The Correction of the Grammatical Case Endings Errors in Arabic Language
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Representation of Inflected Nouns in the Internal Lexicon
Memory & Cognition 1980, Vol. 8 (5), 415423 Represeritation of inflected nouns in the internal lexicon G. LUKATELA, B. GLIGORIJEVIC, and A. KOSTIC University ofBelgrade, Belgrade, Yugoslavia and M.T.TURVEY University ofConnecticut, Storrs, Connecticut 06268 and Haskins Laboratories, New Haven, Connecticut 06510 The lexical representation of Serbo-Croatian nouns was investigated in a lexical decision task. Because Serbo-Croatian nouns are declined, a noun may appear in one of several gram matical cases distinguished by the inflectional morpheme affixed to the base form. The gram matical cases occur with different frequencies, although some are visually and phonetically identical. When the frequencies of identical forms are compounded, the ordering of frequencies is not the same for masculine and feminine genders. These two genders are distinguished further by the fact that the base form for masculine nouns is an actual grammatical case, the nominative singular, whereas the base form for feminine nouns is an abstraction in that it cannot stand alone as an independent word. Exploiting these characteristics of the Serbo Croatian language, we contrasted three views of how a noun is represented: (1) the independent entries hypothesis, which assumes an independent representation for each grammatical case, reflecting its frequency of occurrence; (2) the derivational hypothesis, which assumes that only the base morpheme is stored, with the individual cases derived from separately stored inflec tional morphemes and rules for combination; and (3) the satellite-entries hypothesis, which assumes that all cases are individually represented, with the nominative singular functioning as the nucleus and the embodiment of the noun's frequency and around which the other cases cluster uniformly. -

Does English Have a Genitive Case? [email protected]
2. Amy Rose Deal – University of Massachusetts, Amherst Does English have a genitive case? [email protected] In written English, possessive pronouns appear without ’s in the same environments where non-pronominal DPs require ’s. (1) a. your/*you’s/*your’s book b. Moore’s/*Moore book What explains this complementarity? Various analyses suggest themselves. A. Possessive pronouns are contractions of a pronoun and ’s. (Hudson 2003: 603) B. Possessive pronouns are inflected genitives (Huddleston and Pullum 2002); a morphological deletion rule removes clitic ’s after a genitive pronoun. Analysis A consists of a single rule of a familiar type: Morphological Merger (Halle and Marantz 1993), familiar from forms like wanna and won’t. (His and its contract especially nicely.) No special lexical/vocabulary items need be postulated. Analysis B, on the other hand, requires a set of vocabulary items to spell out genitive case, as well as a rule to delete the ’s clitic following such forms, assuming ’s is a DP-level head distinct from the inflecting noun. These two accounts make divergent predictions for dialects with complex pronominals such as you all or you guys (and us/them all, depending on the speaker). Since Merger operates under adjacency, Analysis A predicts that intervention by all or guys should bleed the formation of your: only you all’s and you guys’ are predicted. There do seem to be dialects with this property, as witnessed by the American Heritage Dictionary (4th edition, entry for you-all). Call these English 1. Here, we may claim that pronouns inflect for only two cases, and Merger operations account for the rest. -

The Term Declension, the Three Basic Qualities of Latin Nouns, That
Chapter 2: First Declension Chapter 2 covers the following: the term declension, the three basic qualities of Latin nouns, that is, case, number and gender, basic sentence structure, subject, verb, direct object and so on, the six cases of Latin nouns and the uses of those cases, the formation of the different cases in Latin, and the way adjectives agree with nouns. At the end of this lesson we’ll review the vocabulary you should memorize in this chapter. Declension. As with conjugation, the term declension has two meanings in Latin. It means, first, the process of joining a case ending onto a noun base. Second, it is a term used to refer to one of the five categories of nouns distinguished by the sound ending the noun base: /a/, /ŏ/ or /ŭ/, a consonant or /ĭ/, /ū/, /ē/. First, let’s look at the three basic characteristics of every Latin noun: case, number and gender. All Latin nouns and adjectives have these three grammatical qualities. First, case: how the noun functions in a sentence, that is, is it the subject, the direct object, the object of a preposition or any of many other uses? Second, number: singular or plural. And third, gender: masculine, feminine or neuter. Every noun in Latin will have one case, one number and one gender, and only one of each of these qualities. In other words, a noun in a sentence cannot be both singular and plural, or masculine and feminine. Whenever asked ─ and I will ask ─ you should be able to give the correct answer for all three qualities. -

Introduction to Gothic
Introduction to Gothic By David Salo Organized to PDF by CommanderK Table of Contents 3..........................................................................................................INTRODUCTION 4...........................................................................................................I. Masculine 4...........................................................................................................II. Feminine 4..............................................................................................................III. Neuter 7........................................................................................................GOTHIC SOUNDS: 7............................................................................................................Consonants 8..................................................................................................................Vowels 9....................................................................................................................LESSON 1 9.................................................................................................Verbs: Strong verbs 9..........................................................................................................Present Stem 12.................................................................................................................Nouns 14...................................................................................................................LESSON 2 14...........................................................................................Strong -

