Royal Statistical Society)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

CONSULTATION REPORT Overview of Comments Received and Officer Responses
Transformation and Sustainability SHEFFIELD LOCAL PLAN (formerly Sheffield Development Framework) CONSULTATION REPORT Overview of comments received and officer responses ‘City Policies and Sites and Proposals Map Consultation Draft 2010’ (June – August 2010) ‘Additional Site Allocation Options’ (January – February 2012) Development Services Sheffield City Council Howden House 1 Union Street SHEFFIELD S1 2SH March 2013 CONTENTS Chapter Page 1. Introduction 1 2. The Consultations 2 3. Overall Results 5 4. Policy Comments 9 Economic Prosperity and Sustainable Employment 9 Serving the City Region 10 Attractive and Sustainable Neighbourhoods 10 Opportunities and Well-Being for All 13 Transport and Movement 14 Global Environment and Natural Resources 15 Green Environment 16 Character and Heritage 17 Areas that Look Good and Work Well 18 Land Uses in Policy Areas 19 5. Area Designations and Site Allocations Comments 21 Central Community Assembly Area 21 East Community Assembly Area 25 North East Community Assembly Area 30 South West Community Assembly Area 33 South Community Assembly Area 37 South East Community Assembly Area 41 Northern Community Assembly Area 46 Appendix 1a – City Policies and Sites Consultation Draft 2010, Policies 59 Appendix 1b – City Policies and Sites Consultation Draft 2010, Sites 67 Appendix 1c – City Policies and Sites Consultation Draft 2010, Proposals 71 Map Appendix 2 – Additional Site Allocation Options Consultation 2012 75 List of Tables Page Table 1 Total Number of Comments, Consultation Draft 2010 5 Table 2 Number of Comments by Chapter 6 Table 3 Number of Comments on Site Allocation by Community 6 Assembly Area Table 4 Number of Comments on Area Designations by Community 6 Assembly Area Table 5 Total Number of Comments, Additional Site Allocation Options 7 2012 1. -

Central Sheffield
H S L E O A A N U G To Northern General V TToo M1 (J36), ManchesterManchester,, T S Y H E P G T T E Hospital A BarBarnsleynsley & Huddersfield T R N E Walkley O I R Neepsend A S R O D T 5 Central SheffieldO 3 A O A D 1 D 6 D A N O A University R E Supertram E C MOWBRAY STREET of Sheffield A L Recommended main routes R R R IL stop & name H E O T H O T I A R N E Infirmary F D Ri L W B I ve L R r A A Road M 95 A A T Bus stop & University R Do I U Y P R P n P R A GR S P D E O EE 9 service number D parking R A 6 N 0 A T T D 1 LA 61 H E NE A O U O P R E N R D R T A P T P Medico-Legal ALMA S U S O E E T T R R R R E R E Centre S Shalesmoor EE L E T E MALINDA ST T S IL O RP H R E V To Banks with cash dispenser facilities: O O R O Y SA D H R R S R A T P T A H L R D E Y PE E S Upperthorpe T A E D P A L Meadowhall, I U R W E O MEADOW S F A M D LloydsHSBC H National Westminster O M1 (J34) & Y DONCASTER STREET 5 O S T D T R 3 E T R D E G 1 A R I R 6 Rotherham O T BRA 95 123 S L E A Royal Bank of Scotland N Yorkshire T TA E R E D E R T A A D R T S R O O ) n E E S D d STREET T A R B R H N E O A a P LE R o R R o E AL K D B R H E D E S S E C 0 100 200 300 400 500 metres S g ' E I R ' I A L in T CORPORATION STREET P G V P R I S P R I N I W r S L r D L B e I I e L R A n T O v H H In E West Bar N i N O O ( P E P W K © Cartographic Services, The University of Sheffield, 2005 A R Police Station R 4 TR S O D G E T . -

