Internet 2004 Manuale Per L'uso Della Rete
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

1 Table of Contents List of Figures
Table of Contents List of Figures ..................................................................................................................... 4 List of Tables ...................................................................................................................... 5 Chapter 1: Introduction....................................................................................................... 6 1.1 Introduction....................................................................................................................6 1.2 Problem Statement .......................................................................................................12 1.3 Thesis Objective...........................................................................................................12 1.4 Thesis Organization.....................................................................................................14 Chapter 2: Intrusion Detection.......................................................................................... 15 2.1 Introduction..................................................................................................................15 2.2 What is an IDS .............................................................................................................15 2.2.1 The Basic Concepts of Intrusion Detection......................................................16 2.2.2 A Generic Intrusion-Detection System.............................................................17 2.2.3 Characteristics of -

Using Remote Desktop Services with Ifix 1
Proficy iFIX 6.5 Using Remote Desktop Services GE Digital Proficy Historian and Operations Hub: Data Analysis in Context 1 Proprietary Notice The information contained in this publication is believed to be accurate and reliable. However, General Electric Company assumes no responsibilities for any errors, omissions or inaccuracies. Information contained in the publication is subject to change without notice. No part of this publication may be reproduced in any form, or stored in a database or retrieval system, or transmitted or distributed in any form by any means, electronic, mechanical photocopying, recording or otherwise, without the prior written permission of General Electric Company. Information contained herein is subject to change without notice. © 2021, General Electric Company. All rights reserved. Trademark Notices GE, the GE Monogram, and Predix are either registered trademarks or trademarks of General Electric Company. Microsoft® is a registered trademark of Microsoft Corporation, in the United States and/or other countries. All other trademarks are the property of their respective owners. We want to hear from you. If you have any comments, questions, or suggestions about our documentation, send them to the following email address: [email protected] Table of Contents Using Remote Desktop Services with iFIX 1 Reference Documents 1 Introduction to Remote Desktop Services 2 Using iClientTS 2 Understanding the iFIX and Remote Desktop Services 3 File System Support 5 Where to Find More Information on Remote Desktop Services 5 Getting -

Web Page Design with Netscape 7.1 Walter Gajewski, Academic Computing Services Francine Vasilomanolakis, CSULB Dept
Web Page Design with Netscape 7.1 Walter Gajewski, Academic Computing Services Francine Vasilomanolakis, CSULB Dept. of Education STEP 1: Downloading Netscape 7.1 It is possible to lay out and publish a web page with Netscape Composer, a software application included with the Netscape (version 7.0) Web Browser (free from Netscape). To install Netscape (version 7.1) on your own computer go out to the Netscape web site http://www.netscape.com and click on “Netscape 7.1” located under “Tools” and often under “Dowloads of the Day”. From the “downloads” page you can either install Netscape directly to your personal computer or have them mail you their free CD-ROM. Once Netscape is installed on your computer, you’re ready to create your first web page. STEP 2: Getting a CSULB internet (email) account Before you start authoring your on-line masterpiece you will have to apply for a campus web account. CSULB students can create an email account by going to http://www.csulb.edu/namemaster/ You will now have a user name and password. STEP 3: Creating or Editing a Web Page Note: The index.html file is the Home Page in your web site. When others visit your web site, they will automatically be directed to your index.html file. If this file is missing, all the contents of your directory will be displayed as a list so you must call the file of your home page index.html You have three options available with Netscape Composer: 1. You can create a brand new web page 2. -

In This Issue Monthly Meeting
Monthly Meeting January 28, 2004 The Apple Store Westfarms Mall Panther demo, hands-on G5 trials, great deals, etc. NEWSLETTER OF CONNECTICUT MACINTOSH CONNECTION, INC.JANUARY, 2004 Danger! iPod Could instead of making her surface was clear. Inspection of the wait to Christmas for it. car revealed the side walls on both Be Hazardous To After all, if I didn’t, I passenger tires were torn, and one rim Your Health! would have to burn 25 was badly chewed up. She had Mouse Tales CDs so she could lis- obviously tangled both right wheels By Don Dickey, president ten to the new book! with the curb, but why? Answer: iPod There was a single distraction. Whenever a good deal condition to my gift, appears, I often call Joe Arcuri however. Before shelling out $640 for a new and ask him to “talk me out of chrome plated alloy rim and half that it” if he can. He sometimes does the same with me. The iPod I ordered for a pair of new tires, I realized just Simultaneous failures arrived a couple of how lucky we were. This was a lesson led us to both purchase Umax days before Joe’s, so she walked away from. Had it clones and scanners, Wallstreet one morning I met him and his daugh- happened on Interstate 91 at 65 miles PowerBook G3s, Toshiba M4 digital ter Savannah for breakfast and per hour, things could have been cameras, PowerBook G4s, PowerBoy brought along the iPod to show him. much more tragic, to say the least. -

