Learning Semantic Relations with Distributional Similarity
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Cohesion and Coherence in Indonesian Textbooks for the Tenth Grader of Senior High School
Advances in Social Science, Education and Humanities Research, volume 301 Seventh International Conference on Languages and Arts (ICLA 2018) COHESION AND COHERENCE IN INDONESIAN TEXTBOOKS FOR THE TENTH GRADER OF SENIOR HIGH SCHOOL Syamsudduha1, Johar Amir2, and Wahida3 1Universitas Negeri Makasar, Makassar, Indonesia, [email protected] 2Universitas Negeri Makasar, Makassar, Indonesia, [email protected] 3 Universitas Negeri Makasar, Makassar, Indonesia, [email protected] Abstract This study aims to describe: (1) cohesion and (2) coherence in Indonesian Textbooks for XI Grade Senior High School. This type of research is qualitative analysis research. The data are the statements or disclosures that contain cohesion and coherence in the Indonesian textbooks. The sources of data are the texts in The Indonesian Textbooks for XI Grade Senior High Schoolpublished by the Ministry of Education and Culture of Republic of Indonesia. The data collection techniques are carried out with documenting, reading,and noting. Data analysis techniques are carried out through reduction, presentation, and inference/verification of data. The results of this study showed that (1) the use of two cohesion markers, grammatical cohesionand lexical cohesion. The markers of grammatical cohesion were reference, substitution, ellipsis, and conjunction. The markers of lexical cohesion were repetition, synonym,antonym, hyponym, and collocation. The later result was (2) the use of coherence markers which are addition, sequencing, resistance, more, cause-consequences, time, terms, ways, uses, and explanations. Those findings showed that the textsof Indonesian Textbooks for XI Grade Senior High School published by the Ministry of Education and Culture of Republic of Indonesia were texts that had cohesion and unity of meaning so that Indonesian Textbooks for XI Grade Senior High Schoolpublished by the Ministry of Education and Cultureof The Republic of Indonesia was declared good to be used as a teaching material. -

Exploring the Relationship Between Word-Association and Learners’ Lexical Development
Exploring the Relationship between Word-Association and Learners’ Lexical Development Jason Peppard An assignment for Master of Arts in Applied Linguistics Module 2 - Lexis July 2007 Centre for English Language Studies Department of English UNIVERSITY OF BIRMINGHAM Birmingham B15 2TT United Kingdom LX/06/02 Follow task 123 outlined on page 152 of McCarthy (1990 Vocabulary OUP). You do not have to use students: anyone who has an L2 but has not been brought up as a bilingual will do. Use at least four subjects and test them on their L2 (or L3/ L4 etc.). Report your findings, giving the level(s) of subjects' L2 (L3, etc.) and including the prompt words and responses. Follow McCarthy's list of evaluation points, adding other points to this if you wish. Approx. 4530 words 1.0 Introduction Learning or acquiring your first language was a piece of cake, right? So why then, is it so difficult for some people to learn a second language? For starters, many learners might be wondering why I referred to a dessert in the opening sentence of a paper concerning vocabulary. The point here is summed up neatly by McCarthy (1990): No matter how well the student learns grammar, no matter how successfully the sounds of L2 are mastered, without words to express a wide range of meanings, communication in an L2 just cannot happen in any meaningful way (p. viii). This paper, based on Task 123 of McCarthy’s Vocabulary (ibid: 152), aims to explore the L2 mental lexicon. A simple word association test consisting of eight stimulus words was administered to both low-level and high-level Japanese EFL students as well as a group of native English speakers for comparative reasons. -

Translating Lexical Semantic Relations: the First Step Towards Multilingual Wordnets*
Translating Lexical Semantic Relations: The First Step Towards Multilingual Wordnets* Chu-Ren Huang, I-Ju E. Tseng, Dylan B.S. Tsai Institute of Linguistics, Preparatory Office, Academia Sinica 128 Sec.2 Academy Rd., Nangkang, Taipei, 115, Taiwan, R.O.C. [email protected], {elanna, dylan}@hp.iis.sinica.edu.tw Abstract Wordnets express ontology via a network of Establishing correspondences between words linked by lexical semantic relations. Since wordnets of different languages is essential these words are by definition the lexicon of each to both multilingual knowledge processing language, the wordnet design feature ensures and for bootstrapping wordnets of versatility in faithfully and comprehensively low-density languages. We claim that such representing the semantic content of each correspondences must be based on lexical semantic relations, rather than top ontology language. Hence, on one hand, these conceptual or word translations. In particular, we define atoms reflect linguistic idiosyncrasies; on the a translation equivalence relation as a other hand, the lexical semantic relations (LSR’s) bilingual lexical semantic relation. Such receive universal interpretation across different relations can then be part of a logical languages. For example, the definition of entailment predicting whether source relations such as synonymy or hypernymy is language semantic relations will hold in a universal. The universality of the LSR’s is the target language or not. Our claim is tested foundation that allows wordnet to serve as a with a study of 210 Chinese lexical lemmas potential common semantic network and their possible semantic relations links representation for all languages. The premise is bootstrapped from the Princeton WordNet. -

