SQL Cookbook Query Solutions and Techniques for All SQL Users
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Solar Moon of Intention • Noos-Letter of the Foundation for the Law of Time
Solar Moon of Intention • Noos-letter of the Foundation for the Law of Time • Issue #34 Sign up! • Unsubscribe • Change your address Trouble viewing? Click here to view online • Share! Welcome to the Solar Jaguar Moon Edition of the Noos-letter Welcome to the Solar Jaguar Moon of Intention, the ninth moon of the Planetary Service Wavespell. "Do not underestimate the power of your own clear mind thought and actions. Through the synchronic codes of the Law of Time, we are all activating the noosphere, an invisible action to pay off in the manifestation of the Rainbow Bridge." –Valum Votan We have now entered the third of seven Mystic Moons – the Moon of the Yellow Solar Seed. Yellow Solar Seed, Kin 204, is the galactic signature of the great Russian diplomat, scientist, visionary artist and peace worker, Nicholas Roerich, who shares his solar birthday (Gregorian October 9) with John Lennon. Roerich and his wife, Helena, went to Central Asia in the 1920s in search for Shambhala, the enlightened society. The Roerich's returned from their journey with the Banner of Peace, which has since been adopted by the World Thirteen Moon Calendar Change Peace Movement as one of its official standards. Song of Shambhala - by Nicholas Roerich Shambhala is the fulfillment of the prophecies of Kalachakra, the wheel of time. The Kalachakra ends in the Kali yuga, the dark age of ignorance and destruction of the Earth because humans are living in artificial time. 1987 fulfilled the cycle of prophecies of Kalachakra and Quetzalcoatl (Harmonic Convergence). 2012 signaled the closing of the cycle and the phasing out of a particular galactic beam, 5,125 years in diameter. -

Governance and Leadership
Dr. Vaishnavanghri Sevaka Das, Ph.D. Director, Bhaktivedanta College of Vedic Education Affiliated to ISKCON, Navi Mumbai 1 Governance and Leadership Governance “the action or manner of governing a state, organization, etc. for enhancing prosperity and sustenance” Leadership “the state or position of being a leader for ensuring the good Governance” 2 Four Yugas and Yuga Chakra Our Position (Fixed) Kali Yuga Dwapara Yuga 4,32,000 Years 8,64,000 Years 10% 20% 1 Yuga Chakra 43,20,000 Years 40% 30% Satya Yuga Treta Yuga 17,28,000 Years 12,96,000 Years 1000 Rotations of the Yuga Chakra = 1 Day of Brahma Ji 1000 Rotations of the Yuga Chakra = 1 Night of Brahma Ji 3 Concept of Four Quotients Spiritually Intellectually Strong Sharp Physically Mentally Fit Balanced 4 Test Your Understanding of the Four Quotients • Rakesh is getting ready for his final semester exam. Because of his night out he is weak and tensed. • Rakesh’s father Rajaram came from morning jogging with heavy sweating and comforted his son with inspirational words. • Rakesh’s mother Shanti did special prayers to Lord Ganesha for all success to her son but she is also very tensed. • Rakesh’s sister Rakhi gave best wishes to him and put a tilak. She reminded him of his strengths and also warned him of weakness of getting nervous. • Rakesh got onto his bike and started speeding towards his college. He is tensed as his thoughts were also speeding on top gear. • Rakesh stopped on the road when he saw his classmate Abhay with whom he never spoke. -
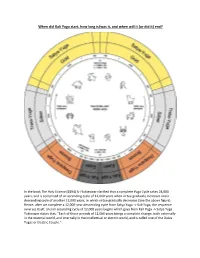
When Did Kali Yuga Start, How Long Is/Was It, and When Will It (Or Did It) End?
