Discovering Pharmacogenomic Variants and Pathways with the Epigenome and Spatial Genome
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Association Analyses of Known Genetic Variants with Gene
ASSOCIATION ANALYSES OF KNOWN GENETIC VARIANTS WITH GENE EXPRESSION IN BRAIN by Viktoriya Strumba A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy (Bioinformatics) in The University of Michigan 2009 Doctoral Committee: Professor Margit Burmeister, Chair Professor Huda Akil Professor Brian D. Athey Assistant Professor Zhaohui S. Qin Research Statistician Thomas Blackwell To Sam and Valentina Dmitriy and Elizabeth ii ACKNOWLEDGEMENTS I would like to thank my advisor Professor Margit Burmeister, who tirelessly guided me though seemingly impassable corridors of graduate work. Throughout my thesis writing period she provided sound advice, encouragement and inspiration. Leading by example, her enthusiasm and dedication have been instrumental in my path to becoming a better scientist. I also would like to thank my co-advisor Tom Blackwell. His careful prodding always kept me on my toes and looking for answers, which taught me the depth of careful statistical analysis. His diligence and dedication have been irreplaceable in most difficult of projects. I also would like to thank my other committee members: Huda Akil, Brian Athey and Steve Qin as well as David States. You did not make it easy for me, but I thank you for believing and not giving up. Huda’s eloquence in every subject matter she explained have been particularly inspiring, while both Huda’s and Brian’s valuable advice made the completion of this dissertation possible. I would also like to thank all the members of the Burmeister lab, both past and present: Sandra Villafuerte, Kristine Ito, Cindy Schoen, Karen Majczenko, Ellen Schmidt, Randi Burns, Gang Su, Nan Xiang and Ana Progovac. -

Analysis of Trans Esnps Infers Regulatory Network Architecture
Analysis of trans eSNPs infers regulatory network architecture Anat Kreimer Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Graduate School of Arts and Sciences COLUMBIA UNIVERSITY 2014 © 2014 Anat Kreimer All rights reserved ABSTRACT Analysis of trans eSNPs infers regulatory network architecture Anat Kreimer eSNPs are genetic variants associated with transcript expression levels. The characteristics of such variants highlight their importance and present a unique opportunity for studying gene regulation. eSNPs affect most genes and their cell type specificity can shed light on different processes that are activated in each cell. They can identify functional variants by connecting SNPs that are implicated in disease to a molecular mechanism. Examining eSNPs that are associated with distal genes can provide insights regarding the inference of regulatory networks but also presents challenges due to the high statistical burden of multiple testing. Such association studies allow: simultaneous investigation of many gene expression phenotypes without assuming any prior knowledge and identification of unknown regulators of gene expression while uncovering directionality. This thesis will focus on such distal eSNPs to map regulatory interactions between different loci and expose the architecture of the regulatory network defined by such interactions. We develop novel computational approaches and apply them to genetics-genomics data in human. We go beyond pairwise interactions to define network motifs, including regulatory modules and bi-fan structures, showing them to be prevalent in real data and exposing distinct attributes of such arrangements. We project eSNP associations onto a protein-protein interaction network to expose topological properties of eSNPs and their targets and highlight different modes of distal regulation. -

