Discourse Models for Collaboratively Edited Corpora
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

(Abstracted by Courtesy of Joe P. Burns
JACK, Rhonda Sue King Jack (Abstracted by courtesy of Joe P. Burns Funeral Home, Perry, FL and Mayo, FL) Rhonda Sue King Jack, age 52, passed away on Sunday, November 18, 2012 at Marshall Health Care Center. She was born in Perry, Florida, on April 12, 1960 to the late Dennis King and the former Reba Cruce. Coming back from Texas she had lived in Perry for the last 5 years. She was a homemaker and a member of the Shady Grove Missionary Baptist Church. In her spare time she enjoyed her grandchildren, attending church, and word puzzles. She was preceded in death by her father, Dennis King, and a son, Tyrel Jack. She is survived by her mother, Reba Todd (Tommy), of Perry, FL, (2) sons, Ryan Jack, of Texarkana, TX, Freddy Jack, of Largo, FL, (2) daughters, Danielle Jack, of Bay City, TX, Ashley Jack, of Bastrop, TX, a brother, Alfred Dennis King, Jr., of Houston, TX, (half- sister, Wendy King Slaughter, of Shady Grove, FL, Step-sisters, Chantelle Johnson, and Donna Land, both of Perry, FL, (11) grandchildren, a host of nieces, nephews, aunts, uncles, and cousins. Funeral Services will be held at Joe P. Burns Funeral Home on Tuesday, November 20, 2012. Interment will follow in Hendry Memorial Cemetery. JACKSON, Annie Margarett Jackson (Abstracted from the Madison Enterprise-Recorder Newspaper, Madison, Florida, May 15, 1942) The death angel visited the home of Mr. and Mrs. G. C. Jackson at Pensacola May 8th, and bore away the gentle spirit of their infant, Annie Margarett Jackson. Annie Margarett was born December 13, 1941. -

The Most Important Dates in the History of Surfing
11/16/2016 The most important dates in the history of surfing (/) Explore longer 31 highway mpg2 2016 Jeep Renegade BUILD & PRICE VEHICLE DETAILS ® LEGAL Search ... GO (https://www.facebook.com/surfertoday) (https://www.twitter.com/surfertoday) (https://plus.google.com/+Surfertodaycom) (https://www.pinterest.com/surfertoday/) (http://www.surfertoday.com/rssfeeds) The most important dates in the history of surfing (/surfing/10553themost importantdatesinthehistoryofsurfing) Surfing is one of the world's oldest sports. Although the act of riding a wave started as a religious/cultural tradition, surfing rapidly transformed into a global water sport. The popularity of surfing is the result of events, innovations, influential people (http://www.surfertoday.com/surfing/9754themostinfluentialpeopleto thebirthofsurfing), and technological developments. Early surfers had to challenge the power of the oceans with heavy, finless surfboards. Today, surfing has evolved into a hightech extreme sport, in which hydrodynamics and materials play vital roles. Surfboard craftsmen have improved their techniques; wave riders have bettered their skills. The present and future of surfing can only be understood if we look back at its glorious past. From the rudimentary "caballitos de totora" to computerized shaping machines, there's an incredible trunk full of memories, culture, achievements and inventions to be rifled through. Discover the most important dates in the history of surfing: 30001000 BCE: Peruvian fishermen build and ride "caballitos -
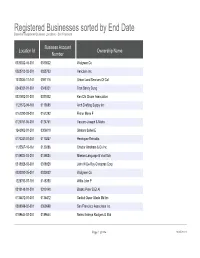
Registered Businesses Sorted by End Date Based on Registered Business Locations - San Francisco
Registered Businesses sorted by End Date Based on Registered Business Locations - San Francisco Business Account Location Id Ownership Name Number 0030032-46-001 0030032 Walgreen Co 0028703-02-001 0028703 Vericlaim Inc 1012834-11-141 0091116 Urban Land Services Of Cal 0348331-01-001 0348331 Tran Sandy Dung 0331802-01-001 0331802 Ken Chi Chuan Association 1121572-09-161 0113585 Arch Drafting Supply Inc 0161292-03-001 0161292 Fisher Marie F 0124761-06-001 0124761 Vaccaro Joseph & Maria 1243902-01-201 0306019 Shatara Suheil E 0170247-01-001 0170247 Henriquez Reinaldo 1125567-10-161 0130286 Chador Abraham & Co Inc 0189884-03-001 0189884 Mission Language & Vocl Sch 0318928-03-001 0318928 John W De Roy Chiroprac Corp 0030032-35-001 0030032 Walgreen Co 1228793-07-191 0148350 Willis John P 0310148-01-001 0310148 Blasko Peter B Et Al 0135472-01-001 0135472 Saddul Oscar Allado Md Inc 0369698-02-001 0369698 San Francisco Associates Inc 0189644-02-001 0189644 Neirro Erainya Rodgers G Etal Page 1 of 984 10/05/2021 Registered Businesses sorted by End Date Based on Registered Business Locations - San Francisco DBA Name Street Address City State Source Zipcode Walgreens #15567 845 Market St San Francisco CA 94103 Vericlaim Inc 500 Sansome St Ste 614 San Francisco CA 94111 Urban Land Services Of Cal 1170 Sacramento St 5d San Francisco CA 94108 Elizabeth Hair Studio 672 Geary St San Francisco CA 94102 Ken Chi Chuan Association 3626 Taraval St Apt 3 San Francisco CA 94116 Arch Drafting Supply Inc 10 Carolina St San Francisco CA 94103 Marie Fisher Interior -

