Light Field Analysis and Its Applications In
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Breaking Down the “Cosine Fourth Power Law”
Breaking Down The “Cosine Fourth Power Law” By Ronian Siew, inopticalsolutions.com Why are the corners of the field of view in the image captured by a camera lens usually darker than the center? For one thing, camera lenses by design often introduce “vignetting” into the image, which is the deliberate clipping of rays at the corners of the field of view in order to cut away excessive lens aberrations. But, it is also known that corner areas in an image can get dark even without vignetting, due in part to the so-called “cosine fourth power law.” 1 According to this “law,” when a lens projects the image of a uniform source onto a screen, in the absence of vignetting, the illumination flux density (i.e., the optical power per unit area) across the screen from the center to the edge varies according to the fourth power of the cosine of the angle between the optic axis and the oblique ray striking the screen. Actually, optical designers know this “law” does not apply generally to all lens conditions.2 – 10 Fundamental principles of optical radiative flux transfer in lens systems allow one to tune the illumination distribution across the image by varying lens design characteristics. In this article, we take a tour into the fascinating physics governing the illumination of images in lens systems. Relative Illumination In Lens Systems In lens design, one characterizes the illumination distribution across the screen where the image resides in terms of a quantity known as the lens’ relative illumination — the ratio of the irradiance (i.e., the power per unit area) at any off-axis position of the image to the irradiance at the center of the image. -

Geometrical Irradiance Changes in a Symmetric Optical System
Geometrical irradiance changes in a symmetric optical system Dmitry Reshidko Jose Sasian Dmitry Reshidko, Jose Sasian, “Geometrical irradiance changes in a symmetric optical system,” Opt. Eng. 56(1), 015104 (2017), doi: 10.1117/1.OE.56.1.015104. Downloaded From: https://www.spiedigitallibrary.org/journals/Optical-Engineering on 11/28/2017 Terms of Use: https://www.spiedigitallibrary.org/terms-of-use Optical Engineering 56(1), 015104 (January 2017) Geometrical irradiance changes in a symmetric optical system Dmitry Reshidko* and Jose Sasian University of Arizona, College of Optical Sciences, 1630 East University Boulevard, Tucson 85721, United States Abstract. The concept of the aberration function is extended to define two functions that describe the light irra- diance distribution at the exit pupil plane and at the image plane of an axially symmetric optical system. Similar to the wavefront aberration function, the irradiance function is expanded as a polynomial, where individual terms represent basic irradiance distribution patterns. Conservation of flux in optical imaging systems is used to derive the specific relation between the irradiance coefficients and wavefront aberration coefficients. It is shown that the coefficients of the irradiance functions can be expressed in terms of wavefront aberration coefficients and first- order system quantities. The theoretical results—these are irradiance coefficient formulas—are in agreement with real ray tracing. © 2017 Society of Photo-Optical Instrumentation Engineers (SPIE) [DOI: 10.1117/1.OE.56.1.015104] Keywords: aberration theory; wavefront aberrations; irradiance. Paper 161674 received Oct. 26, 2016; accepted for publication Dec. 20, 2016; published online Jan. 23, 2017. 1 Introduction the normalized field H~ and aperture ρ~ vectors. -

Nikon Binocular Handbook
THE COMPLETE BINOCULAR HANDBOOK While Nikon engineers of semiconductor-manufactur- FINDING THE ing equipment employ our optics to create the world’s CONTENTS PERFECT BINOCULAR most precise instrumentation. For Nikon, delivering a peerless vision is second nature, strengthened over 4 BINOCULAR OPTICS 101 ZOOM BINOCULARS the decades through constant application. At Nikon WHAT “WATERPROOF” REALLY MEANS FOR YOUR NEEDS 5 THE RELATIONSHIP BETWEEN POWER, Sport Optics, our mission is not just to meet your THE DESIGN EYE RELIEF, AND FIELD OF VIEW The old adage “the better you understand some- PORRO PRISM BINOCULARS demands, but to exceed your expectations. ROOF PRISM BINOCULARS thing—the more you’ll appreciate it” is especially true 12-14 WHERE QUALITY AND with optics. Nikon’s goal in producing this guide is to 6-11 THE NUMBERS COUNT QUANTITY COUNT not only help you understand optics, but also the EYE RELIEF/EYECUP USAGE LENS COATINGS EXIT PUPIL ABERRATIONS difference a quality optic can make in your appre- REAL FIELD OF VIEW ED GLASS AND SECONDARY SPECTRUMS ciation and intensity of every rare, special and daily APPARENT FIELD OF VIEW viewing experience. FIELD OF VIEW AT 1000 METERS 15-17 HOW TO CHOOSE FIELD FLATTENING (SUPER-WIDE) SELECTING A BINOCULAR BASED Nikon’s WX BINOCULAR UPON INTENDED APPLICATION LIGHT DELIVERY RESOLUTION 18-19 BINOCULAR OPTICS INTERPUPILLARY DISTANCE GLOSSARY DIOPTER ADJUSTMENT FOCUSING MECHANISMS INTERNAL ANTIREFLECTION OPTICS FIRST The guiding principle behind every Nikon since 1917 product has always been to engineer it from the inside out. By creating an optical system specific to the function of each product, Nikon can better match the product attri- butes specifically to the needs of the user. -

