Interpretation of Multiple Probe Sets Mapping to the Same Gene in Affymetrix Genechips Maria a Stalteri and Andrew P Harrison*
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

CD29 Identifies IFN-Γ–Producing Human CD8+ T Cells With
+ CD29 identifies IFN-γ–producing human CD8 T cells with an increased cytotoxic potential Benoît P. Nicoleta,b, Aurélie Guislaina,b, Floris P. J. van Alphenc, Raquel Gomez-Eerlandd, Ton N. M. Schumacherd, Maartje van den Biggelaarc,e, and Monika C. Wolkersa,b,1 aDepartment of Hematopoiesis, Sanquin Research, 1066 CX Amsterdam, The Netherlands; bLandsteiner Laboratory, Oncode Institute, Amsterdam University Medical Center, University of Amsterdam, 1105 AZ Amsterdam, The Netherlands; cDepartment of Research Facilities, Sanquin Research, 1066 CX Amsterdam, The Netherlands; dDivision of Molecular Oncology and Immunology, Oncode Institute, The Netherlands Cancer Institute, 1066 CX Amsterdam, The Netherlands; and eDepartment of Molecular and Cellular Haemostasis, Sanquin Research, 1066 CX Amsterdam, The Netherlands Edited by Anjana Rao, La Jolla Institute for Allergy and Immunology, La Jolla, CA, and approved February 12, 2020 (received for review August 12, 2019) Cytotoxic CD8+ T cells can effectively kill target cells by producing therefore developed a protocol that allowed for efficient iso- cytokines, chemokines, and granzymes. Expression of these effector lation of RNA and protein from fluorescence-activated cell molecules is however highly divergent, and tools that identify and sorting (FACS)-sorted fixed T cells after intracellular cytokine + preselect CD8 T cells with a cytotoxic expression profile are lacking. staining. With this top-down approach, we performed an un- + Human CD8 T cells can be divided into IFN-γ– and IL-2–producing biased RNA-sequencing (RNA-seq) and mass spectrometry cells. Unbiased transcriptomics and proteomics analysis on cytokine- γ– – + + (MS) analyses on IFN- and IL-2 producing primary human producing fixed CD8 T cells revealed that IL-2 cells produce helper + + + CD8 Tcells. -
Supplementary Figures and Tables
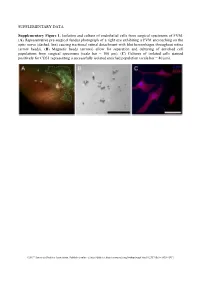
SUPPLEMENTARY DATA Supplementary Figure 1. Isolation and culture of endothelial cells from surgical specimens of FVM. (A) Representative pre-surgical fundus photograph of a right eye exhibiting a FVM encroaching on the optic nerve (dashed line) causing tractional retinal detachment with blot hemorrhages throughout retina (arrow heads). (B) Magnetic beads (arrows) allow for separation and culturing of enriched cell populations from surgical specimens (scale bar = 100 μm). (C) Cultures of isolated cells stained positively for CD31 representing a successfully isolated enriched population (scale bar = 40 μm). ©2017 American Diabetes Association. Published online at http://diabetes.diabetesjournals.org/lookup/suppl/doi:10.2337/db16-1035/-/DC1 SUPPLEMENTARY DATA Supplementary Figure 2. Efficient siRNA knockdown of RUNX1 expression and function demonstrated by qRT-PCR, Western Blot, and scratch assay. (A) RUNX1 siRNA induced a 60% reduction of RUNX1 expression measured by qRT-PCR 48 hrs post-transfection whereas expression of RUNX2 and RUNX3, the two other mammalian RUNX orthologues, showed no significant changes, indicating specificity of our siRNA. Functional inhibition of Runx1 signaling was demonstrated by a 330% increase in insulin-like growth factor binding protein-3 (IGFBP3) RNA expression level, a known target of RUNX1 inhibition. Western blot demonstrated similar reduction in protein levels. (B) siRNA- 2’s effect on RUNX1 was validated by qRT-PCR and western blot, demonstrating a similar reduction in both RNA and protein. Scratch assay demonstrates functional inhibition of RUNX1 by siRNA-2. ns: not significant, * p < 0.05, *** p < 0.001 ©2017 American Diabetes Association. Published online at http://diabetes.diabetesjournals.org/lookup/suppl/doi:10.2337/db16-1035/-/DC1 SUPPLEMENTARY DATA Supplementary Table 1. -