A New Genetic Method for Isolating Functionally Interacting Genes
Copyright 2000 by the Genetics Society of America A New Genetic Method for Isolating Functionally Interacting Genes: High plo1؉-Dependent Mutants and Their Suppressors De®ne Genes in Mitotic and Septation Pathways in Fission Yeast C. Fiona Cullen,*,² Karen M. May,* Iain M. Hagan,³ David M. Glover²,§ and Hiroyuki Ohkura*,² *Institute of Cell and Molecular Biology, The University of Edinburgh, Edinburgh EH9 3JR, United Kingdom, ²Department of Anatomy and Physiology, Medical Sciences Institute, The University of Dundee, Dundee DD1 4HN, United Kingdom, ³School of Biological Sciences, The University of Manchester, Manchester M13 9PT, United Kingdom and §Department of Genetics, University of Cambridge, Cambridge CB2 3EH, United Kingdom Manuscript received February 2, 2000 Accepted for publication April 10, 2000 ABSTRACT We describe a general genetic method to identify genes encoding proteins that functionally interact with and/or are good candidates for downstream targets of a particular gene product. The screen identi®es mutants whose growth depends on high levels of expression of that gene. We apply this to the plo1ϩ gene that encodes a ®ssion yeast homologue of the polo-like kinases. plo1ϩ regulates both spindle formation and septation. We have isolated 17 high plo1ϩ-dependent (pld) mutants that show defects in mitosis or septation. Three mutants show a mitotic arrest phenotype. Among the 14 pld mutants with septation defects, 12 mapped to known loci: cdc7, cdc15, cdc11 spg1, and sid2. One of the pld mutants, cdc7-PD1, was selected for suppressor analysis. As multicopy suppressors, we isolated four known genes involved in septation in ®ssion yeast: spg1ϩ, sce3ϩ, cdc8ϩ, and rho1ϩ, and two previously uncharacterized genes, mpd1ϩ and mpd2ϩ. -

Diseasespecific and Inflammationindependent Stromal
Full Length Arthritis & Rheumatism DOI 10.1002/art.37704 Disease-specific and inflammation-independent stromal alterations in spondyloarthritis synovitis Nataliya Yeremenko1,2, Troy Noordenbos1,2, Tineke Cantaert1,3, Melissa van Tok1,2, Marleen van de Sande1, Juan D. Cañete4, Paul P. Tak1,5*, Dominique Baeten1,2 1Department of Clinical Immunology and Rheumatology and 2Department of Experimental Immunology, Academic Medical Center/University of Amsterdam, the Netherlands. 3Department of Immunobiology, Yale University School of Medicine, New Haven, CT, USA. 4Department of Rheumatology, Hospital Clinic de Barcelona and IDIBAPS, Spain. 5Arthrogen B.V., Amsterdam, the Netherlands. *Currently also: GlaxoSmithKline, Stevenage, U.K. Corresponding author: Dominique Baeten, MD, PhD, Department of Clinical Immunology and Rheumatology, F4-105, Academic Medical Center/University of Amsterdam, Meibergdreef 9, 1105 AZ Amsterdam, The Netherlands. E-mail: [email protected] This article has been accepted for publication and undergone full peer review but has not been through the copyediting, typesetting, pagination and proofreading process which may lead to differences between this version and the Version of Record. Please cite this article as an ‘Accepted Article’, doi: 10.1002/art.37704 © 2012 American College of Rheumatology Received: Apr 11, 2012; Revised: Jul 25, 2012; Accepted: Sep 06, 2012 Arthritis & Rheumatism Page 2 of 36 Abstract Objective: The molecular processes driving the distinct patterns of synovial inflammation and tissue remodelling in spondyloarthritis (SpA) versus rheumatoid arthritis (RA) remain largely unknown. Therefore, we aimed to identify novel and unsuspected disease- specific pathways in SpA by a systematic and unbiased synovial gene expression analysis. Methods: Differentially expressed genes were identified by pan-genomic microarray and confirmed by quantitative PCR and immunohistochemistry using synovial tissue biopsies of SpA (n=63), RA (n=28) and gout (n=9) patients. -