Technical Aspects and Clinical Usage of Keplerian and Galilean Binocular Surgical Loupe Telescopes Used in Dentistry Or Medicine
Surgical and Dental Ergonomic Loupes Magnification and Microscope Design Principles Technical Aspects and Clinical Usage of Keplerian and Galilean Binocular Surgical Loupe Telescopes used in Dentistry or Medicine John Mamoun, DMD1, Mark E. Wilkinson, OD2 , Richard Feinbloom3 1Private Practice, Manalapan, NJ, USA 2Clinical Professor of Opthalmology at the University of Iowa Carver College of Medicine, Department of Ophthalmology and Visual Sciences, Iowa City, IA, USA, and the director, Vision Rehabilitation Service, University of Iowa Carver Family Center for Macular Degeneration 3President, Designs for Vision, Inc., Ronkonkoma, NY Open Access Dental Lecture No.2: This Article is Public Domain. Published online, December 2013 Abstract Dentists often use unaided vision, or low-power telescopic loupes of 2.5-3.0x magnification, when performing dental procedures. However, some clinically relevant microscopic intra-oral details may not be visible with low magnification. About 1% of dentists use a surgical operating microscope that provides 5-20x magnification and co-axial illumination. However, a surgical operating microscope is not as portable as a surgical telescope, which are available in magnifications of 6-8x. This article reviews the technical aspects of the design of Galilean and Keplerian telescopic binocular loupes, also called telemicroscopes, and explains how these technical aspects affect the clinical performance of the loupes when performing dental tasks. Topics include: telescope lens systems, linear magnification, the exit pupil, the depth of field, the field of view, the image inverting Schmidt-Pechan prism that is used in the Keplerian telescope, determining the magnification power of lens systems, and the technical problems with designing Galilean and Keplerian loupes of extremely high magnification, beyond 8.0x. -
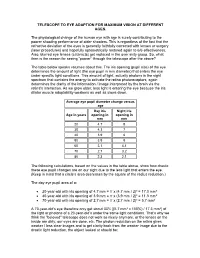
TELESCOPE to EYE ADAPTION for MAXIMUM VISION at DIFFERENT AGES. the Physiological Change of the Human Eye with Age Is Surely
TELESCOPE TO EYE ADAPTION FOR MAXIMUM VISION AT DIFFERENT AGES. The physiological change of the human eye with age is surely contributing to the poorer shooting performance of older shooters. This is regardless of the fact that the refractive deviation of the eyes is generally faithfully corrected with lenses or surgery (laser procedures) and hopefully optometrically restored again to 6/6 effectiveness. Also, blurred eye lenses (cataracts) get replaced in the over sixty group. So, what then is the reason for seeing “poorer” through the telescope after the above? The table below speaks volumes about this. The iris opening (pupil size) of the eye determines the amount of light (the eye pupil in mm diameter) that enters the eye under specific light conditions. This amount of light, actually photons in the sight spectrum that contains the energy to activate the retina photoreceptors, again determines the clarity of the information / image interpreted by the brain via the retina's interaction. As we grow older, less light is entering the eye because the iris dilator muscle adaptability weakens as well as slows down. Average eye pupil diameter change versus age Day iris Night iris Age in years opening in opening in mm mm 20 4.7 8 30 4.3 7 40 3.9 6 50 3.5 5 60 3.1 4.1 70 2.7 3.2 80 2.3 2.5 The following calculations, based on the values in the table above, show how drastic these eye pupil changes are on our sight due to the less light that enters the eye. -