Department of Homeland Security
Vol. 81 Tuesday, No. 104 May 31, 2016 Part IV Department of Homeland Security U.S. Customs and Border Protection Distribution of Continued Dumping and Subsidy Offset to Affected Domestic Producers; Notice VerDate Sep<11>2014 00:07 May 28, 2016 Jkt 238001 PO 00000 Frm 00001 Fmt 4717 Sfmt 4717 E:\FR\FM\31MYN2.SGM 31MYN2 srobinson on DSK5SPTVN1PROD with NOTICES2 34624 Federal Register / Vol. 81, No. 104 / Tuesday, May 31, 2016 / Notices DEPARTMENT OF HOMELAND received pursuant to a countervailing (TFTEA) (Pub. L. 114–125, February 24, SECURITY duty order, an antidumping duty order, 2016), provides new authority for CBP or a finding under the Antidumping Act to deposit into the CDSOA Special U.S. Customs and Border Protection of 1921 will be distributed to affected Account for distribution delinquency domestic producers for certain interest that accrued pursuant to 19 Distribution of Continued Dumping qualifying expenditures that these U.S.C. 1505(d), equitable interest under and Subsidy Offset to Affected producers incur after the issuance of common law, and interest under 19 Domestic Producers such an order or finding. The term U.S.C. 580 for payments received on or AGENCY: U.S. Customs and Border ‘‘affected domestic producer’’ means after October 1, 2014, on CDSOA subject Protection, Department of Homeland any manufacturer, producer, farmer, entries if the payment was made by a Security. rancher or worker representative surety in connection with a customs (including associations of such persons) bond pursuant to a court order or ACTION: Notice of intent to distribute who: judgment, or a litigation settlement with offset for Fiscal Year 2016. -

{PDF EPUB} Only with Passion: Figure Skating's Most
Read Ebook {PDF EPUB} Only With Passion: Figure Skating's Most Winning Champion on Competition and Life by Katarina Witt Witt has always done whatever she's done with all her heart -- with passion, intelligence, and a love of perfection. Now, in Only with Passion, she offers advice to a new generation of women athletes making their way in the world on how to live full out, compete with edge, and navigate life with grace. When a young skater consults her for advice on whether to train abroad -- and leave a boyfriend behind -- Witt … Oct 17, 2005 · Only With Passion: Figure Skating's Most Winning Champion on Competition and Life. In the glamorous, ultra-competitive world of figure skating, Katarina Witt is a living legend. Only With Passion: Figure Skating's Most Winning Champion on Competition and Life by Witt, Katarina (2007) Paperback Paperback. 3.5 out of 5 stars 21 ratings. Overview. In the glamorous, ultra-competitive world of figure skating, Katarina Witt is a living legend. She has won more titles than anyone else before her — including two Olympic gold medals, four world championships, and eight national championships. She is also renowned for independence and self-possession in a world where many stars are in thrall to management companies, and for her ability to … Written with E.M. Swift, author of My Sergei, one of the best-selling skating books of all time, Only with Passion is the perfect gift for young women, young athletes -- particularly skaters -- and skating fans of all ages.Publishers Weekly,Two-time Olympic figure skating gold medalist Witt (b. -

