Boolean Functions and Degree of Approximation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
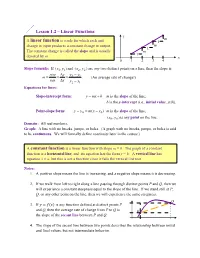
Lesson 1.2 – Linear Functions Y M a Linear Function Is a Rule for Which Each Unit 1 Change in Input Produces a Constant Change in Output
Lesson 1.2 – Linear Functions y m A linear function is a rule for which each unit 1 change in input produces a constant change in output. m 1 The constant change is called the slope and is usually m 1 denoted by m. x 0 1 2 3 4 Slope formula: If (x1, y1)and (x2 , y2 ) are any two distinct points on a line, then the slope is rise y y y m 2 1 . (An average rate of change!) run x x x 2 1 Equations for lines: Slope-intercept form: y mx b m is the slope of the line; b is the y-intercept (i.e., initial value, y(0)). Point-slope form: y y0 m(x x0 ) m is the slope of the line; (x0, y0 ) is any point on the line. Domain: All real numbers. Graph: A line with no breaks, jumps, or holes. (A graph with no breaks, jumps, or holes is said to be continuous. We will formally define continuity later in the course.) A constant function is a linear function with slope m = 0. The graph of a constant function is a horizontal line, and its equation has the form y = b. A vertical line has equation x = a, but this is not a function since it fails the vertical line test. Notes: 1. A positive slope means the line is increasing, and a negative slope means it is decreasing. 2. If we walk from left to right along a line passing through distinct points P and Q, then we will experience a constant steepness equal to the slope of the line. -

9 Power and Polynomial Functions
Arkansas Tech University MATH 2243: Business Calculus Dr. Marcel B. Finan 9 Power and Polynomial Functions A function f(x) is a power function of x if there is a constant k such that f(x) = kxn If n > 0, then we say that f(x) is proportional to the nth power of x: If n < 0 then f(x) is said to be inversely proportional to the nth power of x. We call k the constant of proportionality. Example 9.1 (a) The strength, S, of a beam is proportional to the square of its thickness, h: Write a formula for S in terms of h: (b) The gravitational force, F; between two bodies is inversely proportional to the square of the distance d between them. Write a formula for F in terms of d: Solution. 2 k (a) S = kh ; where k > 0: (b) F = d2 ; k > 0: A power function f(x) = kxn , with n a positive integer, is called a mono- mial function. A polynomial function is a sum of several monomial func- tions. Typically, a polynomial function is a function of the form n n−1 f(x) = anx + an−1x + ··· + a1x + a0; an 6= 0 where an; an−1; ··· ; a1; a0 are all real numbers, called the coefficients of f(x): The number n is a non-negative integer. It is called the degree of the polynomial. A polynomial of degree zero is just a constant function. A polynomial of degree one is a linear function, of degree two a quadratic function, etc. The number an is called the leading coefficient and a0 is called the constant term. -

Polynomials.Pdf
POLYNOMIALS James T. Smith San Francisco State University For any real coefficients a0,a1,...,an with n $ 0 and an =' 0, the function p defined by setting n p(x) = a0 + a1 x + AAA + an x for all real x is called a real polynomial of degree n. Often, we write n = degree p and call an its leading coefficient. The constant function with value zero is regarded as a real polynomial of degree –1. For each n the set of all polynomials with degree # n is closed under addition, subtraction, and multiplication by scalars. The algebra of polynomials of degree # 0 —the constant functions—is the same as that of real num- bers, and you need not distinguish between those concepts. Polynomials of degrees 1 and 2 are called linear and quadratic. Polynomial multiplication Suppose f and g are nonzero polynomials of degrees m and n: m f (x) = a0 + a1 x + AAA + am x & am =' 0, n g(x) = b0 + b1 x + AAA + bn x & bn =' 0. Their product fg is a nonzero polynomial of degree m + n: m+n f (x) g(x) = a 0 b 0 + AAA + a m bn x & a m bn =' 0. From this you can deduce the cancellation law: if f, g, and h are polynomials, f =' 0, and fg = f h, then g = h. For then you have 0 = fg – f h = f ( g – h), hence g – h = 0. Note the analogy between this wording of the cancellation law and the corresponding fact about multiplication of numbers. One of the most useful results about integer multiplication is the unique factoriza- tion theorem: for every integer f > 1 there exist primes p1 ,..., pm and integers e1 em e1 ,...,em > 0 such that f = pp1 " m ; the set consisting of all pairs <pk , ek > is unique. -