Efficacy and Mechanistic Evaluation of Tic10, a Novel Antitumor Agent
University of Pennsylvania ScholarlyCommons Publicly Accessible Penn Dissertations 2012 Efficacy and Mechanisticv E aluation of Tic10, A Novel Antitumor Agent Joshua Edward Allen University of Pennsylvania, [email protected] Follow this and additional works at: https://repository.upenn.edu/edissertations Part of the Oncology Commons Recommended Citation Allen, Joshua Edward, "Efficacy and Mechanisticv E aluation of Tic10, A Novel Antitumor Agent" (2012). Publicly Accessible Penn Dissertations. 488. https://repository.upenn.edu/edissertations/488 This paper is posted at ScholarlyCommons. https://repository.upenn.edu/edissertations/488 For more information, please contact [email protected]. Efficacy and Mechanisticv E aluation of Tic10, A Novel Antitumor Agent Abstract TNF-related apoptosis-inducing ligand (TRAIL; Apo2L) is an endogenous protein that selectively induces apoptosis in cancer cells and is a critical effector in the immune surveillance of cancer. Recombinant TRAIL and TRAIL-agonist antibodies are in clinical trials for the treatment of solid malignancies due to the cancer-specific cytotoxicity of TRAIL. Recombinant TRAIL has a short serum half-life and both recombinant TRAIL and TRAIL receptor agonist antibodies have a limited capacity to perfuse to tissue compartments such as the brain, limiting their efficacy in certain malignancies. To overcome such limitations, we searched for small molecules capable of inducing the TRAIL gene using a high throughput luciferase reporter gene assay. We selected TRAIL-inducing compound 10 (TIC10) for further study based on its induction of TRAIL at the cell surface and its promising therapeutic index. TIC10 is a potent, stable, and orally active antitumor agent that crosses the blood-brain barrier and transcriptionally induces TRAIL and TRAIL-mediated cell death in a p53-independent manner. -

HHS Public Access Author Manuscript
HHS Public Access Author manuscript Author Manuscript Author ManuscriptAm J Med Author Manuscript Genet B Neuropsychiatr Author Manuscript Genet. Author manuscript; available in PMC 2015 December 01. Published in final edited form as: Am J Med Genet B Neuropsychiatr Genet. 2014 December ; 0(8): 673–683. doi:10.1002/ajmg.b.32272. Association and ancestry analysis of sequence variants in ADH and ALDH using alcohol-related phenotypes in a Native American community sample Qian Peng1,2,*, Ian R. Gizer3, Ondrej Libiger2, Chris Bizon4, Kirk C. Wilhelmsen4,5, Nicholas J. Schork1, and Cindy L. Ehlers6,* 1 Department of Human Biology, J. Craig Venter Institute, La Jolla, CA 92037 2 Scripps Translational Science Institute, The Scripps Research Institute, La Jolla, CA 92037 3 Department of Psychological Sciences, University of Missouri-Columbia, Columbia, MO 65211 4 Renaissance Computing Institute, University of North Carolina at Chapel Hill, Chapel Hill, NC 27517 5 Department of Genetics and Neurology, University of North Carolina at Chapel Hill, Chapel Hill, NC 27599 6 Department of Molecular and Cellular Neuroscience, The Scripps Research Institute, La Jolla, CA 92037 Abstract Higher rates of alcohol use and other drug-dependence have been observed in some Native American populations relative to other ethnic groups in the U.S. Previous studies have shown that alcohol dehydrogenase (ADH) genes and aldehyde dehydrogenase (ALDH) genes may affect the risk of development of alcohol dependence, and that polymorphisms within these genes may differentially affect risk for the disorder depending on the ethnic group evaluated. We evaluated variations in the ADH and ALDH genes in a large study investigating risk factors for substance use in a Native American population. -

