C++ Programming/Print Version
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Imagine. Create. Deploy. Inspired? So Are We
Imagine. Create. Deploy. Inspired? So Are We. Inspiration is all around us. From beautiful screens on the web to well-designed reports. New devices push the development envelope and ask that we consider new technologies. The latest release, DevExpress 12.2, delivers the tools you need to build the multi-channel solutions you can imagine: Windows 8-inspired applications with live tiles perfect for Microsoft Surface, multi-screen iOS and Android apps. It’s all possible. Let’s see what develops. Download your 30-day trial at www.DevExpress.com Copyright 1998-2013 Developer Express, Inc. All rights reserved. All trademarks are property of their respective owners. Untitled-9 1 1/8/13 2:10 PM THE MICROSOFT JOURNAL FOR DEVELOPERS MARCH 2013 VOL 28 NO 3 magazine XAML with DirectX and C++..............34 Using XAML with DirectX and C++ COLUMNS in Windows Store Apps WINDOWS WITH C++ Doug Erickson .................................................................34 Rendering in a Desktop Application with Direct2D Exploring the JavaScript API for Offi ce: Kenny Kerr, page 8 Data Access and Events DATA POINTS Stephen Oliver and Eric Schmidt ........................................48 Playing with the EF6 Alpha Julie Lerman, page 16 Best Practices in Asynchronous Programming WINDOWS AZURE INSIDER Stephen Cleary ................................................................56 Real-World Scenarios for Node.js in Windows Azure Migrating ASP.NET Web Forms to the Bruno Terkaly and Ricardo Villalobos, page 26 MVC Pattern with the ASP.NET Web API THE WORKING -

Imagine. Create. Deploy. Inspired? So Are We
Imagine. Create. Deploy. Inspired? So Are We. Inspiration is all around us. From beautiful screens on the web to well-designed reports. New devices push the development envelope and ask that we consider new technologies. The latest release, DevExpress 12.2, delivers the tools you need to build the multi-channel solutions you can imagine: Windows 8-inspired applications with live tiles perfect for Microsoft Surface, multi-screen iOS and Android apps. It’s all possible. Let’s see what develops. Download your 30-day trial at www.DevExpress.com Copyright 1998-2013 Developer Express, Inc. All rights reserved. All trademarks are property of their respective owners. Untitled-9 1 1/8/13 2:10 PM THE MICROSOFT JOURNAL FOR DEVELOPERS FEBRUARY 2013 VOL 28 NO 2 magazine JavaScript API for Offi ce.........................20 Exploring the New JavaScript API for Offi ce COLUMNS Stephen Oliver and Eric Schmidt ........................................20 CUTTING EDGE Essential Facebook Async Causality Chain Tracking Programming: Andrew Stasyuk ...............................................................32 The JavaScript SDK Dino Esposito, page 6 Building a Simple Comet Application WINDOWS WITH C++ in the Microsoft .NET Framework Creating Desktop Apps Derrick Lau .....................................................................42 with Visual C++ 2012 Kenny Kerr, page 12 Detecting Abnormal Data Using TEST RUN k-Means Clustering Naive Bayes Classifi cation with C# ............................................................. James McCaffrey 54 James McCaffrey, -

