Assessing Vowel Quality for Singing Evaluation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Kevin Koga CS465 9/5/08 Final Project Proposal (First Draft, First Idea)
Kevin Koga CS465 9/5/08 Final Project Proposal (First Draft, First Idea) Inspiration: The idea for my project was inspired by guitar hero. In guitar hero, players press buttons in time with a visual display of corresponding buttons and an audio track. Correctly pressing buttons scores you points, and you hear the guitar portion of the audio track. As someone who can actually read music, guitar hero always seemed too easy to me. Obviously the game is designed so that anyone can play it; even if they’ve never before seen written music. I was thinking about how Guitar Hero was eventually expanded to make Rock Band. I thought of how revolutionary those games have been. And my idea then occurred to me. Idea: When people learn to sight-sing music, the only feedback they have is their own ear. If you sing the wrong note, it sounds wrong. With the voice, there is no integral number of notes: no fingerings like on a trumpet, no frets like on a guitar. With voice, as with fretless string instruments such as violin or cello, you could be missing the note by only a quarter-step or less. To a trained ear, this makes a big difference. So I thought, why not add visual feedback? A microphone could be connected to a computer measuring frequency data in real time. The frequency or pitch of the note played or sung could move a cursor on the screen up or down. The cursor could sit atop musical staff, and point to the current note being played. -

From an Ethnic Island to a Transnational Bubble: a Reflection on Korean Americans in Los Angeles
Asian and Asian American Studies Faculty Works Asian and Asian American Studies 2012 From an Ethnic Island to a Transnational Bubble: A Reflection on Korean Americans in Los Angeles Edward J.W. Park Loyola Marymount University, [email protected] Follow this and additional works at: https://digitalcommons.lmu.edu/aaas_fac Part of the East Asian Languages and Societies Commons Recommended Citation Edward J.W. Park (2012) From an Ethnic Island to a Transnational Bubble: A Reflection on orK ean Americans in Los Angeles, Amerasia Journal, 38:1, 43-47. This Article is brought to you for free and open access by the Asian and Asian American Studies at Digital Commons @ Loyola Marymount University and Loyola Law School. It has been accepted for inclusion in Asian and Asian American Studies Faculty Works by an authorized administrator of Digital Commons@Loyola Marymount University and Loyola Law School. For more information, please contact [email protected]. From an Ethnic Island to a Transnational Bubble Transnational a to Island an Ethnic From So much more could be said in reflecting on Sa-I-Gu. My main goal in this brief essay has simply been to limn the ways in which the devastating fires of Sa-I-Gu have produced a loamy and fecund soil for personal discovery, community organizing, political mobilization, and, ultimately, a remaking of what it means to be Korean and Asian in the United States. From an Ethnic Island to a Transnational Bubble: A Reflection on Korean Americans in Los Angeles Edward J.W. Park EDWARD J.W. PARK is director and professor of Asian Pacific American Studies at Loyola Marymount University in Los Angeles. -

Access All Areas? the Evolution of Singstar from the PS2 to PS3 Platform
This may be the author’s version of a work that was submitted/accepted for publication in the following source: Fletcher, Gordon, Light, Ben, & Ferneley, Elaine (2008) Access all areas? The evolution of SingStar from the PS2 to PS3 platform. In Loader, B (Ed.) Internet Research 9.0: Rethinking Community, Rethink- ing Space (2008) - 9th Annual Conference of the Association of Internet Researchers. Association of Internet Researchers, Denmark, pp. 1-13. This file was downloaded from: https://eprints.qut.edu.au/75684/ c Copyright 2008 the authors This work is covered by copyright. Unless the document is being made available under a Creative Commons Licence, you must assume that re-use is limited to personal use and that permission from the copyright owner must be obtained for all other uses. If the docu- ment is available under a Creative Commons License (or other specified license) then refer to the Licence for details of permitted re-use. It is a condition of access that users recog- nise and abide by the legal requirements associated with these rights. If you believe that this work infringes copyright please provide details by email to [email protected] Notice: Please note that this document may not be the Version of Record (i.e. published version) of the work. Author manuscript versions (as Sub- mitted for peer review or as Accepted for publication after peer review) can be identified by an absence of publisher branding and/or typeset appear- ance. If there is any doubt, please refer to the published source. Access All Areas? The -