Rag Parades, Halls & David Bowie
Development Alumni Relations & Events. Rag Parades, Halls & David Bowie. Experiences of University life 1965–84 The winning Stephenson Hall float, Rag 1969. Photo from John Bitton (BEng Civil and Structural Engineering 1970) Twikker, 1969. Photo Archive, University of Sheffield Accommodation A party in the Junior Common Room, Sorby Hall in 1964. Steve Betney (BSc Physics 1965) Thank you This magazine is the result of a request for memories of student life from alumni of The University of Sheffield who graduated in the years 1965 to 1984. The publication provides a glimpse into an interesting period in the University’s history with the rapid expansion of the campus and halls of residence. The eyewitness accounts of the range and quality of bands promoted by the Students’ Union are wonderful testimony to the importance of Sheffield as a city of music. And the activities of students during the Rag Parade and Boat Race would create panic in the Health and Safety Executive if repeated today. I wish to thank everyone who responded so generously with their time and sent us their recollections and photos. Just a fraction of the material appears here; all of the responses will become part of the University Archives. Miles Stevenson The residents of Crewe Hall (popularly known as Kroo’All in those Director of Alumni and Donor days) were a notorious bunch of students whose cruel initiations Relations of their new members were very original. In my case, during Crewe Hall Autumn 2015 that initiation night three senior members brought me up by lift to the top floor of the nearby Halifax Hall. -

Sheffield Local Plan (Formerly Sheffield Development Framework)
Sheffield Local Plan (formerly Sheffield Development Framework) Consultation Schedule – City Policies and Sites Consultation Draft 2010 Full Schedule of individual comments and Council responses on the City Policies and Sites Consultation Draft, Proposals Map and Sustainability Appraisal – June 2010 Representations on City Policies and Sites Consultation Draft................................................................2 Representations on City Policies and Sites Proposals Map………………………………………………112 Representations on City Policies and Sites Consultation Draft Sustainability Appraisal………………136 Representations on City Policies and Sites Consultation Draft Document Section Comment Name of individual/ Nature of Summary of Comment Council response Recommendation ID organisation comment Introduction - General dcps13 Mr Derek Hastings, Object Paragraph 1.7 should reflect that Government policy documents Local development plan policy must be consistent with national No change is proposed. comment Rivelin Valley are non-statutory and that, under the plan-led system, planning policy and the new National Planning Policy Framework will Conservation Group policies should be included in the Development Plan to carry carry considerable weight. But there is no need to duplicate it. maximum weight. Although this can leave the impression of omissions from local policy, duplicating national policy will not add any further weight and any variations in wording could create uncertainty about which applies . Introduction - General dcps14 Mr Derek Hastings, Object The proposed "cull" of planning policies is unacceptable. The The issue is partly dealt with in the response to dcps13. The No change is proposed. comment Rivelin Valley length of the document is irrelevant. Policies included in non- issue of length is relevant, having been raised by the Core Conservation Group statutory national or local policy carry less weight than the Strategy Inspector. -

Central Community Assembly Area Areas and Sites
Transformation and Sustainability SHEFFIELD LOCAL PLAN (formerly Sheffield Development Framework) CITY POLICIES AND SITES DOCUMENT CENTRAL COMMUNITY ASSEMBLY AREA AREAS AND SITES BACKGROUND REPORT Development Services Sheffield City Council Howden House 1 Union Street SHEFFIELD S1 2SH June 2013 CONTENTS Chapter Page 1. Introduction 1 Part 1: City Centre 2. Policy Areas in the City Centre 5 3. Allocated Sites in the City Centre 65 Part 2: Sheaf Valley and Neighbouring Areas 4. Policy Areas in Sheaf Valley and Neighbouring Areas 133 5. Allocated Sites in Sheaf Valley and Neighbouring Areas 175 Part 3: South and West Urban Area 6. Policy Areas in the South and West Urban Area 177 7. Allocated Sites in the South and West Urban Area 227 Part 4: Upper Don Valley 8. Policy Areas 239 9. Allocated Sites in Upper Don Valley 273 List of Tables Page 1 Policy Background Reports 3 2 Potential Capacity of Retail Warehouse Allocations 108 List of Figures Page 1 Consolidated Central and Primary Shopping Areas 8 2 Illustrative Block Plan for The Moor 9 3 Current Street Level Uses in the Cultural Hub 15 4 Priority Office Areas 21 5 City Centre Business Areas 28 6 City Centre Neighbourhoods 46 7 City Centre Open Space 57 8 Bramall Lane/ John Street 139 1. INTRODUCTION The Context 1.1 This report provides evidence to support the published policies for the City Policies and Sites document of the Sheffield Local Plan. 1.2 The Sheffield Local Plan is the new name, as used by the Government, for what was known as the Sheffield Development Framework. -

