Devops with Openshift CLOUD DEPLOYMENTS MADE EASY
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Ansys SCADE Lifecycle®
EMBEDDED SOFTWARE Ansys SCADE LifeCycle® SCADE LifeCycle is part of the Ansys Embedded Software family of products and solutions that includes modules providing unique support for application lifecycle management. This product line features requirements traceability via Application Lifecycle Management (ALM) tools, traceability from models, configuration and change management, and automatic documentation generation. SCADE LifeCycle enhances the functionalities of Ansys SCADE® tools with add-on modules that bridge SCADE solutions and Requirement Management tools or PLM/ALM (Product Lifecycle Management/ Application Lifecycle Management) tools. With SCADE LifeCycle, all systems and software teams involved in critical applications development can manage and control their design and verification activities across the full life cycle of their SCADE applications. / Requirements Traceability SCADE LifeCycle Application Lifecycle Management (ALM) Gateway provides an integrated traceability analysis solution for safety-critical design processes with SCADE Architect, SCADE Suite, SCADE Display, SCADE Solutions for ARINC 661 and SCADE Test: • Connection to ALM tools: linkage to DOORS NG, DOORS (9.6 and up) Jama Connect, Siemens Polarion, Dassault Systèmes Reqtify 2016. • Graphical creation of traceability links between requirements or other structured documents and SCADE models. • Traceability of test cases from SCADE Test Environment projects. • Bidirectional navigation across requirements and tests. • Customizable Export of SCADE artifacts to DOORS or Jama Connect. • Compliant with DO-178B, DO-178C, EN 50128, IEC 61508, ISO 26262, and IEC 60880 standards. EMBEDDED SOFTWARE / SCADE LifeCycle® // 1 / Project Documentation Generation SCADE LifeCycle Reporter automates the time-consuming creation of detailed and complete reports from SCADE Suite, SCADE Display, SCADE Architect and SCADE UA Page Creator for ARINC 661 designs through: • Generation of reports in RTF or HTML formats. -

Configuration Management for Distributed Development
Software Configuration Management Configuration Management for Distributed Development By Nina Rajkumar. © Think Business Networks Pvt. Ltd., July 2001 All rights reserved. You may make one attributed copy of this material for your own personal use. For additional information or assistance please contact Nina at (+91)422-320-606. www.thinkbn.com • 697A, Trichy Road, Coimbatore, TN 641045. Table of Contents Configuration Management for Distributed Development.............................. 4 Configuration Management ................................................................................ 5 Distributed Development.................................................................................... 5 Cases of Distributed Development ..................................................................... 6 Distance Working ........................................................................................... 6 Outsourcing..................................................................................................... 6 Co-located Groups .......................................................................................... 7 Distributed Groups.......................................................................................... 7 Architecture ........................................................................................................ 8 Remote Login.................................................................................................. 8 Several sites by Master-Slave connections .................................................... -
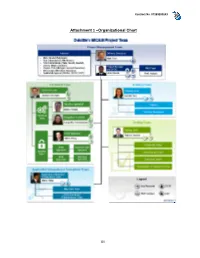
85 Attachment 1 –Organizational Chart
Contract No. 071B3200143 Attachment 1 –Organizational Chart 85 Contract No. 071B3200143 Appendix A - Breakdown of Hardware and Related Software Table 1: Hardware Cost ($): State Brand, Model # Item Specifications will provide from Comments and Description existing Contracts Total # of Virtual The hardware is Machines: 48 sized for Production, QA/Staging, Secure-24 VMware Total # of Virtual Development, and Cluster Access for CPUs: 96 Sandbox Server deploying ISIM, environments in the ISAM and ISFIM Total Virtual RAM: primary data center components 416 GB and for Production, and QA environments in the OS: RedHat Linux secondary data 6.x center The total storage is estimated for Total Storage: 35.7 Production, , TB QA/Staging, Development and Enterprise Class Sandbox Storage (3.8TB of Bronze SAN Storage Tier, 15.8TB of environments in the Silver Tier, 5.1TB of primary data center Logs Tier, 11TB of and for Production, Gold Tier) QA environments in the secondary data center CD/DVD Backup Device None None Rack w/ Power Supply Rack mountable Redundant Power Screen None None A total of 10 Web Gateway appliances are estimated for Production, QA/Staging, Web Gateway Development and Any other Hardware (list) v7.0 Hardware Appliance Sandbox environments in the primary data center and for Production, QA environments in the secondary data center. TOTAL $ 86 Contract No. 071B3200143 Table 2: Related Software Software Component Product Name Cost ($): State # of Licenses Comments License and Version will provide from existing Contracts Contractor user laptops already include this software. We will reuse the Report writers MS Office 2010 State owned software State of Michigan user licenses laptops will need this software for up to 4 users. -

