Man-Bzip2.Pdf
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Lossless Compression of Internal Files in Parallel Reservoir Simulation
Lossless Compression of Internal Files in Parallel Reservoir Simulation Suha Kayum Marcin Rogowski Florian Mannuss 9/26/2019 Outline • I/O Challenges in Reservoir Simulation • Evaluation of Compression Algorithms on Reservoir Simulation Data • Real-world application - Constraints - Algorithm - Results • Conclusions 2 Challenge Reservoir simulation 1 3 Reservoir Simulation • Largest field in the world are represented as 50 million – 1 billion grid block models • Each runs takes hours on 500-5000 cores • Calibrating the model requires 100s of runs and sophisticated methods • “History matched” model is only a beginning 4 Files in Reservoir Simulation • Internal Files • Input / Output Files - Interact with pre- & post-processing tools Date Restart/Checkpoint Files 5 Reservoir Simulation in Saudi Aramco • 100’000+ simulations annually • The largest simulation of 10 billion cells • Currently multiple machines in TOP500 • Petabytes of storage required 600x • Resources are Finite • File Compression is one solution 50x 6 Compression algorithm evaluation 2 7 Compression ratio Tested a number of algorithms on a GRID restart file for two models 4 - Model A – 77.3 million active grid blocks 3.5 - Model K – 8.7 million active grid blocks 3 - 15.6 GB and 7.2 GB respectively 2.5 2 Compression ratio is between 1.5 1 compression ratio compression - From 2.27 for snappy (Model A) 0.5 0 - Up to 3.5 for bzip2 -9 (Model K) Model A Model K lz4 snappy gzip -1 gzip -9 bzip2 -1 bzip2 -9 8 Compression speed • LZ4 and Snappy significantly outperformed other algorithms -

The Ark Handbook
The Ark Handbook Matt Johnston Henrique Pinto Ragnar Thomsen The Ark Handbook 2 Contents 1 Introduction 5 2 Using Ark 6 2.1 Opening Archives . .6 2.1.1 Archive Operations . .6 2.1.2 Archive Comments . .6 2.2 Working with Files . .7 2.2.1 Editing Files . .7 2.3 Extracting Files . .7 2.3.1 The Extract dialog . .8 2.4 Creating Archives and Adding Files . .8 2.4.1 Compression . .9 2.4.2 Password Protection . .9 2.4.3 Multi-volume Archive . 10 3 Using Ark in the Filemanager 11 4 Advanced Batch Mode 12 5 Credits and License 13 Abstract Ark is an archive manager by KDE. The Ark Handbook Chapter 1 Introduction Ark is a program for viewing, extracting, creating and modifying archives. Ark can handle vari- ous archive formats such as tar, gzip, bzip2, zip, rar, 7zip, xz, rpm, cab, deb, xar and AppImage (support for certain archive formats depends on the appropriate command-line programs being installed). In order to successfully use Ark, you need KDE Frameworks 5. The library libarchive version 3.1 or above is needed to handle most archive types, including tar, compressed tar, rpm, deb and cab archives. To handle other file formats, you need the appropriate command line programs, such as zipinfo, zip, unzip, rar, unrar, 7z, lsar, unar and lrzip. 5 The Ark Handbook Chapter 2 Using Ark 2.1 Opening Archives To open an archive in Ark, choose Open... (Ctrl+O) from the Archive menu. You can also open archive files by dragging and dropping from Dolphin. -

Bzip2 and Libbzip2, Version 1.0.8 a Program and Library for Data Compression
bzip2 and libbzip2, version 1.0.8 A program and library for data compression Julian Seward, https://sourceware.org/bzip2/ bzip2 and libbzip2, version 1.0.8: A program and library for data compression by Julian Seward Version 1.0.8 of 13 July 2019 Copyright© 1996-2019 Julian Seward This program, bzip2, the associated library libbzip2, and all documentation, are copyright © 1996-2019 Julian Seward. All rights reserved. Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met: • Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer. • The origin of this software must not be misrepresented; you must not claim that you wrote the original software. If you use this software in a product, an acknowledgment in the product documentation would be appreciated but is not required. • Altered source versions must be plainly marked as such, and must not be misrepresented as being the original software. • The name of the author may not be used to endorse or promote products derived from this software without specific prior written permission. THIS SOFTWARE IS PROVIDED BY THE AUTHOR "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DIS- CLAIMED. IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. -

