2.5 | Four Types of Biological Molecules
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Glossary - Cellbiology
1 Glossary - Cellbiology Blotting: (Blot Analysis) Widely used biochemical technique for detecting the presence of specific macromolecules (proteins, mRNAs, or DNA sequences) in a mixture. A sample first is separated on an agarose or polyacrylamide gel usually under denaturing conditions; the separated components are transferred (blotting) to a nitrocellulose sheet, which is exposed to a radiolabeled molecule that specifically binds to the macromolecule of interest, and then subjected to autoradiography. Northern B.: mRNAs are detected with a complementary DNA; Southern B.: DNA restriction fragments are detected with complementary nucleotide sequences; Western B.: Proteins are detected by specific antibodies. Cell: The fundamental unit of living organisms. Cells are bounded by a lipid-containing plasma membrane, containing the central nucleus, and the cytoplasm. Cells are generally capable of independent reproduction. More complex cells like Eukaryotes have various compartments (organelles) where special tasks essential for the survival of the cell take place. Cytoplasm: Viscous contents of a cell that are contained within the plasma membrane but, in eukaryotic cells, outside the nucleus. The part of the cytoplasm not contained in any organelle is called the Cytosol. Cytoskeleton: (Gk. ) Three dimensional network of fibrous elements, allowing precisely regulated movements of cell parts, transport organelles, and help to maintain a cell’s shape. • Actin filament: (Microfilaments) Ubiquitous eukaryotic cytoskeletal proteins (one end is attached to the cell-cortex) of two “twisted“ actin monomers; are important in the structural support and movement of cells. Each actin filament (F-actin) consists of two strands of globular subunits (G-Actin) wrapped around each other to form a polarized unit (high ionic cytoplasm lead to the formation of AF, whereas low ion-concentration disassembles AF). -
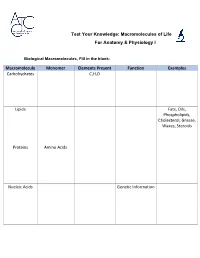
Macromolecules of Life Worksheet
Test Your Knowledge: Macromolecules of Life For Anatomy & Physiology I Biological Macromolecules, Fill in the blank: Macromolecule Monomer Elements Present Function Examples Carbohydrates C,H,O Lipids Fats, Oils, Phospholipids, Cholesterol, Grease, Waxes, Steroids Proteins Amino Acids Nucleic Acids Genetic Information Carbohydrates are classified by __________. The most common simple sugars are glucose, galactose and fructose that are made of a single sugar molecule. These can be classified as __________. Sucrose and __________ are classified as disaccharides; they are made of two monosaccharides joined by a dehydration reaction. The most complex carbohydrates are starch, __________ and cellulose, classified as __________. Lipids most abundant form are __________. Triglycerides building blocks are 1 __________ and 3 __________ per molecule. If a triglyceride only contains __________ bonds that contain the maximum number of __________, then it is classified as a saturated fat. If a triglyceride contains one or more __________ bonds, then it is classified as an unsaturated fat. Lipids are also responsible for a major component of the cell membrane wall that is both attracted to and repelled by water, called __________. The tail of this structure is made of 2 __________, that are water insoluble (hydrophobic). The head of this structure is made of a single __________, that is water soluble (hydrophilic). Proteins building blocks are amino acids that are held together with __________ bonds. These are covalent bonds that link the amino end of one amino acid with the carboxyl end of another. Their overall shape determines their __________. The complex 3D shape of a protein is called a __________. -