Systemic Polyfunctionality and Morphology-Syntax Interdependencies
Systemic polyfunctionality and morphology-syntax interdependencies Farrell Ackerman1 Olivier Bonami2 Irina Nikolaeva3 1University of California, San Diego 2Université Paris-Sorbonne 3SOAS Defaults in Morphological Theory Lexington, May 2012 The basic problem: Systemic Polyfunctionality Cross-linguistically person/number markers (PNMs) in verbal paradigms often exhibit similarities (up to identity) with person/number markers in nominal possessive constructions (Allen 1964, Radics 1980, Siewierska 1998, 2004, among others): When a language has distinct PNM paradigms for verbal subject (S/A) and object (O) indexing, a question arises: Which paradigm does the possessive paradigm align with? (1) Retuarã (Tucanoan) S/A alignment b˜ıre yi-ha¯a-a¯ Psi yi-behoa-pi 2SG 1SG-kill-NEG.IMP 1SG-spear-INSTR ‘(Be careful), lest I kill you with my spear’ (Strom 1992:63) (2) Kilivila (Central-Eastern Malayo-Polynesian) O alignment lube-gu ku-sake-gu buva friend-1SG 2SG-give-1SG betel_nut ‘My friend, do you give me betel nuts?’ (Senft 1986:53) The basic problem: Systemic Polyfunctionality Among the 130 relevant languages in Sierwieska’s (1998) sample she observes that, We see that [...], among the languages in the sample the affinities in form between the possessor affixes and the verbal person markers of the O (41%) are just marginally more common than those with the S/A (39%). (Siewierska 1998:2) There are, by hypothesis, systemic properties of specific grammars, rather than language independent universals, that explain the alignments observed. The languages compared by Siewierska appear to have distinct markers for S/A and O, and the question asked is which paradigm appears in possessive marking. -

Serial Verb Constructions Revisited: a Case Study from Koro
Serial Verb Constructions Revisited: A Case Study from Koro By Jessica Cleary-Kemp A dissertation submitted in partial satisfaction of the requirements for the degree of Doctor of Philosophy in Linguistics in the Graduate Division of the University of California, Berkeley Committee in charge: Associate Professor Lev D. Michael, Chair Assistant Professor Peter S. Jenks Professor William F. Hanks Summer 2015 © Copyright by Jessica Cleary-Kemp All Rights Reserved Abstract Serial Verb Constructions Revisited: A Case Study from Koro by Jessica Cleary-Kemp Doctor of Philosophy in Linguistics University of California, Berkeley Associate Professor Lev D. Michael, Chair In this dissertation a methodology for identifying and analyzing serial verb constructions (SVCs) is developed, and its application is exemplified through an analysis of SVCs in Koro, an Oceanic language of Papua New Guinea. SVCs involve two main verbs that form a single predicate and share at least one of their arguments. In addition, they have shared values for tense, aspect, and mood, and they denote a single event. The unique syntactic and semantic properties of SVCs present a number of theoretical challenges, and thus they have invited great interest from syntacticians and typologists alike. But characterizing the nature of SVCs and making generalizations about the typology of serializing languages has proven difficult. There is still debate about both the surface properties of SVCs and their underlying syntactic structure. The current work addresses some of these issues by approaching serialization from two angles: the typological and the language-specific. On the typological front, it refines the definition of ‘SVC’ and develops a principled set of cross-linguistically applicable diagnostics. -

Why Grammar Matters: Conjugating Verbs in Modern Legal Opinions Robert C
Loyola University Chicago Law Journal Volume 40 Article 3 Issue 1 Fall 2008 2008 Why Grammar Matters: Conjugating Verbs in Modern Legal Opinions Robert C. Farrell Quinnipiac University School of Law Follow this and additional works at: http://lawecommons.luc.edu/luclj Part of the Law Commons Recommended Citation Robert C. Farrell, Why Grammar Matters: Conjugating Verbs in Modern Legal Opinions, 40 Loy. U. Chi. L. J. 1 (2008). Available at: http://lawecommons.luc.edu/luclj/vol40/iss1/3 This Article is brought to you for free and open access by LAW eCommons. It has been accepted for inclusion in Loyola University Chicago Law Journal by an authorized administrator of LAW eCommons. For more information, please contact [email protected]. Why Grammar Matters: Conjugating Verbs in Modern Legal Opinions Robert C. Farrell* I. INTRODUCTION Does it matter that the editors of thirty-three law journals, including those at Yale and Michigan, think that there is a "passive tense"? l Does it matter that the United States Courts of Appeals for the Sixth2 and Eleventh3 Circuits think that there is a "passive mood"? Does it matter that the editors of fourteen law reviews think that there is a "subjunctive tense"?4 Does it matter that the United States Court of Appeals for the District of Columbia Circuit thinks that there is a "subjunctive voice'"? 5 There is, in fact, no "passive tense" or "passive mood." The passive is a voice. 6 There is no "subjunctive voice" or "subjunctive tense." The subjunctive is a mood.7 The examples in the first paragraph suggest that there is widespread unfamiliarity among lawyers and law students * B.A., Trinity College; J.D., Harvard University; Professor, Quinnipiac University School of Law. -

