The Structure and Function of Large Biological Molecules 5
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Glossary - Cellbiology
1 Glossary - Cellbiology Blotting: (Blot Analysis) Widely used biochemical technique for detecting the presence of specific macromolecules (proteins, mRNAs, or DNA sequences) in a mixture. A sample first is separated on an agarose or polyacrylamide gel usually under denaturing conditions; the separated components are transferred (blotting) to a nitrocellulose sheet, which is exposed to a radiolabeled molecule that specifically binds to the macromolecule of interest, and then subjected to autoradiography. Northern B.: mRNAs are detected with a complementary DNA; Southern B.: DNA restriction fragments are detected with complementary nucleotide sequences; Western B.: Proteins are detected by specific antibodies. Cell: The fundamental unit of living organisms. Cells are bounded by a lipid-containing plasma membrane, containing the central nucleus, and the cytoplasm. Cells are generally capable of independent reproduction. More complex cells like Eukaryotes have various compartments (organelles) where special tasks essential for the survival of the cell take place. Cytoplasm: Viscous contents of a cell that are contained within the plasma membrane but, in eukaryotic cells, outside the nucleus. The part of the cytoplasm not contained in any organelle is called the Cytosol. Cytoskeleton: (Gk. ) Three dimensional network of fibrous elements, allowing precisely regulated movements of cell parts, transport organelles, and help to maintain a cell’s shape. • Actin filament: (Microfilaments) Ubiquitous eukaryotic cytoskeletal proteins (one end is attached to the cell-cortex) of two “twisted“ actin monomers; are important in the structural support and movement of cells. Each actin filament (F-actin) consists of two strands of globular subunits (G-Actin) wrapped around each other to form a polarized unit (high ionic cytoplasm lead to the formation of AF, whereas low ion-concentration disassembles AF). -
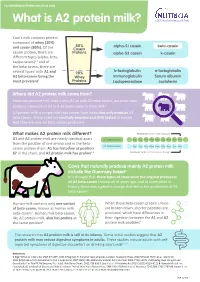
What Is A2 Protein Milk?
For Healthcare Professional use only What is A2 protein milk? Cow’s milk contains protein composed of whey (20%) 80% alpha-S1 casein beta-casein and casein (80%). Of the Casein casein protein, there are Proteins alpha-S2 casein k-casein different types (alpha, beta, kappa casein)1,2 and of the beta-casein, there are b-lactoglobulin a-lactoglobulin several types’ with A1 and 20% A2 beta-casein being the Whey Immunoglobulin Serum albumin most prevalent3 Proteins Lactoperoxidase Lactoferrin Where did A2 protein milk come from? Cows can produce milk that is only A1 or only A2 beta-casein, but most cows produce a mixture of A1 and A2 beta-casein in their milk4 A2 protein milk is simply milk that comes from cows that only produce A2 beta-casein. These cows are carefully selected and DNA tested to ensure that they are only A2 beta-casein producers What makes A2 protein milk different? Position 67(proline hinders cleavage) A1 and A2 protein milk are nearly identical apart A2 beta-casein Val Tyr Pro Phe Pro Gly Pro Iie Pro from the position of one amino acid in the beta- A1 beta-casein casein protein chain: A1 has histadine at position Val Tyr Pro Phe Pro Gly Pro Iie His 67 in the chain, and A2 protein milk has proline4,5 Position 67(histidine readily allows cleavage) Cows that naturally produce mainly A2 protein milk include the Guernsey breed4 It is thought that these types of cows were the original producers of A2 beta-casein thousands of years ago, and at some point in history there was a genetic change that led to the production of A1 beta-casein6 Human milk contains only one variant When these beta-casein protein chains of beta-casein, known as human milk are broken down, shorter peptides are beta-casein7. -