Using Visual COBOL in Modern Application Development Micro Focus the Lawn 22-30 Old Bath Road Newbury, Berkshire RG14 1QN UK
Using Visual COBOL in Modern Application Development Micro Focus The Lawn 22-30 Old Bath Road Newbury, Berkshire RG14 1QN UK http://www.microfocus.com © Copyright 2018-2020 Micro Focus or one of its affiliates. MICRO FOCUS, the Micro Focus logo and Visual COBOL are trademarks or registered trademarks of Micro Focus or one of its affiliates. All other marks are the property of their respective owners. 2020-08-25 ii Contents Using Visual COBOL in Modern Application Development ........................... 4 Introduction to Modern Application Development ................................................................4 What is Modern Application Development? ..............................................................4 Key Concepts in Modern Application Development ..................................................5 Steps Involved in Modern Application Development ................................................ 6 Agile Methods ..................................................................................................................... 7 Introduction to Agile Methods ...................................................................................7 Agile Development Workflow ....................................................................................7 Agile Development and Micro Focus Development Tools .........................................9 Continuous Integration ...................................................................................................... 11 Introduction to Continuous Integration .................................................................. -

Revision Control Solutions to Protect Your Documents and Track Workflow
Revision Control Solutions to Protect Your Documents and Track Workflow WHITE PAPER Contents Overview 3 Common Revision Control Systems 4 Revision Control Systems 4 Using BarTender with Revision Control Systems 4 Limitations of Windows Security 5 Librarian 6 Librarian Features 6 Benefits of Using Librarian with BarTender 7 File States, Publishing and Workflow in Librarian 8 Don’t Forget About Security! 9 Related Documentation 10 Overview A revision control system is based around the concept of tracking changes that happen within directories or files, and preventing one user from overwriting the work of another. Some revision control systems are also used to establish and track workflow for the progression of a file through a series of states. The collection of files or directories in a revision control system are usually called a repository. These systems allow you to specify a directory, file or group of files that will have their changes tracked. This frequently entails users "checking out" and "checking in" files from a repository. Changes are tracked as the user edits the folder or file; these changes will be visible to all users once the item is checked back in. Each revision is annotated with a timestamp and the person making the change. Some of the benefits of revision control include: l Automatic revision numbering for easy tracking. l Enhanced security. Not only does a "check in" and "check out" system keep one user's work from overwriting another, it can prevent unauthorized or even malicious users from accessing a document. l Some revision control systems include publishing "states," which allow you to track the publishing progress of a document and establish a logical, traceable workflow. -

