Anatomy of the Deployment Pipeline
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Efficient Algorithms for Comparing, Storing, and Sharing
EFFICIENT ALGORITHMS FOR COMPARING, STORING, AND SHARING LARGE COLLECTIONS OF EVOLUTIONARY TREES A Dissertation by SUZANNE JUDE MATTHEWS Submitted to the Office of Graduate Studies of Texas A&M University in partial fulfillment of the requirements for the degree of DOCTOR OF PHILOSOPHY May 2012 Major Subject: Computer Science EFFICIENT ALGORITHMS FOR COMPARING, STORING, AND SHARING LARGE COLLECTIONS OF EVOLUTIONARY TREES A Dissertation by SUZANNE JUDE MATTHEWS Submitted to the Office of Graduate Studies of Texas A&M University in partial fulfillment of the requirements for the degree of DOCTOR OF PHILOSOPHY Approved by: Chair of Committee, Tiffani L. Williams Committee Members, Nancy M. Amato Jennifer L. Welch James B. Woolley Head of Department, Hank W. Walker May 2012 Major Subject: Computer Science iii ABSTRACT Efficient Algorithms for Comparing, Storing, and Sharing Large Collections of Evolutionary Trees. (May 2012) Suzanne Jude Matthews, B.S.; M.S., Rensselaer Polytechnic Institute Chair of Advisory Committee: Dr. Tiffani L. Williams Evolutionary relationships between a group of organisms are commonly summarized in a phylogenetic (or evolutionary) tree. The goal of phylogenetic inference is to infer the best tree structure that represents the relationships between a group of organisms, given a set of observations (e.g. molecular sequences). However, popular heuristics for inferring phylogenies output tens to hundreds of thousands of equally weighted candidate trees. Biologists summarize these trees into a single structure called the consensus tree. The central assumption is that the information discarded has less value than the information retained. But, what if this assumption is not true? In this dissertation, we demonstrate the value of retaining and studying tree collections. -

Higher Inductive Types (Hits) Are a New Type Former!
Git as a HIT Dan Licata Wesleyan University 1 1 Darcs Git as a HIT Dan Licata Wesleyan University 1 1 HITs 2 Generator for 2 equality of equality HITs Homotopy Type Theory is an extension of Agda/Coq based on connections with homotopy theory [Hofmann&Streicher,Awodey&Warren,Voevodsky,Lumsdaine,Garner&van den Berg] 2 Generator for 2 equality of equality HITs Homotopy Type Theory is an extension of Agda/Coq based on connections with homotopy theory [Hofmann&Streicher,Awodey&Warren,Voevodsky,Lumsdaine,Garner&van den Berg] Higher inductive types (HITs) are a new type former! 2 Generator for 2 equality of equality HITs Homotopy Type Theory is an extension of Agda/Coq based on connections with homotopy theory [Hofmann&Streicher,Awodey&Warren,Voevodsky,Lumsdaine,Garner&van den Berg] Higher inductive types (HITs) are a new type former! They were originally invented[Lumsdaine,Shulman,…] to model basic spaces (circle, spheres, the torus, …) and constructions in homotopy theory 2 Generator for 2 equality of equality HITs Homotopy Type Theory is an extension of Agda/Coq based on connections with homotopy theory [Hofmann&Streicher,Awodey&Warren,Voevodsky,Lumsdaine,Garner&van den Berg] Higher inductive types (HITs) are a new type former! They were originally invented[Lumsdaine,Shulman,…] to model basic spaces (circle, spheres, the torus, …) and constructions in homotopy theory But they have many other applications, including some programming ones! 2 Generator for 2 equality of equality Patches Patch a a 2c2 diff b d = < b c c --- > d 3 3 id a a b b -

Nabaztag Lives: the Rebirth of a Bunny
Nabaztag Lives: The Rebirth of a Bunny An exploration of the Nabaztag as a social robot in a domestic environment Tanja Kampman, s1724185 Supervisor: dr. ir. Edwin Dertien Critical observer: dr. Angelika Mader 6th of July, 2018 Creative Technology, University of Twente Abstract The Nabaztag is a robot rabbit that this research has given a new purpose. The purpose is to help university students with generalized anxiety disorder symptoms or depressive symptoms, which are common in that group and often come together. The focus is on these students who are in therapy, specifically cognitive behavioural therapy. Current solutions for problems this target audience faces are found and the problems are analysed. The outcome of the ideation is a social robot companion that supports them both in their treatment and their studies by e.g. helping with sticking to a planning. This solution is then evaluated by peers from different fields according to a scenario of a student who struggles. Then, a prototype is created where the interaction is tested on whether the student could form a bond with the robot enough and on whether there are major problems in general. The result of these evaluations is that people believe there is potential for the concept if it was worked out further, but that there are many flaws currently in the system that would need to be fixed. 1 Acknowledgements I would like to give special thanks to my supervisor dr. ir. Edwin Dertien and my critical observer dr. Angelika H. Mader for guiding me on this journey. Also, special thanks to Richard Bults for organising the bachelor assignments. -

