Master Thesis Model-Based Eye Detection and Animation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Achieving Safe DICOM Software in Medical Devices
Master Thesis in Software Engineering & Management REPORT NO. 2009:003 ISSN: 1651-4769 Achieving Safe DICOM Software in Medical Devices Kevin Debruyn IT University of Göteborg Chalmers University of Technology and University of Gothenburg Göteborg, Sweden 2009 Student Kevin Debruyn (820717-2795) Contact Information Phone: +46 73 7418420 / Email: [email protected] Course Supervisor Karin Wagner Course Coordinator Kari Wahll Start and End Date 21 st of February 2008 to 30 th of March 2009 Size 30 Credits Subject Achieving Safe DICOM Software in Medical Devices Overview The present document constitutes the project report that introduces, develops and presents the results of the thesis carried out by a master student of the IT University in Göteborg, Software Engineering & Management during Spring 2008 through Spring 2009 at Micropos Medical AB . Summary This paper reports on an investigation on how to produce a reliable software component to extract critical information from DICOM files. The component shall manipulate safety-critical medical information, i.e. patient demographics and data specific to radiotherapy treatments including radiation target volumes and doses intensity. Handling such sensitive data can potentially lead to medical errors, and threaten the health of patients. Hence, guaranteeing reliability and safety is an essential part of the development process. Solutions for developing the component from scratch or reusing all or parts of existing systems and libraries will be evaluated and compared. The resulting component will be tested to verify that it satisfies its reliability requirements. Subsequently, the component is to be integrated within an innovating radiotherapy positioning system developed by a Swedish start-up, Micropos . -

Experimentální Porovnání Knihoven Na Detekci Emocí Pomocí Webkamery
MASARYKOVA UNIVERZITA FAKULTA INFORMATIKY Û¡¢£¤¥¦§¨ª«¬Æ°±²³´µ·¸¹º»¼½¾¿Ý Experimentální porovnání knihoven na detekci emocí pomocí webkamery DIPLOMOVÁ PRÁCE Bc. Milan Záleský Brno, podzim 2015 Prohlášení Prohlašuji, že tato diplomová práce je mým p ˚uvodnímautorským dílem, které jsem vypracoval samostatnˇe.Všechny zdroje, prameny a literaturu, které jsem pˇrivypracování používal nebo z nich ˇcerpal,v práci ˇrádnˇecituji s uvedením úplného odkazu na pˇríslušnýzdroj. Bc. Milan Záleský Vedoucí práce: RNDr. Zdenek Eichler i Klíˇcováslova OpenCV, facial expression analysis, webcam, experiment, emotion, detekce emocí, experimentální porovnání ii Podˇekování DˇekujiRNDr. Zdenku Eichlerovi, vedoucímu mé práce, za výteˇcnémento- rování, ochotu pomoci i optimistický pˇrístup, který v pr ˚ubˇehumého psaní projevil. Dˇekujisvým pˇrátel˚uma rodinˇeza opakované vyjádˇrenípodpory. V neposlední ˇradˇetaké dˇekujivšem úˇcastník˚umexperimentu, bez jejichž pˇrispˇeníbych porovnání nemohl uskuteˇcnit. iii Obsah 1 Úvod ...................................1 2 Rozpoznávání emocí ..........................2 2.1 Co je to emoce? . .2 2.2 Posouzení emocí . .3 2.3 Využití informaˇcníchtechnologií k rozpoznávání emocí . .3 2.3.1 Facial Action Coding System . .5 2.3.2 Computer vision . .6 2.3.3 OpenCV . 11 2.3.4 FaceTales . 13 3 Metoda výbˇeruknihoven pro rozpoznávání emocí ........ 15 3.1 Kritéria užšího výbˇeru . 15 3.2 Instalace knihoven . 17 3.3 Charakteristika knihoven zvolených pro srovnání . 20 3.3.1 CLMtrackr . 20 3.3.2 EmotionRecognition . 22 3.3.3 InSight SDK . 24 3.3.4 Vzájemné porovnání aplikací urˇcenýchpro experiment 25 4 Návrh experimentu ........................... 27 4.1 Pˇrípravaexperimentálního porovnání knihoven . 28 4.2 Promˇennéexperimentu . 29 4.2.1 Nezávislé promˇenné. 29 4.2.2 Závislé promˇenné . 29 4.2.3 Sledované promˇenné . 30 4.2.4 Vnˇejšípromˇenné . -
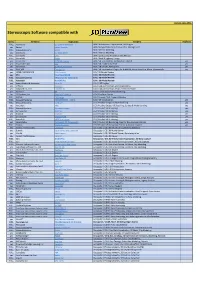
Stereo Software List
Version: June 2021 Stereoscopic Software compatible with Stereo Company Application Category Duplicate FULL Xeometric ELITECAD Architecture BIM / Architecture, Construction, CAD Engine yes Bexcel Bexcel Manager BIM / Design, Data, Project & Facilities Management FULL Dassault Systems 3DVIA BIM / Interior Modeling yes Xeometric ELITECAD Styler BIM / Interior Modeling FULL SierraSoft Land BIM / Land Survey Restitution and Analysis FULL SierraSoft Roads BIM / Road & Highway Design yes Xeometric ELITECAD Lumion BIM / VR Visualization, Architecture Models yes yes Fraunhofer IAO Vrfx BIM / VR enabled, for Revit yes yes Xeometric ELITECAD ViewerPRO BIM / VR Viewer, Free Option yes yes ENSCAPE Enscape 2.8 BIM / VR Visualization Plug-In for ArchiCAD, Revit, SketchUp, Rhino, Vectorworks yes yes OPEN CASCADE CAD CAD Assistant CAx / 3D Model Review yes PTC Creo View MCAD CAx / 3D Model Review FULL Dassault Systems eDrawings for Solidworks CAx / 3D Model Review FULL Autodesk NavisWorks CAx / 3D Model Review yes Robert McNeel & Associates. Rhino (5) CAx / CAD Engine yes Softvise Cadmium CAx / CAD, Architecture, BIM Visualization yes Gstarsoft Co., Ltd HaoChen 3D CAx / CAD, Architecture, HVAC, Electric & Power yes Siemens NX CAx / Construction & Manufacturing Yes 3D Systems, Inc. Geomagic Freeform CAx / Freeform Design FULL AVEVA E3D Design CAx / Process Plant, Power & Marine FULL Dassault Systems 3DEXPERIENCE - CATIA CAx / VR Visualization yes FULL Dassault Systems ICEM Surf CGI / Product Design, Surface Modeling yes yes Autodesk Alias CGI / Product -

