Racetrack Memory Based Logic Design for In‑Memory Computing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Universal Memory
BRIEFING No.4 ICT UNIVERSAL MEMORY Memory is an integral part of information processing devices and is needed for short‐term stor‐ age such as when computer programs are being executed or text documents are processed. Currently, three main types of memory exist: SRAM offers very high speed at a high cost, DRAM is average in terms of speed and cost, and Flash memory is a low cost, low speed solution for applications that need to retain the data even when power is disconnected. A group of emerg‐ ing memory devices called universal memory aim to combine all these features in a single de‐ vice.1 Developments in universal memory devices may eventually lead to the introduction of novel October 2010 October memory architectures that offer increased performance, enable smaller mobile devices, and offer novel features in traditional products such as cars or domestic appliances. Nanotechnol‐ ogy is an integral part of emerging memory research as it is becoming increasingly difficult to enhance the performance of current devices by scaling the technology further. It is unlikely that a single technology will emerge as the universal memory technology; however, the develop‐ ments in this sector will enhance the energy efficiency and performance of memory devices. Currently, the Integrated Circuit (IC) market is dominated by US and Asia based companies. Uni‐ versal memory and nanotechnology based solutions could provide an opportunity for Europe to gain ground in the sector. Background volatility. Its disadvantage compared to SRAM and DRAM is speed. None of the existing memory technologies provide all of the required properties. -

Nanotechnology Trends in Nonvolatile Memory Devices
IBM Research Nanotechnology Trends in Nonvolatile Memory Devices Gian-Luca Bona [email protected] IBM Research, Almaden Research Center © 2008 IBM Corporation IBM Research The Elusive Universal Memory © 2008 IBM Corporation IBM Research Incumbent Semiconductor Memories SRAM Cost NOR FLASH DRAM NAND FLASH Attributes for universal memories: –Highest performance –Lowest active and standby power –Unlimited Read/Write endurance –Non-Volatility –Compatible to existing technologies –Continuously scalable –Lowest cost per bit Performance © 2008 IBM Corporation IBM Research Incumbent Semiconductor Memories SRAM Cost NOR FLASH DRAM NAND FLASH m+1 SLm SLm-1 WLn-1 WLn WLn+1 A new class of universal storage device : – a fast solid-state, nonvolatile RAM – enables compact, robust storage systems with solid state reliability and significantly improved cost- performance Performance © 2008 IBM Corporation IBM Research Non-volatile, universal semiconductor memory SL m+1 SL m SL m-1 WL n-1 WL n WL n+1 Everyone is looking for a dense (cheap) crosspoint memory. It is relatively easy to identify materials that show bistable hysteretic behavior (easily distinguishable, stable on/off states). IBM © 2006 IBM Corporation IBM Research The Memory Landscape © 2008 IBM Corporation IBM Research IBM Research Histogram of Memory Papers Papers presented at Symposium on VLSI Technology and IEDM; Ref.: G. Burr et al., IBM Journal of R&D, Vol.52, No.4/5, July 2008 © 2008 IBM Corporation IBM Research IBM Research Emerging Memory Technologies Memory technology remains an -
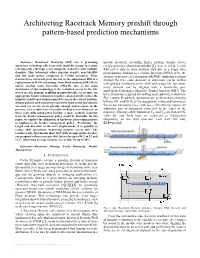
Architecting Racetrack Memory Preshift Through Pattern-Based Prediction Mechanisms
Architecting Racetrack Memory preshift through pattern-based prediction mechanisms Abstract— Racetrack Memories (RM) are a promising metalic racetrack, providing higher package density, lower spintronic technology able to provide multi-bit storage in a single energy and more robust data stability [5]. As seen in Fig. 1, each cell (tape-like) through a ferromagnetic nanowire with multiple RM cell is able to store multiple data bits in a single wire domains. This technology offers superior density, non-volatility programming domains to a certain direction (DWM) or by the and low static power compared to CMOS memories. These absence or presence of a skyrmion (SK-RM). Applying a current features have attracted great interest in the adoption of RM as a through the wire ends, domains or skyrmions can be shifted replacement of RAM technology, from Main memory (DRAM) to left/right at a constant velocity. With such a tape-like operation, maybe on-chip cache hierarchy (SRAM). One of the main every domain can be aligned with a read/write port, drawbacks of this technology is the serialized access to the bits implemented through a Magnetic Tunnel Junction (MTJ). The stored in each domain, resulting in unpredictable access time. An bit-cell structure required for shifting and read/write is shown in appropriate header management policy can potentially reduce the number of shift operations required to access the correct position. Fig. 1.down. Read/write operations are performed precharging Simple policies such as leaving read/write head on the last domain bitlines (BL and BLB) to the appropriate values and turning on accessed (or on the next) provide enough improvement in the the access transistors (TRW1 and TRW2). -