CALEDONIAN SOCIETY of SHEFFIELD
CALEDONIAN SOCIETY of Programme 2018 SHEFFIELD June 13 Saturday Canal Trip July 8 Sunday Treasure Hunt President 2017/2018 Mr William Coupar MBE Aug 30 Thursday Bridgescapes illustrated talk President 2018/2019 Mrs Arlene McMaster Sept 20 Thursday Visit to Wentworth Woodhouse Oct 13 Saturday Arts Group - Two 19th century Scottish Travellers Oct 26 Friday A Night at the Dogs Nov 3 Saturday Armistice Centenary Commemoration INFORMATION Nov 24 Saturday ST ANDREW’S DINNER & BALL Nov 25 Sunday Caledonian Society Church Service & Dec 1 Saturday Arts Group - Stuarts Revisited Dec 7 Friday Cambrian Society Carol Service & Supper BOOKING FORMS Dec 31 Monday HOGMANAY CEILIDH FOR EVENTS IN Programme 2019 MAY, JUNE, AUGUST & Jan 12 Saturday Arts Group - New Year Party Jan 26 Saturday BURNS SUPPER Feb 2 Saturday Arts Group - A History of the Botanical Gardens SEPTEMBER 2018 March 9 Saturday Arts Group - The True Story of Burke & Hare IN THIS ISSUE President’s Letter and more to come Canal Trip Treasure Hunt Bridgescapes Dance Class Society Secretary: St David’s Day Dinner Mr Ian McMaster, 2 Southfield Mount, Chesterfield Road, Complimentary Dinner Dronfield, Sheffield, S18 1YQ Arts Group Telephone 01246 417626 Wentworth Woodhouse Golf Tournament Membership Secretary: Theatre Group Mr Neil Scott, 3 Barnside Close, Penistone, Sheffield S36 6UB Coming soon Telephone 01226 762894 Amendments -errors? - additions - new dates - suggestions about this booklet- ring Bert Redhead on Sheffield 2369849 Dates For Your Diary 16 Our website - www.sheffieldcaledonians.co.uk Forthcoming events This booklet tells you of the main activities of the Caledonian Society of Sheffield and includes information on some events which, although not A night at the dogs - we’re organised by the Society, are likely to be of interest to members. -
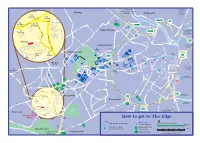
How to Get to the Edge
H L S AN E O To M1 (J36), A U G To Northern V T S Y ET H G P T Manchester, Barnsley General A E T R N E Walkley OA R I & Huddersfield Neepsend R O D S Hospital O A T 5 A D 3 40 D O 1 D 6 A N O A 80 80C 40 R E E C A MOWBRAY STREET L R L R R 80 80A E O J9 I H T H T R A J10 O E I BRIDGEHOUSES L B Infirmary N R L F D iv SAVILLE W A IR er A Road M STREET T 9 A D I 0 A R o 61 40 Y n UTLERS G P A R U A C ATE S T PP R GRE J7 S 40 D E OA 6 EN E 80 80C D RT D 1 SHALESMOORLA LL A H T NE VI O O E A 80 80A U R E S R P P Medico-Legal N AD E R ALMA S R RO P T T TR U E 150 S E R E Centre Shalesmoor ET R O E T R MALINDA ST S RP H E O To O O R Y E A A D TH R R R P D E R L E E T D P ST A J8 Y C E UP Meadowhall, I R Upperthorpe W U O MEADOW CORPORATION 40 F A T D STREET H Y S L M1 (J34) & T H S E D DON R 80 80A R A T T S CASTER STREET E L O AD E E R Rotherham R S G N M E A T ST O O R E T E E T D E G D I A D R B R A R T R O E S A E D E O ) H L K n A R STREET P N T B R E O A d E ALL A C o R R a H R I D o S B R D S E S S ' W ' E I J1 A L R g T P G V P n R I i S R I N I P R E r CUTLERS S L L I E I r B e R D e T L GATE H O v O A H n T West Bar i N N P n CORPORATION ST P E The Edge A O (I E K R D R R Police Station S . -

