(DNC) Magazine
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Imagine. Create. Deploy. Inspired? So Are We
Imagine. Create. Deploy. Inspired? So Are We. Inspiration is all around us. From beautiful screens on the web to well-designed reports. New devices push the development envelope and ask that we consider new technologies. The latest release, DevExpress 12.2, delivers the tools you need to build the multi-channel solutions you can imagine: Windows 8-inspired applications with live tiles perfect for Microsoft Surface, multi-screen iOS and Android apps. It’s all possible. Let’s see what develops. Download your 30-day trial at www.DevExpress.com Copyright 1998-2013 Developer Express, Inc. All rights reserved. All trademarks are property of their respective owners. Untitled-9 1 1/8/13 2:10 PM THE MICROSOFT JOURNAL FOR DEVELOPERS MARCH 2013 VOL 28 NO 3 magazine XAML with DirectX and C++..............34 Using XAML with DirectX and C++ COLUMNS in Windows Store Apps WINDOWS WITH C++ Doug Erickson .................................................................34 Rendering in a Desktop Application with Direct2D Exploring the JavaScript API for Offi ce: Kenny Kerr, page 8 Data Access and Events DATA POINTS Stephen Oliver and Eric Schmidt ........................................48 Playing with the EF6 Alpha Julie Lerman, page 16 Best Practices in Asynchronous Programming WINDOWS AZURE INSIDER Stephen Cleary ................................................................56 Real-World Scenarios for Node.js in Windows Azure Migrating ASP.NET Web Forms to the Bruno Terkaly and Ricardo Villalobos, page 26 MVC Pattern with the ASP.NET Web API THE WORKING -

NET-Microservices-Architecture-For-Containerized-NET-Applications
i EDITION v2.2.1 DOWNLOAD available at: https://aka.ms/microservicesebook PUBLISHED BY Microsoft Developer Division, .NET and Visual Studio product teams A division of Microsoft Corporation One Microsoft Way Redmond, Washington 98052-6399 Copyright © 2019 by Microsoft Corporation All rights reserved. No part of the contents of this book may be reproduced or transmitted in any form or by any means without the written permission of the publisher. This book is provided “as-is” and expresses the author’s views and opinions. The views, opinions and information expressed in this book, including URL and other Internet website references, may change without notice. Some examples depicted herein are provided for illustration only and are fictitious. No real association or connection is intended or should be inferred. Microsoft and the trademarks listed at http://www.microsoft.com on the “Trademarks” webpage are trademarks of the Microsoft group of companies. Mac and macOS are trademarks of Apple Inc. The Docker whale logo is a registered trademark of Docker, Inc. Used by permission. All other marks and logos are property of their respective owners. Co-Authors: Editors: Cesar de la Torre, Sr. PM, .NET product team, Microsoft Corp. Mike Pope Bill Wagner, Sr. Content Developer, C+E, Microsoft Corp. Steve Hoag Mike Rousos, Principal Software Engineer, DevDiv CAT team, Microsoft Participants and reviewers: Jeffrey Richter, Partner Software Eng, Azure team, Microsoft Steve “ardalis” Smith - Software Architect and Trainer - Ardalis.com Jimmy Bogard, Chief Architect at Headspring Ian Cooper, Coding Architect at Brighter Udi Dahan, Founder & CEO, Particular Software Unai Zorrilla, Architect and Dev Lead at Plain Concepts Jimmy Nilsson, Co-founder and CEO of Factor10 Eduard Tomas, Dev Lead at Plain Concepts Glenn Condron, Sr. -

