Barcelona ISBN: 84-7609-447-4 Copyright Deposit: 00000-2005 2 CONTENTS Chairwoman’s Foreword ........................................................................................................................................5 Executive Summary...............................................................................................................................................7 1. Trends and Issues in -

Delegate List 21/05/2019 Company Country Position A+S
Delegate List 21/05/2019 Company Country Position A+S TRANSPROEKT Russian Federation Top Manager AARGAU VERKEHR AG Switzerland Top Manager AB STORSTOCKHOLMS LOKALTRAFIK - STOCKHOLM PUBLIC TRANSPORT Sweden Manager AB STORSTOCKHOLMS LOKALTRAFIK - STOCKHOLM PUBLIC TRANSPORT Sweden Manager AB STORSTOCKHOLMS LOKALTRAFIK - STOCKHOLM PUBLIC TRANSPORT Sweden Expert/Engineer ABB SCHWEIZ AG Switzerland Manager ABB SECHERON LTD Switzerland Senior Manager ABU DHABI DEPARTMENT OF TRANSPORT United Arab Emirates Top Manager ACCENTURE United States of Top Manager America ACCENTURE Canada Other ACCENTURE Germany Senior Manager ACCENTURE United States of Manager America ACCENTURE Germany Top Manager ACCENTURE Canada Top Manager ACCENTURE Canada Manager ACCENTURE MONTREAL Canada Other ACCENTURE SAS France Other ACCENTURE SAS France Manager ACTIA AUTOMOTIVE France Senior Manager ACTIA AUTOMOTIVE France Manager ADDAX ASSESSORIA ECONOMICA E FINANCEIRA LTDA Brazil Senior Manager ADN CONTEXT - AWARE MOBILE SOLUTIONS S.L. Spain Other AESYS - RWH INTL. LTD Germany Top Manager AGENCE POUR LA DIFFUSION DE L INFORMATION TECHNOLOGIQUE France Senior Manager AGENCIA NACIONAL DE TRANSPORTES TERRESTRES Brazil Top Manager AGENCIA NACIONAL DE TRANSPORTES TERRESTRES Brazil Manager AGENCIA NACIONAL DE TRANSPORTES TERRESTRES Brazil Manager AGIR France Top Manager AIT AUSTRIAN INSTITUTE OF TECHNOLOGY GMBH Austria Top Manager AKERSHUS FYLKESKOMMUNE - AKERSHUS COUNTY COUNCIL Norway Senior Manager AKERSHUS FYLKESKOMMUNE - AKERSHUS COUNTY COUNCIL Norway Manager AKERSHUS FYLKESKOMMUNE -

Hyundai Elevator
HYUNDAI ELEVATOR QUARTERLY NEWSLETTER Vol. 06 / JULY 2016 COVER STORY Winning the contract for SEASIDE CITY CEBU in the Philippines HOT ISSUE 1 Hyundai Elevator Participates in the WEE in Shanghai HOT ISSUE 2 H-1 Kick Off to Announce its Vision for Globalization COVER 01 | 02 STORY Opening up the global market through trust Winning the contract for SEASIDE CITY CEBU in the Philippines With continued economic growth, the Philippines is gaining attention as a new destination for investments. Since opening a The Philippines, a ‘VIP’ in the global economy coming to Cebu but also the locals branch office in the Philippines in 1989, Hyundai Elevator has earned the trust of the Filipino market with outstanding products Renowned as a world class holiday destination with beautiful beaches and in Cebu will be able to meet Hyundai blessed natural environment, the Philippines along with Vietnam and Indonesia Elevator’s products at the brand new and technology. As a testament to the company’s continued efforts, we would like to introduce you to the story of how Hyundai has been attracting the attention of the world as a emerging market. Dubbed landmark. Elevator won the contract for ‘SEASIDE CITY CEBU’, the 8th largest shopping mall in the world, in this Cover Story. ‘VIP’ using the first letters of each country, these three countries are seen as the next opportunity for smart investment options after the five countries known as Expanding across the Filipino market BRICs thanks to their rapid economic growth. Despite slow economic all over the using solid partnership world the Philippines has sustained its growth over the past few years. -

Use Style: Paper Title
Int'l Journal of Computing, Communications & Instrumentation Engg. (IJCCIE) Vol. 2, Issue 1 (2015) ISSN 2349-1469 EISSN 2349-1477 Evaluating Mashhad Urban Railway and Presenting Solutions Based on Information Technology (IT) Elham Fariborzi1, and Golnaz Tavassolian2 railway [3]. These advantages made big cities like New York, Abstract— Population growth and the increasing of journeys in London, and Paris to think of using this technology [4]. Paris cities make urban railway as essential public transportation especially urban railway has a station every 500 meters and London in big cities. In Mashhad (The second biggest city of Iran), Urban totally has 275 stations. New York has 450 stations in 621 sq. railway as a newly built transportation, faced some problems and /m2 [5].In some cities like London, tunnels are more than 150 need to improve its services. The objective of this paper was to years old. First underground city tunnel was made in 1863 in evaluate urban railway system of Mashhad from the viewpoint of London. First Paris urban railway line was opened in 1900 and users, and to provide some solutions based on Information Technology for Urban railway’s authorities. Research method was 1904 was for New York. Urban railway and underground descriptive cross-sectional study. Data in this research collected from tunnels have been made with London’s innovation in a way interviews with users of urban railway through open-ended questions that today there are more than 160 urban railway and and environment’s observations. The sampling was underground systems in the world [6]. First urban railway accidental/convenience sampling (A type of no probability sampling). -

Nber Working Paper Series Subways and Urban Air
NBER WORKING PAPER SERIES SUBWAYS AND URBAN AIR POLLUTION Nicolas Gendron-Carrier Marco Gonzalez-Navarro Stefano Polloni Matthew A. Turner Working Paper 24183 http://www.nber.org/papers/w24183 NATIONAL BUREAU OF ECONOMIC RESEARCH 1050 Massachusetts Avenue Cambridge, MA 02138 January 2018, Revised November 2020 We are grateful to Christopher Balette, Jessica Burley, Alejandra Hernandez, Tasnia Hussain, Andy Liu, Fern Ramoutar, Mahdy Saddradini, Mohamed Salat, David Valdes, Farhan Yahya, and Guan Yi for research assistance. Assistance from Lynn Carlson and Yi Qi with the MODIS data and from Windsor Jarrod with computing is gratefully acknowledged, as are helpful conversations with Ken Chay and Michelle Marcus, and comments from Leah Brooks, Gabriel Kreindler, Remi Jedwab and many seminar participants. This paper is part of a Global Research Program on Spatial Development of Cities, funded by the Multi-Donor Trust Fund on Sustainable Urbanization by the World Bank and supported by the UK Department for International Development. The project was made possible through financial support from SSHRC under grant #224995, the International Growth Center under grant #89337, the Connaught Fund, and the Ontario Work-Study program. The views expressed herein are those of the authors and do not necessarily reflect the views of the National Bureau of Economic Research. NBER working papers are circulated for discussion and comment purposes. They have not been peer-reviewed or been subject to the review by the NBER Board of Directors that accompanies official NBER publications. © 2018 by Nicolas Gendron-Carrier, Marco Gonzalez-Navarro, Stefano Polloni, and Matthew A. Turner. All rights reserved. Short sections of text, not to exceed two paragraphs, may be quoted without explicit permission provided that full credit, including © notice, is given to the source.