Molecular Distinctions Between Pediatric and Adult Mature B-Cell Non-Hodgkin Lymphomas Identified Through Genomic Profiling
University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln Public Health Resources Public Health Resources 4-19-2012 Molecular distinctions between pediatric and adult mature B-cell non-Hodgkin lymphomas identified through genomic profiling Karen Deffenbacher University of Nebraska Medical Center, Omaha Javeed Iqbal University of Nebraska Medical Center, Omaha Warren Sanger University of Nebraska Medical Center, Omaha Yulei Shen University of Nebraska Medical Center, Omaha Cynthia Lachel University of Nebraska Medical Center, Omaha See next page for additional authors Follow this and additional works at: https://digitalcommons.unl.edu/publichealthresources Part of the Public Health Commons Deffenbacher, Karen; Iqbal, Javeed; Sanger, Warren; Shen, Yulei; Lachel, Cynthia; Liu, Zhongfeng; Liu, Yanyan; Lim, Megan; Perkins, Sherrie; Fu, Kai; Smith, Lynette; Lynch, James; Staudt, Louis; Rimsza, Lisa M.; Jaffe, Elaine; Rosenwald, Andreas; Ott, German; Delabie, Jan; Campo, Elias; Gascoyne, Randy; Cairo, Mitchell; Weisenburger, Dennis; Greiner, Timothy; Gross, Thomas; and Chan, Wing, "Molecular distinctions between pediatric and adult mature B-cell non-Hodgkin lymphomas identified through genomic profiling" (2012). Public Health Resources. 145. https://digitalcommons.unl.edu/publichealthresources/145 This Article is brought to you for free and open access by the Public Health Resources at DigitalCommons@University of Nebraska - Lincoln. It has been accepted for inclusion in Public Health Resources by an authorized administrator -

Murine Surf4 Is Essential for Early Embryonic Development
Washington University School of Medicine Digital Commons@Becker Open Access Publications 1-1-2020 Murine Surf4 is essential for early embryonic development Brian T. Emmer Paul J. Lascuna Vi T. Tang Emilee N. Kotnik Thomas L. Saunders See next page for additional authors Follow this and additional works at: https://digitalcommons.wustl.edu/open_access_pubs Authors Brian T. Emmer, Paul J. Lascuna, Vi T. Tang, Emilee N. Kotnik, Thomas L. Saunders, Rami Khoriaty, and David Ginsburg RESEARCH ARTICLE Murine Surf4 is essential for early embryonic development 1,2 2 2,3 2¤ Brian T. EmmerID , Paul J. Lascuna , Vi T. Tang , Emilee N. KotnikID , Thomas 1,4,5 1,5,6,7 1,2,5,6,8,9,10 L. SaundersID , Rami Khoriaty , David Ginsburg * 1 Department of Internal Medicine, University of Michigan, Ann Arbor, Michigan, 2 Life Sciences Institute, University of Michigan, Ann Arbor, Michigan, 3 Department of Molecular and Integrative Physiology, University of Michigan, Ann Arbor, Michigan, 4 Transgenic Animal Model Core Laboratory, University of Michigan, Ann Arbor, Michigan, 5 University of Michigan Rogel Cancer Center, Ann Arbor, Michigan, a1111111111 6 Cellular and Molecular Biology Program, University of Michigan, Ann Arbor, Michigan, 7 Department of Cell a1111111111 and Developmental Biology, University of Michigan, Ann Arbor, Michigan, 8 Department of Human Genetics, University of Michigan, Ann Arbor, Michigan, 9 Department of Pediatrics, University of Michigan, Ann Arbor, a1111111111 Michigan, 10 Howard Hughes Medical Institute, University of Michigan, Ann Arbor, Michigan a1111111111 a1111111111 ¤ Current address: Molecular Genetics and Genomics Program, Washington University in St. Louis, St. Louis, Missouri * [email protected] OPEN ACCESS Abstract Citation: Emmer BT, Lascuna PJ, Tang VT, Kotnik EN, Saunders TL, Khoriaty R, et al. -