Part 4: Filed and Aperture, Stop, Pupil, Vignetting Herbert Gross
Optical Engineering Part 4: Filed and aperture, stop, pupil, vignetting Herbert Gross Summer term 2020 www.iap.uni-jena.de 2 Contents . Definition of field and aperture . Numerical aperture and F-number . Stop and pupil . Vignetting Optical system stop . Pupil stop defines: 1. chief ray angle w 2. aperture cone angle u . The chief ray gives the center line of the oblique ray cone of an off-axis object point . The coma rays limit the off-axis ray cone . The marginal rays limit the axial ray cone stop pupil coma ray marginal ray y field angle image w u object aperture angle y' chief ray 4 Definition of Aperture and Field . Imaging on axis: circular / rotational symmetry Only spherical aberration and chromatical aberrations . Finite field size, object point off-axis: - chief ray as reference - skew ray bundels: y y' coma and distortion y p y'p - Vignetting, cone of ray bundle not circular O' field of marginal/rim symmetric view ray RAP' chief ray - to distinguish: u w' u' w tangential and sagittal chief ray plane O entrance object exit image pupil plane pupil plane 5 Numerical Aperture and F-number image . Classical measure for the opening: plane numerical aperture (half cone angle) object in infinity NA' nsinu' DEnP/2 u' . In particular for camera lenses with object at infinity: F-number f f F# DEnP . Numerical aperture and F-number are to system properties, they are related to a conjugate object/image location 1 . Paraxial relation F # 2n'tanu' . Special case for small angles or sine-condition corrected systems 1 F # 2NA' 6 Generalized F-Number . -

The F-Word in Optics
The F-word in Optics F-number, was first found for fixing photographic exposure. But F/number is a far more flexible phenomenon for finding facts about optics. Douglas Goodman finds fertile field for fixes for frequent confusion for F/#. The F-word of optics is the F-number,* also known as F/number, F/#, etc. The F- number is not a natural physical quantity, it is not defined and used consistently, and it is often used in ways that are both wrong and confusing. Moreover, there is no need to use the F-number, since what it purports to describe can be specified rigorously and unambiguously with direction cosines. The F-number is usually defined as follows: focal length F-number= [1] entrance pupil diameter A further identification is usually made with ray angle. Referring to Figure 1, a ray from an object at infinity that is parallel to the axis in object space intersects the front principal plane at height Y and presumably leaves the rear principal plane at the same height. If f is the rear focal length, then the angle of the ray in image space θ′' is given by y tan θ'= [2] f In this equation, as in the others here, a sign convention for angles heights and magnifications is not rigorously enforced. Combining these equations gives: 1 F−= number [3] 2tanθ ' For an object not at infinity, by analogy, the F-number is often taken to be the half of the inverse of the tangent of the marginal ray angle. However, Eq. 2 is wrong. -

6-1 Optical Instrumentation-Stop and Window.Pdf
6.6. OpticalOptical instrumentationinstrumentation Last chapter ¾ Chromatic Aberration ¾ Third-order (Seidel) Optical Aberrations Spherical aberrations, Coma, Astigmatism, Curvature of Field, Distortion This chapter ¾ Aperture stop, Entrance pupil, Exit pupil ¾ Field stop, Entrance window, Exit window Aperture effects on image ¾ Depth of field, Depth of focus ¾ prism and dispersion ¾ Camera ¾ Magnifier and eyepiece Optical instruments ¾ Microscope ¾ Telescope StopsStops inin OpticalOptical SystemsSystems Larger lens improves the brightness of the image Image of S Two lenses of the same formed at focal length (f), but the same diameter (D) differs place by both lenses SS’ Bundle of rays from S, imaged at S’ More light collected is larger for from S by larger larger lens lens StopsStops inin OpticalOptical SystemsSystems • Brightness of the image is determined primarily by the size of the bundle of rays collected by the system (from each object point) • Stops can be used to reduce aberrations StopsStops inin OpticalOptical SystemsSystems How much of the object we see is determined by: Field of View Q Q’ (not seen) Rays from Q do not pass through system We can only see object points closer to the axis of the system Thus, the Field of view is limited by the system ApertureAperture StopStop • A stop is an opening (despite its name) in a series of lenses, mirrors, diaphragms, etc. • The stop itself is the boundary of the lens or diaphragm • Aperture stop: that element of the optical system that limits the cone of light from any particular object point on the axis of the system ApertureAperture StopStop (AS)(AS) E O Diaphragm E Assume that the Diaphragm is the AS of the system Entrance Pupil (E P) Entrance Pupil (EnnP) The entrance pupil is defined to be the image of the aperture stop in all the lenses preceding it (i.e. -

Parallax Adjustment for Riflescopes
Parallax Adjustment For Riflescopes As applied to riflescopes, parallax can be defined as the apparent movement of objects within the field of view in relation to the reticle. Parallax occurs when the “primary image” of the object is formed either in front of, or behind the reticle. If the eye is moved from the optical axis of the scope, this also creates parallax. Parallax does not occur if the primary image is formed on the same focal plane as the reticle, or if the eye is positioned in the optical axis of the scope. Riflescopes with high magnification, or scopes for long-range shooting should be equipped with a parallax adjustment because even slight sighting errors can seriously affect sighting accuracy. By adjusting the objective part of the optical system the target can be brought in the exact focal plane of the reticle at any distance. Tactical style riflescopes do not usually have parallax adjustment because the exact range of the target can never be anticipated. Lower magnification scopes do not usually have parallax adjustment either since at lower powers the amount of parallax is very small and has little importance for practical, fast target sighting accuracy. Factors That Affect the Amount of Parallax in a Riflescope Two main factors that cause and affect the amount of parallax in a riflescope. First is the distance of the target to the objective lens of the riflescope. Since the reticle is in a fixed position within the riflescope housing, the image of the target doesn’t always appear positioned in the same plane as the reticle. -

