Design and Development of an App for Statistical Data Analysis Learning
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

ICT in the Kosovo National Statistical System - Baseline Review and Recommendations for Development
UNDP Kosovo UNKT Technical assistance to the IT department of the Kosovo Agency of Statistics (KAS) Technical analysis of information technology in the national statistical system ICT in the Kosovo National Statistical System - Baseline review and Recommendations for development April 2013 by Arij Dekker, Consultant in statistical data processing and management [email protected] ICT in the Kosovo National Statistical System - Baseline review and Recommendations for development 1 Contents List of Acronyms ...................................................................................................................................... 3 Executive Summary ................................................................................................................................. 5 Chapter 1. Introduction ..................................................................................................................... 7 Chapter 2. Methods of information gathering .................................................................................... 9 2.1 Description of interview partners and question clusters ........................................................... 9 2.2 Other information sources ..................................................................................................... 12 Chapter 3. The present state of ICT in the Kosovo national statistical system ................................... 14 3.1 Summary of information gathered from the interviews ......................................................... -

On New Data Sources for the Production of Official Statistics
On new data sources for the production of official statistics David Salgado1,2 and Bogdan Oancea3 1Dept. Methodology and Development of Statistical Production, Statistics Spain (INE), Spain 2Dept. Statistics and Operations Research, Complutense University of Madrid, Spain 3Dept. Business Administration, University of Bucharest, Romania February 7, 2020 Abstract In the past years we have witnessed the rise of new data sources for the potential production of official statistics, which, by and large, can be classified as survey, administrative, and digital data. Apart from the differences in their generation and collection, we claim that their lack of statistical metadata, their economic value, and their lack of ownership by data holders pose several entangled challenges lurking the incorporation of new data into the routinely production of official statistics. We argue that every challenge must be duly overcome in the international community to bring new statistical products based on these sources. These challenges can be naturally classified into different entangled issues regarding access to data, statistical methodology, quality, information technologies, and management. We identify the most relevant to be necessarily tackled before new data sources can be definitively considered fully incorporated into the production of official statistics. Contents 1 Introduction 2 2 Data: survey, administrative, digital 3 2.1 Somedefinitions ..................................... .... 3 2.2 Statisticalmetadata ................................ ....... 4 2.3 Economicvalue..................................... -

Software Developer
PINKY MONONYANE SOFTWARE DEVELOPER https://www.pinkymononyane.info PROFILE English, Sotho, Tsonga, Tswana, Venda, N. Sotho 33 Years old, Black Female with no disability I have 9 years’ programming experience with professional skills that could fill a South African Citizen, ID Number: 871020 0461 08 1 bucket 10 times over, with few honorable mentions such as HTML, B – Light Vehicles 750kg to 3500kg CSS3, Python (I have more than 5 years Single of Experience in Django framework. I have been developing small to medium projects even before my latest position ADDRESS & CONTACT INFO at BCM), Php and Java Script with keen attention to details, Phone Number: +27 78 968 2362 plus a well dynamic personality that appeals to most that I have had a Home Address Recent / Previous pleasure working/collaborating with. Work Address 684 Lievaart Point to note... Challenges is what I live, Street 145 Second Street breath and seek, for it's in those that's Proclamation Hill Parkmore where personal growth is found. Pretoria, Gauteng Sandton 0183 2052 Furthermore I constantly look for more knowledge related to my field; as such I Email Address: [email protected] have enrolled in Computer Science BSc Degree at UNISA, as they say knowledge CAREER STATUS is like an endless river flow. Can't have 2013-2019 Data Developer: 7 Years’ Experience enough: P. Languages:- So when I'm nowhere to be found rest Python, CSpro, SSRS, SQL Server, R-Statistics, SAS, Server assured you can find me programming a interaction, security and management under various software on my friendly computer or out environments (Linux, Windows and Windows server) on a hunt for further knowledge and if not I’m probably out travelling and 2020-2020 Software Developer: 9 Months Formal Experience spending time with my loved ones. -
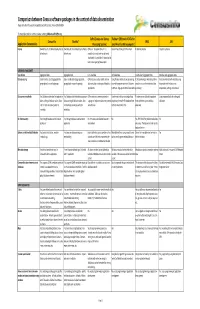
Comparison Between Census Software Packages in the Context of Data Dissemination Prepared by Devinfo Support Group (DSG) and UN Statistics Division (DESA/UNSD)
Comparison between Census software packages in the context of data dissemination Prepared by DevInfo Support Group (DSG) and UN Statistics Division (DESA/UNSD) For more information or comments please contact: [email protected] CsPro (Census and Survey Redatam (REtrieval of DATa for CensusInfo DevInfo* SPSS SAS Application Characteristics Processing System) small Areas by Microcomputer) License Owned by UN, distributed royalty-free to Owned by UN, distributed royalty-free to CSPro is in the public domain. It is Version free of charge for Download Properitery license Properitery license all end-users all end-users available at no cost and may be freely distributed. It is available for download at www.census.gov/ipc/www/cspro DATABASE MANAGEMENT Type of data Aggregated data. Aggregated data. Individual data. Individual data. Individual and aggregated data. Individual and aggregated data. Data processing Easily handles data disaggregated by Easily handles data disaggregated by CSPro lets you create, modify, and run Using Process module allows processing It allows entering primary data, define It lets you interact with your data using geographical area and subgroups. geographical area and subgroups. data entry, batch editing, and tabulation data with programs written in Redatam variables and perform statistical data integrated tools for data entry, applications command language or limited Assisstants processing computation, editing, and retrieval. Data consistency checks Yes, Database administration application Yes, Database administration -