All Approved Premises
All Approved Premises Local Authority Name District Name and Telephone Number Name Address Telephone BARKING AND DAGENHAM BARKING AND DAGENHAM 0208 227 3666 EASTBURY MANOR HOUSE EASTBURY SQUARE, BARKING, 1G11 9SN 0208 227 3666 THE CITY PAVILION COLLIER ROW ROAD, COLLIER ROW, ROMFORD, RM5 2BH 020 8924 4000 WOODLANDS WOODLAND HOUSE, RAINHAM ROAD NORTH, DAGENHAM 0208 270 4744 ESSEX, RM10 7ER BARNET BARNET 020 8346 7812 AVENUE HOUSE 17 EAST END ROAD, FINCHLEY, N3 3QP 020 8346 7812 CAVENDISH BANQUETING SUITE THE HYDE, EDGWARE ROAD, COLINDALE, NW9 5AE 0208 205 5012 CLAYTON CROWN HOTEL 142-152 CRICKLEWOOD BROADWAY, CRICKLEWOOD 020 8452 4175 LONDON, NW2 3ED FINCHLEY GOLF CLUB NETHER COURT, FRITH LANE, MILL HILL, NW7 1PU 020 8346 5086 HENDON HALL HOTEL ASHLEY LANE, HENDON, NW4 1HF 0208 203 3341 HENDON TOWN HALL THE BURROUGHS, HENDON, NW4 4BG 020 83592000 PALM HOTEL 64-76 HENDON WAY, LONDON, NW2 2NL 020 8455 5220 THE ADAM AND EVE THE RIDGEWAY, MILL HILL, LONDON, NW7 1RL 020 8959 1553 THE HAVEN BISTRO AND BAR 1363 HIGH ROAD, WHETSTONE, N20 9LN 020 8445 7419 THE MILL HILL COUNTRY CLUB BURTONHOLE LANE, NW7 1AS 02085889651 THE QUADRANGLE MIDDLESEX UNIVERSITY, HENDON CAMPUS, HENDON 020 8359 2000 NW4 4BT BARNSLEY BARNSLEY 01226 309955 ARDSLEY HOUSE HOTEL DONCASTER ROAD, ARDSLEY, BARNSLEY, S71 5EH 01226 309955 BARNSLEY FOOTBALL CLUB GROVE STREET, BARNSLEY, S71 1ET 01226 211 555 BOCCELLI`S 81 GRANGE LANE, BARNSLEY, S71 5QF 01226 891297 BURNTWOOD COURT HOTEL COMMON ROAD, BRIERLEY, BARNSLEY, S72 9ET 01226 711123 CANNON HALL MUSEUM BARKHOUSE LANE, CAWTHORNE, -