Protein Structure & Folding
6 Protein Structure & Folding To understand protein folding In the last chapter we learned that proteins are composed of amino acids Goal as a chemical equilibrium. linked together by peptide bonds. We also learned that the twenty amino acids display a wide range of chemical properties. In this chapter we will see Objectives that how a protein folds is determined by its amino acid sequence and that the three-dimensional shape of a folded protein determines its function by After this chapter, you should be able to: the way it positions these amino acids. Finally, we will see that proteins fold • describe the four levels of protein because doing so minimizes Gibbs free energy and that this minimization structure and the thermodynamic involves both making the most favorable bonds and maximizing disorder. forces that stabilize them. • explain how entropy (S) and enthalpy Proteins exhibit four levels of structure (H) contribute to Gibbs free energy. • use the equation ΔG = ΔH – TΔS The structure of proteins can be broken down into four levels of to determine the dependence of organization. The first is primary structure, the linear sequence of amino the favorability of a reaction on acids in the polypeptide chain. By convention, the primary sequence is temperature. written in order from the amino acid at the N-terminus (by convention • explain the hydrophobic effect and its usually on the left) to the amino acid at the C-terminus. The second level role in protein folding. of protein structure, secondary structure, is the local conformation adopted by stretches of contiguous amino acids. -

Casein Proteins As a Vehicle to Deliver Vitamin D3
Casein Proteins as a Vehicle to Deliver Vitamin D3: Fortification of Dairy Products with vitamin D3 and Bioavailability of Vitamin D3 from Fortified Mozzarella Cheese Baked with Pizza by Banaz Al-khalidi A thesis submitted in conformity with the requirements for the degree of Master of Science Graduate Department of Nutritional Sciences University of Toronto © Copyright by Banaz Al-khalidi (2012) Casein proteins as a vehicle to deliver vitamin D3: Fortification of dairy products with vitamin D3 and Bioavailability of vitamin D3 from fortified Mozzarella cheese baked with pizza Banaz Al-khalidi Master of Science Department of Nutritional Sciences, Faculty of Medicine University of Toronto 2012 ABSTRACT Current vitamin D intakes in Canada are inadequate. The extension of vitamin D fortification to additional foods may be an effective and appropriate strategy for increasing vitamin D intakes in the general population. Cheese is potentially an ideal candidate for vitamin D fortification. We introduce the potential use of casein proteins as a vehicle for vitamin D3 fortification in industrially made cheeses where we found that over 90% of vitamin D3 added to milk was retained in both Cheddar and Mozzarella cheeses. Use of casein proteins for vitamin D3 fortification did not fully prevent vitamin D3 loss into whey. However the loss was minimized to approximately 8%. We then show that vitamin D3 is bioavailable from fortified Mozzarella cheese baked with pizza suggesting that the high temperature baking process does not significantly breakdown vitamin D3. Our findings could have important implications in increasing fortified food options for Canadians. ii TABLE OF CONTENTS ABSTRACT .................................................................................................................................. -

DNA Glycosylase Exercise - Levels 1 & 2: Answer Key
Name________________________ StarBiochem DNA Glycosylase Exercise - Levels 1 & 2: Answer Key Background In this exercise, you will explore the structure of a DNA repair protein found in most species, including bacteria. DNA repair proteins move along DNA strands, checking for mistakes or damage. DNA glycosylases, a specific type of DNA repair protein, recognize DNA bases that have been chemically altered and remove them, leaving a site in the DNA without a base. Other proteins then come along to fill in the missing DNA base. Learning objectives We will explore the relationship between a protein’s structure and its function in a human DNA glycosylase called human 8-oxoguanine glycosylase (hOGG1). Getting started We will begin this exercise by exploring the structure of hOGG1 using a molecular 3-D viewer called StarBiochem. In this particular structure, the repair protein is bound to a segment of DNA that has been damaged. We will first focus on the structure hOGG1 and then on how this protein interacts with DNA to repair a damaged DNA base. • To begin using StarBiochem, please navigate to: http://mit.edu/star/biochem/. • Click on the Start button Click on the Start button for StarBiochem. • Click Trust when a prompt appears asking if you trust the certificate. • In the top menu, click on Samples à Select from Samples. Within the Amino Acid/Proteins à Protein tab, select “DNA glycosylase hOGG1 w/ DNA – H. sapiens (1EBM)”. “1EBM” is the four character unique ID for this structure. Take a moment to look at the structure from various angles by rotating and zooming on the structure. -