Designing the Internet of Things
Designing the Internet of Things Adrian McEwen, Hakim Cassimally This edition first published 2014 © 2014 John Wiley and Sons, Ltd. Registered office John Wiley & Sons Ltd, The Atrium, Southern Gate, Chichester, West Sussex, PO19 8SQ, United Kingdom For details of our global editorial offices, for customer services and for information about how to apply for permission to reuse the copyright material in this book please see our website at www.wiley.com. The right of the author to be identified as the author of this work has been asserted in accordance with the Copyright, Designs and Patents Act 1988. All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopying, recording or otherwise, except as permitted by the UK Copyright, Designs and Patents Act 1988, without the prior permission of the publisher. Wiley also publishes its books in a variety of electronic formats. Some content that appears in print may not be available in electronic books. Designations used by companies to distinguish their products are often claimed as trademarks. All brand names and product names used in this book are trade names, service marks, trademarks or registered trademarks of their respective owners. The publisher is not associated with any product or vendor mentioned in this book. This publication is designed to provide accurate and authoritative information in regard to the subject matter covered. It is sold on the under- standing that the publisher is not engaged in rendering professional services. If professional advice or other expert assistance is required, the services of a competent professional should be sought. -

DVCS Or a New Way to Use Version Control Systems for Freebsd
Brief history of VCS FreeBSD context & gures Is Arch/baz suited for FreeBSD? Mercurial to the rescue New processes & policies needed Conclusions DVCS or a new way to use Version Control Systems for FreeBSD Ollivier ROBERT <[email protected]> BSDCan 2006 Ottawa, Canada May, 12-13th, 2006 Ollivier ROBERT <[email protected]> DVCS or a new way to use Version Control Systems for FreeBSD Brief history of VCS FreeBSD context & gures Is Arch/baz suited for FreeBSD? Mercurial to the rescue New processes & policies needed Conclusions Agenda 1 Brief history of VCS 2 FreeBSD context & gures 3 Is Arch/baz suited for FreeBSD? 4 Mercurial to the rescue 5 New processes & policies needed 6 Conclusions Ollivier ROBERT <[email protected]> DVCS or a new way to use Version Control Systems for FreeBSD Brief history of VCS FreeBSD context & gures Is Arch/baz suited for FreeBSD? Mercurial to the rescue New processes & policies needed Conclusions The ancestors: SCCS, RCS File-oriented Use a subdirectory to store deltas and metadata Use lock-based architecture Support shared developments through NFS (fragile) SCCS is proprietary (System V), RCS is Open Source a SCCS clone exists: CSSC You can have a central repository with symlinks (RCS) Ollivier ROBERT <[email protected]> DVCS or a new way to use Version Control Systems for FreeBSD Brief history of VCS FreeBSD context & gures Is Arch/baz suited for FreeBSD? Mercurial to the rescue New processes & policies needed Conclusions CVS, the de facto VCS for the free world Initially written as shell wrappers over RCS then rewritten in C Centralised server Easy UI Use sandboxes to avoid locking Simple 3-way merges Can be replicated through CVSup or even rsync Extensive documentation (papers, websites, books) Free software and used everywhere (SourceForge for example) Ollivier ROBERT <[email protected]> DVCS or a new way to use Version Control Systems for FreeBSD Brief history of VCS FreeBSD context & gures Is Arch/baz suited for FreeBSD? Mercurial to the rescue New processes & policies needed Conclusions CVS annoyances and aws BUT.. -

Understanding Expressions of Internet of Things
Understanding Expressions of Internet of Things Kuo Chun, Tseng*, Rung Huei, Liang ** * Department of Industrial and Commercial Design, National Taiwan University of Science and Technology, Taipei, Taiwan, [email protected] ** Department of Industrial and Commercial Design, National Taiwan University of Science and Technology, Taipei, Taiwan, [email protected] Abstract: A recent surge of research on Internet of Things (IoT) has given people new opportunities and challenges. Unfortunately, little research has been done on conceptual framework, which is a crucial aspect to envision IoT design. We found that designers usually felt helpless when designing smart objects in contrast to traditional ones and needed more resources for potential expressions of interactive embodiment with this new technology. Moreover, it appears to be unrealistic to expect the designer to follow the programming thinking and theory of MEMS (Micro Electro Mechanical Systems) field. Therefore, instead of focusing on exploring the technology, this paper proposes an analytical framing and investigates interactive expressions of embodiment on smart objects that help designers understand and handle the technology as design material to design smart objects during the coming era of IoT. To achieve this goal, first we conceptualize an IoT artifact as an object that has four capabilities and provide a clear framework for understanding a thing and multiple things over time and space in ecology of IoT things powered by a cloud-based mechanism. Second, we show the analytical results of three categories: smart things and design agenda over cloud in respect of time and space. Third, drawing on the taxonomy of embodiment in tangible interfaces by Fishkin K. -