Real Zeros of Polynomial Functions
333353_0200.qxp 1/11/07 2:00 PM Page 91 Polynomial and Chapter 2 Rational Functions y y y 2.1 Quadratic Functions 2 2 2 2.2 Polynomial Functions of Higher Degree x x x −44−2 −44−2 −44−2 2.3 Real Zeros of Polynomial Functions 2.4 Complex Numbers 2.5 The Fundamental Theorem of Algebra Polynomial and rational functions are two of the most common types of functions 2.6 Rational Functions and used in algebra and calculus. In Chapter 2, you will learn how to graph these types Asymptotes of functions and how to find the zeros of these functions. 2.7 Graphs of Rational Functions 2.8 Quadratic Models David Madison/Getty Images Selected Applications Polynomial and rational functions have many real-life applications. The applications listed below represent a small sample of the applications in this chapter. ■ Automobile Aerodynamics, Exercise 58, page 101 ■ Revenue, Exercise 93, page 114 ■ U.S. Population, Exercise 91, page 129 ■ Impedance, Exercises 79 and 80, page 138 ■ Profit, Exercise 64, page 145 ■ Data Analysis, Exercises 41 and 42, page 154 ■ Wildlife, Exercise 43, page 155 ■ Comparing Models, Exercise 85, page 164 ■ Media, Aerodynamics is crucial in creating racecars.Two types of racecars designed and built Exercise 18, page 170 by NASCAR teams are short track cars, as shown in the photo, and super-speedway (long track) cars. Both types of racecars are designed either to allow for as much downforce as possible or to reduce the amount of drag on the racecar. 91 333353_0201.qxp 1/11/07 2:02 PM Page 92 92 Chapter 2 Polynomial and Rational Functions 2.1 Quadratic Functions The Graph of a Quadratic Function What you should learn Analyze graphs of quadratic functions. -

1.1 Logic 1.1.1
Section 1.1 Logic 1.1.1 1.1 LOGIC Mathematics is used to predict empirical reality, and is therefore the foundation of engineering. Logic gives precise meaning to mathematical statements. PROPOSITIONS def: A proposition is a statement that is either true (T) or false (F), but not both. Example 1.1.1: 1+1=2.(T) 2+2=5.(F) Example 1.1.2: A fact-based declaration is a proposition, even if no one knows whether it is true. 11213 is prime. 1isprime. There exists an odd perfect number. Coursenotes by Prof. Jonathan L. Gross for use with Rosen: Discrete Math and Its Applic., 5th Ed. Chapter 1 FOUNDATIONS 1.1.2 Example 1.1.3: Logical analysis of rhetoric begins with the modeling of fact-based natural language declarations by propositions. Portland is the capital of Oregon. Columbia University was founded in 1754 by Romulus and Remus. If 2+2 = 5, then you are the pope. (a conditional fact-based declaration). Example 1.1.4: A statement cannot be true or false unless it is declarative. This excludes commands and questions. Go directly to jail. What time is it? Example 1.1.5: Declarations about semantic tokens of non-constant value are NOT proposi- tions. x+2=5. Coursenotes by Prof. Jonathan L. Gross for use with Rosen: Discrete Math and Its Applic., 5th Ed. Section 1.1 Logic 1.1.3 TRUTH TABLES def: The boolean domain is the set {T,F}. Either of its elements is called a boolean value. An n-tuple (p1,...,pn)ofboolean values is called a boolean n-tuple. -

Exclusive Or from Wikipedia, the Free Encyclopedia
New features Log in / create account Article Discussion Read Edit View history Exclusive or From Wikipedia, the free encyclopedia "XOR" redirects here. For other uses, see XOR (disambiguation), XOR gate. Navigation "Either or" redirects here. For Kierkegaard's philosophical work, see Either/Or. Main page The logical operation exclusive disjunction, also called exclusive or (symbolized XOR, EOR, Contents EXOR, ⊻ or ⊕, pronounced either / ks / or /z /), is a type of logical disjunction on two Featured content operands that results in a value of true if exactly one of the operands has a value of true.[1] A Current events simple way to state this is "one or the other but not both." Random article Donate Put differently, exclusive disjunction is a logical operation on two logical values, typically the values of two propositions, that produces a value of true only in cases where the truth value of the operands differ. Interaction Contents About Wikipedia Venn diagram of Community portal 1 Truth table Recent changes 2 Equivalencies, elimination, and introduction but not is Contact Wikipedia 3 Relation to modern algebra Help 4 Exclusive “or” in natural language 5 Alternative symbols Toolbox 6 Properties 6.1 Associativity and commutativity What links here 6.2 Other properties Related changes 7 Computer science Upload file 7.1 Bitwise operation Special pages 8 See also Permanent link 9 Notes Cite this page 10 External links 4, 2010 November Print/export Truth table on [edit] archived The truth table of (also written as or ) is as follows: Venn diagram of Create a book 08-17094 Download as PDF No. -