Data in the Fast Lanes of Racetrack Memory
INFOTECH Data in the Fast Lanes of RACETRACK MEMORY A device that slides magnetic bits back and forth along nanowire “racetracks” could pack data in a three-dimensional microchip and may replace nearly all forms of conventional data storage By Stuart S. P. Parkin he world today is very different from that when the computer powers down—or crashes. of just a decade ago, thanks to our ability A few computers use nonvolatile chips, which T to readily access enormous quantities of retain data when the power is off, as a solid-state information. Tools that we take for granted— drive in place of an HDD. The now ubiquitous social networks, Internet search engines, online smart cell phones and other handheld devices maps with point-to-point directions, and online also use nonvolatile memory, but there is a trade- libraries of songs, movies, books and photo- off between cost and performance. The cheapest KEY CONCEPTS graphs—were unavailable just a few years ago. nonvolatile memory is a kind called flash memo- ■ A radical new design for We owe the arrival of this information age to the ry, which, among other uses, is the basis of the computer data storage rapid development of remarkable technologies little flash drives that some people have hanging called racetrack memory in high-speed communications, data processing from their key rings. Flash memory, however, is (RM) moves magnetic and—perhaps most important of all but least ap- slow and unreliable in comparison with other bits along nanoscopic preciated—digital data storage. memory chips. Each time the high-voltage pulse “racetracks.” Each type of data storage has its Achilles’ heel, (the “flash” of the name) writes a memory cell, ■ RM would be nonvola- however, which is why computers use several the cell is damaged; it becomes unusable after tile—retaining its data types for different purposes. -

A Survey of Architectural Approaches for Managing Embedded DRAM and Non-Volatile On-Chip Caches Sparsh Mittal, Jeffrey S
A Survey Of Architectural Approaches for Managing Embedded DRAM and Non-volatile On-chip Caches Sparsh Mittal, Jeffrey S. Vetter, Dong Li To cite this version: Sparsh Mittal, Jeffrey S. Vetter, Dong Li. A Survey Of Architectural Approaches for Managing Embedded DRAM and Non-volatile On-chip Caches. IEEE Transactions on Parallel and Distributed Systems, Institute of Electrical and Electronics Engineers, 2015, pp.14. 10.1109/TPDS.2014.2324563. hal-01102387 HAL Id: hal-01102387 https://hal.archives-ouvertes.fr/hal-01102387 Submitted on 12 Jan 2015 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. This is the author's version of an article that has been published in this journal. Changes were made to this version by the publisher prior to publication. The final version of record is available at http://dx.doi.org/10.1109/TPDS.2014.2324563 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTING SYSTEMS 1 A Survey Of Architectural Approaches for Managing Embedded DRAM and Non-volatile On-chip Caches Sparsh Mittal, Member, IEEE, Jeffrey S. Vetter, Senior Member, IEEE, and Dong Li Abstract—Recent trends of CMOS scaling and increasing number of on-chip cores have led to a large increase in the size of on- chip caches. -