Ansys SCADE Lifecycle®
EMBEDDED SOFTWARE Ansys SCADE LifeCycle® SCADE LifeCycle is part of the Ansys Embedded Software family of products and solutions that includes modules providing unique support for application lifecycle management. This product line features requirements traceability via Application Lifecycle Management (ALM) tools, traceability from models, configuration and change management, and automatic documentation generation. SCADE LifeCycle enhances the functionalities of Ansys SCADE® tools with add-on modules that bridge SCADE solutions and Requirement Management tools or PLM/ALM (Product Lifecycle Management/ Application Lifecycle Management) tools. With SCADE LifeCycle, all systems and software teams involved in critical applications development can manage and control their design and verification activities across the full life cycle of their SCADE applications. / Requirements Traceability SCADE LifeCycle Application Lifecycle Management (ALM) Gateway provides an integrated traceability analysis solution for safety-critical design processes with SCADE Architect, SCADE Suite, SCADE Display, SCADE Solutions for ARINC 661 and SCADE Test: • Connection to ALM tools: linkage to DOORS NG, DOORS (9.6 and up) Jama Connect, Siemens Polarion, Dassault Systèmes Reqtify 2016. • Graphical creation of traceability links between requirements or other structured documents and SCADE models. • Traceability of test cases from SCADE Test Environment projects. • Bidirectional navigation across requirements and tests. • Customizable Export of SCADE artifacts to DOORS or Jama Connect. • Compliant with DO-178B, DO-178C, EN 50128, IEC 61508, ISO 26262, and IEC 60880 standards. EMBEDDED SOFTWARE / SCADE LifeCycle® // 1 / Project Documentation Generation SCADE LifeCycle Reporter automates the time-consuming creation of detailed and complete reports from SCADE Suite, SCADE Display, SCADE Architect and SCADE UA Page Creator for ARINC 661 designs through: • Generation of reports in RTF or HTML formats. -

Configuration Management for Distributed Development
Software Configuration Management Configuration Management for Distributed Development By Nina Rajkumar. © Think Business Networks Pvt. Ltd., July 2001 All rights reserved. You may make one attributed copy of this material for your own personal use. For additional information or assistance please contact Nina at (+91)422-320-606. www.thinkbn.com • 697A, Trichy Road, Coimbatore, TN 641045. Table of Contents Configuration Management for Distributed Development.............................. 4 Configuration Management ................................................................................ 5 Distributed Development.................................................................................... 5 Cases of Distributed Development ..................................................................... 6 Distance Working ........................................................................................... 6 Outsourcing..................................................................................................... 6 Co-located Groups .......................................................................................... 7 Distributed Groups.......................................................................................... 7 Architecture ........................................................................................................ 8 Remote Login.................................................................................................. 8 Several sites by Master-Slave connections .................................................... -

Darcs 2.0.0 (2.0.0 (+ 75 Patches)) Darcs
Darcs 2.0.0 (2.0.0 (+ 75 patches)) Darcs David Roundy April 23, 2008 2 Contents 1 Introduction 7 1.1 Features . 9 1.2 Switching from CVS . 11 1.3 Switching from arch . 12 2 Building darcs 15 2.1 Prerequisites . 15 2.2 Building on Mac OS X . 16 2.3 Building on Microsoft Windows . 16 2.4 Building from tarball . 16 2.5 Building darcs from the repository . 17 2.6 Building darcs with git . 18 2.7 Submitting patches to darcs . 18 3 Getting started 19 3.1 Creating your repository . 19 3.2 Making changes . 20 3.3 Making your repository visible to others . 20 3.4 Getting changes made to another repository . 21 3.5 Moving patches from one repository to another . 21 3.5.1 All pulls . 21 3.5.2 Send and apply manually . 21 3.5.3 Push . 22 3.5.4 Push —apply-as . 22 3.5.5 Sending signed patches by email . 23 3.6 Reducing disk space usage . 26 3.6.1 Linking between repositories . 26 3.6.2 Alternate formats for the pristine tree . 26 4 Configuring darcs 29 4.1 prefs . 29 4.2 Environment variables . 32 4.3 General-purpose variables . 33 4.4 Remote repositories . 34 3 4 CONTENTS 4.5 Highlighted output . 36 4.6 Character escaping and non-ASCII character encodings . 36 5 Best practices 39 5.1 Introduction . 39 5.2 Creating patches . 39 5.2.1 Changes . 40 5.2.2 Keeping or discarding changes . 40 5.2.3 Unrecording changes . -