(DNC) Magazine
EDITOR’S NOTE @suprotimagarwal Editor in Chief Developers! Developers! Developers! A decade ago, bathed in sweat, Editor In Chief : yelled the one and only Steve Balmer as if he was addressing a sect Suprotim Agarwal that's unlike any other. (suprotimagarwal@ dotnetcurry.com) But why am I bringing this up now? Art Director : Minal Agarwal In the Software ecosystem, change has always been disruptive and has occured more frequently than ever. Contributing Authors : Yacoub Massad Organizations have had the best of intentions while adapting to these Gouri Sohoni frequent changes and have often pondered seriously accelerating their Darren Gillis Daniel Jimenez Garcia digital transformation journey. The actual transformation though has Damir Arh been quite slow due to restraints like time and budget. Benjamin Jakobus That is, until now. Technical Reviewers : Damir Arh The pandemic that began in 2020 forced companies to reformulate Daniel Jimenez Garcia their plans and pivot by setting up remote working environments. Years’ Gouri Sohoni Subodh Sohoni worth of digital transformation, happened in just a matter of months! Suprotim Agarwal And at the center of this were the Developers and IT staff, playing Yacoub Massad a crucial role in this transformation. Sitting in remote locations, and dealing with unprecedented challenges, developers have been working Next Edition : asynchronously to skill, reskill and upskill themselves, and make their April 2021 organizations more agile. Windows, Visual Studio, ASP.NET, Azure, TFS & other Microsoft products & technologies are trademarks of Nobody knows for sure what 2021 and the coming years has in store the Microsoft group of companies. for us. I sincerelly hope it's good for everyone. -
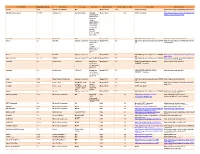
Third Party Version
Third Party Name Third Party Version Manufacturer License Type Comments Merge Product Merge Product Versions License details Software source autofac 3.5.2 Autofac Contributors MIT Merge Cardio 10.2 SOUP repository https://www.nuget.org/packages/Autofac/3.5 .2 Gibraltar Loupe Agent 2.5.2.815 eSymmetrix Gibraltor EULA Gibraltar Merge Cardio 10.2 SOUP repository https://my.gibraltarsoftware.com/Support/Gi Loupe Agent braltar_2_5_2_815_Download will be used within the Cardio Application to view events and metrics so you can resolve support issues quickly and easily. Modernizr 2.8.3 Modernizr MIT Merge Cadio 6.0 http://modernizr.com/license/ http://modernizr.com/download/ drools 2.1 Red Hat Apache License 2.0 it is a very old Merge PACS 7.0 http://www.apache.org/licenses/LICENSE- http://mvnrepository.com/artifact/drools/dro version of 2.0 ols-spring/2.1 drools. Current version is 6.2 and license type is changed too drools 6.3 Red Hat Apache License 2.0 Merge PACS 7.1 http://www.apache.org/licenses/LICENSE- https://github.com/droolsjbpm/drools/releases/ta 2.0 g/6.3.0.Final HornetQ 2.2.13 v2.2..13 JBOSS Apache License 2.0 part of JBOSS Merge PACS 7.0 http://www.apache.org/licenses/LICENSE- http://mvnrepository.com/artifact/org.hornet 2.0 q/hornetq-core/2.2.13.Final jcalendar 1.0 toedter.com LGPL v2.1 MergePacs Merge PACS 7.0 GNU LESSER GENERAL PUBLIC http://toedter.com/jcalendar/ server uses LICENSE Version 2. v1, and viewer uses v1.3. -

Optimizing Software in C++ an Optimization Guide for Windows, Linux and Mac Platforms
1. Optimizing software in C++ An optimization guide for Windows, Linux and Mac platforms By Agner Fog. Copenhagen University College of Engineering. Copyright © 2004 - 2010. Last updated 2010-02-16. Contents 1 Introduction ....................................................................................................................... 3 1.1 The costs of optimizing ............................................................................................... 4 2 Choosing the optimal platform........................................................................................... 4 2.1 Choice of hardware platform....................................................................................... 4 2.2 Choice of microprocessor ........................................................................................... 6 2.3 Choice of operating system......................................................................................... 6 2.4 Choice of programming language ............................................................................... 7 2.5 Choice of compiler ...................................................................................................... 9 2.6 Choice of function libraries........................................................................................ 11 2.7 Choice of user interface framework........................................................................... 13 2.8 Overcoming the drawbacks of the C++ language...................................................... 14 3 Finding -

Benjamin Eugene Key's Resume
Benjamin Eugene Key's Resume Benjamin Eugene Key 12343 Hunters Chase Dr. Apt 826 Austin, Texas 78729-7217 Home: (512) 250-2239 Mobile: (512) 773-0652 E-Mail: [email protected] Summary A dedicated, self-motivated, and self-taught Software Engineer with demonstrated suc cess in the design and development of Assistive Technology applications for Microsoft Windows operating systems. Sixteen years of experience in developing software using C++ and a deep understanding of using object-oriented design principles. Proven problem-solving skills. Proven ability to acquire knowledge about new concepts independently in a short amount of time. Qualifications Programming Languages • C++17 • C++14 • C++11 • C++ • C# • Python • JAWS Scripting Language 1 Markup Languages • HTML 5 • HTML 4 • CSS • Markdown APIs, Frameworks, and Libraries • Win32 API (Windows Application Programming Interface) • STL (Standard Template Library) • MFC (Microsoft Foundation Class Library) • ATL (Active Template Library) • WTL (Windows Template Library) • Boost C++ Libraries • COM (Component Object Model) • MSAA (Microsoft Active Accessibility) • Microsoft SAPI (Speech Application Programming Interface) 4 • Microsoft SAPI 5 • Microsoft Speech Platform 11 • Vocalizer Expressive by Nuance Applications • Microsoft Visual Studio 2017 • Microsoft Visual Studio 2015 • Microsoft Visual Studio 2013 • Microsoft Visual Studio 2010 • Microsoft Visual Studio 2005 • Microsoft Visual Studio 2003 • Microsoft Visual C++ 6 • Microsoft Embedded Visual C++ 4.0 • Perforce • BugZilla • Defect -