Git for the ASP.NET Programmer
git for the ASP.NET Programmer Paul Litwin Fred Hutchinson Cancer Research Center [email protected] @plitwin Slides & samples can be found here… • http://tinyurl.com/DevInt2015Oct Litwin Git for the ASP.NET Programmer 2 Session Itinerary • Why distributed version control? • git basics • Command line git • Using git from VS Code • Using git from Visual Studio • Branching and merging • Wrap up Litwin Git for the ASP.NET Programmer 3 Why distributed version control? Git is a free and open source distributed version control system designed to handle everything from small to very large projects with speed and efficiency Created by Linux creator, Linus Torvalds Litwin Git for the ASP.NET Programmer 5 The name git? “I'm an egotistical bastard, and I name all my projects after myself. First Linux, now git.” Linus Torvalds quote from 2007 Litwin Git for the ASP.NET Programmer 6 Centralized Version Control One repository using a client-server model Litwin Git for the ASP.NET Programmer 7 Distributed Version Control Many repositories using peer to peer model Litwin Git for the ASP.NET Programmer 8 Comparing centralized (tfs) vs distributed (git) Attribute Centralized Distributed TFS, SVN, PVCS git, Mercurial Repositories 1 Many Model Client-server Peer-to-peer Speed of common Slower Fast against local repo operations Redundancy of system None; single point of Redundancy built in failure Offline work More difficult Easy Merging of changes When you check When you sync changes changes in (push/pull) Litwin Git for the ASP.NET Programmer 9 git Basics -

TIBCO Designer User's Guide
TIBCO Designer™ User’s Guide Software Release 5.10 August 2015 Two-Second Advantage® Important Information SOME TIBCO SOFTWARE EMBEDS OR BUNDLES OTHER TIBCO SOFTWARE. USE OF SUCH EMBEDDED OR BUNDLED TIBCO SOFTWARE IS SOLELY TO ENABLE THE FUNCTIONALITY (OR PROVIDE LIMITED ADD-ON FUNCTIONALITY) OF THE LICENSED TIBCO SOFTWARE. THE EMBEDDED OR BUNDLED SOFTWARE IS NOT LICENSED TO BE USED OR ACCESSED BY ANY OTHER TIBCO SOFTWARE OR FOR ANY OTHER PURPOSE. USE OF TIBCO SOFTWARE AND THIS DOCUMENT IS SUBJECT TO THE TERMS AND CONDITIONS OF A LICENSE AGREEMENT FOUND IN EITHER A SEPARATELY EXECUTED SOFTWARE LICENSE AGREEMENT, OR, IF THERE IS NO SUCH SEPARATE AGREEMENT, THE CLICKWRAP END USER LICENSE AGREEMENT WHICH IS DISPLAYED DURING DOWNLOAD OR INSTALLATION OF THE SOFTWARE (AND WHICH IS DUPLICATED IN THE LICENSE FILE) OR IF THERE IS NO SUCH SOFTWARE LICENSE AGREEMENT OR CLICKWRAP END USER LICENSE AGREEMENT, THE LICENSE(S) LOCATED IN THE “LICENSE” FILE(S) OF THE SOFTWARE. USE OF THIS DOCUMENT IS SUBJECT TO THOSE TERMS AND CONDITIONS, AND YOUR USE HEREOF SHALL CONSTITUTE ACCEPTANCE OF AND AN AGREEMENT TO BE BOUND BY THE SAME. This document contains confidential information that is subject to U.S. and international copyright laws and treaties. No part of this document may be reproduced in any form without the written authorization of TIBCO Software Inc. TIBCO, Two-Second Advantage, TIBCO Hawk, TIBCO Rendezvous, TIBCO Runtime Agent, TIBCO ActiveMatrix BusinessWorks, TIBCO Administrator, TIBCO Designer, TIBCO ActiveMatrix Service Gateway, TIBCO BusinessEvents, TIBCO BusinessConnect, and TIBCO BusinessConnect Trading Community Management are either registered trademarks or trademarks of TIBCO Software Inc. -

