Logca: a High-Level Performance Model for Hardware Accelerators Muhammad Shoaib Bin Altaf ∗ David A
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Reconfigurable Embedded Control Systems: Problems and Solutions
RECONFIGURABLE EMBEDDED CONTROL SYSTEMS: PROBLEMS AND SOLUTIONS By Dr.rer.nat.Habil. Mohamed Khalgui ⃝c Copyright by Dr.rer.nat.Habil. Mohamed Khalgui, 2012 v Martin Luther University, Germany Research Manuscript for Habilitation Diploma in Computer Science 1. Reviewer: Prof.Dr. Hans-Michael Hanisch, Martin Luther University, Germany, 2. Reviewer: Prof.Dr. Georg Frey, Saarland University, Germany, 3. Reviewer: Prof.Dr. Wolf Zimmermann, Martin Luther University, Germany, Day of the defense: Monday January 23rd 2012, Table of Contents Table of Contents vi English Abstract x German Abstract xi English Keywords xii German Keywords xiii Acknowledgements xiv Dedicate xv 1 General Introduction 1 2 Embedded Architectures: Overview on Hardware and Operating Systems 3 2.1 Embedded Hardware Components . 3 2.1.1 Microcontrollers . 3 2.1.2 Digital Signal Processors (DSP): . 4 2.1.3 System on Chip (SoC): . 5 2.1.4 Programmable Logic Controllers (PLC): . 6 2.2 Real-Time Embedded Operating Systems (RTOS) . 8 2.2.1 QNX . 9 2.2.2 RTLinux . 9 2.2.3 VxWorks . 9 2.2.4 Windows CE . 10 2.3 Known Embedded Software Solutions . 11 2.3.1 Simple Control Loop . 12 2.3.2 Interrupt Controlled System . 12 2.3.3 Cooperative Multitasking . 12 2.3.4 Preemptive Multitasking or Multi-Threading . 12 2.3.5 Microkernels . 13 2.3.6 Monolithic Kernels . 13 2.3.7 Additional Software Components: . 13 2.4 Conclusion . 14 3 Embedded Systems: Overview on Software Components 15 3.1 Basic Concepts of Components . 15 3.2 Architecture Description Languages . 17 3.2.1 Acme Language . -

Foreign Library Interface by Daniel Adler Dia Applications That Can Run on a Multitude of Plat- Forms
30 CONTRIBUTED RESEARCH ARTICLES Foreign Library Interface by Daniel Adler dia applications that can run on a multitude of plat- forms. Abstract We present an improved Foreign Function Interface (FFI) for R to call arbitary na- tive functions without the need for C wrapper Foreign function interfaces code. Further we discuss a dynamic linkage framework for binding standard C libraries to FFIs provide the backbone of a language to inter- R across platforms using a universal type infor- face with foreign code. Depending on the design of mation format. The package rdyncall comprises this service, it can largely unburden developers from the framework and an initial repository of cross- writing additional wrapper code. In this section, we platform bindings for standard libraries such as compare the built-in R FFI with that provided by (legacy and modern) OpenGL, the family of SDL rdyncall. We use a simple example that sketches the libraries and Expat. The package enables system- different work flow paths for making an R binding to level programming using the R language; sam- a function from a foreign C library. ple applications are given in the article. We out- line the underlying automation tool-chain that extracts cross-platform bindings from C headers, FFI of base R making the repository extendable and open for Suppose that we wish to invoke the C function sqrt library developers. of the Standard C Math library. The function is de- clared as follows in C: Introduction double sqrt(double x); We present an improved Foreign Function Interface The .C function from the base R FFI offers a call (FFI) for R that significantly reduces the amount of gate to C code with very strict conversion rules, and C wrapper code needed to interface with C. -