Molecular Biology and Applied Genetics
MOLECULAR BIOLOGY AND APPLIED GENETICS FOR Medical Laboratory Technology Students Upgraded Lecture Note Series Mohammed Awole Adem Jimma University MOLECULAR BIOLOGY AND APPLIED GENETICS For Medical Laboratory Technician Students Lecture Note Series Mohammed Awole Adem Upgraded - 2006 In collaboration with The Carter Center (EPHTI) and The Federal Democratic Republic of Ethiopia Ministry of Education and Ministry of Health Jimma University PREFACE The problem faced today in the learning and teaching of Applied Genetics and Molecular Biology for laboratory technologists in universities, colleges andhealth institutions primarily from the unavailability of textbooks that focus on the needs of Ethiopian students. This lecture note has been prepared with the primary aim of alleviating the problems encountered in the teaching of Medical Applied Genetics and Molecular Biology course and in minimizing discrepancies prevailing among the different teaching and training health institutions. It can also be used in teaching any introductory course on medical Applied Genetics and Molecular Biology and as a reference material. This lecture note is specifically designed for medical laboratory technologists, and includes only those areas of molecular cell biology and Applied Genetics relevant to degree-level understanding of modern laboratory technology. Since genetics is prerequisite course to molecular biology, the lecture note starts with Genetics i followed by Molecular Biology. It provides students with molecular background to enable them to understand and critically analyze recent advances in laboratory sciences. Finally, it contains a glossary, which summarizes important terminologies used in the text. Each chapter begins by specific learning objectives and at the end of each chapter review questions are also included. -

Physiology, Biochemistry, and Pharmacology of Transporters for Organic Cations
International Journal of Molecular Sciences Editorial Physiology, Biochemistry, and Pharmacology of Transporters for Organic Cations Giuliano Ciarimboli Experimental Nephrology, Department of Internal Medicine D, University Hospital Münster, 48149 Münster, Germany; [email protected] This editorial summarizes the 13 scientific papers published in the Special Issue “Physiology, Biochemistry, and Pharmacology of Transporters for Organic Cations” of the International Journal of Molecular Sciences. In this Special Issue, the readers will find integrative information on transporters for organic cations. Besides reviews on physi- ology, pharmacology, and toxicology of these transporters [1–3], which offer a concise overview of the field, the readers will find original research work focusing on specific transporter aspects. Specifically, the review “Organic Cation Transporters in Human Physiology, Phar- macology, and Toxicology” by Samodelov et al. [1] summarizes well the general as- pects of physiology, pharmacology, and toxicology of transporter for organic cations. The other review “Organic Cation Transporters in the Lung—Current and Emerging (Patho)Physiological and Pharmacological Concepts” by Ali Selo et al. [2] focuses on these aspects of transporters for organic cations in the lung, an important but often ne- glected field. In the paper “Systems Biology Analysis Reveals Eight SLC22 Transporter Subgroups, Including OATs, OCTs, and OCTNs”, by performing a system biology analysis of SLC22 transporters, Engelhart et al. [4] suggest the existence of a transporter–metabolite network. They propose that, in this network, mono-, oligo-, and multi-specific SLC22 transporters Citation: Ciarimboli, G. Physiology, interact to regulate concentrations and fluxes of many metabolites and signaling molecules. Biochemistry, and Pharmacology of In particular, the organic cation transporters (OCT) subgroup seems to be associated with Transporters for Organic Cations. -

BIOCHEMISTRY MAJOR the Biochemistry Major Is Offered Through the Department of Chemistry
BIOCHEMISTRY MAJOR The Biochemistry major is offered through the Department of Chemistry. This sequence is recommended for students planning entry into graduate school in Biochemistry, Pharmacology, or related subjects. It is also strongly recommend for those desiring to pursue medical or dental school. NOTE: This course sequence may be modified to include a Senior Capstone Experience. FIRST YEAR Fall Semester Credits Spring Semester Credits General Chemistry I for Majors (CHE111) 3 General Chemistry II for Majors (CHE112) 3 General Chemistry I Lab for Majors (CHE111L) 1 General Chemistry II Lab for Majors (CHE112L) 1 General Chemistry I Récitation (CHE111R) 0 General Chemistry II Récitation (CHE112R) 0 Precalculus (MAT116 or MAT120) 3-4 Calculus I (MAT231) 4 First Year Composition (ENG103) 4 Foreign Language (FL201) 4 African Diaspora/World I (ADW111) 4 African Diaspora/World II (ADW112) 4 First Year Experience (FYE 101-Chemistry) 1 First Year Experience (FYE 102-Chemistry) 1 First Year Seminar in Chemistry (CHE101) 0 Big Questions Colloquia (BQC) 1 TOTAL HOURS 16-17 TOTAL HOURS 18 SOPHOMORE YEAR Fall Semester Credits Spring Semester Credits Organic Chemistry I for Majors (CHE231) 4 Organic Chemistry II for Majors (CHE232) 4 Organic Chemistry I Lab (CHE233L) 1 Organic Chemistry II Lab (CHE234L) 1 Organic Chemistry I Récitation (CHE233R) 0 Organic Chemistry II Récitation (CHE234R) 0 Biology of the Cell (BIO120) 4 Organismal Form and Function(BIO115) 4 Calculus II (MAT 232) 4 Physics I: Mechanics & Lab (PHY151) 4 Foreign Language (FL202) -