Quantitation of Relative Mobilities of Serum Transferrin in Quarter Horses and Thoroughbreds Using Crossed Immunoelectrophoresis
QUANTITATION OF RELATIVE MOBILITIES OF SERUM TRANSFERRIN IN QUARTER HORSES AND THOROUGHBREDS USING CROSSED IMMUNOELECTROPHORESIS BY RUTH GREER KAGEN II Bachelor of Science in Biology East Central Oklahoma State University Ada. Oklahoma 1982 Submitted to the Faculty of the Graduate College of the Oklahoma State University in partial fulfillment of requirements for the degree of MASTERS OF SCIENCE December. 1985 4 ' ;_ '" SERUM TRANSFERRIN IN QUARTER HORSES AND THOROUGHBREDS USING CROSSED IMMUNOELECTROPHORESIS Thesis Approved ii 1236431 ~ ACKNOWLEDGEMENTS The author wishes to express sincere gratitude to Dr. T. E. Staley for serving as the principle advisor and for providing the facilities and financial support necessary to carry out this work. I am most in debted to Dr. Staley for his continued faith in my work. his constant support and patient advice. and for his attentive and meticulous instruc tion as well as superb organization--all without which this study would not have been possible. I also wish to thank the members of the committee: Dr. C. L. Ownby and Dr. L. G. Stratton. I wish to extend my sincere thanks to Dr. C. L. Ownby for her continued interest in my career and her invaluable advice. both which greatly assisted me in the endeavors to carry out this work. I am very grateful for all the time which Dr. Ownby has afforded me and for her objective and sincere counsel. I am most appreciative of Dr. L. G. Stratton's interest in this project. Through his generous support and concern. we were provided with Pxcellent facilities in which to carry out this work and we were also provided with access to the animals needed for this project. -

Wilson Disease
Wilson Disease What is Wilson disease? Wilson disease is a hereditary disease in which excessive amounts of copper accumulate in the body, mainly in the liver. The disease affects approximately one in every 30,000 Canadians. Small amounts of copper are essential to good health. One of the liver’s jobs is to maintain the balance of copper in the body. The liver is also the main organ to store copper. In Wilson disease, when its storage capacity is full, copper is released into the blood stream. It then accumulates in various organs such as the brain and the cornea of the eye. This copper overload damages these organs. Left untreated, Wilson disease can be fatal. What causes the disease? Wilson disease is inherited. In order to have the disease, a person must get two defective genes, one from each parent. The liver begins to retain copper at birth and it may take years before symptoms manifest themselves. Having only one defective gene does not lead to Wilson disease. What are the symptoms of Wilson disease? Wilson disease is sometimes difficult to diagnose. Affected individuals may have no symptoms for years. When symptoms develop, they can be subtle. Sometimes symptoms of Wilson disease resemble hepatitis. Alternatively, some individuals have an enlarged liver and spleen and liver test abnormalities. Copper accumulation in the brain can present itself in two ways: (1) as physical symptoms such as slurred speech, failing voice, drooling, tremors or difficulty in swallowing or (2) as psychiatric disorders such as depression, manic behaviour or suicidal impulses. Very rarely, Wilson disease may cause the liver to fail. -