An Optokinetic Nystagmus Detection Method for Use with Young Children
Medical Devices and Systems Received 4 December 2014; revised 16 February 2015; accepted 24 February 2015. Date of publication 5 March 2015; date of current version 24 March 2015. Digital Object Identifier 10.1109/JTEHM.2015.2410286 An Optokinetic Nystagmus Detection Method for Use With Young Children MEHRDAD SANGI1, (Student Member, IEEE), BENJAMIN THOMPSON2, AND JASON TURUWHENUA1 1Auckland Bioengineering Institute, University of Auckland, Auckland 1010, New Zealand 2Department of Optometry and Vision Science, University of Auckland, Auckland 1010, New Zealand CORRESPONDING AUTHOR: J. TURUWHENUA ([email protected]) This work was supported in part by the Auckland Bioengineering Institute and in part by the University of Auckland Faculty Research Development Fund under Grant 1165695. This paper has supplementary downloadable material available at http://ieeexplore.ieee.org., provided by the author. ABSTRACT The detection of vision problems in early childhood can prevent neurodevelopmental disorders such as amblyopia. However, accurate clinical assessment of visual function in young children is challenging. optokinetic nystagmus (OKN) is a reflexive sawtooth motion of the eye that occurs in response to drifting stimuli, that may allow for objective measurement of visual function in young children if appropriate child- friendly eye tracking techniques are available. In this paper, we present offline tools to detect the presence and direction of the optokinetic reflex in children using consumer grade video equipment. Our methods are tested on video footage of children (N D 5 children and 20 trials) taken as they freely observed visual stimuli that induced horizontal OKN. Using results from an experienced observer as a baseline, we found the sensitivity and specificity of our OKN detection method to be 89.13% and 98.54%, respectively, across all trials. -