The Structure and Function of Large Biological Molecules 5
The Structure and Function of Large Biological Molecules 5 Figure 5.1 Why is the structure of a protein important for its function? KEY CONCEPTS The Molecules of Life Given the rich complexity of life on Earth, it might surprise you that the most 5.1 Macromolecules are polymers, built from monomers important large molecules found in all living things—from bacteria to elephants— can be sorted into just four main classes: carbohydrates, lipids, proteins, and nucleic 5.2 Carbohydrates serve as fuel acids. On the molecular scale, members of three of these classes—carbohydrates, and building material proteins, and nucleic acids—are huge and are therefore called macromolecules. 5.3 Lipids are a diverse group of For example, a protein may consist of thousands of atoms that form a molecular hydrophobic molecules colossus with a mass well over 100,000 daltons. Considering the size and complexity 5.4 Proteins include a diversity of of macromolecules, it is noteworthy that biochemists have determined the detailed structures, resulting in a wide structure of so many of them. The image in Figure 5.1 is a molecular model of a range of functions protein called alcohol dehydrogenase, which breaks down alcohol in the body. 5.5 Nucleic acids store, transmit, The architecture of a large biological molecule plays an essential role in its and help express hereditary function. Like water and simple organic molecules, large biological molecules information exhibit unique emergent properties arising from the orderly arrangement of their 5.6 Genomics and proteomics have atoms. In this chapter, we’ll first consider how macromolecules are built. -

Biochemistry and Molecular Biology
School of Life Sciences / Department of Biochemistry and Biophysics BIOCHEMISTRY AND MOLECULAR BIOLOGY Revealing how life works Department of Biochemistry and Biophysics Oregon State University 2011 Agriculture and Life Sciences Building Corvallis, OR 97331 OSUBB 541-737-4511 biochem.oregonstate.edu College of Science Oregon State University 128 Kidder Hall Corvallis, OR 97331 541-737-4811 science.oregonstate.edu This publication will be made available in an accessible alternative format upon request. Please contact the College COLLEGE OF SCIENCE of Science at 541-737-4811 or [email protected]. ACADEMIC BROCHURE / 2020 Highlights • Solve problems at the What will you discover? intersection of biological and physical sciences with our The Department of Biochemistry and Biophysics offers nationally accredited program world-class faculty, a tradition of interdisciplinary in biochemistry, molecular and research, teaching excellence and extraordinary cellular biology, chemistry, laboratories to facilitate undergraduate learning. molecular genetics, physics and statistics. The department ranks high nationally and internationally in many research areas, including signal transduction, gene • Tailor your education to expression, epigenetics, metabolic regulation, structural specific career goals with three biology, and genetic code expansion technology. different options. The department offers two Bachelor of Science degrees, • Thrive in a smaller, supportive both accredited by the American Society for Biochemistry department within a world-class and Molecular Biology (ASBMB): research university. • Biochemistry and Molecular Biology (BMB) with • Pursue interdisciplinary research options in Advanced Molecular Biology, Computational projects with faculty across OSU. Molecular Biology, and Pre-medicine; • Participate in the Biochemistry • Biochemistry and Biophysics (BB) with options in Club for community, leadership Advanced Biophysics, Neuroscience, and Pre-medicine. -