Imagine. Create. Deploy. Inspired? So Are We
Imagine. Create. Deploy. Inspired? So Are We. Inspiration is all around us. From beautiful screens on the web to well-designed reports. New devices push the development envelope and ask that we consider new technologies. The latest release, DevExpress 12.2, delivers the tools you need to build the multi-channel solutions you can imagine: Windows 8-inspired applications with live tiles perfect for Microsoft Surface, multi-screen iOS and Android apps. It’s all possible. Let’s see what develops. Download your 30-day trial at www.DevExpress.com Copyright 1998-2013 Developer Express, Inc. All rights reserved. All trademarks are property of their respective owners. Untitled-9 1 1/8/13 2:10 PM THE MICROSOFT JOURNAL FOR DEVELOPERS FEBRUARY 2013 VOL 28 NO 2 magazine JavaScript API for Offi ce.........................20 Exploring the New JavaScript API for Offi ce COLUMNS Stephen Oliver and Eric Schmidt ........................................20 CUTTING EDGE Essential Facebook Async Causality Chain Tracking Programming: Andrew Stasyuk ...............................................................32 The JavaScript SDK Dino Esposito, page 6 Building a Simple Comet Application WINDOWS WITH C++ in the Microsoft .NET Framework Creating Desktop Apps Derrick Lau .....................................................................42 with Visual C++ 2012 Kenny Kerr, page 12 Detecting Abnormal Data Using TEST RUN k-Means Clustering Naive Bayes Classifi cation with C# ............................................................. James McCaffrey 54 James McCaffrey, -

Real-Time Web Application Development Real-Time Web Development Application
Vemula FOR PROFESSIONALS BY PROFESSIONALS® Real-Time Web Application Development Application Development Web Real-Time Design, develop, and deploy a real-world web application by leveraging modern open source technologies. This book shows you how to use ASP.NET Core to build cross-platform web applications along with SignalR to enrich the application by enabling real-time communication between server and clients. You will use Docker to containerize your application, integrate with GitHub to package the application, and provide continuous deployment to Azure’s IaaS platform. Along the way, Real-Time Web Application Development covers topics including designing a Materialize CSS theme, using a test-driven development approach with xUnit.net, and securing your application with the OAuth 2.0 protocol. To further your understanding of the technology, you will learn logging and exception handling; navigation using view components; and how to work with forms and validations. The rich code samples from this book can be used to retrofit or upgrade existing ASP.NET Core applications. Real-Time Web You will: • Design and develop a real-world web application • Implement security and data storage with OAuth2 and Azure Table Storage • Orchestrate real-time notifications through SignalR Application • Use GitHub and Travis CI for continuous integration of code • Master Docker containerization and continuous deployment with Docker Cloud to Azure Linux virtual machines Development With ASP.NET Core, SignalR, Docker, and Azure — US $44.99 Rami Vemula ISBN 978-1-4842-3269-9 54499 Shelve in: .NET User Level: Beginning–Intermediate 9781484 232699 SOURCE CODE ONLINE www.apress.com Real-Time Web Application Development With ASP.NET Core, SignalR, Docker, and Azure Rami Vemula Real-Time Web Application Development Rami Vemula Visakhapatnam, Andhra Pradesh, India ISBN-13 (pbk): 978-1-4842-3269-9 ISBN-13 (electronic): 978-1-4842-3270-5 https://doi.org/10.1007/978-1-4842-3270-5 Library of Congress Control Number: 2017960937 Copyright © 2017 by Rami Vemula This work is subject to copyright. -