JASP: Graphical Statistical Software for Common Statistical Designs
JSS Journal of Statistical Software January 2019, Volume 88, Issue 2. doi: 10.18637/jss.v088.i02 JASP: Graphical Statistical Software for Common Statistical Designs Jonathon Love Ravi Selker Maarten Marsman University of Newcastle University of Amsterdam University of Amsterdam Tahira Jamil Damian Dropmann Josine Verhagen University of Amsterdam University of Amsterdam University of Amsterdam Alexander Ly Quentin F. Gronau Martin Šmíra University of Amsterdam University of Amsterdam Masaryk University Sacha Epskamp Dora Matzke Anneliese Wild University of Amsterdam University of Amsterdam University of Amsterdam Patrick Knight Jeffrey N. Rouder Richard D. Morey University of Amsterdam University of California, Irvine Cardiff University University of Missouri Eric-Jan Wagenmakers University of Amsterdam Abstract This paper introduces JASP, a free graphical software package for basic statistical pro- cedures such as t tests, ANOVAs, linear regression models, and analyses of contingency tables. JASP is open-source and differentiates itself from existing open-source solutions in two ways. First, JASP provides several innovations in user interface design; specifically, results are provided immediately as the user makes changes to options, output is attrac- tive, minimalist, and designed around the principle of progressive disclosure, and analyses can be peer reviewed without requiring a “syntax”. Second, JASP provides some of the recent developments in Bayesian hypothesis testing and Bayesian parameter estimation. The ease with which these relatively complex Bayesian techniques are available in JASP encourages their broader adoption and furthers a more inclusive statistical reporting prac- tice. The JASP analyses are implemented in R and a series of R packages. Keywords: JASP, statistical software, Bayesian inference, graphical user interface, basic statis- tics. -

Security Systems Services World Report
Security Systems Services World Report established in 1974, and a brand since 1981. www.datagroup.org Security Systems Services World Report Database Ref: 56162 This database is updated monthly. Security Systems Services World Report SECURITY SYSTEMS SERVICES WORLD REPORT The Security systems services Report has the following information. The base report has 59 chapters, plus the Excel spreadsheets & Access databases specified. This research provides World Data on Security systems services. The report is available in several Editions and Parts and the contents and cost of each part is shown below. The Client can choose the Edition required; and subsequently any Parts that are required from the After-Sales Service. Contents Description ....................................................................................................................................... 5 REPORT EDITIONS ........................................................................................................................... 6 World Report ....................................................................................................................................... 6 Regional Report ................................................................................................................................... 6 Country Report .................................................................................................................................... 6 Town & Country Report ...................................................................................................................... -