Working with Compressed Archives
Working with compressed archives Archiving a collection of files or folders means creating a single file that groups together those files and directories. Archiving does not manipulate the size of files. They are added to the archive as they are. Compressing a file means shrinking the size of the file. There are software for archiving only, other for compressing only and (as you would expect) other that have the ability to archive and compress. This document will show you how to use a windows application called 7-zip (seven zip) to work with compressed archives. 7-zip integrates in the context menu that pops-up up whenever you right-click your mouse on a selection1. In this how-to we will look in the application interface and how we manipulate archives, their compression and contents. 1. Click the 'start' button and type '7-zip' 2. When the search brings up '7-zip File Manager' (as the best match) press 'Enter' 3. The application will startup and you will be presented with the 7-zip manager interface 4. The program integrates both archiving, de/compression and file-management operations. a. The main area of the window provides a list of the files of the active directory. When not viewing the contents of an archive, the application acts like a file browser window. You can open folders to see their contents by just double-clicking on them b. Above the main area you have an address-like bar showing the name of the active directory (currently c:\ADG.Becom). You can use the 'back' icon on the far left to navigate back from where you are and go one directory up. -

Gzip, Bzip2 and Tar EXPERT PACKING
LINUXUSER Command Line: gzip, bzip2, tar gzip, bzip2 and tar EXPERT PACKING A short command is all it takes to pack your data or extract it from an archive. BY HEIKE JURZIK rchiving provides many bene- fits: packed and compressed Afiles occupy less space on your disk and require less bandwidth on the Internet. Linux has both GUI-based pro- grams, such as File Roller or Ark, and www.sxc.hu command-line tools for creating and un- packing various archive types. This arti- cle examines some shell tools for ar- chiving files and demonstrates the kind of expert packing that clever combina- tained by the packing process. If you A gzip file can be unpacked using either tions of Linux commands offer the com- prefer to use a different extension, you gunzip or gzip -d. If the tool discovers a mand line user. can set the -S (suffix) flag to specify your file of the same name in the working di- own instead. For example, the command rectory, it prompts you to make sure that Nicely Packed with “gzip” you know you are overwriting this file: The gzip (GNU Zip) program is the de- gzip -S .z image.bmp fault packer on Linux. Gzip compresses $ gunzip screenie.jpg.gz simple files, but it does not create com- creates a compressed file titled image. gunzip: screenie.jpg U plete directory archives. In its simplest bmp.z. form, the gzip command looks like this: The size of the compressed file de- Listing 1: Compression pends on the distribution of identical Compared gzip file strings in the original file. -

Deduplicating Compressed Contents in Cloud Storage Environment
Deduplicating Compressed Contents in Cloud Storage Environment Zhichao Yan, Hong Jiang Yujuan Tan* Hao Luo University of Texas Arlington Chongqing University University of Nebraska Lincoln [email protected] [email protected] [email protected] [email protected] Corresponding Author Abstract Data compression and deduplication are two common approaches to increasing storage efficiency in the cloud environment. Both users and cloud service providers have economic incentives to compress their data before storing it in the cloud. However, our analysis indicates that compressed packages of different data and differ- ently compressed packages of the same data are usual- ly fundamentally different from one another even when they share a large amount of redundant data. Existing data deduplication systems cannot detect redundant data among them. We propose the X-Ray Dedup approach to extract from these packages the unique metadata, such as the “checksum” and “file length” information, and use it as the compressed file’s content signature to help detect and remove file level data redundancy. X-Ray Dedup is shown by our evaluations to be capable of breaking in the boundaries of compressed packages and significantly Figure 1: A user scenario on cloud storage environment reducing compressed packages’ size requirements, thus further optimizing storage space in the cloud. will generate different compressed data of the same con- tents that render fingerprint-based redundancy identifi- cation difficult. Third, very similar but different digital 1 Introduction contents (e.g., files or data streams), which would other- wise present excellent deduplication opportunities, will Due to the information explosion [1, 3], data reduc- become fundamentally distinct compressed packages af- tion technologies such as compression and deduplica- ter applying even the same compression algorithm. -