In “Love” Jukebox Memoir
in “Love” Jukebox Memoir (release date: 2/25/14) After recording 2012’s Domestic Disturbances, I realized I’d been struggling on the last couple of records to assimilate some of our many influences into what could be described as “The Jet Age sound.” Thus the concept for this album: To “own” the music that inspired us, without worrying about appearances. Of course, we didn’t want to sound like a wedding band, so if a song didn’t make sense to a player, if it didn’t resonate, it wasn’t gonna happen. A few songs didn’t make the cut (notably my ABBA homage—seriously), but once we’d gotten those missteps out of the way, these tracks quickly fell into place: 1. I Can’t Turn Around – Deliberately written as a state-of-the-art Jet Age song, this track brings our memoir up- to-date. I’d initially attributed the extended outro to our stint opening for The Wedding Present during 2011’s Bizarro tour, but I realized we’d been doing stuff like this since our debut, 2005’s Breathless. 2. Come Lie Down – A dream come true for me as Swervedriver’s Adam Franklin and Ride’s Mark Gardener join me on vocals. When I first started making music, Ride really showed me how guys who sing like girls could rock like The Who, while Swervedriver gave me guitar heroics to aspire to. I also cribbed from Spiritualized’s take on the Troggs’ “Anyway That You Want Me” and The Wedding Present’s “Dalliance,” which is ironic, since the latter inspired me to pare back some of my shoegazing tendencies. -

1 Music Article from a Homeless Street Musician in Nashville to a Top
Music article From a homeless street musician in Nashville to a top-selling artist in Sweden - The remarkable story of Doug Seegers (by J. Granstrom) In the previous newsletter, we covered Jill Johnson’s highly celebrated TV show “Jills veranda (Jill’s Porch)”, where she invites Swedish artists to visit her in Nashville to make music and learn more Seegers with Johnson at the Swedish about different aspects about life in the American TV show “Allsång på Skansen” Deep South. In one of the most popular episodes during the first season of the show in 2014, Johnson and her guest Magnus Carlson - singer of the popular Swedish band “Weeping Willows” which has collaborated with Oasis member Andy Bell on several occasions - met the 62-year old homeless street musician Doug Seegers who was performing on a park bench in Nashville. A street vendor recommended Johnson and Carlson to check out Seegers, and both were immediately impressed by Seeger’s voice. He tells them that he “lives in a place where he doesn’t have to pay rent - under a bridge”, and then brings them out to a church where homeless people are Seegers with Johnson on offered free food and clothes. During the visit, Seegers plays the cover of their joint his own song ”Going Down To The River”, which impressed album “In Tandem” Johnson and Carlson so much that they returned some time later and offered to record the song with Seegers in Johnny Cash’s old studio in Nashville. Seegers became an overnight sensation in Sweden after the episode was broadcast, and “Going Down To The River” was number 1 on the Swedish iTunes charts for 12 consecutive days. -

February 2012
FEBRUARY 2012 10803_Ironworker.indd 1 2/9/12 5:03 PM President’s The Reality: We Can Double Our Page Market Share in Ten Years uring the past year, as I have trav- tractors been better, more honest, Deled to local unions, district councils, and more of a partnership. We have or contractor association meetings and the best partners in the industry and speak that the Iron Workers will double the programs IMPACT has created our market share in the next ten years, and brought to bear will create more there is usually the skeptic who shakes opportunities and more market share his head or mutters that it can’t be done for union ironworkers. Your good or we’ve heard this before. This article is work and reputation is being publi- for them and why I so confident that it cized so owners and contractors know will be accomplished. we are the best value in the industry. 1. I have complete faith in our mem- 5. The demands of our two nations will bers—their skills, attitude and deter- dictate increased commitments to in- mination. Ironworkers are a differ- frastructure, energy, education and ent breed. Whether it comes from the manufacturing through public or work we do or the type of individual private partnerships. The work will our trade attracts; our work ethic, be done and we are positioning our- WALTER WISE competitiveness, and pride is recog- selves to do it. General President nized, acknowledged and respected by 6. Our competition’s labor force has brother tradesmen, contractors and dissipated. -