System Level Management of Hybrid Memory Systems
UNIVERSIDAD COMPLUTENSE DE MADRID FACULTAD DE INFORMÁTICA DEPARTAMENTO DE ARQUITECTURA DE COMPUTADORES Y AUTOMÁTICA TESIS DOCTORAL System Level Management of Hybrid Memory Systems Gestión de jerarquías de memoria híbridas a nivel de sistema MEMORIA PARA OPTAR AL GRADO DE DOCTOR PRESENTADA POR Manu Perumkunnil Komalan DIRECTORES José Ignacio Gómez Pérez Christian Tomás Tenllado Francky Catthoor Madrid, 2018 © Manu Perumkunnil Komalan, 2017 ARENBERG DOCTORAL SCHOOL Faculty of Engineering Science Universidad Complutense de Madrid Facultad de Informática Departamento de Arquitectura de Computadores y Automática System Level Management of Hybrid Memory Systems Gestión de jerarquías de memoria híbridas a nivel de sistema Manu Perumkunnil Komalan Supervisors Prof. dr. ir. José Ignacio Gómez Pérez (UCM) Prof. dr. ir. Christian Tomás Tenllado (UCM) Prof. dr. ir. Francky Catthoor (KU Leuven) March 2017 System Level Management of Hybrid Memory Sys tems Gestión de jerarquías de memoria híbridas a nivel de sistema Manu Perumkunnil KOMALAN Examination committee: Prof. dr. ir. José Ignacio Gómez Pérez Prof. dr. ir. Christian Tomás Tenllado Prof. dr. ir. Francky Catthoor Prof. dr. ir. Wim Dehaene Prof. dr. ir. Dirk Wouters Prof. dr. ir. Manuel Prieto Matías Prof. dr. ir. Luis Piñuel Prof. dr. ir. José Manuel Colmenar March 2017 2017, UC Madrid, KU Leuven, – Manu Perumkunnil Komalan Acknowledgments There is an impossibly long list of people I want to thank for helping me in the pursuit of my PhD and making it worth much more than simple technical jargon. Like I’ve been counseled many a times and experienced, my PhD like every other PhD has followed the trajectory of a sine wave. -