Karaoke Catalog Updated On: 11/01/2019 Sing Online on in English Karaoke Songs
Karaoke catalog Updated on: 11/01/2019 Sing online on www.karafun.com In English Karaoke Songs 'Til Tuesday What Can I Say After I Say I'm Sorry The Old Lamplighter Voices Carry When You're Smiling (The Whole World Smiles With Someday You'll Want Me To Want You (H?D) Planet Earth 1930s Standards That Old Black Magic (Woman Voice) Blackout Heartaches That Old Black Magic (Man Voice) Other Side Cheek to Cheek I Know Why (And So Do You) DUET 10 Years My Romance Aren't You Glad You're You Through The Iris It's Time To Say Aloha (I've Got A Gal In) Kalamazoo 10,000 Maniacs We Gather Together No Love No Nothin' Because The Night Kumbaya Personality 10CC The Last Time I Saw Paris Sunday, Monday Or Always Dreadlock Holiday All The Things You Are This Heart Of Mine I'm Not In Love Smoke Gets In Your Eyes Mister Meadowlark The Things We Do For Love Begin The Beguine 1950s Standards Rubber Bullets I Love A Parade Get Me To The Church On Time Life Is A Minestrone I Love A Parade (short version) Fly Me To The Moon 112 I'm Gonna Sit Right Down And Write Myself A Letter It's Beginning To Look A Lot Like Christmas Cupid Body And Soul Crawdad Song Peaches And Cream Man On The Flying Trapeze Christmas In Killarney 12 Gauge Pennies From Heaven That's Amore Dunkie Butt When My Ship Comes In My Own True Love (Tara's Theme) 12 Stones Yes Sir, That's My Baby Organ Grinder's Swing Far Away About A Quarter To Nine Lullaby Of Birdland Crash Did You Ever See A Dream Walking? Rags To Riches 1800s Standards I Thought About You Something's Gotta Give Home Sweet Home -

Encoremanual UKV.Pdf
Contents GETTING STARTED 2 Wii MENU UPDATE 2 SETTING UP 4 PLAYING THE GAME 4 THE GAME SCREEN 5 SONG SELECTION 7 PARTY MODE 9 SOLO MODE 11 LESSONS 11 AWARDS 12 KARAOKE 12 JUKEBOX 12 CHARTS 12 OPTIONS 12 PAUSE MENU 13 RESULTS 15 CREDITS 16 MUSIC CREDITS 17 1 Getting Started Insert the We Sing Encore Disc into the Disc Slot. The WiiTM console will switch on. The Health and Safety Screen, as shown here, will be displayed. After reading the details press the A Button. The Health and Safety Screen will be displayed even if the Disc is inserted after turning the Wii console’s power on. Point at the Disc Channel from the Wii Menu Screen and press the A Button. The Channel Preview Screen will be displayed. Point at START and press the A Button. The Wii RemoteTM Wrist Strap Information Screen will be displayed. Tighten the strap around your wrist, then press the A Button. The opening movie will then begin to play. CAUTION – USE THE Wii REMOTE WRIST STRAP For information on how to use the Wii Remote Wrist Strap refer to the Wii Operations Manual – System Setup (Using the Wii Remote). The in-game language depends on the one that is set on your Wii console. This game includes five different language versions: English, German, French, Spanish and Italian. If your Wii console is already set to one of them, the same language will be displayed in the game. If your Wii console is set to a different language than those available in the game, the in-game default language will be English. -