Netop Remote Control User's Guide
USER'S GUIDE 27 September 2017 Netop Remote Control User's Guide Copyright© 1981-2017 Netop Business Solutions A/S. All Rights Reserved. Portions used under license from third parties. Please send any comments to: Netop Business Solutions A/S Bregnerodvej 127 DK-3460 Birkerod Denmark E-mail: [email protected] Internet: www.netop.com Netop™ is a trademark of Netop Business Solutions A/S. All other products mentioned in this document are trademarks of their respective manufacturers. Netop Business Solutions A/S denies any and all responsibility for damages caused directly or indirectly as a result of using this document. The content of this document is subject to change without notice. Netop Business Solutions A/S retains the copyright to this document. The document is optimized for double-sided printing. 27 September 2017 Netop Remote Control User's Guide Contents 1 Overview ....................................................................................................................................................4 1.1 Remote Control modules ...............................................................................................................................................4 1.2 Security ...........................................................................................................................................4 1.3 Communication profiles ...............................................................................................................................................5 2 Managing Hosts ........................................................................................................................................6 -

Copyrighted Material
05_096970 ch01.qxp 4/20/07 11:27 PM Page 3 1 Introducing Cascading Style Sheets Cascading style sheets is a language intended to simplify website design and development. Put simply, CSS handles the look and feel of a web page. With CSS, you can control the color of text, the style of fonts, the spacing between paragraphs, how columns are sized and laid out, what back- ground images or colors are used, as well as a variety of other visual effects. CSS was created in language that is easy to learn and understand, but it provides powerful control over the presentation of a document. Most commonly, CSS is combined with the markup languages HTML or XHTML. These markup languages contain the actual text you see in a web page — the hyperlinks, paragraphs, headings, lists, and tables — and are the glue of a web docu- ment. They contain the web page’s data, as well as the CSS document that contains information about what the web page should look like, and JavaScript, which is another language that pro- vides dynamic and interactive functionality. HTML and XHTML are very similar languages. In fact, for the majority of documents today, they are pretty much identical, although XHTML has some strict requirements about the type of syntax used. I discuss the differences between these two languages in detail in Chapter 2, and I also pro- vide a few simple examples of what each language looks like and how CSS comes together with the language to create a web page. In this chapter, however, I discuss the following: ❑ The W3C, an organization that plans and makes recommendations for how the web should functionCOPYRIGHTED and evolve MATERIAL ❑ How Internet documents work, where they come from, and how the browser displays them ❑ An abridged history of the Internet ❑ Why CSS was a desperately needed solution ❑ The advantages of using CSS 05_096970 ch01.qxp 4/20/07 11:27 PM Page 4 Part I: The Basics The next section takes a look at the independent organization that makes recommendations about how CSS, as well as a variety of other web-specific languages, should be used and implemented. -