A Study About Non-Volatile Memories
Preprints (www.preprints.org) | NOT PEER-REVIEWED | Posted: 29 July 2016 doi:10.20944/preprints201607.0093.v1 1 Article 2 A Study about Non‐Volatile Memories 3 Dileep Kumar* 4 Department of Information Media, The University of Suwon, Hwaseong‐Si South Korea ; [email protected] 5 * Correspondence: [email protected] ; Tel.: +82‐31‐229‐8212 6 7 8 Abstract: This paper presents an upcoming nonvolatile memories (NVM) overview. Non‐volatile 9 memory devices are electrically programmable and erasable to store charge in a location within the 10 device and to retain that charge when voltage supply from the device is disconnected. The 11 non‐volatile memory is typically a semiconductor memory comprising thousands of individual 12 transistors configured on a substrate to form a matrix of rows and columns of memory cells. 13 Non‐volatile memories are used in digital computing devices for the storage of data. In this paper 14 we have given introduction including a brief survey on upcoming NVMʹs such as FeRAM, MRAM, 15 CBRAM, PRAM, SONOS, RRAM, Racetrack memory and NRAM. In future Non‐volatile memory 16 may eliminate the need for comparatively slow forms of secondary storage systems, which include 17 hard disks. 18 Keywords: Non‐volatile Memories; NAND Flash Memories; Storage Memories 19 PACS: J0101 20 21 22 1. Introduction 23 Memory is divided into two main parts: volatile and nonvolatile. Volatile memory loses any 24 data when the system is turned off; it requires constant power to remain viable. Most kinds of 25 random access memory (RAM) fall into this category. -
Perspectives of Racetrack Memory Based on Current-Induced Domain Wall Motion: from Device to System
See discussions, stats, and author profiles for this publication at: http://www.researchgate.net/publication/277712760 Perspectives of Racetrack Memory Based on Current-Induced Domain Wall Motion: From Device to System CONFERENCE PAPER · MAY 2015 DOWNLOADS VIEWS 92 16 6 AUTHORS, INCLUDING: Yue Zhang Jacques-Olivier Klein Beihang University(BUAA) Université Paris-Sud 11 53 PUBLICATIONS 173 CITATIONS 140 PUBLICATIONS 555 CITATIONS SEE PROFILE SEE PROFILE Weisheng ZHAO CNRS, Univ. Paris Sud, Beihang University, 155 PUBLICATIONS 908 CITATIONS SEE PROFILE Available from: Weisheng ZHAO Retrieved on: 08 July 2015 Perspectives of Racetrack Memory Based on Current- Induced Domain Wall Motion: From Device to System Yue Zhang1, Chao Zhang3, Jacques-Olivier Klein1, Dafine Ravelosona1, Guangyu Sun3, Weisheng Zhao1,2 Email: [email protected] [email protected] 1Institut d’Electronique Fondamentale, Univ. Paris-Sud/UMR 8622 CNRS, Orsay, France 2Spintronics Interdisciplinary Center, Beihang University, Beijing, China 3Center for Energy-Efficient Computing and Applications, Peking University, Beijing, China Abstract—Current-induced domain wall motion (CIDWM) is Firstly, in order to overcome the issue of thermal stability, regarded as a promising way towards achieving emerging high- materials with perpendicular magnetic anisotropy (PMA) have density, high-speed and low-power non-volatile devices. being intensively studied and can offer various other Racetrack memory is an attractive concept based on this performance improvements compared with those with in-plane phenomenon, which can store and transfer a series of data along magnetic anisotropy, such as lower DW nucleation critical a magnetic nanowire. Although the first prototype has been successfully fabricated, its advancement is relatively arduous current and higher DW shifting speed [7-8]. -

Emerging Non-Volatile Storage Memories
IBM Research Emerging Non-volatile Storage Memories Gian-Luca Bona [email protected] IBM Research, Almaden Research Center © 2005 IBM Corporation IBM Research Outline Non-volatile Memory Landscape Emerging Non-volatile Storage Memory Examples - Phase Change Memory - Polymer-based Charge Storage Memory - Storage Probe Memory - Magnetic Shift Register Memory Summary & Conclusion: Expected Advances in Solid State Storage Technology IBM © 2005 IBM Corporation IBM Research Non-volatile Storage Memories SL m+1 SL m SL m-1 WL n-1 WL n WL n+1 Everyone is looking for a dense (cheap) crosspoint memory. It is relatively easy to identify materials that show bistable hysteretic behavior (easily distinguishable, stable on/off states). IBM © 2005 IBM Corporation IBM Research The Nonvolatile Memory Landscape © 2005 IBM Corporation IBM Research The Nonvolatile Memory Landscape More new non-volatile memory technologies under development today than at any time in history 2 reasons Year 03 04 05 06 07 08 09 Flash 107 90 80 70 65 57 50 Technology node (nm) Flash NOR 9-10 8.5- 8.5- 8-9 8-9 8-9 8-9 tunnel oxide 9.5 9.5 thickness (nm) Manufacturing solution exist ITRS 2004 Manufacturing solution is known Manufacturing solution is NOT known Scaling: Oxide thickness will Explosive market growth reach limit very soon Diversified applications © 2005 IBM Corporation IBM Research Non-volatile Storage Memory Storage Class Memory (SCM): Key Features: • Much faster to write small blocks than Flash, HDD • Less expensive than Flash • More rugged than HDD • Lower -