When did Kali Yuga start, how long is/was it, and when will it (or did it) end? In the book The Holy Science (1894) Sri Yukteswar clarified that a complete Yuga Cycle takes 24,000 years, and is comprised of an ascending cycle of 12,000 years when virtue gradually increases and a descending cycle of another 12,000 years, in which virtue gradually decreases (See the above figure). Hence, after we complete a 12,000-year descending cycle from Satya Yuga -> Kali Yuga, the sequence reverses itself, and an ascending cycle of 12,000 years begins which goes from Kali Yuga -> Satya Yuga. Yukteswar states that, “Each of these periods of 12,000 years brings a complete change, both externally in the material world, and internally in the intellectual or electric world, and is called one of the Daiva Yugas or Electric Couple.” Unfortunately, the start and end dates as well as the duration of the ages are not agreed upon, and Sri Yukteswar (who I have deep faith in) is one of many individuals that have laid out differing dates, times, and structures. “In spite of the elaborate theological framework of the Yuga Cycle, the start and end dates of the Kali Yuga remain shrouded in mystery. The popularly accepted date for the beginning of the Kali Yuga is 3102 BCE, thirty-five years after the conclusion of the battle of the Mahabharata.” This quote is taken from a well-researched article, “The End of the Kali Yuga in 2025: Unravelling the Mysteries of the Yuga Cycle in the New Dawn online magazine which can be found HERE. -

Time Structure of Universe Chart
Time Structure of Universe Chart Creation of Universe Lifespan of Universe - 1 Maha Kalpa (311.040 Trillion years, One Breath of Maha-Visnu - An Expansion of Lord Krishna) Complete destruction of Universe Age of Universe: 155.52197 Trillion years Time remaining until complete destruction of Universe: 155.51803 Trillion years At beginning of Brahma's day, all living beings become manifest from the unmanifest state (Bhagavad-Gita 8.18) 1st day of Brahma in his 51st year (current time position of Brahma) When night falls, all living beings become unmanifest 1 Kalpa (Daytime of Brahma, 12 hours)=4.32 Billion years 71 71 71 71 71 71 71 71 71 71 71 71 71 71 Chaturyugas Chaturyugas Chaturyugas Chaturyugas Chaturyugas Chaturyugas Chaturyugas Chaturyugas Chaturyugas Chaturyugas Chaturyugas Chaturyugas Chaturyugas Chaturyugas 1 Manvantara 306.72 Million years Age of current Manvantara and current Manu (Vaivasvata): 120.533 Million years Time remaining for current day of Brahma: 2.347051 Billion years Between each Manvantara there is a juncture (sandhya) of 1.728 Million years 1 Chaturyuga (4 yugas)=4.32 Million years 28th Chaturyuga of the 7th manvantara (current time position) Satya-yuga (1.728 million years) Treta-yuga (1.296 million years) Dvapara-yuga (864,000 years) Kali-yuga (432,000 years) Time remaining for Kali-yuga: 427,000 years At end of each yuga and at the start of a new yuga, there is a juncture period 5000 years (current time position in Kali-yuga) "By human calculation, a thousand ages taken together form the duration of Brahma's one day [4.32 billion years]. -

The Calendars of India
The Calendars of India By Vinod K. Mishra, Ph.D. 1 Preface. 4 1. Introduction 5 2. Basic Astronomy behind the Calendars 8 2.1 Different Kinds of Days 8 2.2 Different Kinds of Months 9 2.2.1 Synodic Month 9 2.2.2 Sidereal Month 11 2.2.3 Anomalistic Month 12 2.2.4 Draconic Month 13 2.2.5 Tropical Month 15 2.2.6 Other Lunar Periodicities 15 2.3 Different Kinds of Years 16 2.3.1 Lunar Year 17 2.3.2 Tropical Year 18 2.3.3 Siderial Year 19 2.3.4 Anomalistic Year 19 2.4 Precession of Equinoxes 19 2.5 Nutation 21 2.6 Planetary Motions 22 3. Types of Calendars 22 3.1 Lunar Calendar: Structure 23 3.2 Lunar Calendar: Example 24 3.3 Solar Calendar: Structure 26 3.4 Solar Calendar: Examples 27 3.4.1 Julian Calendar 27 3.4.2 Gregorian Calendar 28 3.4.3 Pre-Islamic Egyptian Calendar 