Rt Visage Download
Rt visage download click here to download Visage is a contemporary blending of stunning, refined visuals, combined with a to Visage template downloads, updates, and the Visage support forum. Visage, the July theme release, is a contemporary blending of stunning, refined visuals, combined with a polished and powerful undertone, providing a. Uncertainty is the root of all fear Wander through the halls, explore each room and every corner of the house in search of an escape route. Uncertainty will. FaceTrack includes face tracking, head tracking, face detection and gaze tracking. RT Visage v - Wordpress Theme Demo: http:www.doorway.ru Turbobit download: http:www.doorway.ru Rapidgator download. SadSquare Studio is raising funds for Visage (Psychological horror game) Going this route doesn't exclude the possibility of us taking on a. GPS Industries Visage Golf Downloads Missing: rt. Visage 7 offers immediate differentiation for imaging organizations seeking to Download Visage 7 Rays Case Study – Acrobat pdf k. pdf Missing: rt. Download Visage Lab for PC - Use Andy OS to run any mobile app Support: we maintain an online real-time Facebook support group if you. Real-time telemetry information was displayed by VisAGE as it was downloaded GenSAA/Genie provided the ability to download telemetry data, maintain. Real time telemetry information was displayed by VisAGE as it was GenSAA/Genie was used to download telemetry data and maintain scheduling information. RT Visage v for Joomla , Visage, the December template have to click to download the www.doorway.ru, in germany it is possible. i use. Visage Mobile Golf Information System: revenue-improvement technology for golf operations. -

A Framework for the Manipulation of Video Game Elements Using the Player’S Biometric Data
MESTRADO MULTIMÉDIA - ESPECIALIZAÇÃO EM TECNOLOGIAS A framework for the manipulation of video game elements using the player’s biometric data Manuel César Bessa Seixas M 2016 FACULDADES PARTICIPANTES: FACULDADE DE ENGENHARIA FACULDADE DE BELAS ARTES FACULDADE DE CIÊNCIAS FACULDADE DE ECONOMIA FACULDADE DE LETRAS FACULDADE DE ENGENHARIA DA UNIVERSIDADE DO PORTO A framework for the manipulation of video game elements using the player’s biometric data Manuel César Bessa Seixas Mestrado em Multimédia Orientador: Pedro Cardoso (Assistente Convidado) Co-orientadores: Miguel Carvalhais (Professor Auxiliar) Rui Rodrigues (Professor Auxiliar) Julho de 2016 © Manuel César Bessa Seixas, 2016 A framework for the manipulation of video game elements using the player’s biometric data Manuel César Bessa Seixas Mestrado em Multimédia da Universidade do Porto Aprovado em provas públicas pelo Júri: Presidente: Nuno Honório Rodrigues Flores (Professor Auxiliar) Vogal Externo: Carlos José Ribeiro Campos (Equiparado a Assistente 1º Triénio) Orientador: Pedro Jorge Couto Cardoso (Assistente Convidado) ____________________________________________________ 15 de Julho de 2016 Abstract The following dissertation focuses on the use of several physiological signals produced by human players to manipulate several game elements. These elements comprehend the game mechanics, aesthetics, behaviour of elements that act in opposition to the player, dialogues and narrative, among others. Our objective is the development of a framework aimed at supporting games that use, or intend to use, biofeedback. Looking for a solution (and inspiration), we studied how biofeedback is being presently applied, either in scientific experiences or commercially, type of biometric sensors are available in the market, other frameworks with similar purposes, as well as profiling and dramatic tension in games. -

A Cloud Based Disaster Management System
Journal of Sensor and Actuator Networks Article A Cloud Based Disaster Management System Omar Cheikhrouhou 1,2,* , Anis Koubaa 3,4 and Anis Zarrad 5,* 1 College of Information Technology and Computer Science, Taif University, Taif 26571, Saudi Arabia 2 Computer and Embedded Systems Laboratory, Sfax University, Sfax 3029, Tunisia 3 CISTER/INESC-TEC, Polytechnic Institute of Porto, 4200 Porto, Portugal; [email protected] 4 Department of Computer Science, Prince Sultan University, Riyadh 12435, Saudi Arabia 5 School of Computer Science, University of Birmingham Dubai, Dubai 73000, UAE * Correspondence: [email protected] (O.C.); [email protected] (A.Z.) Received: 23 November 2019; Accepted: 6 January 2020; Published: 13 January 2020 Abstract: The combination of wireless sensor networks (WSNs) and 3D virtual environments opens a new paradigm for their use in natural disaster management applications. It is important to have a realistic virtual environment based on datasets received from WSNs to prepare a backup rescue scenario with an acceptable response time. This paper describes a complete cloud-based system that collects data from wireless sensor nodes deployed in real environments and then builds a 3D environment in near real-time to reflect the incident detected by sensors (fire, gas leaking, etc.). The system’s purpose is to be used as a training environment for a rescue team to develop various rescue plans before they are applied in real emergency situations. The proposed cloud architecture combines 3D data streaming and sensor data collection to build an efficient network infrastructure that meets the strict network latency requirements for 3D mobile disaster applications. -

