Dude Wheres My Stars 04.23.21.Pdf
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Rotational Motion (The Dynamics of a Rigid Body)
University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln Robert Katz Publications Research Papers in Physics and Astronomy 1-1958 Physics, Chapter 11: Rotational Motion (The Dynamics of a Rigid Body) Henry Semat City College of New York Robert Katz University of Nebraska-Lincoln, [email protected] Follow this and additional works at: https://digitalcommons.unl.edu/physicskatz Part of the Physics Commons Semat, Henry and Katz, Robert, "Physics, Chapter 11: Rotational Motion (The Dynamics of a Rigid Body)" (1958). Robert Katz Publications. 141. https://digitalcommons.unl.edu/physicskatz/141 This Article is brought to you for free and open access by the Research Papers in Physics and Astronomy at DigitalCommons@University of Nebraska - Lincoln. It has been accepted for inclusion in Robert Katz Publications by an authorized administrator of DigitalCommons@University of Nebraska - Lincoln. 11 Rotational Motion (The Dynamics of a Rigid Body) 11-1 Motion about a Fixed Axis The motion of the flywheel of an engine and of a pulley on its axle are examples of an important type of motion of a rigid body, that of the motion of rotation about a fixed axis. Consider the motion of a uniform disk rotat ing about a fixed axis passing through its center of gravity C perpendicular to the face of the disk, as shown in Figure 11-1. The motion of this disk may be de scribed in terms of the motions of each of its individual particles, but a better way to describe the motion is in terms of the angle through which the disk rotates. -

The Rotation Group in Plate Tectonics and the Representation of Uncertainties of Plate Reconstructions
Geophys. J. In?. (1990) 101, 649-661 The rotation group in plate tectonics and the representation of uncertainties of plate reconstructions T. Chang’ J. Stock2 and P. Molnar3 ‘Department of Mathematics, University of Virginia, Charlottesville, Virginia 22903-3199, USA ‘Department of Earth and Planetary Sciences, Harvard University, Cambridge, MA 02138, USA ’Department of Earth, Atmospheric, and Planetary Sciences, Massachusetts Institute of Technology, Cambridge, MA 02139, USA Accepted 1989 December 27. Received 1989 December 27; in original form 1989 August 11 Downloaded from SUMMARY The calculation of the uncertainty in an estimated rotation requires a parametriza- tion of the rotation group; that is, a unique mapping of the rotation group to a point in 3-D Euclidean space, R3. Numerous parametrizations of a rotation exist, http://gji.oxfordjournals.org/ including: (1) the latitude and longitude of the axis of rotation and the angle of rotation; (2) a representation as a Cartesian vector with length equal to the rotation angle and direction parallel to the rotation axis; (3) Euler angles; or (4) unit length quaternions (or, equivalently, Cayley-Klein parameters). The uncertainty in a rotation is determined by the effect of nearby rotations on the rotated data. The uncertainty in a rotation is small, if rotations close to the best fitting rotation degrade the fit of the data by a large amount, and it is large, if only rotations differing by a large amount cause such a degradation. Ideally, we would at California Institute of Technology on August 29, 2014 like to parametrize the rotations in such a way so that their representation as points in R3 would have the property that the distance between two points in R3 reflects the effects of the corresponding rotations on the fit of the data. -

4-2 Degrees and Radians
4-2 Degrees and Radians Write each degree measure in radians as a multiple of π and each radian measure in degrees. 10. 30° SOLUTION: To convert a degree measure to radians, multiply by ANSWER: 14. SOLUTION: To convert a radian measure to degrees, multiply by ANSWER: 120° Identify all angles that are coterminal with the given angle. Then find and draw one positive and one negative angle coterminal with the given angle. 20. 225° SOLUTION: All angles measuring are coterminal with a angle. Sample answer: Let n = 1 and −1. eSolutions Manual - Powered by Cognero Page 1 ANSWER: 225° + 360n°; Sample answer: 585°, −135° 24. SOLUTION: All angles measuring are coterminal with a angle. Sample answer: Let n = 1 and −1. ANSWER: Find the length of the intercepted arc with the given central angle measure in a circle with the given radius. Round to the nearest tenth. 29. , r = 4 yd SOLUTION: ANSWER: 5.2 yd 30. 105°, r = 18.2 cm SOLUTION: Method 1 Convert 105° to radian measure, and then use s = rθ to find the arc length. Substitute r = 18.2 and θ = . Method 2 Use s = to find the arc length. ANSWER: 33.4 cm Find the rotation in revolutions per minute given the angular speed and the radius given the linear speed and the rate of rotation. 36. = 104π rad/min SOLUTION: The angular speed is 104π radians per minute. Each revolution measures 2π radians 104π ÷ 2π = 52 The angle of rotation is 52 revolutions per minute. ANSWER: 52 rev/min 37. v = 82.3 m/s, 131 rev/min SOLUTION: 131 × 2π = 262π The linear speed is 82.3 meters per second with an angle of rotation of 262π radians per minute. -