Full Text (PDF)
CHI 2007 Workshop on Vocal Interaction in Assistive Technologies and Games (CHI 2007), San Jose, CA, USA, April 29 – May 3 Teaching a Music Search Engine Through Play Bryan Pardo David A. Shamma EECS, Northwestern University Yahoo! Research Berkeley Ford Building, Room 3-323, 2133 Sheridan Rd. 1950 University Ave, Suite 200 Evanston, IL, 60208, USA Berkeley, CA 94704 [email protected] [email protected] +1 (847) 491-7184 +1 (510) 704-2419 ABSTRACT include string alignment [1], n-grams [2], Markov models Systems able to find a song based on a sung, hummed, or [3], dynamic time warping [4] and earth mover distance [5]. whistled melody are called Query-By-Humming (QBH) These compare melodies transcribed from sung queries to systems. We propose an approach to improve search human-encoded symbolic music keys, such as MIDI files. performance of a QBH system based on data collected from an online social music game, Karaoke Callout. Users of Deployed QBH systems [6] have no provision for Karaoke Callout generate training data for the search automatically vetting search keys in the database for engine, allowing both ongoing personalization of query effectiveness. As melodic databases grow from thousands processing as well as vetting of database keys. to millions of entries, hand-vetting of keys will become Personalization of search engine user models takes place impractical. Current QBH systems also presume users through using sung examples generated in the course of singing styles will be similar to that of those the system was play to optimize parameters of user models. initially designed for. -
Up T Se at S R D Et Te G T G Ni E F Aok E Res Atu Ess Acc I Kar Ng
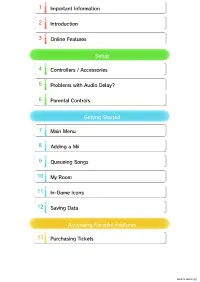
1 Importan t Informati on 2 Idntro unctio 3 Oinl ne Feusat re Setup 4 Controlle rs / Accessor ies 5 Proble ms w ith Audio Delay? 6 Parent al Contro ls Gtget in Srdta te 7 Mnai Muen 8 Agddin a Mii 9 Qunue ei go S ng s 10 My Room 11 Imn-Ga e Icons 12 Svna i g Daat Access ing Karaoke F eatu res 13 Purc has ing Ticke ts WUP-N-WAHP-00 Prod uct Inform ati on 14 Copyrigh t Informati on 15 Supp ort Inform ati on 1 Importan t Informati on Thank you for selecting Wii Karaoke U™ by JOYSOUND™ for Wii U™. This software is designed only for use with the European/Australian version of the Wii U console. Please read this manual carefully before using this software. If the software is to be used by young children, the manual should be read and explained to them by an adult. Before use, please also read the content of the Health and Safety Information application on the Wii U Menu. It contains important information that will help you enjoy this software. Language Selection This title supports five different languages: English, German, French, Spanish and Italian. If your Wii U console language is set to one of these, the same language will be displayed in the game. You can change the console language in System Settings. If your Wii U console is set to another language, you will be able to select the in- game language after launching the software. Age Rating Information For age rating information for this and other software, please consult the relevant website for the age rating system in your region. -