A Concise Review of Human Brain Methylome During Aging and Neurodegenerative Diseases
BMB Rep. 2019; 52(10): 577-588 BMB www.bmbreports.org Reports Invited Mini Review A concise review of human brain methylome during aging and neurodegenerative diseases Renuka Prasad G & Eek-hoon Jho* Department of Life Science, University of Seoul, Seoul 02504, Korea DNA methylation at CpG sites is an essential epigenetic mark position of carbon in the cytosine within CG dinucleotides that regulates gene expression during mammalian development with resultant formation of 5mC. The symmetrical CG and diseases. Methylome refers to the entire set of methylation dinucleotides are also called as CpG, due to the presence of modifications present in the whole genome. Over the last phosphodiester bond between cytosine and guanine. The several years, an increasing number of reports on brain DNA human genome contains short lengths of DNA (∼1,000 bp) in methylome reported the association between aberrant which CpG is commonly located (∼1 per 10 bp) in methylation and the abnormalities in the expression of critical unmethylated form and referred as CpG islands; they genes known to have critical roles during aging and neuro- commonly overlap with the transcription start sites (TSSs) of degenerative diseases. Consequently, the role of methylation genes. In human DNA, 5mC is present in approximately 1.5% in understanding neurodegenerative diseases has been under of the whole genome and CpG base pairs are 5-fold enriched focus. This review outlines the current knowledge of the human in CpG islands than other regions of the genome (3, 4). CpG brain DNA methylomes during aging and neurodegenerative islands have the following salient features. In the human diseases. -

(12) Patent Application Publication (10) Pub. No.: US 2012/0322864 A1 Rossi Et Al
US 2012O322864A1 (19) United States (12) Patent Application Publication (10) Pub. No.: US 2012/0322864 A1 Rossi et al. (43) Pub. Date: Dec. 20, 2012 (54) SUSTAINED POLYPEPTIDE EXPRESSION (60) Provisional application No. 61/325,003, filed on Apr. FROM SYNTHETIC, MODIFIED RNAS AND 16, 2010, provisional application No. 61/387,220, USES THEREOF filed on Sep. 28, 2010. Publication Classification (75) Inventors: Derrick Rossi, Roslindale, MA (US); (51) Int. Cl. Luigi Warren, Cambridge, MA (US) CI2N5/07 (2010.01) A6IR 48/00 (2006.01) (73) Assignee: IMMUNE DISEASE INSTITUTE, C7H 2L/02 (2006.01) INC., Boston, MA (US) (52) U.S. Cl. ...................... 514/44 R; 536/23.5; 435/377 (57) ABSTRACT (21) Appl. No.: 13/590,880 Described herein are synthetic, modified RNAs for changing the phenotype of a cell. Such as expressing a polypeptide or altering the developmental potential. Accordingly, provided (22) Filed: Aug. 21, 2012 herein are compositions, methods, and kits comprising Syn thetic, modified RNAs for changing the phenotype of a cellor Related U.S. Application Data cells. These methods, compositions, and kits comprising Syn thetic, modified RNAs can be used either to express a desired (63) Continuation of application No. 13/088,009, filed on protein in a cell or tissue, or to change the differentiated Apr. 15, 2011. phenotype of a cell to that of another, desired cell type. Patent Application Publication Dec. 20, 2012 Sheet 1 of 45 US 2012/0322864 A1 s se xxx S s s nnnn s e sit. occa S. s Ra w s e s S. iiii is is iiiiSE SEE SS Patent Application Publication Dec. -