Community Notebook
Community Notebook Free Software Projects Projects on the Move Who says statistics have to be a nightmare? Also in this issue: After the Deadline takes care of language issues. By Carsten Schnober and Heike Jurzik Jan Prchal, 123RF ven hardened nerds are often over-challenged by the less than intuitive field of statistics. Besides the theory, you Kheng123RF Ho Toh, need to know how to use the software that converts all Ethe theory into a practical application. The R environment [1] can be a big help on the software side. This free implementation of the S statistics programming lan- guage was launched in 1992. Initially, you will not be able to do much with R and its spartan command-line tools until you learn the language. Although SPSS [2] is a commercial alternative, even students are asked to pay a three-digit licensing fee, and the quality isn’t always on par with R. Sofa Statistics for All Free statistics software with an intuitive web interface is a niche that the Sofa (Statistics Open For All) [3] project fills. One of the project’s aims is to give statisticians an easy-to-use tool. Like many other mathematical disciplines, statistics is an ancillary science that is used in many areas to interpret empiric surveys. For example, you can use a series of results to calcu- late the probability of dice throws. Social scientists can also forecast whether a survey is significant or will just output random values. Many statistical tests have different strengths and weaknesses that only specialists can assess. -

Saidou Hamadou
SAIDOU HAMADOU Contact address: P.O.Box : 707 Yaoundé (Cameroon) Telephone: Cameroon : (237) 677 71 94 98 / 697 42 42 32 Email: [email protected] [email protected] Summary Over 11 years of experience in managing data, conducting health and/or demographic surveys in many countries in Central and West Africa Over 08 years of experiences in implementing and evaluating result-based financing in Cameroon, Burkina-Faso, Liberia, Republic of Congo, Democratic Republic of Congo, Chad, Djibouti and Haïti ; 03 years of experiences with Service Delivery Indicators (SDI) surveys Member of many research projects in Africa and in the World Fluent in French and speaks enough English Education University of Paris-Dauphine (FRANCE) 2018 PhD dissertation : „Poverty, Malaria and Health System Reforms in Africa: Three Studies Applied in Cameroon’ Doctoral advisors: Pr. Sandrine MESPLE-SOMPS and Dr. Anne-Sophie ROBILLIARD Institute for Training and Demographic Research (IFORD)(CAMEROUN) 2007-2009 Professional master in Demography, Master‟s Thesis: Dynamics of the relationship between standard of living of households and diarrhea- related morbidity in children of less than three years in Cameroon University of YAOUNDÉ I (CAMEROUN) 2005-2006 Master's degree in computer science - Option: Calculation scientific, Master‟s degree thesis: The securing of data circulation in a local network of enterprise by the CRYPTOGRAPHY University of NGAOUNDÉRÉ (CAMEROUN) 2004-2005 Bachelor of science and technical information (STI) - Option: Calculation scientific, -

O4 EN Nowy.Pdf
Authors: Agata Goździk, Dagmara Bożek, Karolina Chodzińska, Jesús Clemente, María Clemente, Alexia Micallef Gatt, Antonija Grizelj, Despoina Mitropoulou, Kostas Papadimas, Anita Simac, Franca Sormani, Mieke Sterken, Contributors: Institute of Geophysiscs, Polish Academy of Sciences Please cite this publication as: Goździk, A. et al (2021). BRITEC Citizen Science Toolkit. BRITEC report. March 2021, Institute of Geophysics PAS, Poland Keywords: Science, Technology, Engineering and Mathematics (STEM); Citizen Science; Participatory Science; School Education, research ethics Design/DTP: Mattia Gentile This report is published under the terms and conditions of the Attribution 4.0 International (CC BY 4.0) (https://creativecommons.org/licenses/by/4.0/). This report was produced within the project BRITEC: Bringing Research into the Classroom and has been funded with support from the European Commission within ERASMUS+ Programme, and corresponds to Output 4 of the project. This report reflects the views only of the authors, and FRSE and the European Commission cannot be held responsible for any use which may be made of the information contained therein. 1 Table of contents Executive summary ................................................................................................................................. 3 Introduction to Citizen Science ............................................................................................................... 4 Citizen Science Tools .............................................................................................................................. -