And Even-Length, Medium-Chain Fatty Acids in Plants (Amino Adds/Elongtin) ANTOANETA B
Proc. Nadl. Acad. Sci. USA Vol. 91, pp. 11437-11441, November 1994 Biochemistry A pathway for the biosynthesis of straight and branched, odd- and even-length, medium-chain fatty acids in plants (amino adds/elongtin) ANTOANETA B. KROUMOVA, ZHIYI XIE, AND GEORGE J. WAGNER* Plant Physiology/Biochemistry/Molecular Biology Program, Agronomy Department, University of Kentucky, Lexington, KY 40546-0091 Communicated by Martin Gibbs, July 25, 1994 ABSTRACT Pathways and enzymes offatty acid synthase- and even-length scFAs are synthesized via modified mediated, long-even-chain (generally C16-C20) fatty add syn- branched-chain amino acid (bcAA) metabolism in tobacco thesis are well studied, and general metabolism involved in trichome glands (6, 7). It is possible that at least branched and short-chain (Cs-C7) fatty acid biosynthesis is also understood. odd-length mcFAs are formed in this tissue similarly. Alter- In contrast, mechanism of medinm-chain (C#-C14) fatty acid natively, primers derived from bcAA metabolism may be synthesis are unclear. Recent work suggests involvement of elongated by fatty acid synthase (FAS), as suggested for chain-elongation-terminating thloesterases in medium-chain tomato trichomes (8) and tobacco epidermis (9). fatty acid formation in oilseeds and animals. We have shown The classical pathway for bcAA (Val, Leu, Ileu) biosyn- that iso- and anteiso-branched and straigbt, odd- and even- thesis in microorganisms (and largely by inference in plants, length, short-chain fatty adds esterifled in plant-trichome- ref. 10) is shown in the shaded areas of Fig. 1. Key activities gland-produced sucrose esters are synthesized by using carbon involved in branched-chain formation (reactions 1, 1A, and 2) skeletons provided by modified branched-chain amino acid are those catalyzing leucine biosynthesis in all organisms and metabolism/catablis. -

Biochemistry Major University of Michigan - Department of Chemistry Effective 9/2017 ______
Biochemistry Major University of Michigan - Department of Chemistry Effective 9/2017 _____________________________________________________________________________________________ Biochemistry is, literally the chemistry of life. Biochemists seek to understand the chemical principles that underpin all living organisms. Biochemistry is central to medical science as almost all diseases and drugs act to change the body’s chemistry. Advances in biochemistry directly impact the fields of biotechnology, pharmaceutical science, agriculture and environmental science, among many others. The B.S. major in Biochemistry is for those are interested in learning about life from a chemical perspective. Students will be well equipped for graduate studies in biochemistry, chemical biology, and many other fields of inquiry in the life sciences. The degree will also provide excellent preparation for students intending to pursue professional careers in industry and medicine. Prerequisites Course # Course Description Term Term Credits Completed Typically Offered CHEM 210 Structure and Reactivity I F, W, Sp 4 CHEM 211 Investigations in Chemistry: Laboratory F, W, Sp 1 CHEM 215 Structure and Reactivity II F, W, Sp 3 BIO 171 Introductory Biology: Ecology and Evolution F, W, Sp, Su 4 BIO 172 Introductory Biology: Molecular Cellular and Developmental F, W, Sp 4 MATH 115 Calculus I F, W, Sp, Su 4 MATH 116 Calculus II F, W, Sp, Su 4 One of the Following: CHEM 262 Mathematical Methods for Chemists F, W 4 OR MATH 215 Calculus III F, W, Sp, Su 4 One of the Following -

Chapter 2 Introduction to Some Basic Features of Genetic Information
Chapter 2 Introduction to some basic features of genetic information: From DNA to proteins 1 1, 2 1, 3 DAVID QUIST, KAARE M. NIELSEN AND TERJE TRAAVIK 1 THE NORWEGIAN INSTITUTE OF GENE ECOLOGY (GENØK), TROMSØ, NORWAY 2 DEPARTMENT OF PHARMACY, UNIVERSITY OF TROMSØ, NORWAY 3 DEPARTMENT OF MICROBIOLOGY AND VIROLOGY, UNIVERSITY OF TROMSØ, NORWAY Molecular biology is the study of biology at a molecular level, with the aim of understanding the interactions between the various systems of a cell, including the interrelationship and regulation of DNA, RNA and protein synthesis. In general terms, DNA (deoxyribonucleic acid) is the basic genetic information macromolecule of the cell. It provides the rudimentary instructions for all kinds of biochemical functions, from making proteins to regulatory functions. DNA is found in every cell and every cell type and organism, from single-celled organisms (prokaryotes, e.g. bacteria), to larger multicellular organisms (eukaryotes, e.g. seaweeds, fungi, plant, animals) that can have many different cell and tissue types.1 DNA contains the genetic ‘code’ of information that makes each species unique. Smaller variations in the DNA can lead to minor differences among individuals of the same species. The combination of specific DNA composition, epigenetic changes (see Chapter 8) and environmental influences determine an organism’s appearance and development. In this book, we discuss how the main carrier of heritable information (DNA) and the environment interact, with particular emphasis on how genetic engineering may intentionally or unintentionally affect this interaction. This chapter focuses on DNA, RNA and the concept of genes. It is structured as follows: 1. -