30 3.4.4 Iranian Calendar 31 3.5 Lunisolar calendars: Structure 32 3.5.1 Method of Cycles 32 3.5.2 Improvements over Metonic Cycle 34 3.5.3 A Mathematical Model for Intercalation 34 3.5.3 Intercalation in India 35 3.6 Lunisolar Calendars: Examples 36 3.6.1 Chinese Lunisolar Year 36 3.6.2 Pre-Christian Greek Lunisolar Year 37 3.6.3 Jewish Lunisolar Year 38 3.7 Non-Astronomical Calendars 38 4. Indian Calendars 42 4.1 Traditional (Siderial Solar) 42 4.2 National Reformed (Tropical Solar) 49 4.3 The Nānakshāhī Calendar (Tropical Solar) 51 4.5 Traditional Lunisolar Year 52 4.5 Traditional Lunisolar Year (vaisnava) 58 5. -
CALENDRICAL CALCULATIONS the Ultimate Edition an Invaluable
Cambridge University Press 978-1-107-05762-3 — Calendrical Calculations 4th Edition Frontmatter More Information CALENDRICAL CALCULATIONS The Ultimate Edition An invaluable resource for working programmers, as well as a fount of useful algorithmic tools for computer scientists, astronomers, and other calendar enthu- siasts, the Ultimate Edition updates and expands the previous edition to achieve more accurate results and present new calendar variants. The book now includes algorithmic descriptions of nearly forty calendars: the Gregorian, ISO, Icelandic, Egyptian, Armenian, Julian, Coptic, Ethiopic, Akan, Islamic (arithmetic and astro- nomical forms), Saudi Arabian, Persian (arithmetic and astronomical), Bahá’í (arithmetic and astronomical), French Revolutionary (arithmetic and astronomical), Babylonian, Hebrew (arithmetic and astronomical), Samaritan, Mayan (long count, haab, and tzolkin), Aztec (xihuitl and tonalpohualli), Balinese Pawukon, Chinese, Japanese, Korean, Vietnamese, Hindu (old arithmetic and medieval astronomical, both solar and lunisolar), and Tibetan Phug-lugs. It also includes information on major holidays and on different methods of keeping time. The necessary astronom- ical functions have been rewritten to produce more accurate results and to include calculations of moonrise and moonset. The authors frame the calendars of the world in a completely algorithmic form, allowing easy conversion among these calendars and the determination of secular and religious holidays. Lisp code for all the algorithms is available in machine- readable form. Edward M. Reingold is Professor of Computer Science at the Illinois Institute of Technology. Nachum Dershowitz is Professor of Computational Logic and Chair of Computer Science at Tel Aviv University. © in this web service Cambridge University Press www.cambridge.org Cambridge University Press 978-1-107-05762-3 — Calendrical Calculations 4th Edition Frontmatter More Information About the Authors Edward M. -
1) Origin of Astronomy
Events that shaped human migrations • The last ice age began about 120,000 years ago. Origins of Astronomy • The Last Glacial Maximum, occurred about 18,000 BCE. • Between 15,000 BCE and 5,000 BCE, most of the world's glaciers melted the sea reclaimed former beaches and even valleys. • This movement of the sea inland occurred in several steps. – 13,000 BC Mayank Vahia – 9,000 - 8,000 BCE. 22 mm/year Tata Institute of Fundamental Research – 6,000 BCE. 2 mm/year – From 3000 BC, the rise is 7.5 mm/year. Mumbai 400 005 • Myths of great floods occur in many of the world's cultures. Origins of Astronomy 1 Origins of Astronomy 2 End of Ice Age and Human Migration • The last great Ice Age ended around 15,000 AVERAGE years ago and that must have facilitated human SNOW LINE migration. Origins of Astronomy 3 Origins of Astronomy 4 1 1,000,000 years in a nutshell! • Human race (Homo sapiens) first originate in Africa about million years ago. • They remain confined to central and northern Africa for almost 900,000 years! • Due to a mixture of reasons such as: – Sheer tireless desire to explore. – An overflow from population growth. – Inability of the local food sources to support a large human population. – Internal conflicts of personality within the population. – Differences in taste and preferred environment for settlement. They migrate out of Africa about 100,000 years ago. Origins of Astronomy 5 Origins of Astronomy 6 Origins of Astronomy 7 Origins of Astronomy 8 2 Migration and evolution Astronomy • Human race has gone through various stages of development. -