Gpu-Accelerated Applications Gpu‑Accelerated Applications
GPU-ACCELERATED APPLICATIONS GPU-ACCELERATED APPLICATIONS Accelerated computing has revolutionized a broad range of industries with over five hundred applications optimized for GPUs to help you accelerate your work. CONTENTS 1 Computational Finance 2 Climate, Weather and Ocean Modeling 2 Data Science & Analytics 4 Deep Learning and Machine Learning 8 Defense and Intelligence 9 Manufacturing/AEC: CAD and CAE COMPUTATIONAL FLUID DYNAMICS COMPUTATIONAL STRUCTURAL MECHANICS DESIGN AND VISUALIZATION ELECTRONIC DESIGN AUTOMATION 17 Media & Entertainment ANIMATION, MODELING AND RENDERING COLOR CORRECTION AND GRAIN MANAGEMENT COMPOSITING, FINISHING AND EFFECTS EDITING ENCODING AND DIGITAL DISTRIBUTION ON-AIR GRAPHICS ON-SET, REVIEW AND STEREO TOOLS WEATHER GRAPHICS 24 Medical Imaging 27 Oil and Gas 28 Research: Higher Education and Supercomputing COMPUTATIONAL CHEMISTRY AND BIOLOGY NUMERICAL ANALYTICS PHYSICS SCIENTIFIC VISUALIZATION 39 Safety and Security 42 Tools and Management Computational Finance APPLICATION NAME COMPANY/DEVELOPER PRODUCT DESCRIPTION SUPPORTED FEATURES GPU SCALING Accelerated Elsen Secure, accessible, and accelerated back- • Web-like API with Native bindings for Multi-GPU Computing Engine testing, scenario analysis, risk analytics Python, R, Scala, C Single Node and real-time trading designed for easy • Custom models and data streams are integration and rapid development. easy to add Adaptiv Analytics SunGard A flexible and extensible engine for fast • Existing models code in C# supported Multi-GPU calculations of a wide variety of pricing transparently, with minimal code Single Node and risk measures on a broad range of changes asset classes and derivatives. • Supports multiple backends including CUDA and OpenCL • Switches transparently between multiple GPUs and CPUS depending on the deal support and load factors. -

OSINT Handbook September 2020
OPEN SOURCE INTELLIGENCE TOOLS AND RESOURCES HANDBOOK 2020 OPEN SOURCE INTELLIGENCE TOOLS AND RESOURCES HANDBOOK 2020 Aleksandra Bielska Noa Rebecca Kurz, Yves Baumgartner, Vytenis Benetis 2 Foreword I am delighted to share with you the 2020 edition of the OSINT Tools and Resources Handbook. Once again, the Handbook has been revised and updated to reflect the evolution of this discipline, and the many strategic, operational and technical challenges OSINT practitioners have to grapple with. Given the speed of change on the web, some might question the wisdom of pulling together such a resource. What’s wrong with the Top 10 tools, or the Top 100? There are only so many resources one can bookmark after all. Such arguments are not without merit. My fear, however, is that they are also shortsighted. I offer four reasons why. To begin, a shortlist betrays the widening spectrum of OSINT practice. Whereas OSINT was once the preserve of analysts working in national security, it now embraces a growing class of professionals in fields as diverse as journalism, cybersecurity, investment research, crisis management and human rights. A limited toolkit can never satisfy all of these constituencies. Second, a good OSINT practitioner is someone who is comfortable working with different tools, sources and collection strategies. The temptation toward narrow specialisation in OSINT is one that has to be resisted. Why? Because no research task is ever as tidy as the customer’s requirements are likely to suggest. Third, is the inevitable realisation that good tool awareness is equivalent to good source awareness. Indeed, the right tool can determine whether you harvest the right information. -