Comparative Analysis of the Ubiquitin-Proteasome System in Homo Sapiens and Saccharomyces Cerevisiae
Comparative Analysis of the Ubiquitin-proteasome system in Homo sapiens and Saccharomyces cerevisiae Inaugural-Dissertation zur Erlangung des Doktorgrades der Mathematisch-Naturwissenschaftlichen Fakultät der Universität zu Köln vorgelegt von Hartmut Scheel aus Rheinbach Köln, 2005 Berichterstatter: Prof. Dr. R. Jürgen Dohmen Prof. Dr. Thomas Langer Dr. Kay Hofmann Tag der mündlichen Prüfung: 18.07.2005 Zusammenfassung I Zusammenfassung Das Ubiquitin-Proteasom System (UPS) stellt den wichtigsten Abbauweg für intrazelluläre Proteine in eukaryotischen Zellen dar. Das abzubauende Protein wird zunächst über eine Enzym-Kaskade mit einer kovalent gebundenen Ubiquitinkette markiert. Anschließend wird das konjugierte Substrat vom Proteasom erkannt und proteolytisch gespalten. Ubiquitin besitzt eine Reihe von Homologen, die ebenfalls posttranslational an Proteine gekoppelt werden können, wie z.B. SUMO und NEDD8. Die hierbei verwendeten Aktivierungs- und Konjugations-Kaskaden sind vollständig analog zu der des Ubiquitin- Systems. Es ist charakteristisch für das UPS, daß sich die Vielzahl der daran beteiligten Proteine aus nur wenigen Proteinfamilien rekrutiert, die durch gemeinsame, funktionale Homologiedomänen gekennzeichnet sind. Einige dieser funktionalen Domänen sind auch in den Modifikations-Systemen der Ubiquitin-Homologen zu finden, jedoch verfügen diese Systeme zusätzlich über spezifische Domänentypen. Homologiedomänen lassen sich als mathematische Modelle in Form von Domänen- deskriptoren (Profile) beschreiben. Diese Deskriptoren können wiederum dazu verwendet werden, mit Hilfe geeigneter Verfahren eine gegebene Proteinsequenz auf das Vorliegen von entsprechenden Homologiedomänen zu untersuchen. Da die im UPS involvierten Homologie- domänen fast ausschließlich auf dieses System und seine Analoga beschränkt sind, können domänen-spezifische Profile zur Katalogisierung der UPS-relevanten Proteine einer Spezies verwendet werden. Auf dieser Basis können dann die entsprechenden UPS-Repertoires verschiedener Spezies miteinander verglichen werden. -

DISCOVERY and CHARACTERIZATION of LONG NON-CODING Rnas in PROSTATE CANCER by John R. Prensner a Dissertation Submitted in Parti
DISCOVERY AND CHARACTERIZATION OF LONG NON-CODING RNAs IN PROSTATE CANCER by John R. Prensner A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy (Molecular and Cellular Pathology) in the University of Michigan 2012 Doctoral Committee: Professor Arul M. Chinnaiyan, Chair Professor David Beer Professor Kathleen Cho Professor David Ginsburg Assistant Professor Yali Dou © John R. Prensner All Rights Reserved 2012 ACKNOWLEDGEMENTS This work represents the combined efforts of many talented individuals. First, my mentor, Arul Chinnaiyan, deserves much credit for guiding me through this experience and pushing me to produce the best science that I could. My thesis committee—Kathy Cho, David Beer, David Ginsburg, and Yali Dou—was an integral part of my development and I am truly grateful for their participation in my education. I am also indebted to the many collaborators who have contributed to this work. Foremost, Matthew Iyer has been responsible for much of my progress and has been an invaluable colleague. Saravana M. Dhanasekaran mentored me and taught me much of what I know. Wei Chen has spent countless hours working on these projects. I have also been fortunate to collaborate with Felix Feng, Qi Cao, Alejandro Balbin, Sameek Roychowdhury, Brendan Veeneman, Lalit Patel, Anirban Sahu, Chad Brenner, Irfan Asangani, and Xuhong Cao who have helped to make this thesis possible. I would like to extend my appreciation to my wonderful support network at MCTP and the MSTP office: Karen Giles, Christine Betts, Dianna Banka, Ron Koenig, Ellen Elkin, and Hilkka Ketola, who have been immensely supportive and helpful during my training. -