Rotation Matrix - Wikipedia, the Free Encyclopedia Page 1 of 22
Rotation matrix - Wikipedia, the free encyclopedia Page 1 of 22 Rotation matrix From Wikipedia, the free encyclopedia In linear algebra, a rotation matrix is a matrix that is used to perform a rotation in Euclidean space. For example the matrix rotates points in the xy -Cartesian plane counterclockwise through an angle θ about the origin of the Cartesian coordinate system. To perform the rotation, the position of each point must be represented by a column vector v, containing the coordinates of the point. A rotated vector is obtained by using the matrix multiplication Rv (see below for details). In two and three dimensions, rotation matrices are among the simplest algebraic descriptions of rotations, and are used extensively for computations in geometry, physics, and computer graphics. Though most applications involve rotations in two or three dimensions, rotation matrices can be defined for n-dimensional space. Rotation matrices are always square, with real entries. Algebraically, a rotation matrix in n-dimensions is a n × n special orthogonal matrix, i.e. an orthogonal matrix whose determinant is 1: . The set of all rotation matrices forms a group, known as the rotation group or the special orthogonal group. It is a subset of the orthogonal group, which includes reflections and consists of all orthogonal matrices with determinant 1 or -1, and of the special linear group, which includes all volume-preserving transformations and consists of matrices with determinant 1. Contents 1 Rotations in two dimensions 1.1 Non-standard orientation -

Rotational Motion CONTENTS CHAPTER-OPENING QUESTION—Guess Now! 8–1 Angular Quantities a Solid Ball and a Solid Cylinder Roll Down a Ramp
You too can experience rapid rotation—if your stomach can take the high angular velocity and centripetal acceleration of some of the faster amusement park rides. If not, try the slower merry-go-round or Ferris wheel. Rotating carnival rides have rotational kinetic energy as well as angular momentum. Angular acceleration is produced by a net torque, and rotating objects have rotational kinetic energy. P T A E H R C 8 Rotational Motion CONTENTS CHAPTER-OPENING QUESTION—Guess now! 8–1 Angular Quantities A solid ball and a solid cylinder roll down a ramp. They both start from rest at the 8–2 Constant Angular Acceleration same time and place. Which gets to the bottom first? 8–3 Rolling Motion (a) They get there at the same time. (Without Slipping) (b) They get there at almost exactly the same time except for frictional differences. 8–4 Torque (c) The ball gets there first. 8–5 Rotational Dynamics; (d) The cylinder gets there first. Torque and Rotational Inertia (e) Can’t tell without knowing the mass and radius of each. 8–6 Solving Problems in Rotational Dynamics ntil now, we have been concerned mainly with translational motion. We 8–7 Rotational Kinetic Energy discussed the kinematics and dynamics of translational motion (the role 8–8 Angular Momentum and of force). We also discussed the energy and momentum for translational Its Conservation U *8–9 Vector Nature of motion. In this Chapter we will deal with rotational motion. We will discuss the Angular Quantities kinematics of rotational motion and then its dynamics (involving torque), as well as rotational kinetic energy and angular momentum (the rotational analog of linear momentum). -