Machine Reading = Text Understanding! David Israel! What Is It to Understand a Text? !
Machine Reading = Text Understanding! David Israel! What is it to Understand a Text? ! • To understand a text — starting with a single sentence — is to:! • determine its truth (perhaps along with the evidence for its truth)! ! • determine its truth-conditions (roughly: what must the world be like for it to be true)! • So one doesn’t have to check how the world actually is — that is whether the sentence is true! • calculate its entailments! • take — or at least determine — appropriate action in light of it (and some given preferences/goals/desires)! • translate it accurately into another language! • and what does accuracy come to?! • ground it in a cognitively plausible conceptual space! • …….! • These are not necessarily competing alternatives! ! For Contrast: What is it to Engage Intelligently in a Dialogue? ! • Respond appropriately to what your dialogue partner has just said (and done)! • Typically, taking into account the overall purpose(s) of the interaction and the current state of that interaction (the dialogue state)! • Compare and contrast dialogue between “equals” and between a human and a computer, trying to assist the human ! • Siri is a very simple example of the latter! A Little Ancient History of Dialogue Systems! STUDENT (Bobrow 1964) Question-Answering: Word problems in simple algebra! “If the number of customers Tom gets is twice the square of 20% of the number of advertisements he runs, and the number of advertisements he runs is 45, what is the number of customers Tom gets?” ! Overview of the method ! . 1 Map referential expressions to variables. ! ! . 2 Use regular expression templates to identify and transform mathematical expressions. -

Hindi Wordnet
Description Hindi WordNet The Hindi WordNet is a system for bringing together different lexical and semantic relations between the Hindi words. It organizes the lexical information in terms of word meanings and can be termed as a lexicon based on psycholinguistic principles. The design of the Hindi WordNet is inspired by the famous English WordNet. In the Hindi WordNet the words are grouped together according to their similarity of meanings. Two words that can be interchanged in a context are synonymous in that context. For each word there is a synonym set, or synset, in the Hindi WordNet, representing one lexical concept. This is done to remove ambiguity in cases where a single word has multiple meanings. Synsets are the basic building blocks of WordNet. The Hindi WordNet deals with the content words, or open class category of words. Thus, the Hindi WordNet contains the following category of words- Noun, Verb, Adjective and Adverb. Each entry in the Hindi WordNet consists of following elements 1. Synset: It is a set of synonymous words. For example, “वि饍यालय, पाठशाला, कू ल” (vidyaalay, paaThshaalaa, skuul) represents the concept of school as an educational institution. The words in the synset are arranged according to the frequency of usage. 2. Gloss: It describes the concept. It consists of two parts: Text definition: It explains the concept denoted by the synset. For example, “िह थान जहााँ प्राथमिक या िाध्यमिक तर की औपचाररक मशक्षा दी जाती है” (vah sthaan jahaan praathamik yaa maadhyamik star kii aupachaarik sikshaa dii jaatii hai) explains the concept of school as an educational institution. -

12 Morphology and Lexical Semantics
248 Beth Levin and Malka Rappaport Hovav 12 Morphology and Lexical Semantics BETH LEVIN AND MALKA RAPPAPORT HOVAV The relation between lexical semantics and morphology has not been the subject of much study. This may seem surprising, since a morpheme is often viewed as a minimal Saussurean sign relating form and meaning: it is a concept with a phonologically composed name. On this view, morphology has both a semantic side and a structural side, the latter sometimes called “morphological realization” (Aronoff 1994, Zwicky 1986b). Since morphology is the study of the structure and derivation of complex signs, attention could be focused on the semantic side (the composition of complex concepts) and the structural side (the composition of the complex names for the concepts) and the relation between them. In fact, recent work in morphology has been concerned almost exclusively with the composition of complex names for concepts – that is, with the struc- tural side of morphology. This dissociation of “form” from “meaning” was foreshadowed by Aronoff’s (1976) demonstration that morphemes are not necessarily associated with a constant meaning – or any meaning at all – and that their nature is basically structural. Although in early generative treat- ments of word formation, semantic operations accompanied formal morpho- logical operations (as in Aronoff’s Word Formation Rules), many subsequent generative theories of morphology, following Lieber (1980), explicitly dissoci- ate the lexical semantic operations of composition from the formal structural -