1 Thank You Very Much for Inviting Me, Kimiko. It's Always a Pleasure To
Thank you very much for inviting me, Kimiko. It’s always a pleasure to speak at Berkeley and to speak to this class. Today I want to talk about how ubiquitous computing technology creates a fuzzy boundary between products and services and to look a handful of case studies that show a range of approaches for merging products and services.! 1! But first, let me tell you a little about who I am. I’m a user experience researcher and designer. I spend much of my time thinking about how technologies and people affect each other from social, economic, historical and technological perspectives, and how the technological side of that relationship can be made better, or at least more interesting, for the human side of it. ! 2! I spent a little more than 10 years doing design and research for the web. I worked with many dotcoms, some famous, some infamous. 3! I sat out the first dotcom crash writing a book based on the work I had been doing. It’s a cookbook of user research methods that some of you may have used in a class here at the iSchool. 4! In 2001 I co-founded a design and consulting company called Adaptive Path. Things went very well, Adaptive Path is doing very well, but I was interested in other ways that technology was changing society. 5! So I founded a company with Tod E. Kurt called ThingM to pursue these ideas commercially three years ago. We're a ubiquitous computing consumer electronics company, which sounds fancy, but we’re pretty small. -
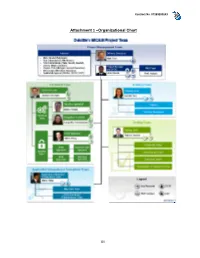
85 Attachment 1 –Organizational Chart
Contract No. 071B3200143 Attachment 1 –Organizational Chart 85 Contract No. 071B3200143 Appendix A - Breakdown of Hardware and Related Software Table 1: Hardware Cost ($): State Brand, Model # Item Specifications will provide from Comments and Description existing Contracts Total # of Virtual The hardware is Machines: 48 sized for Production, QA/Staging, Secure-24 VMware Total # of Virtual Development, and Cluster Access for CPUs: 96 Sandbox Server deploying ISIM, environments in the ISAM and ISFIM Total Virtual RAM: primary data center components 416 GB and for Production, and QA environments in the OS: RedHat Linux secondary data 6.x center The total storage is estimated for Total Storage: 35.7 Production, , TB QA/Staging, Development and Enterprise Class Sandbox Storage (3.8TB of Bronze SAN Storage Tier, 15.8TB of environments in the Silver Tier, 5.1TB of primary data center Logs Tier, 11TB of and for Production, Gold Tier) QA environments in the secondary data center CD/DVD Backup Device None None Rack w/ Power Supply Rack mountable Redundant Power Screen None None A total of 10 Web Gateway appliances are estimated for Production, QA/Staging, Web Gateway Development and Any other Hardware (list) v7.0 Hardware Appliance Sandbox environments in the primary data center and for Production, QA environments in the secondary data center. TOTAL $ 86 Contract No. 071B3200143 Table 2: Related Software Software Component Product Name Cost ($): State # of Licenses Comments License and Version will provide from existing Contracts Contractor user laptops already include this software. We will reuse the Report writers MS Office 2010 State owned software State of Michigan user licenses laptops will need this software for up to 4 users. -

Using Visual COBOL in Modern Application Development Micro Focus the Lawn 22-30 Old Bath Road Newbury, Berkshire RG14 1QN UK
Using Visual COBOL in Modern Application Development Micro Focus The Lawn 22-30 Old Bath Road Newbury, Berkshire RG14 1QN UK http://www.microfocus.com © Copyright 2018-2020 Micro Focus or one of its affiliates. MICRO FOCUS, the Micro Focus logo and Visual COBOL are trademarks or registered trademarks of Micro Focus or one of its affiliates. All other marks are the property of their respective owners. 2020-08-25 ii Contents Using Visual COBOL in Modern Application Development ........................... 4 Introduction to Modern Application Development ................................................................4 What is Modern Application Development? ..............................................................4 Key Concepts in Modern Application Development ..................................................5 Steps Involved in Modern Application Development ................................................ 6 Agile Methods ..................................................................................................................... 7 Introduction to Agile Methods ...................................................................................7 Agile Development Workflow ....................................................................................7 Agile Development and Micro Focus Development Tools .........................................9 Continuous Integration ...................................................................................................... 11 Introduction to Continuous Integration ..................................................................