TRANSCRIPTION REGULATION of the CLASS IV ALCOHOL DEHYDROGENASE 7 (ADH7) Sowmya Jairam Submitted to the Faculty of the University
TRANSCRIPTION REGULATION OF THE CLASS IV ALCOHOL DEHYDROGENASE 7 (ADH7) Sowmya Jairam Submitted to the faculty of the University Graduate School in partial fulfillment of the requirements for the degree Doctor of Philosophy in the Department of Biochemistry and Molecular Biology, Indiana University May 2014 Accepted by the Graduate Faculty, of Indiana University, in partial fulfillment of the requirements for the degree of Doctor of Philosophy. Howard J. Edenberg, Ph.D., Chair Brian P. Herring, Ph.D. Doctoral Committee David G. Skalnik, Ph.D. January 21, 2014 Ronald C. Wek, Ph.D. ii ACKNOWLEDGEMENTS I would like to thank my advisor, Dr. Howard Edenberg, for his guidance and support throughout my time in his lab. He fostered the ability to think independently by asking questions and letting me find the answers, even those I didn’t have readily, while making sure I was on the right track. I know the lessons I have learnt and the training I have received will stand me in good stead in my career. I would also like to thank all the current and former lab members at both the MS building and BRTC, particularly Jun Wang, Dr. Jeanette McClintick, Ron Jerome and Dr. Sirisha Pochareddy for their mentoring and friendship. They have been a great help and an immense support whenever I needed to get a second opinion on a technique or a research idea, and I have enjoyed discussing both scientific and non-scientific topics with them. I would like to thank my committee members Dr. Paul Herring, Dr. David Skalnik and Dr. -
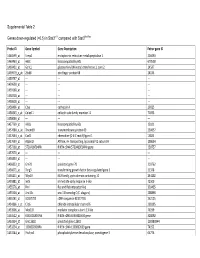
0.5) in Stat3∆/∆ Compared with Stat3flox/Flox
Supplemental Table 2 Genes down-regulated (<0.5) in Stat3∆/∆ compared with Stat3flox/flox Probe ID Gene Symbol Gene Description Entrez gene ID 1460599_at Ermp1 endoplasmic reticulum metallopeptidase 1 226090 1460463_at H60c histocompatibility 60c 670558 1460431_at Gcnt1 glucosaminyl (N-acetyl) transferase 1, core 2 14537 1459979_x_at Zfp68 zinc finger protein 68 24135 1459747_at --- --- --- 1459608_at --- --- --- 1459168_at --- --- --- 1458718_at --- --- --- 1458618_at --- --- --- 1458466_at Ctsa cathepsin A 19025 1458345_s_at Colec11 collectin sub-family member 11 71693 1458046_at --- --- --- 1457769_at H60a histocompatibility 60a 15101 1457680_a_at Tmem69 transmembrane protein 69 230657 1457644_s_at Cxcl1 chemokine (C-X-C motif) ligand 1 14825 1457639_at Atp6v1h ATPase, H+ transporting, lysosomal V1 subunit H 108664 1457260_at 5730409E04Rik RIKEN cDNA 5730409E04Rik gene 230757 1457070_at --- --- --- 1456893_at --- --- --- 1456823_at Gm70 predicted gene 70 210762 1456671_at Tbrg3 transforming growth factor beta regulated gene 3 21378 1456211_at Nlrp10 NLR family, pyrin domain containing 10 244202 1455881_at Ier5l immediate early response 5-like 72500 1455576_at Rinl Ras and Rab interactor-like 320435 1455304_at Unc13c unc-13 homolog C (C. elegans) 208898 1455241_at BC037703 cDNA sequence BC037703 242125 1454866_s_at Clic6 chloride intracellular channel 6 209195 1453906_at Med13l mediator complex subunit 13-like 76199 1453522_at 6530401N04Rik RIKEN cDNA 6530401N04 gene 328092 1453354_at Gm11602 predicted gene 11602 100380944 1453234_at -