Chapter 1 Linear Functions
Chapter 1 Linear Functions 11 Sec. 1.1: Slopes and Equations of Lines Date Lines play a very important role in Calculus where we will be approximating complicated functions with lines. We need to be experts with lines to do well in Calculus. In this section, we review slope and equations of lines. Slope of a Line: The slope of a line is defined as the vertical change (the \rise") over the horizontal change (the \run") as one travels along the line. In symbols, taking two different points (x1; y1) and (x2; y2) on the line, the slope is Change in y ∆y y − y m = = = 2 1 : Change in x ∆x x2 − x1 Example: World milk production rose at an approximately constant rate between 1996 and 2003 as shown in the following graph: where M is in million tons and t is the years since 1996. Estimate the slope and interpret it in terms of milk production. 12 Clicker Question 1: Find the slope of the line through the following pair of points (−2; 11) and (3; −4): The slope is (A) Less than -2 (B) Between -2 and 0 (C) Between 0 and 2 (D) More than 2 (E) Undefined It will be helpful to recall the following facts about intercepts. Intercepts: x-intercepts The points where a graph touches the x-axis. If we have an equation, we can find them by setting y = 0. y-intercepts The points where a graph touches the y-axis. If we have an equation, we can find them by setting x = 0. -

Technology Mapping for Vlsi Circuits Exploiting Boolean Properties and Operations
TECHNOLOGY MAPPING FOR VLSI CIRCUITS EXPLOITING BOOLEAN PROPERTIES AND OPERATIONS disserttion sumi ttedtothe deprtmentofeletrilengi neering ndtheommitteeongrdutestudies ofstnforduniversi ty in prtilfulfillmentoftherequirements forthedegreeof dotorofphilosophy By Fr´ed´eric Mailhot December 1991 c Copyright 1991 by Fr´ed´eric Mailhot ii I certify that I have read this thesis and that in my opinion it is fully adequate, in scope and in quality, as a dissertation for the degree of Doctor of Philosophy. Giovanni De Micheli (Principal Advisor) I certify that I have read this thesis and that in my opinion it is fully adequate, in scope and in quality, as a dissertation for the degree of Doctor of Philosophy. Mark A. Horowitz I certify that I have read this thesis and that in my opinion it is fully adequate, in scope and in quality, as a dissertation for the degree of Doctor of Philosophy. Robert W. Dutton Approved for the University Committee on Graduate Stud- ies: Dean of Graduate Studies & Research iii Abstract Automatic synthesis of digital circuits has gained increasing importance. The synthesis process consists of transforming an abstract representation of a system into an implemen- tation in a target technology. The set of transformations has traditionally been broken into three steps: high-level synthesis, logic synthesis and physical design. This dissertation is concerned with logic synthesis. More specifically, we study tech- nology mapping, which is the link between logic synthesis and physical design. The object of technology mapping is to transform a technology-independent logic description into an implementation in a target technology. One of the key operations during tech- nology mapping is to recognize logic equivalence between a portion of the initial logic description and an element of the target technology. -

Second-Order Differential Equations
MST224 Mathematical methods Second-order differential equations This publication forms part of an Open University module. Details of this and other Open University modules can be obtained from the Student Registration and Enquiry Service, The Open University, PO Box 197, Milton Keynes MK7 6BJ, United Kingdom (tel. +44 (0)845 300 6090; email [email protected]). Alternatively, you may visit the Open University website at www.open.ac.uk where you can learn more about the wide range of modules and packs offered at all levels by The Open University. To purchase a selection of Open University materials visit www.ouw.co.uk, or contact Open University Worldwide, Walton Hall, Milton Keynes MK7 6AA, United Kingdom for a brochure (tel. +44 (0)1908 858779; fax +44 (0)1908 858787; email [email protected]). Note to reader Mathematical/statistical content at the Open University is usually provided to students in printed books, with PDFs of the same online. This format ensures that mathematical notation is presented accurately and clearly. The PDF of this extract thus shows the content exactly as it would be seen by an Open University student. Please note that the PDF may contain references to other parts of the module and/or to software or audio-visual components of the module. Regrettably mathematical and statistical content in PDF files is unlikely to be accessible using a screenreader, and some OpenLearn units may have PDF files that are not searchable. You may need additional help to read these documents. The Open University, Walton Hall, Milton Keynes, MK7 6AA. -