Hardware, Firmware, Devices Disks Kernel, Boot, Swap Files, Volumes
hardware, kernel, boot, firmware, disks files, volumes swap devices software, security, patching, networking references backup tracing, logging TTAASSKK\ OOSS AAIIXX AA//UUXX DDGG//UUXX FFrreeeeBBSSDD HHPP--UUXX IIRRIIXX Derived from By IBM, with Apple 1988- 4.4BSD-Lite input from 1995. Based and 386BSD. System V, BSD, etc. on AT&T Data General This table SysV.2.2 with was aquired does not Hewlett- SGI. SVR4- OS notes Runs mainly extensions by EMC in include Packard based on IBM from V.3, 1999. external RS/6000 and V.4, and BSD packages related 4.2 and 4.3 from hardware. /usr/ports. /usr/sysadm ssmmiitt ssaamm /bin/sysmgr (6.3+) ssmmiittttyy ttoooollcchheesstt administrativ /usr/Cadmin/ wwssmm FFiinnddeerr ssyyssaaddmm ssyyssiinnssttaallll ssmmhh (11.31+) e GUI bin/* /usr/sysadm/ useradd (5+) FFiinnddeerr uusseerraadddd aadddduusseerr uusseerraadddd privbin/ addUserAcco userdell (5+) //eettcc//aadddduusseerr uusseerrddeell cchhppaassss uusseerrddeell unt usermod edit rrmmuusseerr uusseerrmmoodd managing (5+) /etc/passwd users llssuusseerr ppww ggeettpprrppww ppaassssmmggmmtt mmkkuusseerr vviippww mmooddpprrppww /usr/Cadmin/ cchhuusseerr ppwwggeett bin/cpeople rmuser usrck TASK \ OS AAIIXX AA//UUXX DDGG//UUXX FFrreeeeBBSSDD HHPP--UUXX IIRRIIXX pprrttccoonnff uunnaammee iioossccaann hhiinnvv dmesg (if (if llssccffgg ssyyssccttll--aa you're lucky) llssaattttrr ddmmeessgg aaddbb ssyyssiinnffoo--vvvv catcat lsdev /var/run/dm model esg.boot stm (from the llssppaatthh ppcciiccoonnff--ll SupportPlus CDROM) list hardware dg_sysreport - bdf (like -

Basics of UNIX
Basics of UNIX August 23, 2012 By UNIX, I mean any UNIX-like operating system, including Linux and Mac OS X. On the Mac you can access a UNIX terminal window with the Terminal application (under Applica- tions/Utilities). Most modern scientific computing is done on UNIX-based machines, often by remotely logging in to a UNIX-based server. 1 Connecting to a UNIX machine from {UNIX, Mac, Windows} See the file on bspace on connecting remotely to SCF. In addition, this SCF help page has infor- mation on logging in to remote machines via ssh without having to type your password every time. This can save a lot of time. 2 Getting help from SCF More generally, the department computing FAQs is the place to go for answers to questions about SCF. For questions not answered there, the SCF requests: “please report any problems regarding equipment or system software to the SCF staff by sending mail to ’trouble’ or by reporting the prob- lem directly to room 498/499. For information/questions on the use of application packages (e.g., R, SAS, Matlab), programming languages and libraries send mail to ’consult’. Questions/problems regarding accounts should be sent to ’manager’.” Note that for the purpose of this class, questions about application packages, languages, li- braries, etc. can be directed to me. 1 3 Files and directories 1. Files are stored in directories (aka folders) that are in a (inverted) directory tree, with “/” as the root of the tree 2. Where am I? > pwd 3. What’s in a directory? > ls > ls -a > ls -al 4. -

Oracle1® VM Virtualbox1® User Manual
Oracle R VM VirtualBox R User Manual Version 6.1.0_RC1 c 2004-2019 Oracle Corporation http://www.virtualbox.org Contents Preface i 1 First Steps 1 1.1 Why is Virtualization Useful?.............................2 1.2 Some Terminology..................................2 1.3 Features Overview..................................3 1.4 Supported Host Operating Systems.........................5 1.5 Host CPU Requirements...............................6 1.6 Installing Oracle VM VirtualBox and Extension Packs...............6 1.7 Starting Oracle VM VirtualBox............................7 1.8 Creating Your First Virtual Machine.........................8 1.9 Running Your Virtual Machine............................ 11 1.9.1 Starting a New VM for the First Time................... 12 1.9.2 Capturing and Releasing Keyboard and Mouse.............. 12 1.9.3 Typing Special Characters.......................... 13 1.9.4 Changing Removable Media........................ 14 1.9.5 Resizing the Machine’s Window...................... 14 1.9.6 Saving the State of the Machine...................... 15 1.10 Using VM Groups................................... 16 1.11 Snapshots....................................... 17 1.11.1 Taking, Restoring, and Deleting Snapshots................ 17 1.11.2 Snapshot Contents............................. 18 1.12 Virtual Machine Configuration............................ 19 1.13 Removing and Moving Virtual Machines...................... 19 1.14 Cloning Virtual Machines............................... 20 1.15 Importing and Exporting Virtual Machines.................... -