Introduction to Lexical Resources Oduc O O E Ca Esou
Introductio n to le xica l resou r ces BlttSBolette San dfdPddford Pedersen Centre for Language Technology University of Copenhagen [email protected] Outline 1 . Why are lexical semantic resources relevant for semantic annotation? . What is the relation between traditional lexicography and lexica l resou rces fo r a nno ta tio n pu rpo ses? Bolette S. Pedersen, CLARA Course 2011 Outline 2 . WordNet, primary focus on vertical , taxonomical relations . VbNtVerbNet, prifimary focus on hitlhorizontal, synttitagmatic relations, thematic roles . PropBank, primary focus on horizontal, syntagmatic relations, argument structure . FrameNet, primary focus on horizontal, syntagmatic relations, thematic roles (()= frame elements) . PAROLE/SIMPLE - Semantic Information for Multifunctional, PluriLingual Lexicons - based on the Generative Lexicon (Pustejovsky 1995) Bolette S. Pedersen, CLARA Course 2011 Outline 2 . WordNet, primary focus on vertical , taxonomical relations . VbNtVerbNet, prifimary focus on hitlhorizontal, synttitagmatic relations, thematic roles . PropBank, primary focus on horizontal, syntagmatic relations, argument structure . FrameNet, primary focus on horizontal, syntagmatic relations, thematic roles . PAROLE/SIMPLE - Semantic Information for Multifunctional, PluriLingual Lexicons - based on the Generative Lexicon (Pustejovsky 1995) Bolette S. Pedersen, CLARA Course 2011 Outline 2 . WordNet, primary focus on vertical , taxonomical relations . VbNtVerbNet, prifimary focus on hitlhorizontal, synttitagmatic relations, thematic roles -

Studies in the Linguistic Sciences
UNIVERSITY OF ILLINOIS Llb'RARY AT URBANA-CHAMPAIGN MODERN LANGUAGE NOTICE: Return or renew all Library Materialsl The Minimum Fee (or each Lost Book is $50.00. The person charging this material is responsible for its return to the library from which it was withdrawn on or before the Latest Date stamped below. Theft, mutilation, and underlining of books are reasons for discipli- nary action and may result in dismissal from the University. To renew call Telephone Center, 333-8400 UNIVERSITY OF ILLINOIS LIBRARY AT URBANA-CHAMPAIGN ModeriJLanp & Lb Library ^rn 425 333-0076 L161—O-I096 Che Linguistic Sciences PAPERS IN GENERAL LINGUISTICS ANTHONY BRITTI Quantifier Repositioning SUSAN MEREDITH BURT Remarks on German Nominalization CHIN-CHUAN CHENG AND CHARLES KISSEBERTH Ikorovere Makua Tonology (Part 1) PETER COLE AND GABRIELLA HERMON Subject to Object Raising in an Est Framework: Evidence from Quechua RICHARD CURETON The Inclusion Constraint: Description and Explanation ALICE DAVISON Some Mysteries of Subordination CHARLES A. FERGUSON AND APIA DIL The Sociolinguistic Valiable (s) in Bengali: A Sound Change in Progress GABRIELLA HERMON Rule Ordering Versus Globality: Evidencefrom the Inversion Construction CHIN-W. KIM Neutralization in Korean Revisited DAVID ODDEN Principles of Stress Assignment: A Crosslinguistic View PAULA CHEN ROHRBACH The Acquisition of Chinese by Adult English Speakers: An Error Analysis MAURICE K.S. WONG Origin of the High Rising Changed Tone in Cantonese SORANEE WONGBIASAJ On the Passive in Thai Department of Linguistics University of Illinois^-^ STUDIES IN THE LINGUISTIC SCIENCES PUBLICATION OF THE DEPARTMENT OF LINGUISTICS UNIVERSITY OF ILLINOIS AT URBANA-CHAMPAIGN EDITORS: Charles W. Kisseberth, Braj B. -

Morphemes by Kirsten Mills Student, University of North Carolina at Pembroke, 1998
Morphemes by Kirsten Mills http://www.uncp.edu/home/canada/work/caneng/morpheme.htm Student, University of North Carolina at Pembroke, 1998 Introduction Morphemes are what make up words. Often, morphemes are thought of as words but that is not always true. Some single morphemes are words while other words have two or more morphemes within them. Morphemes are also thought of as syllables but this is incorrect. Many words have two or more syllables but only one morpheme. Banana, apple, papaya, and nanny are just a few examples. On the other hand, many words have two morphemes and only one syllable; examples include cats, runs, and barked. Definitions morpheme: a combination of sounds that have a meaning. A morpheme does not necessarily have to be a word. Example: the word cats has two morphemes. Cat is a morpheme, and s is a morpheme. Every morpheme is either a base or an affix. An affix can be either a prefix or a suffix. Cat is the base morpheme, and s is a suffix. affix: a morpheme that comes at the beginning (prefix) or the ending (suffix) of a base morpheme. Note: An affix usually is a morpheme that cannot stand alone. Examples: -ful, -ly, -ity, -ness. A few exceptions are able, like, and less. base: a morpheme that gives a word its meaning. The base morpheme cat gives the word cats its meaning: a particular type of animal. prefix: an affix that comes before a base morpheme. The in in the word inspect is a prefix. suffix: an affix that comes after a base morpheme. -