ROTATION: a Review of Useful Theorems Involving Proper Orthogonal Matrices Referenced to Three- Dimensional Physical Space
Unlimited Release Printed May 9, 2002 ROTATION: A review of useful theorems involving proper orthogonal matrices referenced to three- dimensional physical space. Rebecca M. Brannon† and coauthors to be determined †Computational Physics and Mechanics T Sandia National Laboratories Albuquerque, NM 87185-0820 Abstract Useful and/or little-known theorems involving33× proper orthogonal matrices are reviewed. Orthogonal matrices appear in the transformation of tensor compo- nents from one orthogonal basis to another. The distinction between an orthogonal direction cosine matrix and a rotation operation is discussed. Among the theorems and techniques presented are (1) various ways to characterize a rotation including proper orthogonal tensors, dyadics, Euler angles, axis/angle representations, series expansions, and quaternions; (2) the Euler-Rodrigues formula for converting axis and angle to a rotation tensor; (3) the distinction between rotations and reflections, along with implications for “handedness” of coordinate systems; (4) non-commu- tivity of sequential rotations, (5) eigenvalues and eigenvectors of a rotation; (6) the polar decomposition theorem for expressing a general deformation as a se- quence of shape and volume changes in combination with pure rotations; (7) mix- ing rotations in Eulerian hydrocodes or interpolating rotations in discrete field approximations; (8) Rates of rotation and the difference between spin and vortici- ty, (9) Random rotations for simulating crystal distributions; (10) The principle of material frame indifference (PMFI); and (11) a tensor-analysis presentation of classical rigid body mechanics, including direct notation expressions for momen- tum and energy and the extremely compact direct notation formulation of Euler’s equations (i.e., Newton’s law for rigid bodies). -
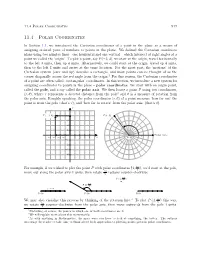
11.4 Polar Coordinates 917
11.4 Polar Coordinates 917 11.4 Polar Coordinates In Section 1.1, we introduced the Cartesian coordinates of a point in the plane as a means of assigning ordered pairs of numbers to points in the plane. We defined the Cartesian coordinate plane using two number lines { one horizontal and one vertical { which intersect at right angles at a point we called the `origin'. To plot a point, say P (−3; 4), we start at the origin, travel horizontally to the left 3 units, then up 4 units. Alternatively, we could start at the origin, travel up 4 units, then to the left 3 units and arrive at the same location. For the most part, the `motions' of the Cartesian system (over and up) describe a rectangle, and most points can be thought of as the corner diagonally across the rectangle from the origin.1 For this reason, the Cartesian coordinates of a point are often called `rectangular' coordinates. In this section, we introduce a new system for assigning coordinates to points in the plane { polar coordinates. We start with an origin point, called the pole, and a ray called the polar axis. We then locate a point P using two coordinates, (r; θ), where r represents a directed distance from the pole2 and θ is a measure of rotation from the polar axis. Roughly speaking, the polar coordinates (r; θ) of a point measure `how far out' the point is from the pole (that's r), and `how far to rotate' from the polar axis, (that's θ). -

Hybrid Attitude Control and Estimation on SO(3)
Western University Scholarship@Western Electronic Thesis and Dissertation Repository 11-29-2017 4:00 PM Hybrid Attitude Control and Estimation On SO(3) Soulaimane Berkane The University of Western Ontario Supervisor Tayebi, Abdelhamid The University of Western Ontario Graduate Program in Electrical and Computer Engineering A thesis submitted in partial fulfillment of the equirr ements for the degree in Doctor of Philosophy © Soulaimane Berkane 2017 Follow this and additional works at: https://ir.lib.uwo.ca/etd Part of the Acoustics, Dynamics, and Controls Commons, Controls and Control Theory Commons, and the Navigation, Guidance, Control and Dynamics Commons Recommended Citation Berkane, Soulaimane, "Hybrid Attitude Control and Estimation On SO(3)" (2017). Electronic Thesis and Dissertation Repository. 5083. https://ir.lib.uwo.ca/etd/5083 This Dissertation/Thesis is brought to you for free and open access by Scholarship@Western. It has been accepted for inclusion in Electronic Thesis and Dissertation Repository by an authorized administrator of Scholarship@Western. For more information, please contact [email protected]. Abstract This thesis presents a general framework for hybrid attitude control and estimation de- sign on the Special Orthogonal group SO(3). First, the attitude stabilization problem on SO(3) is considered. It is shown that, using a min-switch hybrid control strategy de- signed from a family of potential functions on SO(3), global exponential stabilization on SO(3) can be achieved when this family of potential functions satisfies certain properties. Then, a systematic methodology to construct these potential functions is developed. The proposed hybrid control technique is applied to the attitude tracking problem for rigid body systems. -

General Angles and Radian Measure 777 EXAMPLE 3 Converting Between Degrees and Radians
General Angles and 13.2 Radian Measure GOAL 1 ANGLES IN STANDARD POSITION What you should learn GOAL 1 Measure angles in In Lesson 13.1 you worked only with acute angles (angles measuring between 0° and standard position using 90°). In this lesson you will study angles whose measures can be any real numbers. degree measure and radian Recall that an angle is formed by two rays that have Њ measure. terminal y 90 a common endpoint, called the vertex. You can side GOAL 2 Calculate arc generate any angle by fixing one ray, called the lengths and areas of sectors, initial side, and rotating the other ray, called the as applied in Example 6. terminal side, about the vertex. In a coordinate 0Њ plane, an angle whose vertex is at the origin and you should learn it x Why whose initial side is the positive x-axis is in 180Њ vertex initial side 360Њ ᭢ To solve real-life standard position. problems, such as finding the angle generated by a The measure of an angle is determined by the amount and direction of rotation from the initial side rotating figure skater in 270Њ to the terminal side. The angle measure is positive if Exs. 77–79. L LIF A E E R the rotation is counterclockwise, and negative if the rotation is clockwise. The terminal side of an angle can make more than one complete rotation. EXAMPLE 1 Drawing Angles in Standard Position Draw an angle with the given measure in standard position. Then tell in which quadrant the terminal side lies. -