NET Technology Guide for Business Applications // 1
.NET Technology Guide for Business Applications Professional Cesar de la Torre David Carmona Visit us today at microsoftpressstore.com • Hundreds of titles available – Books, eBooks, and online resources from industry experts • Free U.S. shipping • eBooks in multiple formats – Read on your computer, tablet, mobile device, or e-reader • Print & eBook Best Value Packs • eBook Deal of the Week – Save up to 60% on featured titles • Newsletter and special offers – Be the first to hear about new releases, specials, and more • Register your book – Get additional benefits Hear about it first. Get the latest news from Microsoft Press sent to your inbox. • New and upcoming books • Special offers • Free eBooks • How-to articles Sign up today at MicrosoftPressStore.com/Newsletters Wait, there’s more... Find more great content and resources in the Microsoft Press Guided Tours app. The Microsoft Press Guided Tours app provides insightful tours by Microsoft Press authors of new and evolving Microsoft technologies. • Share text, code, illustrations, videos, and links with peers and friends • Create and manage highlights and notes • View resources and download code samples • Tag resources as favorites or to read later • Watch explanatory videos • Copy complete code listings and scripts Download from Windows Store Free ebooks From technical overviews to drilldowns on special topics, get free ebooks from Microsoft Press at: www.microsoftvirtualacademy.com/ebooks Download your free ebooks in PDF, EPUB, and/or Mobi for Kindle formats. Look for other great resources at Microsoft Virtual Academy, where you can learn new skills and help advance your career with free Microsoft training delivered by experts. -
Third Party Version
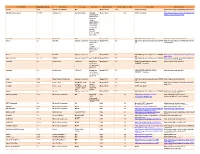
Third Party Name Third Party Version Manufacturer License Type Comments Merge Product Merge Product Versions License details Software source autofac 3.5.2 Autofac Contributors MIT Merge Cardio 10.2 SOUP repository https://www.nuget.org/packages/Autofac/3.5 .2 Gibraltar Loupe Agent 2.5.2.815 eSymmetrix Gibraltor EULA Gibraltar Merge Cardio 10.2 SOUP repository https://my.gibraltarsoftware.com/Support/Gi Loupe Agent braltar_2_5_2_815_Download will be used within the Cardio Application to view events and metrics so you can resolve support issues quickly and easily. Modernizr 2.8.3 Modernizr MIT Merge Cadio 6.0 http://modernizr.com/license/ http://modernizr.com/download/ drools 2.1 Red Hat Apache License 2.0 it is a very old Merge PACS 7.0 http://www.apache.org/licenses/LICENSE- http://mvnrepository.com/artifact/drools/dro version of 2.0 ols-spring/2.1 drools. Current version is 6.2 and license type is changed too drools 6.3 Red Hat Apache License 2.0 Merge PACS 7.1 http://www.apache.org/licenses/LICENSE- https://github.com/droolsjbpm/drools/releases/ta 2.0 g/6.3.0.Final HornetQ 2.2.13 v2.2..13 JBOSS Apache License 2.0 part of JBOSS Merge PACS 7.0 http://www.apache.org/licenses/LICENSE- http://mvnrepository.com/artifact/org.hornet 2.0 q/hornetq-core/2.2.13.Final jcalendar 1.0 toedter.com LGPL v2.1 MergePacs Merge PACS 7.0 GNU LESSER GENERAL PUBLIC http://toedter.com/jcalendar/ server uses LICENSE Version 2. v1, and viewer uses v1.3. -

Redhat and Microsoft
Liens Présentation : http://bit.ly/14juin2018 GitHub des démonstrations : https://github.com/mathieu-benoit/RedHatOpenShiftAndMicrosoftAzureWorkshop Vers OpenShift sur Azure Multiplateforme Windows, Linux and macOS. Rapide Une des technologies web la plus rapide selon les tests de TechEmpower Léger Aucun déploiement d'impact et un modèle de développement modulaire parfait pour les conteneurs Open source Runtime, bibliothèques, compilateur, langues et outils développés dans GitHub Données provenant des tests officiels disponibles àTechEmpower Round 14. “En utilisant le serveur de même taille, nous avons pu passer de 1 000 demandes par seconde par noeud avec Node. js à 20 000 requêtes par seconde avec .Net Core. "— Raygun https://www.microsoft.com/net/customers IdentityManager ASP.NET Core MEF .NET Core Mailkit Kudu Mono Cecil Microsoft Azure SDK for .NET Cake Xamarin.Auth xUnit.net Open Live Writer Mimekit WCF Nancy Couchbase Lite for .NET ASP.NET Web Pages Umbraco LLILC Orchard CMS System.Drawing Open XML SDK IdentityServer ASP.NET MVC OWIN Authentication Middleware NuGet Polly Orleans Microsoft Azure WebJobs SDK Prism Xamarin.Mobile Salesforce Toolkits for .NET ASP.NET SignalR ASP.NET Web API .NET SDK for Hadoop Xamarin SDK WorldWide Telescope Entity Framework Benchmark.NET MVVM Light Toolkit .NET Compiler Platform ("Roslyn") MSBuild ASP.NET AJAX Control Toolkit ProtoBuild eSHOP Référence d’application e onCONTAINERS microservices avec .Net Core Explorez et fournissez vos commentaires: http://aka.ms/MicroservicesArchitecture Shopping Cart Service Catalog Service Inventory Service WEB APP Shipping Service Account Service Azure Container Registry (ACR) Gérer un registre privé de Docker en tant que ressource Azure de première classe Gérer des images pour Utilisez des outils CLI de Geo-réplication du tous les types de Docker familiers et registre de conteneurs conteneurs ouverts Azure Démo ACR - L’expérience du portail Azure Visual Studio Team Services Team Foundation Server DevOps Value cspkg Measure Kubernetes… Service 2. -