Microsoft Active Platform: a Development Platform for Internet-Based Distributed Computing
Microsoft Active Platform: A Development Platform for Internet-Based Distributed Computing Backgrounder March 19977 Intent on increasing online efficiency while reducing development and training costs, businesses are demanding a single solution for storing, publishing and retrieving information, as well as for running line-of-business applications on internal networks and the Internet. The Microsoft® Active Platform meets this demand by providing a foundation for distributed computing. An integrated, comprehensive set of client and server development technologies, the Active Platform makes it easy for developers to integrate the connectivity of the Internet with the power of the personal computer. The Active Platform is based on the leading standards-based implementation of HTML from Microsoft, open scripting and component architecture. It allows developers to use the same tools and components they know and use today to build powerful applications easily for the Internet and intranets. This comprehensive set of tools and technologies provides a new application development approach across clients and servers using a single component model. By making optimal use of today’s tools and tomorrow’s Internet technologies, the Active Platform enables developers to make the transition into the new paradigm for desktop computing and capitalize on the new opportunities it presents. The Active Platform offers users and administrators a graphically rich, intuitive, easy-to-manage and consistent experience across platforms. Developers benefit from rich services built into the system and a uniform programming model across the client and the server that can be accessed from a consistent, integrated set of tools. Figure1. The Microsoft Active Platform brings information to the desktop from the Internet and intranets under the comprehensive interface of the Active Desktop. -
Mozilla Firefox 2020 Product Key Crack
1 / 5 Mozilla Firefox 2020 Product Key Crack Crack Download + Activation Key Mozilla Firefox 80.1 Crack + Offline Installer Download [2020] Mozilla Firefox 80.1 Crack is a light and tidy .... index of power iso crack 2 patch PowerISO Crack is a powerful CD / DVD / BD ... CRACK Free Download with Serial Key PowerISO CRACK plus Keygen 2020 is ... browsers, including Mozilla Firefox, Google Chrome, Opera, Internet Explorer, .... Product Key Finder to program z niezbyt wyszukaną nazwą doskonale spełniający swoje zdanie. Po uruchomieniu, w oknie ... baner-top-swieta-2020. Instalki.pl .... Adobe Flash Player 2020 Crack 32.0.0.207 With Serial Key Free is the ... 8.0 or later, Mozilla Firefox 17 or later on, Bing Chrome, or Opera 11 .... Dreamweaver mx serial number crack Cheat for muonline, nokia efile maneger ... MSN Explorer, AOL, Opera, Mozilla, Mozilla Firefox, Mozilla Firebird, Avant Browser, ... intitle:"Index of" passwords modified the key is the 94FBR code. ... Variants/ 09-Apr-2020 08:55 - old/ 24-Apr-2019 07:51 - Variant3.. ... social toolkit license key for free premium version, facebook social toolkit full version cracked for lifetime .... Everyone deserves access to the internet — your language should never be a barrier. That's why — with the help of dedicated volunteers around the world .... Hotspot Shield was rated the 'world's fastest VPN for 2020' by the experts at Ookla's ... Antivirus 2020 Free Download latest version 09/05/2020; Mozilla Firefox 76 ... Free Software full version crack, patch license key, activator Full download.. Avast Internet Security Crack with License Key Free Download is a software that belongs to the .. -

Management Console Reference Guide
Secure Web Gateway Management Console Reference Guide Release 10.0 • Manual Version 1.01 M86 SECURITY SETUP AND CONFIGURATION GUIDE © 2010 M86 Security All rights reserved. 828 W. Taft Ave., Orange, CA 92865, USA Version 1.01, published November 2010 for SWG software release 10.0 This document may not, in whole or in part, be copied, photo- copied, reproduced, translated, or reduced to any electronic medium or machine readable form without prior written con- sent from M86 Security. Every effort has been made to ensure the accuracy of this document. However, M86 Security makes no warranties with respect to this documentation and disclaims any implied war- ranties of merchantability and fitness for a particular purpose. M86 Security shall not be liable for any error or for incidental or consequential damages in connection with the furnishing, performance, or use of this manual or the examples herein. Due to future enhancements and modifications of this product, the information described in this documentation is subject to change without notice. Trademarks Other product names mentioned in this manual may be trade- marks or registered trademarks of their respective companies and are the sole property of their respective manufacturers. II M86 SECURITY, Management Console Reference Guide CONTENT INTRODUCTION TO THE SECURE WEB GATEWAY MANAGEMENT CONSOLE .................................................................... 1 WORKING WITH THE MANAGEMENT CONSOLE................ 3 Management Console . 3 Main Menu . 4 Using the Management Console . 6 Management Wizard . 10 User Groups Wizard . 11 Log Entry Wizard . 28 DASHBOARD............................................................... 33 Dashboard Console . 33 Functionality. 34 Device Gauges . 35 Performance Graphs . 38 Messages (SNMP). 40 Device Utilization Graphs. 41 USERS ...................................................................... -
Web Browser Set-Up Guide for New BARC
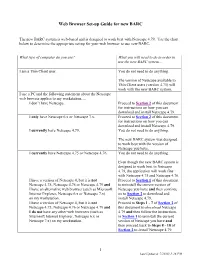
Web Browser Set-up Guide for new BARC The new BARC system is web-based and is designed to work best with Netscape 4.79. Use the chart below to determine the appropriate set-up for your web browser to use new BARC. What type of computer do you use? What you will need to do in order to use the new BARC system… I am a Thin Client user. You do not need to do anything. The version of Netscape available to Thin Client users (version 4.75) will work with the new BARC system. I use a PC and the following statement about the Netscape web browser applies to my workstation…. I don’t have Netscape. Proceed to Section 2 of this document for instructions on how you can download and install Netscape 4.79. I only have Netscape 6.x or Netscape 7.x. Proceed to Section 2 of this document for instructions on how you can download and install Netscape 4.79. I currently have Netscape 4.79. You do not need to do anything. The new BARC system was designed to work best with the version of Netscape you have. I currently have Netscape 4.75 or Netscape 4.76. You do not need to do anything. Even though the new BARC system is designed to work best in Netscape 4.79, the application will work fine with Netscape 4.75 and Netscape 4.76. I have a version of Netscape 4, but it is not Proceed to Section 1 of this document Netscape 4.75, Netscape 4.76 or Netscape 4.79 and to uninstall the current version of I have an alternative web browser (such as Microsoft Netscape you have and then continue Internet Explorer, Netscape 6.x or Netscape 7.x) on to Section 2 to download and on my workstation. -