10.2A Angles of Rotation
10.2A Angles of Rotation Objective: F.TF.2: Explain how the unit circle in the coordinate plane enables the extension of trigonometric functions to all real numbers, interpreted as radian measures of angles traversed counterclockwise around the unit circle. For the Board: You will be able to draw angles in standard position and determine the values of the trigonometric functions for an angle in standard position. Anticipatory Set: In the previous section we worked with acute angles of a right triangle. In this section we will investigate angles in the coordinate plane. 90° An angle is in standard position when its vertex is at the origin and one ray is on the positive x-axis. The initial side of the angle is the ray on the x-axis and the other ray Terminal side is the terminal side of the angle. 180° 0° Initial side Angle measure is then based on the degree of rotation. An angle of rotation is formed by rotating the terminal side and keeping the initial side in place. 270° Rotation can be either clockwise or counterclockwise. Counterclockwise is considered the positive rotation direction. Clockwise is considered the negative rotation direction. Positive Rotation Negative Rotation 90° -270° + degree Terminal side Initial side 180° 0° - 180° 0° Initial side Terminal side - degree - 90° 270° Instruction: Open the book to page 700 and read example 1. Example: Draw an angle with the given measure in standard position. a. 320° b. -110° c. 990° White Board Activity: Practice: Draw an angle with the given measure in standard position. -

11. Rotation Translational Motion: Motion of the Center of Mass of an Object from One Position to Another
11. Rotation Translational Motion: Motion of the center of mass of an object from one position to another. All the motion discussed so far belongs to this category, except uniform circular motion. Rotational Motion: Motion of an object about an axis: e.g. a basketball spinning on your finger, an ice skater spinning on his skates, the rotation of a bicycle wheel. Uniform circular motion is a special case of rotational motion. • Will limit our discussion to rigid bodies, i.e. objects that don't deform. • Also will limit ourselves to rotational motion about a fixed axis, i.e. the axis is not moving. Define a coordinate system to describe the rotational motion: y q reference line x • Every particle on the body moves in a circle whose center is on the axis of rotation. • Each point rotates through the same angles over a fixed time period. H Will define a set of quantities to describe rotational motion similar to position, displacement, velocity, and acceleration used to describe translational motion. Angular Position (q): This is the angular location of the reference line which rotates with the object relative to a fixed axis. • Unit: radian (not degree) • If a body makes two complete revolutions, the angular position is 4p. (Don't "reset" the angular position to less that 2p). • Define the counterclockwise direction as the direction of increasing q and the clockwise direction as the direction of decreasing q. • The distance that a point on the object moves is the arc length defined by q and the distance from the axis of rotation: s = rq Angular Displacement: The change in the angular position from one time to another: Dq = q2 - q1 • Dq can be positive or negative. -
Title Glossary of Interest to Earthquake and Engineering Seismologists 1
Glossary Title Glossary of interest to earthquake and engineering seismologists Compiled Peter Bormann, retired from GFZ German Research Centre for Geosciences, and Telegrafenberg, 14473 Potsdam, Germany; E-mail: [email protected] amended Keiiti Aki ()(1930-2005) by William H. K. Lee, retired from U.S. Geological Survey, Menlo Park, CA 94025, USA; [email protected] Johannes Schweitzer, NORSAR, Gunnar Randers vei 15, P.O. Box 53, N- 2027 Kjeller, Norway; contact via: Phone: +47-63805940, E-mail: [email protected] Version 1 November 2011; DOI: 10.2312/GFZ.NMSOP-2_Glossary 1 Introduction This is a preliminary glossary, still under development, revision and amendment, also with respect to co-authorship. Comments, corrections as well as proposals for complementary entries are highly welcome and should be sent to the editor, P. Bormann. He has compiled the current version by combining, harmonizing, amending and sometimes correcting entries from three major earlier published glossaries of terms that are (see References): 1) frequently used in seismological observatory practice (glossary in the first edition of the IASPEI New Manual of Seismological Observatory Practice (NMSOP; Bormann, 2002 and 2009; see http://nmsop.gfz-potsdam.de); 2) of interest to earthquake and engineering seismologists (glossary compiled by Aki and Lee, 2003, for the International Handbook of Earthquake and Engineering Seismology (see Lee et al., 2003); 3) now widely used in some rapidly developing new fields such as rotational seismology, (compiled by Lee, 2009). The following glossary includes some 1,500 specialized terms. Not included were abbreviations and acronyms (with the exception of just a few that required more explanation), Acronyms have been added as an extra file to this Manual (see NMSOP-2 website cover page).