Karaoke: a Tool for Promoting Reading Abha Gupta Old Dominion University, [email protected]
Old Dominion University ODU Digital Commons Teaching & Learning Faculty Publications Teaching & Learning 2006 Karaoke: A Tool for Promoting Reading Abha Gupta Old Dominion University, [email protected] Follow this and additional works at: https://digitalcommons.odu.edu/teachinglearning_fac_pubs Part of the Educational Methods Commons Repository Citation Gupta, Abha, "Karaoke: A Tool for Promoting Reading" (2006). Teaching & Learning Faculty Publications. 2. https://digitalcommons.odu.edu/teachinglearning_fac_pubs/2 Original Publication Citation Gupta, A. (2006). Karaoke: A Tool for Promoting Reading. Reading Matrix: An International Online Journal, 6(2), 80-89. This Article is brought to you for free and open access by the Teaching & Learning at ODU Digital Commons. It has been accepted for inclusion in Teaching & Learning Faculty Publications by an authorized administrator of ODU Digital Commons. For more information, please contact [email protected]. 80 The Reading Matrix Vol. 6, No. 2, September 2006 KARAOKE: A TOOL FOR PROMOTING READING Abha Gupta [email protected] Abstract ________________ This article is a description of a teaching strategy that we have experimented with promising results as a motivational tool. The strategy uses Karaoke as a tool to build and enhance reading behaviors such as fluency and motivation as a twofold purpose for struggling readers. An audio and video sample of children engaged in reading and singing using Karaoke is enclosed. Some modified Karaoke instructional approaches are mentioned for a whole group / classroom use. _______________ Introduction Five-year old Kindergartner, Eesha comes home from the bus-stop and talks excitedly about Britney Spears as her favorite singer and starts to sing, “Oops, I did it again!” She had heard about the singer in the school bus where apparently, most kids were into “Britney Spears”. -

Siglos Karaoke Professional
User's Guide Siglos Karaoke Professional © 2020 Doblon Contents Chapter 1 1 Introduction 2 Professional mode 2 Quick start 10 Song database 15 Adding singers 18 Playback management 22 Fill-in playlist 23 Remote access 32 Basic mode 32 Quick start (basic mode) 34 Playing 37 Recording 41 Using playlists 43 Main window controls 43 Getting karaoke songs 44 Settings 44 Display 45 Recording 46 CD 46 General 46 Skins 46 KJ 50 Keyboard shortcuts 50 Supported file types 51 Troubleshooting 52 Unlocking and evaluation 2 Introduction 1 Thank you for choosing Siglos Karaoke Professional. Siglos Karaoke Professional is a karaoke show manager that allows you to keep song database, and helps to run karaoke shows by the means managing singers, songs, and rotation. Siglos Karaoke Professional is also an advanced karaoke player that can play karaoke songs in various formats (including CD+G and MIDI Karaoke) and record your voice while you sing along. The program has two modes of operation -- professional and basic. Professional mode should be used when running a show, while basic mode is for everyday use. To switch the mode go to Settings dialog box, select KJ section, and change Use professional KJ mode option. Siglos Karaoke Professional has been designed to be as simple as possible -- it uses graphical interface that any computer user should be familiar with. To learn more about Siglos Karaoke Professional features select one of the topics below: Professional mode: Quick start Song database Adding singers Playback management Fill-in playlist Basic mode: Quick start Playing karaoke songs Recording your singing Using playlists Common topics: Main window controls Adjusting settings Chapter 1 Introduction 1 Introduction 1 Keyboard shortcuts Troubleshooting Unlocking and evaluation Professional mode Quick start Importing songs The first thing you need to do before you use Siglos Karaoke Professional to run your karaoke show is creating a database of songs. -

NES Specifications
Everynes - Nocash NES Specs Everynes Hardware Specifications Tech Data Memory Maps I/O Map Picture Processing Unit (PPU) Audio Processing Unit (APU) Controllers Cartridges and Mappers Famicom Disk System (FDS) Hardware Pin-Outs CPU 65XX Microprocessor About Everynes Tech Data Overall Specs CPU 2A03 - customized 6502 CPU - audio - does not contain support for decimal The NTSC NES runs at 1.7897725MHz, and 1.7734474MHz for PAL. NMIs may be generated by PPU each VBlank. IRQs may be generated by APU and by external hardware. Internal Memory: 2K WRAM, 2K VRAM, 256 Bytes SPR-RAM, and Palette/Registers The cartridge connector also passes audio in and out of the cartridge, to allow for external sound chips to be mixed in with the Famicom audio. Original Famicom (Family Computer) (1983) (Japan) 60-pin cartridge slot, with external sound-input, without lockout chip. Two joypads directly attached to console, Joypad 1 with Start/Select buttons, Joypad 2 with microphone, but without Start/Select. 15pin Expansion port for further controllers. Video RF-Output only. "During its first year, people found the Famicom to be unreliable, with programming errors and freezing rampant. Yamauchi recalled all sold Famicom systems, and put the Famicom out of production until the errors were fixed. The Famicom was re-released with a new motherboard." Original NES (Nintendo Entertainment System) (1985) (US, Europe, Australia) Same as Famicom, but with slightly different pin-outs on cartridge slot, and controllers/expansion ports: Front-loading 72-pin cartridge slot, without external sound-input on cartridge slot, without microphone on joypads, with lockout chip. Newer Famicom, AV Famicom (1993-1995) 60-pin cartridge slot, with external sound-input, without lockout chip. -