The Campus in Context Opportunities + Constraints
PART 2 THE CAMPUS IN CONTEXT OPPORTUNITIES + CONSTRAINTS 15 DRAFT for consultation Autumn 2014 THE UNIVERSITY OF SHEFFIELD MASTERPLAN 2.1 Location The University of Sheffield central campus is located on A61 the west slopes of the city centre. The campus forms a city gateway characterised by a change from leafy suburbia to a more built up urban environment. The central campus is often identified as sitting within the St George’s Quarter of the city, A61 though reaches beyond this quarter in all directions, and as such has highly permeable boundaries. The central campus is divided by Upper Hanover Street, a north-south section of the A61 city ring road, and further divided by significant east-west roads A57 to M1 Western Bank and Broad Lane. The resulting campus zones are known as the east, north and west campus. The academic and social shape of these is described in later sections. On foot, the centre of the campus is approximately 15 minutes from the city centre, and 25 minutes from Midland Rail Station, the Bus Station and Sheffield Hallam University, which A57 A61 are east of the city centre. A61 North Campus A625 A621 Google copyright for aerial image component Principal routes to the city A57 East Campus West Campus 16 LOCATION KEY 1 Weston Park 2 Royal Hallamshire Hospital 3 Firth Hall 12 4 UoS Students’ Union 5 St George’s Church 6 Devonshire Green 7 City Hall 8 Sheffield Town Hall 9 Sheffield Hallam University 10 Bus Station 11 Midland Station 12 A61 Ring Road 1 University buildings shaded blue 5 3 Whilst the Hallamshire Hospital and 7 Sheffield Children’s Hospital are not 4 10 owned by the University of Sheffield, 8 we do have significant numbers of staff based in these two locations under 9 long-term arrangements which is why 6 they are included here. -
The Magazine for Sheffield 23,000 Copies • Est
The Magazine For Sheffield 23,000 copies • Est. 1991 • August 2021 • www.grapevinesheffield.net Smoke of War Sheffield, 1915 - p.33 Spying For Germany? Incas Were Gay Swimming School Christmas Dinner! Sheffield Lord Mayor’s Trial - p.18 Amazing Teapot Discovery - p.3 Lessons For Children - p.29 And Half-Price Meals - p.3, p.31 How To Cook Steel Dancers In The Frame Patio In Porcelain Knightly Roof Work Some Heavy Recipes - p.34 On Psalter Lane - p.26 Sleek Ceramic Look - p.30 Repairing Camelot - p.8 2 Grapevine Magazine t seems,” announced my old chum Mr Smith when he visited me embassy (being Churchill Fellows), and it was not long before one yesterday, “that the University of Sheffield’s archaeology department of the diplomats said: “I suppose you lads want to go tomb robbing.” Iis history. I’ve heard it’s going to be closed, which must be of great “Yes, please!” we replied, whereupon Our Man in Lima drove us concern to you - our city’s most esteemed tomb robber.” in his car to an area of desert a few miles north. It seemed strewn “Smith, it’s almost 50 years since I hung up my excavating trowel, with discarded newspapers, which turned out to be shrouds and I must tell you that scratting for bits of pottery was no more of people buried centuries ago. All around, as far as the eye interesting than typing the crown green bowling results, which was one could see, were bones from desecrated graves. of my first tasks as a cub reporter on the Ossett Observer. -
BBEST Design Guide
BBEST DESIGN GUIDE V10 March 2021 CONSULTANT/CLIENT INFORMATION Project BBEST Design Guide Client BBEST Title of Document BBEST DESIGN GUIDE File Origin rtu2017-ID-005 CONTENTS BBEST Design Guide 1. Introduction Pg. 4 2. Characteristics of BBEST Area Pg. 6 Conservation Areas Listed Buildings Variety of scales and building types and routes 3. Key Principles Pg. 12 What is important Maintaining key views Sites of Particular Signifi cance to the Community 4. Character Area Appraisals Pg. 24 Introduction Crookes Valley Pg. 26 Hospital Quarter Pg. 32 Residential South East Pg. 38 Residential North East Pg. 44 Retail Centre Pg. 50 Residential North West Pg. 58 Residential South West Pg. 64 Endcliff e Pg. 70 BBEST Design Guide 3 1. INTRODUCTION The BBEST Design Guide sits alongside the BBEST Neighbourhood Plan as a companion document. The character of the whole area is distinctive and attractive. This document seeks to identify the chacteristics that make the area special with a view to ensuring that new development can be brought forward in a manner that respects this unique character, repairs past mistakes or damage and takes opportunities to deliver improvements. The document provides a balance of guidelines and policy to inform development. The document is split into 3 main sections - Characteristics of the area - Key Principles - covering design principles relevant to the whole area. - Character Areas - The BBEST area has been split into 8 character areas, describing the specifi c issues and opportunities unique to particular areas. The BBEST area covers a signifi cant zone to the west of Sheffi eld City Centre. -

Sheffield Local Plan (Formerly Sheffield Development Framework)
Sheffield Local Plan (formerly Sheffield Development Framework) Consultation Schedule – Additional Site Allocation Options Full Schedule of individual comments and Council responses on the Additional Site Allocation Options and Sustainability Appraisal – January/February 2012 Representations on Additional Site Allocation Options………..................................................................2 Representations on Sustainability Appraisal………………………………………………………………..103 General Response A P00497 Lydgate Reservoir, Evelyn Road…………………………………...104 General Response B P00517 Canterbury Crescent………………………………………………...105 General Response C P00367 Beighton Road………………………………………………………..106 General Response D P00509 Junction Road, Woodhouse………………………………………...108 General Response E P00508 Former Sports Ground, Bawtry Road, Tinsley……………………110 General Response F P00502 Wiggan Farm…………………………………………………………112 General Response G P00517 Canterbury Crescent………………………………………………...114 General Response H P00505 Platts Lane/Oughtibridge Lane, Oughtibridge…………………….115 General Response I P00507 Worrall Hall Farm…………………………………………………….117 General Response J P00503 Former Sports Ground, Greaves Lane, Stannington…………….119 General Response K P00506 Hawthorn Avenue, Stocksbridge/Coppice Close…………………121 Representations on Additional Site Allocation Options Document Section Comment Name of individual/ Nature of Summary of Comment Council response Recommendation ID organisation comment Introduction - General ASAO-10 Mr Ian Richmond Disagree comment Introduction - General ASAO-39