Symbian Os � 925
CONTENTS PREFACE xxiv 1 INTRODUCTION 1 1.1 WHAT IS AN OPERATING SYSTEM? 3 1.1.1 The Operating System as an Extended Machine 4 1.1.2 The Operating System as a Resource Manager 6 1.2 HISTORY OF OPERATING SYSTEMS 7 1.2.1 The First Generation (1945-55) Vacuum Tubes 7 1.2.2 The Second Generation (1955-65) Transistors and Batch Systems 8 1.2.3 The Third Generation (1965-1980) ICs and Multiprogramming 10 1.2.4 The Fourth Generation (1980—Present) Personal Computers 13 1.3 COMPUTER HARDWARE REVIEW 17 1.3.1 Processors 17 1.3.2 Memory 21 1.3.3 Disks 24 1.3.4 Tapes 25 1.3.5 1/0 Devices 25 1.3.6 Buses 28 1.3.7 Booting the Computer 31 vii Viii CONTENTS 1.4 THE OPERATING SYSTEM ZOO 31 1.4.1 Mainframe Operating Systems 32 1.4.2 Server Operating Systems 32 1.4.3 Multiprocessor Operating Systems 32 1.4.4 Personal Computer Operating Systems 33 1.4.5 Handheld Computer Operating Systems 33 1.4.6 Embedded Operating Systems. 33 1.4.7 Sensor Node Operating Systems 34 1.4.8 Real-Time Operating Systems 34 1.4.9 Smart Card Operating Systems 35 1.5 OPERATING SYSTEM CONCEPTS 35 1.5.1 Processes 36 1.5.2 Address Spaces 38 1.5.3 Files 38 1.5.4 Input/Output 41 1.5.5 Protection 42 1.5.6 The Shell 42 1.5.7 Ontogeny Recapitulates Phylogeny 44 1.6 SYSTEM CALLS 47 1.6.1 System Calls for Process Management 50 1.6.2 System Calls for File Management 54 1.6.3 System Calls for Directory Management 55 1.6.4 Miscellaneous System Calls 56 1.6.5 The Windows Win32 API 57 1.7 OPERATING SYSTEM STRUCTURE 60 1.7.1 Monolithic Systems 60 1.7.2 Layered Systems 61 1.7.3 Microkernels 62 1.7.4 -
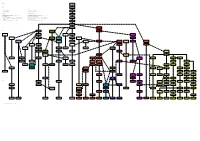
Unix History 2.6 Unix Geschichte 2.6 1972
1960 AT&T UNICS 1969 1970 UNIX 1 1971 UNIX 2 Unix history 2.6 Unix Geschichte 2.6 1972 Small UNIX history Kleine UNIX-Geschichte UNIX 3 1973 Represented are only the origin lines. Dargestellt sind nur die Ursprungslinien. The different influences are shown only with Apple, since they impair Die verschiedenen Einflüsse sind nur bei Apple abgebildet, da sie die the clarity strongly. Übersichtlichkeit stark beeinträchtigen. UNIX 4 Further data are: Manufacturer, operating system name as well as the Weitere Daten sind: Hersteller, Betriebssystem-Name sowie das 1973 feature year of the software. The individual versions are listed only with Erscheinungsjahr der Software. Die einzelnen Versionen sind nur bei UNIX and Linux. UNIX und Linux aufgelistet. More detailed list under: http://www.levenez.com/unix/ Detailliertere Liste unter: http://www.levenez.com/unix/ UNIX 5 1974 UNIX 6 1976 UNIX 7 Berkeley Software 1979 Distribution: BSD 1978 1980 UNIX System III Microsoft BSD 4.1 1981 XENIX 1981 1980 UNIX V UNIX 8 SUN SPIX QUNIX 1983 1985 Sun OS 1.0 1982 1981 1982 UNIX V.2 Microsoft/SCO Siemens UNIX 9 Sun OS 2.0 Dynix Venix 1984 XENIX 3.0 Sinix 1.0 1986 1985 1984 1985 1984 1984 HP IBM UNIX 10 MIPS BSD 4.2 GNU Sun OS 3.0 Andrew S. Mach HP-UX AIX/RT 2 End: 1989 MIPS OS 1985 Trix 1986 Tanenbaum: Minix 1985 1986 1986 1985 1986 1987 UNIX V.3 SGI Mach 2.0 Minix 1.0 NonStop-UX 1986 IRIX 1996 1987 1987 1988 UNIX V.4 AIX/6000 v3 BOS MIPS OS NeXT A/UX 1988 1989 1989 End: 1989 NeXTSTEP 1988 1988 1990 UNIX V.x Trusted AIX 3.1 IRIX 4.0 Mach 3.0 Linus Torvalds -