LIM Domain Proteins Pinch1/2 Regulate Chondrogenesis and Bone Mass in Mice
Bone Research www.nature.com/boneres ARTICLE OPEN LIM domain proteins Pinch1/2 regulate chondrogenesis and bone mass in mice Yiming Lei1, Xuekun Fu1, Pengyu Li1, Sixiong Lin1,2, Qinnan Yan1, Yumei Lai3, Xin Liu1, Yishu Wang1, Xiaochun Bai 4, Chuanju Liu5,6, Di Chen7, Xuenong Zou2, Xu Cao8, Huiling Cao1 and Guozhi Xiao1 The LIM domain-containing proteins Pinch1/2 regulate integrin activation and cell–extracellular matrix interaction and adhesion. Here, we report that deleting Pinch1 in limb mesenchymal stem cells (MSCs) and Pinch2 globally (double knockout; dKO) in mice causes severe chondrodysplasia, while single mutant mice do not display marked defects. Pinch deletion decreases chondrocyte proliferation, accelerates cell differentiation and disrupts column formation. Pinch loss drastically reduces Smad2/3 protein expression in proliferative zone (PZ) chondrocytes and increases Runx2 and Col10a1 expression in both PZ and hypertrophic zone (HZ) chondrocytes. Pinch loss increases sclerostin and Rankl expression in HZ chondrocytes, reduces bone formation, and increases bone resorption, leading to low bone mass. In vitro studies revealed that Pinch1 and Smad2/3 colocalize in the nuclei of chondrocytes. Through its C-terminal region, Pinch1 interacts with Smad2/3 proteins. Pinch loss increases Smad2/3 ubiquitination and degradation in primary bone marrow stromal cells (BMSCs). Pinch loss reduces TGF-β-induced Smad2/3 phosphorylation and nuclear localization in primary BMSCs. Interestingly, compared to those from single mutant mice, BMSCs from dKO mice express dramatically lower protein levels of β-catenin and Yap1/Taz and display reduced osteogenic but increased adipogenic differentiation capacity. Finally, ablating Pinch1 in chondrocytes and Pinch2 globally causes severe osteopenia with subtle limb fi 1234567890();,: shortening. -

HERV-K(HML7) Integrations in the Human Genome: Comprehensive Characterization and Comparative Analysis in Non-Human Primates
biology Article HERV-K(HML7) Integrations in the Human Genome: Comprehensive Characterization and Comparative Analysis in Non-Human Primates Nicole Grandi 1,* , Maria Paola Pisano 1 , Eleonora Pessiu 1, Sante Scognamiglio 1 and Enzo Tramontano 1,2 1 Laboratory of Molecular Virology, Department of Life and Environmental Sciences, University of Cagliari, 09042 Monserrato, Cagliari, Italy; [email protected] (M.P.P.); [email protected] (E.P.); [email protected] (S.S.); [email protected] (E.T.) 2 Istituto di Ricerca Genetica e Biomedica, Consiglio Nazionale delle Ricerche (CNR), 09042 Monserrato, Cagliari, Italy * Correspondence: [email protected] Simple Summary: The human genome is not human at all, but it includes a multitude of sequences inherited from ancient viral infections that affected primates’ germ line. These elements can be seen as the fossils of now-extinct retroviruses, and are called Human Endogenous Retroviruses (HERVs). View as “junk DNA” for a long time, HERVs constitute 4 times the amount of DNA needed to produce all cellular proteins, and growing evidence indicates their crucial role in primate brain evolution, placenta development, and innate immunity shaping. HERVs are also intensively studied for a pathological role, even if the incomplete knowledge about their exact number and genomic position has thus far prevented any causal association. Among possible relevant HERVs, the HERV-K Citation: Grandi, N.; Pisano, M.P.; supergroup is of particular interest, including some of the oldest (HML5) as well as youngest (HML2) Pessiu, E.; Scognamiglio, S.; integrations. Among HERV-Ks, the HML7 group still lack a detailed description, and the present Tramontano, E. -