Optimizing Software in C++ an Optimization Guide for Windows, Linux and Mac Platforms
1. Optimizing software in C++ An optimization guide for Windows, Linux and Mac platforms By Agner Fog. Copenhagen University College of Engineering. Copyright © 2004 - 2010. Last updated 2010-02-16. Contents 1 Introduction ....................................................................................................................... 3 1.1 The costs of optimizing ............................................................................................... 4 2 Choosing the optimal platform........................................................................................... 4 2.1 Choice of hardware platform....................................................................................... 4 2.2 Choice of microprocessor ........................................................................................... 6 2.3 Choice of operating system......................................................................................... 6 2.4 Choice of programming language ............................................................................... 7 2.5 Choice of compiler ...................................................................................................... 9 2.6 Choice of function libraries........................................................................................ 11 2.7 Choice of user interface framework........................................................................... 13 2.8 Overcoming the drawbacks of the C++ language...................................................... 14 3 Finding -

Benjamin Eugene Key's Resume
Benjamin Eugene Key's Resume Benjamin Eugene Key 12343 Hunters Chase Dr. Apt 826 Austin, Texas 78729-7217 Home: (512) 250-2239 Mobile: (512) 773-0652 E-Mail: [email protected] Summary A dedicated, self-motivated, and self-taught Software Engineer with demonstrated suc cess in the design and development of Assistive Technology applications for Microsoft Windows operating systems. Sixteen years of experience in developing software using C++ and a deep understanding of using object-oriented design principles. Proven problem-solving skills. Proven ability to acquire knowledge about new concepts independently in a short amount of time. Qualifications Programming Languages • C++17 • C++14 • C++11 • C++ • C# • Python • JAWS Scripting Language 1 Markup Languages • HTML 5 • HTML 4 • CSS • Markdown APIs, Frameworks, and Libraries • Win32 API (Windows Application Programming Interface) • STL (Standard Template Library) • MFC (Microsoft Foundation Class Library) • ATL (Active Template Library) • WTL (Windows Template Library) • Boost C++ Libraries • COM (Component Object Model) • MSAA (Microsoft Active Accessibility) • Microsoft SAPI (Speech Application Programming Interface) 4 • Microsoft SAPI 5 • Microsoft Speech Platform 11 • Vocalizer Expressive by Nuance Applications • Microsoft Visual Studio 2017 • Microsoft Visual Studio 2015 • Microsoft Visual Studio 2013 • Microsoft Visual Studio 2010 • Microsoft Visual Studio 2005 • Microsoft Visual Studio 2003 • Microsoft Visual C++ 6 • Microsoft Embedded Visual C++ 4.0 • Perforce • BugZilla • Defect -