Racetrack Memory 15 November 2010
Racetrack memory 15 November 2010 in the wire are simply pushed around inside the tape using a spin polarized current, attaining the breakneck speed of several hundred meters per second in the process. It's like reading an entire VHS cassette in less than a second. In order for the idea to be feasible, each bit of information must be clearly separated from the next so that the data can be read reliably. This is achieved by using domain walls with magnetic vortices to delineate two adjacent bits. To estimate the maximum velocity at which the bits can be moved, Kläui and his colleagues* carried out measurements on vortices and found that the The bits of information stored in the wire are simply physical mechanism could allow for possible higher pushed around inside the tape using a spin polarized current, attaining the breakneck speed of several access speeds than expected. Their results were hundred meters per second in the process. Credit: IBM published online October 25, 2010, in the journal Almaden Research Center Physical Review Letters. Scientists at the Zurich Research Center of IBM (which is developing a racetrack memory) have confirmed the importance of the results in a Viewpoint article. Millions or even Imagine a computer equipped with shock-proof billions of nanowires would be embedded in a chip, memory that's 100,000 times faster and consumes providing enormous capacity on a shock-proof less power than current hard disks. EPFL platform. A market-ready device could be available Professor Mathias Klaui is working on a new kind in as little as 5-7 years. -

Storage Class Memory Towards a Disruptively Low-Cost Solid-State Non-Volatile Memory
Storage Class Memory Towards a disruptively low-cost solid-state non-volatile memory Science & Technology Almaden Research Center January 2013 Storage Class Memory Power & space in the server room The cache/memory/storage hierarchy is rapidly becoming the bottleneck for large systems. We know how to create MIPS & MFLOPS cheaply and in abundance, but feeding them with data has become the performance-limiting and most-expensive part of a system (in both $ and Watts). Extrapolation to 2020 (at 70% CGR need 2 GIOP/sec) • 5 million HDD . 16,500 sq. ft. !! . 22 Megawatts R. Freitas and W. Wilcke, Storage Class Memory: the next storage system technology –"Storage Technologies & Systems" special issue of the IBM Journal of R&D (2008) 2 Science & Technology – IBM Almaden Research Center Jan 2013 Storage Class Memory …yet critical applications are also undergoing a paradigm shift Compute-centric Data-centric paradigm paradigm Main Focus: Solve differential equations Analyze petabytes of data Bottleneck: CPU / Memory Storage & I/O Typical Examples: Computational Fluid Dynamics Search and Mining Finite Element Analysis Analyses of social/terrorist networks Multi-body Simulations Sensor network processing Digital media creation/transmission Environmental & economic modeling Extrapolation (at 90% CGR need 1.7 PB/sec) (at 90% CGR need 8.4G SIO/sec) to 2020 • 5.6 million HDD • 21 million HDD . 19,000 sq. ft. !! . 70,000 sq. ft. !! [Freitas:2008] . 25 Megawatts . 93 Megawatts 3 Science & Technology – IBM Almaden Research Center Jan 2013 Storage Class -

Low-Power Volatile and Non-Volatile Memory Design
Low-power Volatile and Non-volatile Memory Design by Qing Dong A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy (Electrical Engineering) in the University of Michigan 2017 Doctoral Committee: Professor Dennis Michael Sylvester, Chair Professor David Blaauw Professor Branko Kerkez Professor Zhengya Zhang Qing Dong [email protected] ORCID ID: 0000-0002-1380-269X © Qing Dong 2017 i DEDICATION To my family & friends… This dissertation is dedicated to my family and friends that supported, encouraged, and inspired me throughout my education. ii Table of Contents DEDICATION............................................................................................................................... ii LIST OF FIGURES ..................................................................................................................... vi LIST OF TABLES ..................................................................................................................... xiii ABSTRACT ................................................................................................................................ xiv CHAPTER 1. Introduction ......................................................................................................... 1 1.1 Low-power SRAMs and In-memory-computing ............................................... 4 1.2 NOR Flash Memory .............................................................................................. 6 1.3 STT-MRAM Memory ..........................................................................................