Is It Time to Replace Gzip?
bioRxiv preprint doi: https://doi.org/10.1101/642553; this version posted May 20, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. Is it time to replace gzip? Comparison of modern compressors for molecular sequence databases Kirill Kryukov*, Mahoko Takahashi Ueda, So Nakagawa, Tadashi Imanishi Department of Molecular Life Science, Tokai University School of Medicine, Isehara, Kanagawa 259-1193, Japan. *Correspondence: [email protected] Abstract Nearly all molecular sequence databases currently use gzip for data compression. Ongoing rapid accumulation of stored data calls for more efficient compression tool. We systematically benchmarked the available compressors on representative DNA, RNA and Protein datasets. We tested specialized sequence compressors 2bit, BLAST, DNA-COMPACT, DELIMINATE, Leon, MFCompress, NAF, UHT and XM, and general-purpose compressors brotli, bzip2, gzip, lz4, lzop, lzturbo, pbzip2, pigz, snzip, xz, zpaq and zstd. Overall, NAF and zstd performed well in terms of transfer/decompression speed. However, checking benchmark results is necessary when choosing compressor for specific data type and application. Benchmark results database is available at: http://kirr.dyndns.org/sequence-compression-benchmark/. Keywords: compression; benchmark; DNA; RNA; protein; genome; sequence; database. Molecular sequence databases store and distribute DNA, RNA and protein sequences as compressed FASTA files. Currently, nearly all databases universally depend on gzip for compression. This incredible longevity of the 26-year-old compressor probably owes to multiple factors, including conservatism of database operators, wide availability of gzip, and its generally acceptable performance. -

Software Development Kits Comparison Matrix
Software Development Kits > Comparison Matrix Software Development Kits Comparison Matrix DATA COMPRESSION TOOLKIT FOR TOOLKIT FOR TOOLKIT FOR LIBRARY (DCL) WINDOWS WINDOWS JAVA Compression Method DEFLATE DEFLATE64 DCL Implode BZIP2 LZMA PPMd Extraction Method DEFLATE DEFLATE64 DCL Implode BZIP2 LZMA PPMd Wavpack Creation Formats Supported ZIP BZIP2 GZIP TAR UUENCODE, XXENCODE Large Archive Creation Support (ZIP64) Archive Extraction Formats Supported ZIP BZIP2 GZIP, TAR, AND .Z (UNIX COMPRESS) UUENCODE, XXENCODE CAB, BinHex, ARJ, LZH, RAR, 7z, and ISO/DVD Integration Format Static Dynamic Link Libraries (DLL) Pure Java Class Library (JAR) Programming Interface C C/C++ Objects C#, .NET interface Java Support for X.509-Compliant Digital Certificates Apply digital signatures Verify digital signatures Encrypt archives www.pkware.com Software Development Kits > Comparison Matrix DATA COMPRESSION TOOLKIT FOR TOOLKIT FOR TOOLKIT FOR LIBRARY (DCL) WINDOWS WINDOWS JAVA Signing Methods SHA-1 MD5 SHA-256, SHA-384 and SHA-512 Message Digest Timestamp .ZIP file signatures ENTERPRISE ONLY Encryption Formats ZIP OpenPGP ENTERPRISE ONLY Encryption Methods AES (256, 192, 128-bit) 3DES (168, 112-bit) 168 ONLY DES (56-bit) RC4 (128, 64, 40-bit), RC2 (128, 64, 40-bit) CAST5 and IDEA Decryption Methods AES (256, 192, 128-bit) 3DES (168, 112-bit) 168 ONLY DES (56-bit) RC4 (128, 64, 40-bit), RC2 (128, 64, 40-bit) CAST5 and IDEA Additional Features Supports file, memory and streaming operations Immediate archive operation Deferred archive operation Multi-Thread -
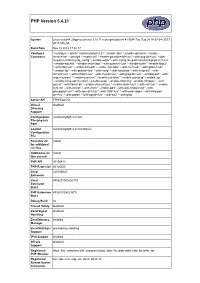
PHP Version 5.4.21
PHP Version 5.4.21 System Linux web244.20gp.ha.ovh.net 3.10.11-mutu-grs-ipv6-64 #1 SMP Tue Sep 24 18:07:54 CEST 2013 x86_64 Build Date Nov 12 2013 17:52:17 Configure './configure' '--prefix=/usr/local/php5.4.21' '--enable-fpm' '--enable-opcache' '--enable- Command memcache' '--with-gd' '--enable-intl' '--enable-gd-native-ttf=/usr' '--with-png-dir=/usr' '--with- mysqli=/usr/bin/mysql_config' '--enable-wddx' '--with-config-file-path=/usr/local/php5.4.21/etc' '--enable-sigchild' '--enable-short-tags' '--with-openssl=/usr' '--disable-rpath' '--enable-libgcc' '--with-zlib=/usr' '--enable-bcmath' '--enable-calendar' '--with-curl=/usr' '--with-gdbm=/usr' '--enable-ftp' '--with-gettext=/usr' '--with-imap' '--with-kerberos' '--with-imap-ssl' '--with- mcrypt=/usr' '--with-mhash=/usr' '--with-mysql=/usr' '--with-jpeg-dir=/usr' '--enable-exif' '--with- regex=system' '--enable-sysvsem' '--enable-sysvshm' '--enable-sysvmsg' '--enable-zip' '--enable-inline-optimization' '--enable-soap' '--enable-mbstring' '--enable-mbregex' '--with- gnu-ld' '--with-libxml-dir' '--enable-shared=yes' '--enable-static=yes' '--with-xsl=/usr' '--enable- sockets' '--with-xmlrpc' '--with-iconv' '--enable-pdo' '--with-pdo-mysql=/usr' '--with- pdo-pgsql=/usr' '--with-xpm-dir=/usr' '--with-t1lib=/usr' '--with-pcre-regex' '--with-freetype- dir=/usr' '--with-pspell' '--with-pgsql=/usr' '--with-bz2' '--with-gmp' Server API FPM/FastCGI Virtual disabled Directory Support Configuration /usr/local/php5.4.21/etc File (php.ini) Path Loaded /usr/local/php5.4.21/etc/php.ini Configuration -