Objective and Subjective Genitives
Objective and Subjective Genitives To this point, there have been three uses of the Genitive Case. They are possession, partitive, and description. Many genitives which have been termed possessive, however, actually are not. When a Genitive Case noun is paired with certain special nouns, the Genitive has a special relationship with the other noun, based on the relationship of a noun to a verb. Many English and Latin nouns are derived from verbs. For example, the word “love” can be used either as a verb or a noun. Its context tells us how it is being used. The patriot loves his country. The noun country is the Direct Object of the verb loves. The patriot has a great love of his country. The noun country is still the object of loving, but now loving is expressed as a noun. Thus, the genitive phrase of his country is called an Objective Genitive. You have actually seen a number of Objective Genitives. Another common example is Rex causam itineris docuit. The king explained the cause of the journey (the thing that caused the journey). Because “cause” can be either a noun or a verb, when it is used as a noun its Direct Object must be expressed in the Genitive Case. A number of Latin adjectives also govern Objective Genitives. For example, Vir miser cupidus pecuniae est. A miser is desirous of money. Some special nouns and adjectives in Latin take Objective Genitives which are more difficult to see and to translate. The adjective peritus, -a, - um, meaning “skilled” or “experienced,” is one of these: Nautae sunt periti navium. -
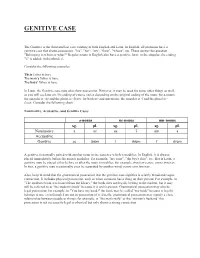
Genitive Case
GENITIVE CASE The Genitive is the third and last case existing in both English and Latin. In English, all pronouns have a genitive case that shows possession: "his", "her", "my", "their", "whose", etc. These answer the question "Belonging to whom or what?" Regular nouns in English also have a genitive form: in the singular, the ending "'s" is added; in the plural, s'. Consider the following examples: Their father is here. The man's father is here. The boys' father is here. In Latin, the Genitive case may also show possession. However, it may be used for some other things as well, as you will see later on. It's ending of course varies depending on the original ending of the noun: for a-nouns, the singular is -ae and the plural is -ārum; for both us- and um-nouns, the singular is -ī and the plural is - ōrum. Consider the following chart: Nominative, Accusative, and Genitive Cases a-nouns us-nouns um-nouns sg. pl. sg. pl. sg. pl. Nominative a ae us ī um a Accusative Genitive ae ārum ī ōrum ī ōrum A genitive is normally paired with another noun in the sentence which it modifies. In English, it is always placed immediately before the noun it modifies: for example, "my soup", "the boy's shirt", etc. But in Latin, a genitive may be placed either before or after the noun it modifies: for example, feminae panes, panes feminae. In fact, a genitive may occasionally even be separated by another word: panes sunt feminae. Also, keep in mind that the grammatical possession that the genitive case signifies is a fairly broad and vague connection. -

Spanish Verbs and Essential Grammar Review
Spanish Verbs and Essential Grammar Review Prepared by: Professor Carmen L. Torres-Robles Department of Foreign Languages & Literatures Purdue University Calumet Revised: 1 /2003 Layout by: Nancy J. Tilka CONTENTS Spanish Verbs Introduction 4 Indicative Mood 5 ® simple & compound tenses: present, past, future, conditional Subjunctive Mood 12 ® simple & compound tenses: present, past Ser / Estar 16 Essential Grammar Pronouns 20 Possesive Adjectives and Pronouns 23 Prepositional Pronouns 25 Por versus Para 27 Comparisons / Superlatives 31 Preterite / Imperfect 34 Subjunctive Mood 37 Commands 42 Passive Voice 46 2 Spanish Verbs 3 INTRODUCTION VERBS (VERBOS) MOODS (MODOS) There are three moods or ways to express verbs (actions) in Spanish. 1. Indicative Mood (objective) 2. Subjunctive Mood (subjective) 3. Imperative Mood (commands) INFINITIVES (INFINITIVOS) A verb in the purest form (without a noun or subject pronoun to perform the action) is called an infinitive. The infinitives in English are characterized by the prefix “to” + “verb form”, the Spanish infinitives are identified by the “r” ending. Example estudiar, comer, dormir to study, to eat, to sleep CONJUGATIONS (CONJUGACIONES) Spanish verbs are grouped in three categories or conjugations. 1. Infinitives ending in –ar belong to the first conjugation. (estudiar) 2. Infinitives ending in –er belong to the second conjugation. (comer) 3. Infinitives ending in –ir belong to the third conjugation. (dormir) VERB STRUCTURE (ESTRUCTURA VERBAL) Spanish verbs are divided into three parts. (infinitive: estudiar) 1. Stem or Root (estudi-) 2. Theme Vowel (-a-) 3. "R" Ending (-r) CONJUGATED VERBS (VERBOS CONJUGADOS) To conjugate a verb, a verb must have an explicit subject noun (ex: María), a subject pronoun (yo, tú, usted, él, ella, nosotros(as), vosotros(as), ustedes, ellos, ellas), or an implicit subject, to indicate the performer of the action. -