Windows® Embedded CE 6.0 Fundamentals
Windows® Embedded CE 6.0 Fundamentals Stanislav Pavlov Pavel Belevsky Chapter 9 Application Development This chapter covers the differences between native and managed code, choosing when to create an operating system (OS) design subproject or a separately developed project, how to prepare for application development, making device connections, and application debugging approaches . For detailed information about native code application development for Windows Embedded CE, see Douglas Boling’s book, “Programming Windows Embedded CE 6 .0 Developer Reference, 4th Edition,” and for more information about managed code application development, see the book of Andy Wigley, Daniel Moth, and Peter Foot, “Microsoft Mobile Development Handbook ”. Alternatively, you can use the MSDN Web site to find documentation, code samples, articles, virtual labs, and Web casts . You can build applications for Windows Embedded CE by using native code or managed code . Native code applications can be built as subprojects of the OS design, or as individual projects . When building projects by using native code separately from the OS design, the first step is to build an OS design, and later build applications for it . After that, an SDK should be created and installed with the development tools . Managed code applications can be built only as separate applications . However, as opposed to native code applications, managed code applications actually do not require an SDK to be installed with the development tools, and instead require the execution environment of the device . Native Code and Managed Code Native (unmanaged) code is code written in C/C++ or ASM and compiled on a development workstation to produce binary code that is native to the device processor . -

Bigfix Lifecycle Starter Kit Open Source Licenses and Notices
---------------------------------- BigFix Lifecycle StarterKit 10.0 Jan 2021 ---------------------------------- ------------------------------------------------------------------------- ------------------------------------------------------------------------- The HCL license agreement and any applicable information on the web download page for HCL products refers Licensee to this file for details concerning notices applicable to code included in the products listed above ("the Program"). Notwithstanding the terms and conditions of any other agreement Licensee may have with HCL or any of its related or affiliated entities (collectively "HCL"), the third party code identified below is subject to the terms and conditions of the HCL license agreement for the Program and not the license terms that may be contained in the notices below. The notices are provided for informational purposes. Please note: This Notices file may identify information that is not used by, or that was not shipped with, the Program as Licensee installed it. IMPORTANT: HCL does not represent or warrant that the information in this NOTICES file is accurate. Third party websites are independent of HCL and HCL does not represent or warrant that the information on any third party website referenced in this NOTICES file is accurate. HCL disclaims any and all liability for errors and omissions or for any damages accruing from the use of this NOTICES file or its contents, including without limitation URLs or references to any third party websites. ------------------------------------------------------------------------- -

Evolving a Language in and for the Real World: C++ 1991-2006
Evolving a language in and for the real world: C++ 1991-2006 Bjarne Stroustrup Texas A&M University www.research.att.com/~bs Abstract Obviously, the C++ community spent the most time and This paper outlines the history of the C++ programming lan- money on the first of those items. The ISO C++ standards guage from the early days of its ISO standardization (1991), committee tends to focus on the second with some concern through the 1998 ISO standard, to the later stages of the for the third. My main effort was on the third and the fourth. C++0x revision of that standard (2006). The emphasis is on The ISO committee is the focus for people who aim to the ideals, constraints, programming techniques, and people improve the C++ language and standard library. Through that shaped the language, rather than the minutiae of lan- such change they (we) hope to improve the state of the guage features. Among the major themes are the emergence art in real-world C++ programming. The work of the C++ of generic programming and the STL (the C++ standard li- standards committee is the primary focus of the evolution of brary’s algorithms and containers). Specific topics include C++ and of this paper. separate compilation of templates, exception handling, and Thinking of C++ as a platform for applications, many support for embedded systems programming. During most have wondered why — after its initial success — C++ didn’t of the period covered here, C++ was a mature language with shed its C heritage to “move up the food chain” and be- millions of users. -