I Came to Drop Bombs Auditing the Compression Algorithm Weapons Cache
I Came to Drop Bombs Auditing the Compression Algorithm Weapons Cache Cara Marie NCC Group Blackhat USA 2016 About Me • NCC Group Senior Security Consultant Pentested numerous networks, web applications, mobile applications, etc. • Hackbright Graduate • Ticket scalper in a previous life • @bones_codes | [email protected] What is a Decompression Bomb? A decompression bomb is a file designed to crash or render useless the program or system reading it. Vulnerable Vectors • Chat clients • Image hosting • Web browsers • Web servers • Everyday web-services software • Everyday client software • Embedded devices (especially vulnerable due to weak hardware) • Embedded documents • Gzip’d log uploads A History Lesson early 90’s • ARC/LZH/ZIP/RAR bombs were used to DoS FidoNet systems 2002 • Paul L. Daniels publishes Arbomb (Archive “Bomb” detection utility) 2003 • Posting by Steve Wray on FullDisclosure about a bzip2 bomb antivirus software DoS 2004 • AERAsec Network Services and Security publishes research on the various reactions of antivirus software against decompression bombs, includes a comparison chart 2014 • Several CVEs for PIL are issued — first release July 2010 (CVE-2014-3589, CVE-2014-3598, CVE-2014-9601) 2015 • CVE for libpng — first release Aug 2004 (CVE-2015-8126) Why Are We Still Talking About This?!? Why Are We Still Talking About This?!? Compression is the New Hotness Who This Is For Who This Is For The Archives An archive bomb, a.k.a. zip bomb, is often employed to disable antivirus software, in order to create an opening for more traditional viruses • Singly compressed large file • Self-reproducing compressed files, i.e. Russ Cox’s Zips All The Way Down • Nested compressed files, i.e. -

12.1 Introduction 12.2 Tar Command
12.1 Introduction Linux distributions provide several different sets of commands for compressing and archiving files and directories. This chapter will describe their advantages and disadvantages as well as their usefulness in making backup copies of files and directories efficiently. More sophisticated types of copying, using the dd and cpio commands, will also be covered. These commands, while more complex, offer powerful features. 12.2 tar Command An archive is a single file, which consists of many files, though not necessarily compressed. The tar command is typically used to make archives within Linux. These tar archive files, sometimes called tarballs, were originally used to backup data onto magnetic tape. Tar is derived from the words "tape archive". While the primary purpose of the tar command is to merge multiple files into a single file, it is capable of many different operations and there are numerous options. The functionality of the tar command can be broken down into three basic functions: creating, viewing and extracting archives. The tar command accepts all three styles of options (x, -x, --extract) as parameters. Do not be surprised to see it used with options that have no hyphens (BSD style), a single hyphen (UNIX style) or two hyphens (GNU style). The tar command originally did not support compression, but a newer version that was developed by the GNU project supports both gzip and bzip2compression. Both of these compression schemes will be presented later in this chapter. To use gzip compression with the tar command, use the -z option. To use bzip2 compression, use the -j option. -

Software Requirements Specification
Software Requirements Specification for PeaZip Requirements for version 2.7.1 Prepared by Liles Athanasios-Alexandros Software Engineering , AUTH 12/19/2009 Software Requirements Specification for PeaZip Page ii Table of Contents Table of Contents.......................................................................................................... ii 1. Introduction.............................................................................................................. 1 1.1 Purpose ........................................................................................................................1 1.2 Document Conventions.................................................................................................1 1.3 Intended Audience and Reading Suggestions...............................................................1 1.4 Project Scope ...............................................................................................................1 1.5 References ...................................................................................................................2 2. Overall Description .................................................................................................. 3 2.1 Product Perspective......................................................................................................3 2.2 Product Features ..........................................................................................................4 2.3 User Classes and Characteristics .................................................................................5