Windows® Embedded CE 6.0 Fundamentals
Windows® Embedded CE 6.0 Fundamentals Stanislav Pavlov Pavel Belevsky Chapter 9 Application Development This chapter covers the differences between native and managed code, choosing when to create an operating system (OS) design subproject or a separately developed project, how to prepare for application development, making device connections, and application debugging approaches . For detailed information about native code application development for Windows Embedded CE, see Douglas Boling’s book, “Programming Windows Embedded CE 6 .0 Developer Reference, 4th Edition,” and for more information about managed code application development, see the book of Andy Wigley, Daniel Moth, and Peter Foot, “Microsoft Mobile Development Handbook ”. Alternatively, you can use the MSDN Web site to find documentation, code samples, articles, virtual labs, and Web casts . You can build applications for Windows Embedded CE by using native code or managed code . Native code applications can be built as subprojects of the OS design, or as individual projects . When building projects by using native code separately from the OS design, the first step is to build an OS design, and later build applications for it . After that, an SDK should be created and installed with the development tools . Managed code applications can be built only as separate applications . However, as opposed to native code applications, managed code applications actually do not require an SDK to be installed with the development tools, and instead require the execution environment of the device . Native Code and Managed Code Native (unmanaged) code is code written in C/C++ or ASM and compiled on a development workstation to produce binary code that is native to the device processor . -

Bigfix Lifecycle Starter Kit Open Source Licenses and Notices
---------------------------------- BigFix Lifecycle StarterKit 10.0 Jan 2021 ---------------------------------- ------------------------------------------------------------------------- ------------------------------------------------------------------------- The HCL license agreement and any applicable information on the web download page for HCL products refers Licensee to this file for details concerning notices applicable to code included in the products listed above ("the Program"). Notwithstanding the terms and conditions of any other agreement Licensee may have with HCL or any of its related or affiliated entities (collectively "HCL"), the third party code identified below is subject to the terms and conditions of the HCL license agreement for the Program and not the license terms that may be contained in the notices below. The notices are provided for informational purposes. Please note: This Notices file may identify information that is not used by, or that was not shipped with, the Program as Licensee installed it. IMPORTANT: HCL does not represent or warrant that the information in this NOTICES file is accurate. Third party websites are independent of HCL and HCL does not represent or warrant that the information on any third party website referenced in this NOTICES file is accurate. HCL disclaims any and all liability for errors and omissions or for any damages accruing from the use of this NOTICES file or its contents, including without limitation URLs or references to any third party websites. ------------------------------------------------------------------------- -

Signalr Blueprints
SignalR Blueprints Build real-time ASP.NET web applications with SignalR and create various interesting projects to improve your user experience Einar Ingebrigtsen BIRMINGHAM - MUMBAI SignalR Blueprints Copyright © 2015 Packt Publishing All rights reserved. No part of this book may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, without the prior written permission of the publisher, except in the case of brief quotations embedded in critical articles or reviews. Every effort has been made in the preparation of this book to ensure the accuracy of the information presented. However, the information contained in this book is sold without warranty, either express or implied. Neither the author, nor Packt Publishing, and its dealers and distributors will be held liable for any damages caused or alleged to be caused directly or indirectly by this book. Packt Publishing has endeavored to provide trademark information about all of the companies and products mentioned in this book by the appropriate use of capitals. However, Packt Publishing cannot guarantee the accuracy of this information. First published: February 2015 Production reference: 1200215 Published by Packt Publishing Ltd. Livery Place 35 Livery Street Birmingham B3 2PB, UK. ISBN 978-1-78398-312-4 www.packtpub.com Credits Author Project Coordinator Einar Ingebrigtsen Purav Motiwalla Reviewers Proofreaders Dejan Caric Stephen Copestake Anup Hariharan Nair Faye Coulman Michael Smith Maria Gould Commissioning Editor Indexer Usha Iyer Tejal Soni Acquisition Editors Production Coordinator Richard Harvey Aparna Bhagat James Jones Cover Work Content Development Editor Aparna Bhagat Sumeet Sawant Technical Editor Shashank Desai Copy Editors Janbal Dharmaraj Relin Hedly About the Author Einar Ingebrigtsen has been working professionally with software since 1994, ranging from games development on platforms such as the PlayStation, Xbox, and PC to the enterprise line of business application development since 2002.