Theranostics Transcriptomic Analysis Identifies a Tumor Subtype Mrna
Theranostics 2021, Vol. 11, Issue 1 132 Ivyspring International Publisher Theranostics 2021; 11(1): 132-146. doi: 10.7150/thno.47525 Research Paper Transcriptomic analysis identifies a tumor subtype mRNA classifier for invasive non-functioning pituitary neuroendocrine tumor diagnostics Xinjie Bao1#, Gengchao Wang2,3#, Shan Yu2,3#, Jian Sun4, Liu He2,3, Hualu Zhao2,3, Yanni Ma2,3, Fang Wang2,3, Xiaoshuang Wang2,3, Renzhi Wang1 and Jia Yu2,3,5 1. Department of Neurosurgery, Pituitary Center, Peking Union Medical College Hospital (PUMCH), Chinese Academy of Medical Sciences (CAMS) & Peking Union Medical College (PUMC), Beijing 100730, PR China. 2. State Key Laboratory of Medical Molecular Biology, Institute of Basic Medical Sciences, Chinese Academy of Medical Sciences (CAMS) & School of Basic Medicine, Peking Union Medical College (PUMC), Beijing 100005, PR China. 3. Department of Biochemistry, Institute of Basic Medical Sciences, Chinese Academy of Medical Sciences (CAMS) & School of Basic Medicine, Peking Union Medical College (PUMC), Beijing 100005, PR China. 4. Department of Pathology, Peking Union Medical College Hospital (PUMCH), Chinese Academy of Medical Sciences (CAMS) & Peking Union Medical College (PUMC), Beijing 100730, PR China. 5. Medical Epigenetic Research Center, Chinese Academy of Medical Sciences (CAMS), Beijing 100005, PR China. #These authors contributed equally to this work. Corresponding authors: Jia Yu, State Key Laboratory of Medical Molecular Biology, Institute of Basic Medical Sciences, Chinese Academy of Medical -

4E-BP2 / EIF4EBP2 Antibody (Aa99-120) Rabbit Polyclonal Antibody Catalog # ALS12947
10320 Camino Santa Fe, Suite G San Diego, CA 92121 Tel: 858.875.1900 Fax: 858.622.0609 4E-BP2 / EIF4EBP2 Antibody (aa99-120) Rabbit Polyclonal Antibody Catalog # ALS12947 Specification 4E-BP2 / EIF4EBP2 Antibody (aa99-120) - Product Information Application IHC Primary Accession Q13542 Reactivity Human, Mouse, Rat, Pig, Bovine, Dog Host Rabbit Clonality Polyclonal Calculated MW 13kDa KDa 4E-BP2 / EIF4EBP2 Antibody (aa99-120) - Additional Information Anti-EIF4EBP2 / 4EBP2 antibody IHC of Gene ID 1979 human pancreas. Other Names Eukaryotic translation initiation factor 4E-BP2 / EIF4EBP2 Antibody (aa99-120) - 4E-binding protein 2, 4E-BP2, eIF4E-binding Background protein 2, EIF4EBP2 Regulates eIF4E activity by preventing its Target/Specificity assembly into the eIF4F complex. Mediates the Detects 17 and 20 kD proteins, regulation of protein translation by hormones, corresponding to the apparent molecular growth factors and other stimuli that signal mass of PHAS-II and its phosphorylated through the MAP kinase pathway. state on SDS-PAGE immunoblots. 4E-BP2 / EIF4EBP2 Antibody (aa99-120) - Reconstitution & Storage References Short term 4°C, long term aliquot and store at -20°C, avoid freeze thaw cycles. For Pause A.,et al.Nature 371:762-767(1994). maximum product recovery, after thawing, Kalnine N.,et al.Submitted (MAY-2003) to the centrifuge the product vial before removing cap. EMBL/GenBank/DDBJ databases. Dephoure N.,et al.Proc. Natl. Acad. Sci. U.S.A. Precautions 105:10762-10767(2008). 4E-BP2 / EIF4EBP2 Antibody (aa99-120) is Gauci S.,et al.Anal. Chem. for research use only and not for use in 81:4493-4501(2009). diagnostic or therapeutic procedures.