30. Tense Aspect Mood 615
30. Tense Aspect Mood 615 Richards, Ivor Armstrong 1936 The Philosophy of Rhetoric. Oxford: Oxford University Press. Rockwell, Patricia 2007 Vocal features of conversational sarcasm: A comparison of methods. Journal of Psycho- linguistic Research 36: 361−369. Rosenblum, Doron 5. March 2004 Smart he is not. http://www.haaretz.com/print-edition/opinion/smart-he-is-not- 1.115908. Searle, John 1979 Expression and Meaning. Cambridge: Cambridge University Press. Seddiq, Mirriam N. A. Why I don’t want to talk to you. http://notguiltynoway.com/2004/09/why-i-dont-want- to-talk-to-you.html. Singh, Onkar 17. December 2002 Parliament attack convicts fight in court. http://www.rediff.com/news/ 2002/dec/17parl2.htm [Accessed 24 July 2013]. Sperber, Dan and Deirdre Wilson 1986/1995 Relevance: Communication and Cognition. Oxford: Blackwell. Voegele, Jason N. A. http://www.jvoegele.com/literarysf/cyberpunk.html Voyer, Daniel and Cheryl Techentin 2010 Subjective acoustic features of sarcasm: Lower, slower, and more. Metaphor and Symbol 25: 1−16. Ward, Gregory 1983 A pragmatic analysis of epitomization. Papers in Linguistics 17: 145−161. Ward, Gregory and Betty J. Birner 2006 Information structure. In: B. Aarts and A. McMahon (eds.), Handbook of English Lin- guistics, 291−317. Oxford: Basil Blackwell. Rachel Giora, Tel Aviv, (Israel) 30. Tense Aspect Mood 1. Introduction 2. Metaphor: EVENTS ARE (PHYSICAL) OBJECTS 3. Polysemy, construal, profiling, and coercion 4. Interactions of tense, aspect, and mood 5. Conclusion 6. References 1. Introduction In the framework of cognitive linguistics we approach the grammatical categories of tense, aspect, and mood from the perspective of general cognitive strategies. -

The Differences Between Spoken and Written Grammar in English, in Comparison with Vietnamese1
GIST EDUCATION AND LEARNING RESEARCH JOURNAL. ISSN 1692-5777. NO. 11, (JULY - DECEMBER) 2015. pp. 138-153. The Differences between Spoken and Written Grammar in English, in Comparison 1 with Vietnamese Las Diferencias entre la Gramática Oral y Escrita del Idioma Inglés en Comparación con el Idioma Vietnamita Nguyen Cao Thanh2* Tan Trao University, Vietnam Abstract The fundamental point of this paper is to describe and evaluate some differences between spoken and written grammar in English, and compare some of the points with Vietnamese. This paper illustrates that spoken grammar is less rigid than written grammar. Moreover, it highlights the distinction between speaking and writing in terms of subordination and coordination. Further, the different frequency of adverbials and adjectivals between spoken and written language is also compared and analyzed. Keywords: spoken and written grammar, English, Vietnamese 138 1 Received: July 15, 2015 / Accepted: September 10, 2015 2 [email protected] No. 11 (July - December 2015) No. 11 (July - December 2015) CAO Resumen El principal objetivo de este artículo es describir y evaluar algunas diferencias entre la gramática oral y escrita del idioma inglés y comparar algunos aspectos gramaticales con el idioma vietnamita. Esta revisión muestra como la gramática oral es menos rígida que la gramática escrita. Por otra parte, se destaca la distinción entre el hablar y el escribir en términos de subordinación y coordinación. Además, la diferencia en el uso de adverbios y adjetivos entre la gramática oral y escrita también es comparada y analizada. Palabras clave: gramática oral y escrita, inglés, vietnamita Resumo O principal objetivo deste artigo é descrever e avaliar algumas diferenças entre a gramática oral e escrita do idioma inglês e comparar alguns aspectos gramaticais com o idioma vietnamita.