Cumulation of Poverty Measures: the Theory Beyond It, Possible Applications and Software Developed
Cumulation of Poverty measures: the theory beyond it, possible applications and software developed (Francesca Gagliardi and Giulio Tarditi) Siena, October 6th , 2010 1 Context and scope Reliable indicators of poverty and social exclusion are an essential monitoring tool. In the EU-wide context, these indicators are most useful when they are comparable across countries and over time. Furthermore, policy research and application require statistics disaggregated to increasingly lower levels and smaller subpopulations. Direct, one-time estimates from surveys designed primarily to meet national needs tend to be insufficiently precise for meeting these new policy needs. This is particularly true in the domain of poverty and social exclusion, the monitoring of which requires complex distributional statistics – statistics necessarily based on intensive and relatively small- scale surveys of households and persons. This work addresses some statistical aspects relating to improving the sampling precision of such indicators in EU countries, in particular through the cumulation of data over rounds of regularly repeated national surveys. 2 EU-SILC The reference data for this purpose are EU Statistics on Income and Living Conditions, the major source of comparative statistics on income and living conditions in Europe. A standard integrated design has been adopted by nearly all EU countries. It involves a rotational panel, with a new sample of households and persons introduced each year to replace one-fourth of the existing sample. Persons enumerated in each new sample are followed-up in the survey for four years. The design yields each year a cross- sectional sample, as well as longitudinal samples of 2, 3 and 4 year duration. -

Catering Services World Market Database Report & Database
Catering Services World Market Database Report & Database established in 1974, and a brand since 1981. www.datagroup.org Catering Services Database Ref: W2811_L This database is updated monthly. Catering Services World Market Database Report & Database CATERING SERVICES REPORT The Catering services Report & Database has the following information. The base report has 59 chapters, plus the Excel spreadsheets & Access databases specified. This research provides World Market Database on Catering services. The report is available in several Editions and Parts and the contents and cost of each part is shown below. The Client can choose the Edition required; and subsequently any Parts that are required from the After-Sales Service. Contents Description ....................................................................................................................................... 5 Coverage ......................................................................................................................................... 8 REPORT EDITIONS ......................................................................................................................... 12 World Report & Database.................................................................................................................. 12 Regional Report & Database ............................................................................................................. 12 Country Report & Database ............................................................................................................. -

Objectives Overview of Data Management Tools
Data Management: Collecting, Protecting and Managing Data Presented by Andre Hackman Johns Hopkins Bloomberg School of Public Health Department of Biostatistics July 17, 2014 Objectives • Review of available database and data management tools and their capabilities • Demonstrate examples of good data management • Discuss strategies and good practice for data security and backup • Discuss data conversion and transfer options Overview of Data Management Tools Types of data management tools to consider Type of tool Examples Spreadsheet Microsoft Excel Google Docs Spreadsheet Open Office Calc Desktop database Microsoft Access Filemaker Pro Specialized databases Epi Info, CSPro, EpiData Web database REDCap OpenClinica Mobile data collection Open Data Kit, CommCare, Magpi, iFormBuilder, 1 Choosing a data management tool… Pick the tool that is appropriate for the data needs of the project • What will be the challenges you face with each tool? – Complexity and scale of the data being collected • Is it longitudinal data with many time points? • What is the expected number of records? Choosing a data management tool… Pick the tool that is appropriate for the data needs of the project • What will be the challenges you face with each tool? – Complexity and scale of the data being collected – Mixture of collection modes: mobile, kiosk, and computer entry. • How will data flow between them? Choosing a data management tool… Pick the tool that is appropriate for the data needs of the project • What will be the challenges you face with each tool? – Complexity and scale of the data being collected – Mixture of collection modes: mobile, kiosk, and computer entry. – Complexity of the data entry forms 2 Choosing a data management tool… Pick the tool that is appropriate for the data needs of the project • What will be the challenges you face with each tool? – Complexity and scale of the data being collected – Mixture of collection modes: mobile, kiosk, and computer entry.