Biochemistry and Molecular Biology (BMB) 1
Biochemistry and Molecular Biology (BMB) 1 BMB 372. Advanced Molecular Biology. (3 h) BIOCHEMISTRY AND Presents molecular mechanisms by which stored genetic information is expressed including the mechanisms for and regulation of gene MOLECULAR BIOLOGY (BMB) expression, protein synthesis, and genome editing. Emphasizes analysis and interpretation of experimental data from the primary literature. Also Interdisciplinary Major listed as BIO 372. P-BIO 213 and 214 and BIO 370/BMB 370/CHM 370 or BIO 265 and BIO 370/BMB 370/CHM 370. This interdisciplinary Bachelor of Science major, jointly offered by the Departments of Biology and Chemistry, provides a strong foundation BMB 372L. Advanced Molecular Biology Laboratory. (1.5 h) in biological chemistry and molecular biology, and related topics at Introduces modern methods of molecular biology to analyze and the interface of these two disciplines. The major is designed to build manipulate expression of genes and function of gene products. Also conceptual understanding and practical and critical thinking skills to listed as BIO 372L. P or C-BIO 372/CHM 372 or BMB 373/CHM 373. address current biological, biochemical, and biomedical challenges. A BMB 373. Biochemistry II. (3 h) required research experience spanning multiple semesters, culminating Examines the structure, function, and synthesis of proteins and nucleic in a senior project, will give students strong experimental skills and acids and includes advanced topics in biochemistry including catalytic provide insight into biochemical and molecular biological experimental mechanisms of enzymes and ribozymes, use of sequence and structure approaches and results that demonstrate the function of biological databases, and molecular basis of disease and drug action. -

Biochemistry Metabolism
Biochemistry Metabolism 07.11.2017 – 27.11.2017 Photosynthesis Gerhild van Echten-Deckert Tel. 73 2703 E-mail: [email protected] www.limes-institut-bonn.de Photosynthesis Light reaction: - Light absorption, generation of a high energy electron and oxidation of water - Electron transport from water to NADPH and generation of a proton-motive force -Synthesis of ATP Berg, Tymoczko, Stryer: Biochemistry “Dark reaction”: - CO2 conversion into carbohydrates consuming ATP and NADPH (Calvin Cycle) Photosynthesis is localized to the thylakoid membranes Lodish et al. Molecular Cell Biology Comparison of photosynthesis and oxidative phosphorylation Berg, Tymoczko, Stryer: Biochemistry Chlorophyll a is the main pigment capturing energy of light Lodish et al. Molecular Cell Biology Energy diagram indicating the electronic states of chlorophyll and their most important modes of interconversion Other light-absorbing pigments, such as carotenoids, extend the range of light that can be absorbed and used for photosynthesis The action spectrum of photosynthesis matches the absorption spectra of chlorophyll a and b and of -carotene The absorption of photons from two distinct photosystems (PSI and PSII + is required for complete electron flow from H2O to NADP Berg, Tymoczko, Stryer: Biochemistry Light absorption by reaction-centre chlorophylls causes a charge separation across the thylakoid membrane The energy of the absorbed light is used to strip an electron from a chlorophyll molecule of the reaction centre to a primary electron acceptor thereby acquiring a positive charge (generation of a strong oxidizing- and a strong reducing agent) Lodish et al. Molecular Cell Biology Subsequent electron flow and coupled proton movement Lodish et al.