In the GNU Fortran Compiler
Using GNU Fortran For gcc version 12.0.0 (pre-release) (GCC) The gfortran team Published by the Free Software Foundation 51 Franklin Street, Fifth Floor Boston, MA 02110-1301, USA Copyright c 1999-2021 Free Software Foundation, Inc. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.3 or any later version published by the Free Software Foundation; with the Invariant Sections being \Funding Free Software", the Front-Cover Texts being (a) (see below), and with the Back-Cover Texts being (b) (see below). A copy of the license is included in the section entitled \GNU Free Documentation License". (a) The FSF's Front-Cover Text is: A GNU Manual (b) The FSF's Back-Cover Text is: You have freedom to copy and modify this GNU Manual, like GNU software. Copies published by the Free Software Foundation raise funds for GNU development. i Short Contents 1 Introduction ::::::::::::::::::::::::::::::::::::::::: 1 Invoking GNU Fortran 2 GNU Fortran Command Options :::::::::::::::::::::::: 7 3 Runtime: Influencing runtime behavior with environment variables ::::::::::::::::::::::::::::::::::::::::::: 33 Language Reference 4 Fortran standards status :::::::::::::::::::::::::::::: 39 5 Compiler Characteristics :::::::::::::::::::::::::::::: 45 6 Extensions :::::::::::::::::::::::::::::::::::::::::: 51 7 Mixed-Language Programming ::::::::::::::::::::::::: 73 8 Coarray Programming :::::::::::::::::::::::::::::::: 89 9 Intrinsic Procedures ::::::::::::::::::::::::::::::::: 113 -

Logtag Analyzer User Guide Page 2
Analyzer User Guide Software Revision: 3.1 Document Revision: 2.8 Published: 29. September 2020 About LogTag Analyzer User Guide page 2 Copyright Typographical Conventions The information contained in this User Guide regarding the use of Text in this font refers to buttons on a LogTag® product. LogTag® Analyzer software is intended as a guide and does not Text in this font refers to actions to be taken in LogTag®Analyzer, such constitute a declaration of performance. The information contained in as clicking a button, icon or menu item. this document is subject to change without notice. Unless otherwise in this font noted, the example companies, organizations, email addresses and Text describes features of a LogTag® product. people depicted herein are fictitious, and no association with any real An icon or menu in gray color cannot be clicked and its company, organization, email address or person is intended or should be function is not available at this time. inferred. Complying with all applicable copyright laws is the responsibility of the user. No representation or warranty is given and no liability is assumed by LogTag® Recorders with respect to the accuracy or use of such An icon or menu in the theme color can be clicked and its information or infringement of patents or other intellectual property function is available. rights arising from such use or otherwise. Copyright © 2004-2020 LogTag Recorders LTD. All rights reserved. https://logtagrecorders.com Text like this gives you tips on how to simplify tasks and how to get extra information. Privacy Policy Text like this highlights notes and key information that you should be aware of. -