Windows and CVS Suite
Windows and CVS Suite INSTALL GUIDE 2009 Build 7799 April 2021 March Hare Software Ltd INSTALL GUIDE 2009 Build 7799 April 2021 Legal Notices Legal Notices There are various product or company names used herein that are the trademarks, service marks, or trade names of their respective owners, and March Hare Software Limited makes no claim of ownership to, nor intends to imply an endorsement of, such products or companies by their usage. This document and all information contained herein are the property of March Hare Software Limited, and may not be reproduced, disclosed, revealed, or used in any way without prior written consent of March Hare Software Limited. This document and the information contained herein are subject to confidentiality agreement, violation of which will subject the violator to all remedies and penalties provided by the law. LIMITED WARRANTY. TO THE MAXIMUM EXTENT PERMITTED BY APPLICABLE LAW, March Hare Software Limited AND ITS SUPPLIERS DISCLAIM ALL WARRANTIES AND CONDITIONS, EITHER EXPRESS OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, IMPLIED WARRANTIES OR CONDITIONS OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE, TITLE AND NON-INFRINGEMENT, WITH REGARD TO THIS DOCUMENT, AND ANY ADVICE OR RECOMMENDATION CONTAINED IN THIS DOCUMENT. NO OTHER WARRANTIES. TO THE MAXIMUM EXTENT PERMITTED BY APPLICABLE LAW, IN NO EVENT SHALL March Hare Software Limited OR ITS SUPPLIERS BE LIABLE FOR ANY SPECIAL, INCIDENTAL, INDIRECT, OR CONSEQUENTIAL DAMAGES WHATSOEVER (INCLUDING, WITHOUT LIMITATION, DAMAGES FOR LOSS OF BUSINESS PROFITS, BUSINESS INTERRUPTION, LOSS OF BUSINESS INFORMATION, OR ANY OTHER PECUNIARY LOSS) ARISING OUT OF THE USE OF OR INABILITY TO USE THE FOLLOWING DOCUMENTATION INCLUDING ANY RECOMMENDATION OR ADVICE THERIN, EVEN IF March Hare Software Limtied HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES. -

Reference Architecture for Google Cloud's Anthos with Lenovo
Reference Architecture for Google Cloud’s Anthos with Lenovo ThinkAgile VX Last update: 11 June 2020 Describes the business case Provides an overview of for modern micro-services, Google Kubernetes Engine containers, and multi-cloud (GKE) on-premises with Anthos Describes the architecture and Provides Anthos use-cases implementation of Anthos and examples including solution on ThinkAgile VX DevOps, Service management, hyperconverged infrastructure Hybrid and Multi-cloud Srihari Angaluri Xiaotong Jiang Markesha Parker Table of Contents 1 Introduction ............................................................................................... 1 2 Business problem and business value ................................................... 2 2.1 Business problem .................................................................................................... 2 2.2 Business Value ........................................................................................................ 3 3 Requirements ............................................................................................ 4 3.1 Introduction .............................................................................................................. 4 3.1.1 Modern application development ................................................................................................. 4 3.1.2 Containers ................................................................................................................................... 5 3.1.3 DevOps ....................................................................................................................................... -

Bill Laboon Friendly Introduction Version Control: a Brief History
Git and GitHub: A Bill Laboon Friendly Introduction Version Control: A Brief History ❖ In the old days, you could make a copy of your code at a certain point, and release it ❖ You could then continue working on your code, adding features, fixing bugs, etc. ❖ But this had several problems! VERSION 1 VERSION 2 Version Control: A Brief History ❖ Working with others was difficult - if you both modified the same file, it could be very difficult to fix! ❖ Reviewing changes from “Release n” to “Release n + 1” could be very time-consuming, if not impossible ❖ Modifying code locally meant that a crash could take out much of your work Version Control: A Brief History ❖ So now we have version control - a way to manage our source code in a regular way. ❖ We can tag releases without making a copy ❖ We can have numerous “save points” in case our modifications need to be unwound ❖ We can easily distribute our code across multiple machines ❖ We can easily merge work from different people to the same codebase Version Control ❖ There are many kinds of version control out there: ❖ BitKeeper, Perforce, Subversion, Visual SourceSafe, Mercurial, IBM ClearCase, AccuRev, AutoDesk Vault, Team Concert, Vesta, CVSNT, OpenCVS, Aegis, ArX, Darcs, Fossil, GNU Arch, BitKeeper, Code Co-Op, Plastic, StarTeam, MKS Integrity, Team Foundation Server, PVCS, DCVS, StarTeam, Veracity, Razor, Sun TeamWare, Code Co-Op, SVK, Fossil, Codeville, Bazaar…. ❖ But we will discuss git and its most popular repository hosting service, GitHub What is git? ❖ Developed by Linus Torvalds ❖ Strong support for distributed development ❖ Very fast ❖ Very efficient ❖ Very resistant against data corruption ❖ Makes branching and merging easy ❖ Can run over various protocols Git and GitHub ❖ git != GitHub ❖ git is the software itself - GitHub is just a place to store it, and some web-based tools to help with development. -