Gpu-Accelerated Applications Gpu‑Accelerated Applications
GPU-ACCELERATED APPLICATIONS GPU-ACCELERATED APPLICATIONS Accelerated computing has revolutionized a broad range of industries with over five hundred applications optimized for GPUs to help you accelerate your work. CONTENTS 1 Computational Finance 2 Climate, Weather and Ocean Modeling 2 Data Science and Analytics 4 Artificial Intelligence DEEP LEARNING AND MACHINE LEARNING 8 Federal, Defense and Intelligence 10 Design for Manufacturing/Construction: CAD/CAE/CAM COMPUTATIONAL FLUID DYNAMICS COMPUTATIONAL STRUCTURAL MECHANICS DESIGN AND VISUALIZATION ELECTRONIC DESIGN AUTOMATION INDUSTRIAL INSPECTION 19 Media & Entertainment ANIMATION, MODELING AND RENDERING COLOR CORRECTION AND GRAIN MANAGEMENT Test Drive the COMPOSITING, FINISHING AND EFFECTS World’s Fastest EDITING ENCODING AND DIGITAL DISTRIBUTION Accelerator – Free! ON-AIR GRAPHICS ON-SET, REVIEW AND STEREO TOOLS Take the GPU Test Drive, a free and WEATHER GRAPHICS easy way to experience accelerated computing on GPUs. You can run 29 Medical Imaging your own application or try one of the preloaded ones, all running on a 30 Oil and Gas remote cluster. Try it today. 31 Research: Higher Education and Supercomputing www.nvidia.com/gputestdrive COMPUTATIONAL CHEMISTRY AND BIOLOGY NUMERICAL ANALYTICS PHYSICS SCIENTIFIC VISUALIZATION 47 Safety and Security 49 Tools and Management Computational Finance APPLICATION NAME COMPANY/DEVELOPER PRODUCT DESCRIPTION SUPPORTED FEATURES GPU SCALING Accelerated Elsen Secure, accessible, and accelerated back- • Web-like API with Native bindings for Multi-GPU Computing Engine testing, scenario analysis, risk analytics Python, R, Scala, C Single Node and real-time trading designed for easy • Custom models and data streams are integration and rapid development. easy to add Adaptiv Analytics SunGard A flexible and extensible engine for fast • Existing models code in C# supported Multi-GPU calculations of a wide variety of pricing transparently, with minimal code Single Node and risk measures on a broad range of changes asset classes and derivatives. -

Imaging Software Wiki
Imaging software wiki click here to download This article is a comparison of notable software applications that can access or manipulate disk image files. It compares their disk image handling features.Comparison criteria · Capabilities · The comparison. Applications for macOS are often delivered online as an Apple Disk Image containing a file system that includes the Uses · Virtualization · System backup · Rapid deployment of. Drive Image (PQDI) is a software disk cloning package for Intel-based computers. The software was developed and distributed by the former PowerQuest. This is a comparison of disk cloning software, computer programs that can copy the contents of one disk into another disk or into a disk image. In computing, a system image is a serialized copy of the entire state of a computer system The DBMS can then be restarted later with the information in the database intact and proceed as though the software had never stopped. Another. Analyze is a software package developed by the Biomedical Imaging Resource (BIR) at Mayo Clinic for multi-dimensional display, processing, and. Imaging is the representation or reproduction of an object's form; especially a visual Imaging for Windows, a software product for scanning paper documents. Acronis True Image is a software product produced by Acronis that provides data protection for personal users including, backup, archive, access and recovery Stable release: New Generation / April Photogrammetry is the technique to extract geometric information from two-dimensional images 3D pup-up old 3D pup-up new, Unknown, Unknown, Standalone, No, No, single image only, Image, , Carnegie Mellon University, non. Software Imaging is based in the beautiful University city of Oxford, England. -

Bio-Formats Documentation Release 5.0.8
Bio-Formats Documentation Release 5.0.8 The Open Microscopy Environment February 07, 2015 CONTENTS I About Bio-Formats 2 1 Why Java? 4 2 Bio-Formats metadata processing 5 3 Help 6 3.1 Reporting a bug ................................................... 6 3.2 Troubleshooting ................................................... 7 4 Bio-Formats versions 9 4.1 Version history .................................................... 9 II User Information 26 5 Using Bio-Formats with ImageJ and Fiji 27 5.1 ImageJ overview ................................................... 27 5.2 Fiji overview ..................................................... 28 5.3 Bio-Formats features in ImageJ and Fiji ....................................... 28 5.4 Installing Bio-Formats in ImageJ .......................................... 29 5.5 Using Bio-Formats to load images into ImageJ ................................... 31 5.6 Managing memory in ImageJ/Fiji using Bio-Formats ................................ 34 6 Command line tools 38 6.1 Command line tools introduction .......................................... 38 6.2 Displaying images and metadata ........................................... 39 6.3 Converting a file to different format ......................................... 40 6.4 Validating XML in an OME-TIFF .......................................... 41 6.5 Editing XML in an OME-TIFF ........................................... 42 7 OMERO 43 8 Image server applications 44 8.1 BISQUE ....................................................... 44 8.2 OME Server ....................................................