A General Role for MIA3/TANGO1 in Secretory Pathway Organization and Function
© 2021. Published by The Company of Biologists Ltd. This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by /4.0), which permits unrestricted use, distribution and reproduction in any medium provided that the original work is properly attributed. A general role for MIA3/TANGO1 in secretory pathway organization and function Janine McCaughey1†, Nicola L. Stevenson1, Judith M. Mantell2, Chris R. Neal2, Alex Paterson3, Kate Heesom4, and David J. Stephens1* 1Cell Biology Laboratories, School of Biochemistry, Faculty of Life Sciences, University Walk, University of Bristol, Bristol, BS8 1TD, UK. 2Wolfson Bioimaging Facility, Faculty of Life Sciences, University Walk, University of Bristol, Bristol, BS8 1TD, UK. 3 In Silico Consulting, Winchester, UK. 4Proteomics Facility, Faculty of Life Sciences, University Walk, University of Bristol, Bristol, BS8 1TD, UK. *Correspondence to: [email protected]. †Current address: Utrecht University, Kruytgebouw, Padualaan 8, 3584 CH Utrecht, The Netherlands ORCID: JM: 0000-0001-7709-2597 NS: 0000-0001-8967-7277 JMM: 0000-0002-9061-8933 CRN: 0000-0001-6604-280X AP: 0000-0003-3025-8347 KH: 0000-0002-5418-5392 DJS: 0000-0001-5297-3240 Keywords: Secretory pathway, COPII, collagen, Golgi, TANGO1, ERGIC Summary statement: TANGO1 is required to maintain the fundamental organization of the early secretory pathway in mammalian cells to support secretion of a diverse range of newly synthesized cargo proteins. Abstract Complex machinery is required to drive secretory cargo export from the endoplasmic reticulum, an essential process in eukaryotic cells. In vertebrates, the Mia3 gene encodes two major forms of Transport ANd Golgi Organization Protein 1 (TANGO1S and TANGO1L), previously implicated in selective trafficking of procollagen. -

Content Based Search in Gene Expression Databases and a Meta-Analysis of Host Responses to Infection
Content Based Search in Gene Expression Databases and a Meta-analysis of Host Responses to Infection A Thesis Submitted to the Faculty of Drexel University by Francis X. Bell in partial fulfillment of the requirements for the degree of Doctor of Philosophy November 2015 c Copyright 2015 Francis X. Bell. All Rights Reserved. ii Acknowledgments I would like to acknowledge and thank my advisor, Dr. Ahmet Sacan. Without his advice, support, and patience I would not have been able to accomplish all that I have. I would also like to thank my committee members and the Biomed Faculty that have guided me. I would like to give a special thanks for the members of the bioinformatics lab, in particular the members of the Sacan lab: Rehman Qureshi, Daisy Heng Yang, April Chunyu Zhao, and Yiqian Zhou. Thank you for creating a pleasant and friendly environment in the lab. I give the members of my family my sincerest gratitude for all that they have done for me. I cannot begin to repay my parents for their sacrifices. I am eternally grateful for everything they have done. The support of my sisters and their encouragement gave me the strength to persevere to the end. iii Table of Contents LIST OF TABLES.......................................................................... vii LIST OF FIGURES ........................................................................ xiv ABSTRACT ................................................................................ xvii 1. A BRIEF INTRODUCTION TO GENE EXPRESSION............................. 1 1.1 Central Dogma of Molecular Biology........................................... 1 1.1.1 Basic Transfers .......................................................... 1 1.1.2 Uncommon Transfers ................................................... 3 1.2 Gene Expression ................................................................. 4 1.2.1 Estimating Gene Expression ............................................ 4 1.2.2 DNA Microarrays ...................................................... -