ENTERTAINMENT Page 17 Technique • Friday, March 24, 2000 • 17
ENTERTAINMENT page 17 Technique • Friday, March 24, 2000 • 17 Fu Manchu on the road On shoulders of giants ENTERTAINMENT The next time you head off down the Oasis returns after some troubling highway and are looking for some years with a new release and new hope tunes, try King of the Road. Page 19 for the future of the band. Page 21 Technique • Friday, March 24, 2000 Passion from the mouthpiece all the way to the back row By Alan Back Havana, Cuba, in 1949, Sandoval of jazz, classical idioms, and Living at a 15-degree tilt began studying classical trumpet traditional Cuban styles. at the age of 12, and his early During a 1977 visit to Cuba, Spend five minutes, or even experience included a three-year bebop master and Latin music five seconds, talking with enrollment at the Cuba National enthusiast Dizzy Gillespie heard trumpeter Arturo Sandoval and the young upstart performing you get an idea of just how with Irakere and decided to be- dedicated he is to his art. Whether “I don’t have to ask gin mentoring him. In the fol- working as a recording artist, lowing years, Sandoval left the composer, professor, or amateur permission to group in order to tour with both actor, he knows full well where anybody to do Gillespie’s United Nation Or- his inspiration comes from and chestra and an ensemble of his does everything in his power to what I have to.” own. The two formed a friend- pass that spark along to anyone Arturo Sandoval ship that lasted until the older who will listen. -

“All Politicians Are Crooks and Liars”
Blur EXCLUSIVE Alex James on Cameron, Damon & the next album 2 MAY 2015 2 MAY Is protest music dead? Noel Gallagher Enter Shikari Savages “All politicians are Matt Bellamy crooks and liars” The Horrors HAVE THEIR SAY The GEORGE W BUSH W GEORGE Prodigy + Speedy Ortiz STILL STARTING FIRES A$AP Rocky Django Django “They misunderestimated me” David Byrne THE PAST, PRESENT & FUTURE OF MUSIC Palma Violets 2 MAY 2015 | £2.50 US$8.50 | ES€3.90 | CN$6.99 # "% # %$ % & "" " "$ % %"&# " # " %% " "& ### " "& "$# " " % & " " &# ! " % & "% % BAND LIST NEW MUSICAL EXPRESS | 2 MAY 2015 Anna B Savage 23 Matthew E White 51 A$AP Rocky 10 Mogwai 35 Best Coast 43 Muse 33 REGULARS The Big Moon 22 Naked 23 FEATURES Black Rebel Motorcycle Nicky Blitz 24 Club 17 Noel Gallagher 33 4 Blanck Mass 44 Oasis 13 SOUNDING OFF Blur 36 Paddy Hanna 25 6 26 Breeze 25 Palma Violets 34, 42 ON REPEAT The Prodigy Brian Wilson 43 Patrick Watson 43 Braintree’s baddest give us both The Britanys 24 Passion Pit 43 16 IN THE STUDIO Broadbay 23 Pink Teens 24 Radkey barrels on politics, heritage acts and Caribou 33 The Prodigy 26 the terrible state of modern dance Carl Barât & The Jackals 48 Radkey 16 17 ANATOMY music. Oh, and eco light bulbs… Chastity Belt 45 Refused 6, 13 Coneheads 23 Remi Kabaka 15 David Byrne 12 Ride 21 OF AN ALBUM De La Soul 7 Rihanna 6 Black Rebel Motorcycle Club 32 Protest music Django Django 15, 44 Rolo Tomassi 6 – ‘BRMC’ Drenge 33 Rozi Plain 24 On the eve of the general election, we Du Blonde 35 Run The Jewels 6 -