Unit 2 Cell Biology Page 1 Sub-Topics Include
Sub-Topics Include: 2.1 Cell structure 2.2 Transport across cell membranes 2.3 Producing new cells 2.4 DNA and the production of proteins 2.5 Proteins and enzymes 2.6 Genetic Engineering 2.7 Respiration 2.8 Photosynthesis Unit 2 Cell Biology Page 1 UNIT 2 TOPIC 1 1. Cell Structure 1. Types of organism Animals and plants are made up of many cells and so are described as multicellular organisms. Similar cells doing the same job are grouped together to form tissues. Animals and plants have systems made up of a number of organs, each doing a particular job. For example, the circulatory system is made up of the heart, blood and vessels such as arteries, veins and capillaries. Some fungi such as yeast are single celled while others such as mushrooms and moulds are larger. Cells of animals plants and fungi have contain a number of specialised structures inside their cells. These specialised structures are called organelles. Bacteria are unicellular (exist as single cells) and do not have organelles in the same way as other cells. 2. Looking at Organelles Some organelles can be observed by staining cells and viewing them using a light microscope. Other organelles are so small that they cannot be seen using a light microscope. Instead, they are viewed using an electron microscope, which provides a far higher magnification than a light microscope. Most organelles inside cells are surrounded by a membrane which is similar in composition (make-up) to the cell membrane. Unit 2 Cell Biology Page 2 3. A Typical Cell ribosome 4. -

Chapter 23 Nucleic Acids
7-9/99 Neuman Chapter 23 Chapter 23 Nucleic Acids from Organic Chemistry by Robert C. Neuman, Jr. Professor of Chemistry, emeritus University of California, Riverside [email protected] <http://web.chem.ucsb.edu/~neuman/orgchembyneuman/> Chapter Outline of the Book ************************************************************************************** I. Foundations 1. Organic Molecules and Chemical Bonding 2. Alkanes and Cycloalkanes 3. Haloalkanes, Alcohols, Ethers, and Amines 4. Stereochemistry 5. Organic Spectrometry II. Reactions, Mechanisms, Multiple Bonds 6. Organic Reactions *(Not yet Posted) 7. Reactions of Haloalkanes, Alcohols, and Amines. Nucleophilic Substitution 8. Alkenes and Alkynes 9. Formation of Alkenes and Alkynes. Elimination Reactions 10. Alkenes and Alkynes. Addition Reactions 11. Free Radical Addition and Substitution Reactions III. Conjugation, Electronic Effects, Carbonyl Groups 12. Conjugated and Aromatic Molecules 13. Carbonyl Compounds. Ketones, Aldehydes, and Carboxylic Acids 14. Substituent Effects 15. Carbonyl Compounds. Esters, Amides, and Related Molecules IV. Carbonyl and Pericyclic Reactions and Mechanisms 16. Carbonyl Compounds. Addition and Substitution Reactions 17. Oxidation and Reduction Reactions 18. Reactions of Enolate Ions and Enols 19. Cyclization and Pericyclic Reactions *(Not yet Posted) V. Bioorganic Compounds 20. Carbohydrates 21. Lipids 22. Peptides, Proteins, and α−Amino Acids 23. Nucleic Acids ************************************************************************************** -

Proteasomes on the Chromosome Cell Research (2017) 27:602-603
602 Cell Research (2017) 27:602-603. © 2017 IBCB, SIBS, CAS All rights reserved 1001-0602/17 $ 32.00 RESEARCH HIGHLIGHT www.nature.com/cr Proteasomes on the chromosome Cell Research (2017) 27:602-603. doi:10.1038/cr.2017.28; published online 7 March 2017 Targeted proteolysis plays an this process, both in mediating homolog ligases, respectively, as RN components important role in the execution and association and in providing crossovers that impact crossover formation [5, 6]. regulation of many cellular events. that tether homologs and ensure their In the first of the two papers, Ahuja et Two recent papers in Science identify accurate segregation. Meiotic recom- al. [7] report that budding yeast pre9∆ novel roles for proteasome-mediated bination is initiated by DNA double- mutants, which lack a nonessential proteolysis in homologous chromo- strand breaks (DSBs) at many sites proteasome subunit, display defects in some pairing, recombination, and along chromosomes, and the multiple meiotic DSB repair, in chromosome segregation during meiosis. interhomolog interactions formed by pairing and synapsis, and in crossover Protein degradation by the 26S pro- DSB repair drive homolog association, formation. Similar defects are seen, teasome drives a variety of processes culminating in the end-to-end homolog but to a lesser extent, in cells treated central to the cell cycle, growth, and dif- synapsis by a protein structure called with the proteasome inhibitor MG132. ferentiation. Proteins are targeted to the the synaptonemal complex (SC) [3]. These defects all can be ascribed to proteasome by covalently ligated chains SC-associated focal protein complexes, a failure to remove nonhomologous of ubiquitin, a small (8.5 kDa) protein. -