Rational DOORS Installation Guide Release 9.2
IBM Rational DOORS Rational DOORS Installation Guide Release 9.2 Rational DOORS Rational DOORS Integration Products Before using this information, be sure to read the general information under the "Notices" chapter on page 107. This edition applies to IBM Rational DOORS, VERSION 9.2, and to all subsequent releases and modifications until otherwise indicated in new editions. © Copyright IBM Corporation 1993, 2009 US Government Users Restricted Rights—Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Table of contents Chapter 1: About this manual 1 Chapter 2: Introduction 3 What is Rational DOORS? . 3 What types of Rational DOORS installation can I have? . 5 What are the licensing options?. 6 What next? . 6 Chapter 3: New installation of Rational DOORS on Windows 9 Installing the Rational DOORS database server . 9 Installing the Rational DOORS client. 12 Installing Rational DOORS for Rational Quality Manager Interface . 14 The Rational DOORS for Rational Quality Manager Interface client . 15 The Rational DOORS for Rational Quality Manager Interface server . 16 Silent installation . 18 Starting Rational DOORS . 19 For installations that point to an empty data folder . 19 For installations that point to existing Rational DOORS data . 20 RDS, the Rational DOORS database and UUIDs . 20 tds_valid_id.txt . 21 tds_registered.txt . 21 Installing the Rational DOORS Example Data . 21 Uninstalling Rational DOORS . 22 Chapter 4: Upgrading from version 9.0 and later 23 Information for users upgrading to Rational DOORS 9.2 from 9.0 and 9.1 . 23 Data migration. 23 Licensing . 23 Compatibility between version 9.0 and Rational DOORS 9.2 . -

Introduction to Rational Synergy Release 7.1 Before Using This Information, Be Sure to Read the General Information Under Appendix A, “Notices” on Page 55
Introduction to Rational Synergy Release 7.1 Before using this information, be sure to read the general information under Appendix A, “Notices” on page 55. This edition applies to VERSION 7.1, Rational Synergy (product number MN-SCM-IV-ICM70-08-01) and to all subsequent releases and modifications until otherwise indicated in new editions. © Copyright IBM Corporation 1992, 2009 US Government Users Restricted Rights—Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. ii Introduction to Rational Synergy Table of Contents Chapter 1: Introduction 1 Transitioning from other tools. 1 Conventions . 2 Rational Synergy graphical user interfaces . 2 Rational Synergy command line interface. 2 Typefaces and symbols . 2 Contacting IBM Rational Software Support . 3 Prerequisites . 3 Submitting problems. 3 Chapter 2: Benefits of using Rational Synergy 7 Goals of a configuration management tool . 7 Rational Synergy benefits . 8 Easy to use, right out of the box . 8 Fast start-up . 8 Rapid productivity for new users . 9 Flexible, automated workflow . 9 Secure team engineering environment . 10 World-wide control and transfer of information . 10 Seamless integrations for Windows development . 12 Chapter 3: Rational Synergy terminology 13 The Rational Synergy database. 13 Tasks and objects . 13 More about objects . 16 The check out and check in operations . 16 History. 18 Properties. 18 Current task. 18 Users, lifecycles, and states. 19 Introduction to Rational Synergy iii Projects and project groupings . 20 Directories and candidates . 22 The work area . 22 The synchronize operation . 23 Using, creating, adding, deleting, or removing objects . 23 Update, baseline, tasks, and process rules .