Boolean.Py Documentation Release 3.2
boolean.py Documentation Release 3.2 Sebastian Krämer Aug 06, 2018 Contents 1 User Guide 1 1.1 Introduction...............................................1 1.2 Installation................................................2 1.3 Creating boolean expressions......................................2 1.4 Evaluation of expressions........................................2 1.5 Equality of expressions..........................................3 1.6 Analyzing a boolean expression.....................................4 1.7 Using boolean.py to define your own boolean algebra.........................5 2 Concepts and Definitions 7 2.1 Basic Definitions.............................................7 2.2 Laws...................................................9 3 Development Guide 13 3.1 Testing.................................................. 13 3.2 Classes Hierarchy............................................ 14 3.3 Class creation............................................... 14 3.4 Class initialization............................................ 14 3.5 Ordering................................................. 14 3.6 Parsing.................................................. 15 4 Acknowledgments 17 i ii CHAPTER 1 User Guide This document provides an introduction on boolean.py usage. It requires that you are already familiar with Python and know a little bit about boolean algebra. All definitions and laws are stated in Concepts and Definitions. Contents • User Guide – Introduction – Installation – Creating boolean expressions – Evaluation of expressions – Equality -

MAT 4810: Calculus for Elementary and Middle School Teachers MAT 4810: Calculus
MAT 4810: Calculus for Elementary and Middle School Teachers MAT 4810: Calculus Computing for Elementary and Middle School Teachers Derivatives & Integrals Part I Charles Delman Computing Derivatives & Integrals The Definition Part I & Meaning of the Derivative Function Local Charles Delman Coordinates Computing Derivatives of More Complicated October 17, 2016 Functions Believe You Can Solve Problems Without Being Told How! MAT 4810: Calculus for Elementary and Middle School Teachers I would like to share the following words from the introduction to Don Cohen's book. I hope you will take the attitude they Computing Derivatives & express to heart and share it with your own students. Integrals Part I Charles \You can do it! You must tell yourself that. Don't think Delman because you haven't done a problem before, that you can't do The Definition & Meaning of it, or that someone else must show you how to do it first (a the Derivative Function myth some people want to use to keep others in ignorance). Local You can do it! Don't be afraid. You've learned how to do the Coordinates hardest things you'll ever do, walking and talking { mostly by Computing Derivatives of yourself. This stuff is much easier!" More Complicated Functions Recall: Linear Rates of Change MAT 4810: Calculus for Elementary and Middle School Teachers mi To travel at 60 miles per hour ( h ) is to travel a distance Computing Derivatives & of 60∆t miles in ∆t hours: ∆d = 60∆t, where d is Integrals Part I distance in miles and t is time in hours; ∆d and ∆t are Charles the changes in these quantities, respectively. -

Linear and Quadratic Functions
Chapter 2 Linear and Quadratic Functions 2.1 Linear Functions We now begin the study of families of functions. Our first family, linear functions, are old friends as we shall soon see. Recall from Geometry that two distinct points in the plane determine a unique line containing those points, as indicated below. P (x0; y0) Q (x1; y1) To give a sense of the `steepness' of the line, we recall that we can compute the slope of the line using the formula below. Equation 2.1. The slope m of the line containing the points P (x0; y0) and Q (x1; y1) is: y − y m = 1 0 ; x1 − x0 provided x1 =6 x0. A couple of notes about Equation 2.1 are in order. First, don't ask why we use the letter `m' to represent slope. There are many explanations out there, but apparently no one really knows for 1 sure. Secondly, the stipulation x1 =6 x0 ensures that we aren't trying to divide by zero. The reader is invited to pause to think about what is happening geometrically; the anxious reader can skip along to the next example. Example 2.1.1. Find the slope of the line containing the following pairs of points, if it exists. Plot each pair of points and the line containing them. 1See www.mathforum.org or www.mathworld.wolfram.com for discussions on this topic. 152 Linear and Quadratic Functions 1. P (0; 0), Q(2; 4) 2. P (−1; 2), Q(3; 4) 3. P (−2; 3), Q(2; −3) 4.