A Unique Collection of Neurodevelopmental Genes
7586 • The Journal of Neuroscience, August 17, 2005 • 25(33):7586–7600 Development/Plasticity/Repair Telencephalic Embryonic Subtractive Sequences: A Unique Collection of Neurodevelopmental Genes Alessandro Bulfone,2 Pietro Carotenuto,1,3* Andrea Faedo,2* Veruska Aglio,1* Livia Garzia,1,3 Anna Maria Bello,1 Andrea Basile,2 Alessandra Andre`,1 Massimo Cocchia,3 Ombretta Guardiola,1 Andrea Ballabio,3 John L. R. Rubenstein,4 and Massimo Zollo1 1Centro di Ingegneria Genetica e Biotecnologie Avanzate, 80145 Napoli, Italy, 2Stem Cell Research Institute–Hospital San Raffaele, Istituto Scientifico San Raffaele, 20132 Milan, Italy, 3Telethon Institute of Genetics and Medicine, 80131 Naples, Italy, and 4Nina Ireland Laboratory of Developmental Neurobiology, Center for Neurobiology and Psychiatry Genetics, University of California at San Francisco, San Francisco, California 94143-2611 The vertebrate telencephalon is composed of many architectonically and functionally distinct areas and structures, with billions of neurons that are precisely connected. This complexity is fine-tuned during development by numerous genes. To identify genes involved in the regulation of telencephalic development, a specific subset of differentially expressed genes was characterized. Here, we describe a set of cDNAs encoded by genes preferentially expressed during development of the mouse telencephalon that was identified through a functional genomics approach. Of 832 distinct transcripts found, 223 (27%) are known genes. Of the remaining, 228 (27%) correspond to expressed sequence tags of unknown function, 58 (7%) are homologs or orthologs of known genes, and 323 (39%) correspond to novel rare transcripts, including 48 (14%) new putative noncoding RNAs. As an example of this latter group of novel precursor transcripts of micro-RNAs, telencephalic embryonic subtractive sequence (TESS) 24.E3 was functionally characterized, and one of its targets was identified: the zinc finger transcription factor ZFP9. -

A Concise Review of Human Brain Methylome During Aging and Neurodegenerative Diseases
BMB Rep. 2019; 52(10): 577-588 BMB www.bmbreports.org Reports Invited Mini Review A concise review of human brain methylome during aging and neurodegenerative diseases Renuka Prasad G & Eek-hoon Jho* Department of Life Science, University of Seoul, Seoul 02504, Korea DNA methylation at CpG sites is an essential epigenetic mark position of carbon in the cytosine within CG dinucleotides that regulates gene expression during mammalian development with resultant formation of 5mC. The symmetrical CG and diseases. Methylome refers to the entire set of methylation dinucleotides are also called as CpG, due to the presence of modifications present in the whole genome. Over the last phosphodiester bond between cytosine and guanine. The several years, an increasing number of reports on brain DNA human genome contains short lengths of DNA (∼1,000 bp) in methylome reported the association between aberrant which CpG is commonly located (∼1 per 10 bp) in methylation and the abnormalities in the expression of critical unmethylated form and referred as CpG islands; they genes known to have critical roles during aging and neuro- commonly overlap with the transcription start sites (TSSs) of degenerative diseases. Consequently, the role of methylation genes. In human DNA, 5mC is present in approximately 1.5% in understanding neurodegenerative diseases has been under of the whole genome and CpG base pairs are 5-fold enriched focus. This review outlines the current knowledge of the human in CpG islands than other regions of the genome (3, 4). CpG brain DNA methylomes during aging and neurodegenerative islands have the following salient features. In the human diseases.