Affect of Eye Pupil on Binocular Aperture by Ed Zarenski August 2004
Copyright (c) 2004 Cloudy Nights Telescope Reviews Affect of Eye Pupil on Binocular Aperture by Ed Zarenski August 2004 This information has been discussed before, elsewhere in other forums and also here in the CN binocular forum. However, the question keeps coming up and it is certainly worthwhile to document all of this in one complete discussion. In a telescope, you can vary the exit pupil by changing the eyepiece. In a fixed power binocular the exit pupil you purchase is the exit pupil you live with. The question answered here is this: What happens when your eye pupil is smaller than the binocular exit pupil? The implications are not at all intuitive, and certainly without explanation may not be clearly understood. There has been much prior debate over this issue, some of which I have participated in. Research, as always, provides some answers. Hopefully, this article will answer the question for you. Clear skies, and if not, Cloudy Nights Edz Aug. 2004 The author practices astronomy from his home in Cumberland, R. I. How big are your eye pupils? An important aspect to consider when choosing any binocular is the maximum dilation of your own eye pupils. Your own eyes may have a significant impact on the effective performance of a binocular. Depending on your desired use, failing to take maximum dilated eye pupil into consideration before you make your purchase may lead to an inappropriate choice. Exit pupil larger than eye pupil results in not realizing the maximum potential of the binocular. There are several simple methods to determine the size of you eye pupils. -

Precision Optics for Precision Shooting
PRECISION OPTICS FOR PRECISION SHOOTING Glass-etched illuminated reticles are standard with every Sand, dust, mud, heat and cold are a few of the environmental Nightforce scope. challenges every Nightforce scope faces in its development. Every aspect is thoroughly tested, proven, and tested again before we build a fi nal You cannot buy a higher quality rifl escope. product. Anything you can infl ict upon a scope, you can be certain we’ve already done it fi rst. That’s a strong claim, without a doubt. But, it’s a claim we can prove. And our customers do prove it…every The terms “rugged” and day, under some of the harshest, most unforgiving conditions on earth. “precision optics” are usually not compatible. Any optical We didn’t start building scopes and expect people to fi nd uses for instrument built to highly them. Instead, we looked at real-world needs. Needs that were not The spring that maintains exacting tolerances and absolute being met by other optics. And created, from the ground up, the pressure on our elevation and alignment is by its very nature a ultimate precision instrument for the intended application. windage adjustments spends delicate device. You can tell the difference the moment you pick one up. And if you two weeks in a polishing Not so with Nightforce. could look inside a Nightforce scope, the differences would be even tumbler before going into a The design of our scopes is Turret adjustments are made more obvious. Nightforce scope, to assure unique within the industry, with specially treated hardened Fortunately, just looking through one will tell you just about there are no rough spots or allowing us to combine optics metals, and advanced dry everything you need to know. -

Optics for Birding – the Basics
Optics for Birding – The Basics A Wisconsin Society for Ornithology Publicity Committee Fact Sheet Christine Reel – WSO Treasurer Arm yourself with a field guide and a binocular and you are ready to go birding. The binocular – a hand-held, double- barreled telescope – uses lenses and roof or porro prisms to magnify images generally between 6 and 12 times. Some birds are too distant for easy viewing with a binocular. At these times, a spotting scope – a single-barrel telescope with a magnification of generally 15 to 60 power using zoom or interchangeable fixed eyepieces – makes all the difference. Remember that a scope is not a substitute for a binocular, because it must be fitted to a tripod or another stabilizing device, and maneuverability and portability are limited. Optics shopping Buying a binocular or scope is a lot like buying a car: do some research, set some minimum standards, and then look at special features and options; also consider a number of choices and compare them. Keep in mind that there is no perfect binocular or scope, only one that is perfect for you. It must fit your hands, your face, your eyes, your size, and the way you bird. 1. Research. Plan to visit a local birding site or club meeting and ask a few birders what binoculars or scopes they prefer and why. Then choose a store or nature center that is geared toward birders and has a large selection of optics. Research the various specifications and what they mean to your birding experience (use this sheet as a starting point).