Adream Season
EVGENIA MEDVEDEVA MOVES TO CANADIAN COACH ALJONA SAVCHENKO KAETLYN BRUNO OSMOND MASSOT TURN TO A DREAM COACHING SEASON MADISON CHOCK & SANDRA EVAN BATES GO NORTH BEZIC OF THE REFLECTS BORDER ON HER CREATIVE CAREER Happy family: Maxim Trankov and Tatiana Volosozhar posed for a series of family photos with their 1-year-old daughter, Angelica. Photo: Courtesy Sergey Bermeniev Adam Rippon and his partner Jena Johnson hoisted their Mirrorball Trophies after winning “Dancing with the Stars: Athlete’s Edition” in May. Photo: Courtesy Rogers Media/CityTV Contents 24 Features VOLUME 23 | ISSUE 4 | AUGUST 2018 EVGENIA MEDVEDEVA 6 Feeling Confident and Free MADISON CHOCK 10 & EVAN BATES Olympic Redemption A CREATIVE MIND 14 Canadian Choreographer Sandra Bezic Reflects on Her Illustrious Career DIFFERENT DIRECTIONS 22 Aljona Savchenko and Bruno Massot Turn to Coaching ON THE KAETLYN OSMOND COVER Ê 24 Celebrates a Dream Season OLYMPIC INDUCTIONS 34 Champions of the Past Headed to Hall of Fame EVOLVING ICE DANCE HUBS 38 Montréal Now the Hot Spot in the Ice Dance World THE JUNIOR CONNECTION 40 Ted Barton on the Growth and Evolution of the Junior Grand Prix Series Kaetlyn Osmond Departments 4 FROM THE EDITOR 44 FASHION SCORE All About the Men 30 INNER LOOP Around the Globe 46 TRANSITIONS Retirements and 42 RISING STARS Coaching Changes NetGen Ready to Make a Splash 48 QUICKSTEPS COVER PHOTO: SUSAN D. RUSSELL 2 IFSMAGAZINE.COM AUGUST 2018 Gabriella Papadakis drew the starting orders for the seeded men at the French Open tennis tournament, and had the opportunity to meet one of her idols, Rafael Nadal. -

Read Classic Pro Wrestling Photos 7Z for Ipad
Classic pro wrestling photos ENRIQUE & RAMON TORRES FACSIMILE AUTO PUBLICITY Photo 8X10 Wrestling VINTAGE. "Macho Man" Randy Savage is escorted to the ring for a match circa 1989. Businessmen in formal wear competing arm wrestling in modern office. International professional boxing ring in bright lights 3d render. J.C. Dykes and the Dominoes [Frank Hester-Cliff Lilly]. ANDRE THE GIANT vs MACHO MAN RANDY SAVAGE 8x10 WWF WWE Vintage Wrestling Photo. This Is Not the Olympics Japan Hoped For. Vintage LUNA VACHON WWF Wrestling Pinup Photo Lot (2) WCW DIVA 1990s RARE. Old School Wrestling with Texas Red AKA Red Bastien. The Late Pro Wrestling Legend Roddy Piper Sharing a Special Moment with His Youngest Fan Photo. Hulk Hogan Vintage Original 8 1/2x11 Promo Photo Unbranded 1980s WWF AWA WCW WWE. Vintage 1987 PRIVATE PHOTOS OF FALLEN ANGEL Print Ad NANCY BENOIT WOMAN. After garnering widespread acclaim and awards, Ted Lasso returns for another season. Here's what's in store for the unique coach and AFC Richmond. Luster the Legend Preparing For a Comeback black and white version Photo. Vintage Jackie Fargo Promotional Photo - Great Wrestling History. "Macho Man" Randy Savage enters the ring circa 1987 at Madison Square Garden in New York City. Tarzan Tyler vs Hiro Matsuda, ref Jack Terry. Pro Wrestler Gangrel Down But Not Out By a Long Shot Photo. ODESSA, UKRAINE-June 30, 2019: Fighters of MMA boxers are fighting without rules in cage ring of octagons. MMA fighters in ring at championship. Look at boxing fights without rules through metal cage. Boxing ring.