Marcus Ljung Och Per Turner Examensarbete V2013
Computer Science, Degree Project, Advanced Course, 15 Credits CAN TOOL FOR ATLAS COPCO’S RIG CONTROL SYSTEM Marcus Ljung and Per Turner Computer Engineering Programme, 180 Credits Örebro, Sweden, Spring 2013 Examiner: Lars Karlsson CAN-VERKTYG FÖR ATLAS COPCOS RIGGKONTROLLSYSTEM Örebro universitet Örebro University Institutionen för School of Science and Technology naturvetenskap och teknik SE-701 82 Örebro, Sweden 701 82 Örebro Abstract The goal of this 15 hp thesis in computer engineering was to develop a tool for monitoring and analyzing the data flow on a Controller Area Network (CAN) called Rig Control System (RCS) that is used by Atlas Copco. Atlas Copco develops and manufactures machines for Mining and Rock Excavation. The Rocktec division is responsible for the Rig Control System platform used on machines in all division within the Mining and Rock Excavation Technique (MR) business area. The tool’s primary purpose is monitor and analyze data from the RCS network and present the analyzed data in an easy way to help with development and maintenance of RCS and machines that use RCS. The advantages and how data is sent over the CAN bus are presented as well as the CANopen protocol which is a higher layer protocol based on CAN. Two ways of data acquisition from RCS are presented, a simulated environment and real hardware. Different types of interprocess communication are presented as well as the pros and cons of each of these types. The creation of the tool required a Graphical User Interface (GUI) so different frameworks for this task are also presented and discussed. -

Evolving a Language in and for the Real World: C++ 1991-2006
Evolving a language in and for the real world: C++ 1991-2006 Bjarne Stroustrup Texas A&M University www.research.att.com/~bs Abstract Obviously, the C++ community spent the most time and This paper outlines the history of the C++ programming lan- money on the first of those items. The ISO C++ standards guage from the early days of its ISO standardization (1991), committee tends to focus on the second with some concern through the 1998 ISO standard, to the later stages of the for the third. My main effort was on the third and the fourth. C++0x revision of that standard (2006). The emphasis is on The ISO committee is the focus for people who aim to the ideals, constraints, programming techniques, and people improve the C++ language and standard library. Through that shaped the language, rather than the minutiae of lan- such change they (we) hope to improve the state of the guage features. Among the major themes are the emergence art in real-world C++ programming. The work of the C++ of generic programming and the STL (the C++ standard li- standards committee is the primary focus of the evolution of brary’s algorithms and containers). Specific topics include C++ and of this paper. separate compilation of templates, exception handling, and Thinking of C++ as a platform for applications, many support for embedded systems programming. During most have wondered why — after its initial success — C++ didn’t of the period covered here, C++ was a mature language with shed its C heritage to “move up the food chain” and be- millions of users. -

Webroot Secureanywhere for Business
Webroot SecureAnywhere® Business Apache License Version 2.0 • Apache-Logging log4net version 1.2.10 Copyright © 2004-2017 Apache Software Foundation • ASP.Net MVC WebApi Client version 1.0.0 Copyright © .NET Foundation • ASP.NET MVC version 4.0.20710.0 Copyright © Microsoft Corporation • aws-sdk-net Copyright Copyright © 2008 Amazon.com • bootstrap-paginator 1 Copyright © 2013 Yun Lai • Bootstrap-Tree version 0.2 1 Copyright © 2012 Cutters Crossing • Common.Logging.Core Copyright © Aleksandar Seovic, Mark Pollack, Erich Eichinger, Stephen Bohlen Fluent Migrator Tools version 1.5.1 Copyright © 2007-2018, Sean Chambers • common-logging version 3.3.1 Copyright © 2001-201 Aleksandar Seovic, Mark Pollack, Erich Eichinger, Stephen Bohlen Common.Logging version 2.1.2 Copyright © Aleksandar Seovic, Mark Pollack, Erich Eichinger, Stephen Bohlen • Fluent Migrator Tools 1.5.1Contributors at https://github.com/fluentmigrator/fluentmigrator/blob/master/CONTRIBUTORS.md • log4net versions 1.2.11 version 2.0.3 Copyright © 2004-2017 Apache Software Foundation. • Quartz Enterprise Scheduler .NET version 2.2.4 Copyright © .NET Foundation. • Quartz Enterprise Scheduler .NET version 2.5 Copyright © .NET Foundation. • SignalR Copyright © .NET Foundation. • swagger-codegen Copyright © 2016 SmartBear Software • System.Web.Mvc.Extensions Copyright © 2015 HZBC Inc • Xunit version 2.4 Copyright © .NET Foundation and Contributors Apache License Version 2.0, January 2004 TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION Definitions. “License” shall mean the terms and conditions for use, reproduction, and distribution as defined by Sections 1 through 9 of this document. “Licensor” shall mean the copyright owner or entity authorized by the copyright owner that is granting the License.