LAFF-On Programming for High Performance
LAFF-On Programming for High Performance ulaff.net LAFF-On Programming for High Performance ulaff.net Robert van de Geijn The University of Texas at Austin Margaret Myers The University of Texas at Austin Devangi Parikh The University of Texas at Austin June 13, 2021 Cover: Texas Advanced Computing Center Edition: Draft Edition 2018–2019 Website: ulaff.net ©2018–2019 Robert van de Geijn, Margaret Myers, Devangi Parikh Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts. A copy of the license is included in the appendix entitled “GNU Free Documentation License.” All trademarks™ are the registered® marks of their respective owners. Acknowledgements We would like to thank the people who created PreTeXt, the authoring system used to typeset these materials. We applaud you! This work is funded in part by the National Science Foundation (Awards ACI-1550493 and CCF-1714091). vii viii Preface Over the years, we have noticed that many ideas that underlie programming for high performance can be illustrated through a very simple example: the computation of a matrix-matrix multiplication. It is perhaps for this reason that papers that expose the intricate details of how to optimize matrix-matrix multiplication are often used in the classroom [2] [10]. In this course, we have tried to carefully scaffold the techniques that lead to a high performance matrix- matrix multiplication implementation with the aim to make the materials of use to a broad audience. -

Customized OS Kernel for Data-Processing on Modern Hardware
Imperial College London MEng Computing Individual Project Customized OS kernel for data-processing on modern hardware Author: Supervisor: Daniel Grumberg Dr. Jana Giceva An Individual Project Report submitted in fulfillment of the requirements for the degree of MEng Computing in the Department of Computing June 18, 2018 iii Abstract Daniel Grumberg Customized OS kernel for data-processing on modern hardware The end of Moore’s Law shows that traditional processor design has hit its peak and that it cannot yield new major performance improvements. As an answer, computer architecture is turning towards domain-specific solutions in which the hardware’s properties are tailored to specific workloads. An example of this new trend is the Xeon Phi accelerator card which aims to bridge the gap between modern CPUs and GPUs. Commodity operating systems are not well equipped to leverage these ad- vancements. Most systems treat accelerators as they would an I/O device, or as an entirely separate system. Developers need to craft their algorithms to target the new device and to leverage its properties. However, transferring data between compu- tational devices is very costly, so programmers must also carefully specify all the individual memory transfers between the different execution environments to avoid unnecessary costs. This proves to be a complex task and software engineers often need to specialise and complicate their code in order to implement optimal memory transfer patterns. This project analyses the features of main-memory hash join algorithms, that are used in relational databases for join operations. Specifically, we explore the relation- ship between the main hash join algorithms and the hardware properties of Xeon Phi cards. -

Operating Systems and Middleware: Supporting Controlled Interaction
Operating Systems and Middleware: Supporting Controlled Interaction Max Hailperin Gustavus Adolphus College Revised Edition 1.1.2 August 2, 2012 Copyright c 2011 by Max Hailperin. This work is licensed under the Creative Commons Attribution-ShareAlike 3.0 Unported License. To view a copy of this license, visit http://creativecommons.org/licenses/by-sa/3.0/ or send a letter to Creative Commons, 171 Second Street, Suite 300, San Francisco, California, 94105, USA. To my family iv Contents Preface xi 1 Introduction 1 1.1 Chapter Overview . .1 1.2 What Is an Operating System? . .2 1.3 What is Middleware? . .6 1.4 Objectives for the Book . .7 1.5 Multiple Computations on One Computer . .9 1.6 Controlling the Interactions Between Computations . 11 1.7 Supporting Interaction Across Time . 13 1.8 Supporting Interaction Across Space . 15 1.9 Security . 17 2 Threads 21 2.1 Introduction . 21 2.2 Example of Multithreaded Programs . 23 2.3 Reasons for Using Concurrent Threads . 27 2.4 Switching Between Threads . 30 2.5 Preemptive Multitasking . 37 2.6 Security and Threads . 39 3 Scheduling 45 3.1 Introduction . 45 3.2 Thread States . 46 3.3 Scheduling Goals . 49 3.3.1 Throughput . 51 3.3.2 Response Time . 54 3.3.3 Urgency, Importance, and Resource Allocation . 55 3.4 Fixed-Priority Scheduling . 61 v vi CONTENTS 3.5 Dynamic-Priority Scheduling . 65 3.5.1 Earliest Deadline First Scheduling . 65 3.5.2 Decay Usage Scheduling . 66 3.6 Proportional-Share Scheduling . 71 3.7 Security and Scheduling .