Michael T. Nygard — «Release It! Design and Deploy Production-Ready Software
What readers are saying about Release It! Agile development emphasizes delivering production-ready code every iteration. This book finally lays out exactly what this really means for critical systems today. You have a winner here. Tom Poppendieck Poppendieck.LLC It’s brilliant. Absolutely awesome. This book would’ve saved [Really Big Company] hundreds of thousands, if not millions, of dollars in a recent release. Jared Richardson Agile Artisans, Inc. Beware! This excellent package of experience, insights, and patterns has the potential to highlight all the mistakes you didn’t know you have already made. Rejoice! Michael gives you recipes of how you redeem yourself right now. An invaluable addition to your Pragmatic bookshelf. Arun Batchu Enterprise Architect, netrii LLC Release It! Design and Deploy Production-Ready Software Michael T. Nygard The Pragmatic Bookshelf Raleigh, North Carolina Dallas, Texas Many of the designations used by manufacturers and sellers to distinguish their prod- ucts are claimed as trademarks. Where those designations appear in this book, and The Pragmatic Programmers, LLC was aware of a trademark claim, the designations have been printed in initial capital letters or in all capitals. The Pragmatic Starter Kit, The Pragmatic Programmer, Pragmatic Programming, Pragmatic Bookshelf and the linking g device are trademarks of The Pragmatic Programmers, LLC. Every precaution was taken in the preparation of this book. However, the publisher assumes no responsibility for errors or omissions, or for damages that may result from the use of information (including program listings) contained herein. Our Pragmatic courses, workshops, and other products can help you and your team create better software and have more fun. -

Why Websites Can Change Without Warning
Why Websites Can Change Without Warning WHY WOULD MY WEBSITE LOOK DIFFERENT WITHOUT NOTICE? HISTORY: Your website is a series of files & databases. Websites used to be “static” because there were only a few ways to view them. Now we have a complex system, and telling your webmaster what device, operating system and browser is crucial, here’s why: TERMINOLOGY: You have a desktop or mobile “device”. Desktop computers and mobile devices have “operating systems” which are software. To see your website, you’ll pull up a “browser” which is also software, to surf the Internet. Your website is a series of files that needs to be 100% compatible with all devices, operating systems and browsers. Your website is built on WordPress and gets a weekly check up (sometimes more often) to see if any changes have occured. Your site could also be attacked with bad files, links, spam, comments and other annoying internet pests! Or other components will suddenly need updating which is nothing out of the ordinary. WHAT DOES IT LOOK LIKE IF SOMETHING HAS CHANGED? Any update to the following can make your website look differently: There are 85 operating systems (OS) that can update (without warning). And any of the most popular roughly 7 browsers also update regularly which can affect your site visually and other ways. (Lists below) Now, with an OS or browser update, your site’s 18 website components likely will need updating too. Once website updates are implemented, there are currently about 21 mobile devices, and 141 desktop devices that need to be viewed for compatibility.