From Phoneme to Morpheme Author(S): Zellig S
Linguistic Society of America From Phoneme to Morpheme Author(s): Zellig S. Harris Source: Language, Vol. 31, No. 2 (Apr. - Jun., 1955), pp. 190-222 Published by: Linguistic Society of America Stable URL: http://www.jstor.org/stable/411036 Accessed: 09/02/2009 08:03 Your use of the JSTOR archive indicates your acceptance of JSTOR's Terms and Conditions of Use, available at http://www.jstor.org/page/info/about/policies/terms.jsp. JSTOR's Terms and Conditions of Use provides, in part, that unless you have obtained prior permission, you may not download an entire issue of a journal or multiple copies of articles, and you may use content in the JSTOR archive only for your personal, non-commercial use. Please contact the publisher regarding any further use of this work. Publisher contact information may be obtained at http://www.jstor.org/action/showPublisher?publisherCode=lsa. Each copy of any part of a JSTOR transmission must contain the same copyright notice that appears on the screen or printed page of such transmission. JSTOR is a not-for-profit organization founded in 1995 to build trusted digital archives for scholarship. We work with the scholarly community to preserve their work and the materials they rely upon, and to build a common research platform that promotes the discovery and use of these resources. For more information about JSTOR, please contact [email protected]. Linguistic Society of America is collaborating with JSTOR to digitize, preserve and extend access to Language. http://www.jstor.org FROM PHONEME TO MORPHEME ZELLIG S. HARRIS University of Pennsylvania 0.1. -
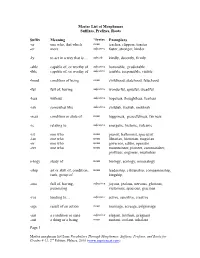
Morpheme Master List
Master List of Morphemes Suffixes, Prefixes, Roots Suffix Meaning *Syntax Exemplars -er one who, that which noun teacher, clippers, toaster -er more adjective faster, stronger, kinder -ly to act in a way that is… adverb kindly, decently, firmly -able capable of, or worthy of adjective honorable, predictable -ible capable of, or worthy of adjective terrible, responsible, visible -hood condition of being noun childhood, statehood, falsehood -ful full of, having adjective wonderful, spiteful, dreadful -less without adjective hopeless, thoughtless, fearless -ish somewhat like adjective childish, foolish, snobbish -ness condition or state of noun happiness, peacefulness, fairness -ic relating to adjective energetic, historic, volcanic -ist one who noun pianist, balloonist, specialist -ian one who noun librarian, historian, magician -or one who noun governor, editor, operator -eer one who noun mountaineer, pioneer, commandeer, profiteer, engineer, musketeer o-logy study of noun biology, ecology, mineralogy -ship art or skill of, condition, noun leadership, citizenship, companionship, rank, group of kingship -ous full of, having, adjective joyous, jealous, nervous, glorious, possessing victorious, spacious, gracious -ive tending to… adjective active, sensitive, creative -age result of an action noun marriage, acreage, pilgrimage -ant a condition or state adjective elegant, brilliant, pregnant -ant a thing or a being noun mutant, coolant, inhalant Page 1 Master morpheme list from Vocabulary Through Morphemes: Suffixes, Prefixes, and Roots for -

Verbs of 'Preparing Something for Eating by Heating It in a Particular
DEPARTAMENTO DE FILOLOGÍA INGLESA Y ALEMANA Verbs of ‘preparing something for eating by heating it in a particular way’: a lexicological analysis Grado en Estudios Ingleses Fabián García Díaz Tutora: Mª del Carmen Fumero Pérez San Cristóbal de La Laguna, Tenerife 8 de septiembre de 2015 INDEX 1. Abstract ................................................................................................................................. 3 2. Introduction .......................................................................................................................... 4 3. Theoretical perspective ........................................................................................................ 6 4. Analysis: verbs of to prepare something for eating by heating it in a particular way: cook, fry and roast. ................................................................................................................... 9 4.1. Corpus selection .............................................................................................................. 9 4.2. Verb selection ................................................................................................................ 11 5. Paradigmatic relations ....................................................................................................... 13 5.1. Semantic components and lexematic analysis ............................................................... 13 5.2. Lexical relations ...........................................................................................................