Beverly Hot Springs Development Or User Opportunity
BEVERLY BLVD OAKWOOD AVE N OXFORD AVE BEVERLY HOT SPRINGS DEVELOPMENT OR USER OPPORTUNITY KIDDER.COM OFFERING MEMORANDUM | 308 N OXFORD AVE | LOS ANGELES, CA TABLE OF 01 OFFERING SUMMARY The Offering Opportunity CONTENTS Property Photos Metro Map 02 MARKET OVERVIEW Koreatown Overview Koreatown Attractions Notable Sites EXCLUSIVELY LISTED BY Accessibility CHARLES DESANTIS JOHNNY CHOI Executive Vice President Vice President 310.996.2232 310.550.2526 [email protected] [email protected] LIC N° 00961029 LIC N° 01705079 The information contained in the following Marketing Brochure is proprietary and strictly confidential. It is intended to be reviewed only by the party receiving it from Kidder Mathews and should not be made available to any other person or entity without the written consent of Kidder Mathews. This Marketing Brochure has been prepared to provide summary, unverified information to prospective purchasers, and to establish only a preliminary level of interest in the subject property. The information contained herein is not a substitute for a thorough due diligence investigation. Kidder Mathews has not made any investigation, and makes no warranty or representation, with respect to the income or expenses for the subject property, the future projected financial performance of the property, the size and square footage of the property and improvements, the presence or absence of contaminating substances, PCB’s or asbestos, the compliance with State and Federal regulations, the physical condition of the improvements thereon, or the financial condition or business prospects of any tenant, or any tenant’s plans or intentions to continue its occupancy of the subject property. -

CD-I FAQ 2000 Edition Revised February 21, 2001
CD-i FAQ 2000 Edition Revised February 21, 2001 CD-i FAQ 2000 Edition Revised February 21, 2001 PDF Version 2.0 Published by The New International CD-i Association www.icdia.org Copyright 2001 Jorg Kennis All rights reserved The latest version of this FAQ can always be found at http://www.icdia.org Please contact the author with questions or remarks: [email protected] You may publish this document on other websites, provided that it is complete and unmodified. Please notify the author when you include this document on other websites. Latest version and more CD-i info: http://www.icdia.org 1 CD-i FAQ 2000 Edition Revised February 21, 2001 Contents 0. About this CD-i FAQ 0.1 What's the goal of this FAQ? 0.2 Who wrote it and who maintains it? 0.3 Who helped along the sidelines? 0.4 How can I contact the author? 0.5 What's the official status of this FAQ? 1. The CD-i System 1.1 What is CD-i? 1.2 Who invented CD-i? 1.3 Is CD-i propietary? 1.4 What is the Green Book? 1.5 What versions of the Green Book are available? 1.6 Where can I get the licenses? 1.7 Will any CD-i disc play on any CD-i player? 1.8 What's a Base Case player and a Base Case disc? 1.9 Does CD-i support full-screen moving video? 1.10 What disc types can be played on a CD-i player? 1.11 What are the advantages of CD-i over PC-based interactive systems? 1.12 How is CD-i related to other TV-based interactive systems? 1.13 What is the official CD-i logo? 1.14 What is the correct way of writing CD-i? 2.