Chapter 13 Protein Structure Learning Objectives
Chapter 13 Protein structure Learning objectives Upon completing this material you should be able to: ■ understand the principles of protein primary, secondary, tertiary, and quaternary structure; ■use the NCBI tool CN3D to view a protein structure; ■use the NCBI tool VAST to align two structures; ■explain the role of PDB including its purpose, contents, and tools; ■explain the role of structure annotation databases such as SCOP and CATH; and ■describe approaches to modeling the three-dimensional structure of proteins. Outline Overview of protein structure Principles of protein structure Protein Data Bank Protein structure prediction Intrinsically disordered proteins Protein structure and disease Overview: protein structure The three-dimensional structure of a protein determines its capacity to function. Christian Anfinsen and others denatured ribonuclease, observed rapid refolding, and demonstrated that the primary amino acid sequence determines its three-dimensional structure. We can study protein structure to understand problems such as the consequence of disease-causing mutations; the properties of ligand-binding sites; and the functions of homologs. Outline Overview of protein structure Principles of protein structure Protein Data Bank Protein structure prediction Intrinsically disordered proteins Protein structure and disease Protein primary and secondary structure Results from three secondary structure programs are shown, with their consensus. h: alpha helix; c: random coil; e: extended strand Protein tertiary and quaternary structure Quarternary structure: the four subunits of hemoglobin are shown (with an α 2β2 composition and one beta globin chain high- lighted) as well as four noncovalently attached heme groups. The peptide bond; phi and psi angles The peptide bond; phi and psi angles in DeepView Protein secondary structure Protein secondary structure is determined by the amino acid side chains. -

Course Outline for Biology Department Adeyemi College of Education
COURSE CODE: BIO 111 COURSE TITLE: Basic Principles of Biology COURSE OUTLINE Definition, brief history and importance of science Scientific method:- Identifying and defining problem. Raising question, formulating Hypotheses. Designing experiments to test hypothesis, collecting data, analyzing data, drawing interference and conclusion. Science processes/intellectual skills: (a) Basic processes: observation, Classification, measurement etc (b) Integrated processes: Science of Biology and its subdivisions: Botany, Zoology, Biochemistry, Microbiology, Ecology, Entomology, Genetics, etc. The Relevance of Biology to man: Application in conservation, agriculture, Public Health, Medical Sciences etc Relation of Biology to other science subjects Principles of classification Brief history of classification nomenclature and systematic The 5 kingdom system of classification Living and non-living things: General characteristics of living things. Differences between plants and animals. COURSE OUTLINE FOR BIOLOGY DEPARTMENT ADEYEMI COLLEGE OF EDUCATION COURSE CODE: BIO 112 COURSE TITLE: Cell Biology COURSE OUTLINE (a) A brief history of the concept of cell and cell theory. The structure of a generalized plant cell and generalized animal cell, and their comparison Protoplasm and its properties. Cytoplasmic Organelles: Definition and functions of nucleus, endoplasmic reticulum, cell membrane, mitochondria, ribosomes, Golgi, complex, plastids, lysosomes and other cell organelles. (b) Chemical constituents of cell - salts, carbohydrates, proteins, fats