The Aesthetic Evolution of Melvin B. Tolson : a Thematic Study of His Poetry
RICE UNIVERSITY THE AESTHETIC EVOLUTION OF MELVIN B. TOLSON: A THEMATIC STUDY OF HIS POETRY by HERMINE D. PINSON A THESIS SUBMITTED IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE DOCTOR OF PHILOSOPHY APPROVED, THESIS COMMITTEE /?. U-G Terrence A. Doody, Professor of English, Chakman * mL ysL. Wesley Mojpris, Professor of English Bernard Aresu, Associate Professor of French Lorenzo Thomas, Writer-In-Residence, Uniyersity of Houston / /O 12. on, Associate Professor of Eng' outhern University THE AESTHETIC EVOLUTION OF MELVIN B. TOLSON: A THEMATIC STUDY OF HIS WORKS by Hermine D. Pinson ABSTRACT Within the context of Euro-American and Afro-American modernism Toison is an enigmatic figure. Only in recent years have critics and students begun to reappraise the works of a poet whose body of work reveals the varied influences of the writers of the Harlem Renaissance, the Symbolists, and the Euro-American modernists. Toison shares with Afro-American modernists, from Langston Hughes to Ralph Ellison, an indebtedness to Afro-American music and culture, from the blues to black vernacular speech to the tradition of "signifying," whether in the service of citing or "righting history." On the other hand, he shares with Euro-American modernists, from Ezra Pound to T. S. Eliot to W. B. Yeats, a predilection for symbolism, imagism, obscure allusions, and a preoccupation with confronting the chimeras of history and consciousness. To understand how Toison manages to incorporate elements of aesthetic approaches that are often politically and stylistically antithetical, this study traces the poet’s developing aesthetic, from his first manuscript, Portraits in a Harlem Gallery, to his last work, Harlem Gallery. -

St Arfle E T Communiqué
STARFLEET FIRST-CLASS MAIL US POSTAGE COMMUNIQUÉ PAID Stow, OH 656 LAFAYETTE ROAD, MEDINA, OHIO 44256 Permit No. 18 STARFLEET APPLICATION STARFLEET is the fan organization whose members are united the world over in their appreciation of Star Trek. Adventure. Hundreds of chap- ters worldwide link members into local fandom as well as the International organization. As a member of STARFLEET, you will receive a membership packet containing the basic supplies you need top get started on the road to becoming an active member in your local club. This packet contains: your membership certificate and card, a copy of the Membership Handbook, the Vessel Registry [a book containing all active chapters in the Fleet], a memo pad, and a application to Starfleet Academy. The membership handbook will introduce you to STARFLEET’s unique infrastructure that offers two membership options. One allows you to be an associate member with no obligation other than receiving membership materials and newsletters. The other option provides a more futuristic atmosphere for the fan intrigued by the Fleet structure within the Star Trek universe. After receiving the membership package you will have the oppor- tunity to sign aboard the chapter of your choice, hold a fictional rank and position and take part in that chapter’s Star Trek related activi- ties and community service endeavors, and other projects. Another service of STARFLEET is the COMMUNIQUE, our bi-monthly magazine, written by and for our members. The COMMU- NIQUE contains current information on STARFLEET operations and chapter activities, list of upcoming conventions, news and information on STAR TREK media and articles on the space program and other areas of interest to members. -
Grey Lodge Occult Review :: Issue #6
C O N T E N T S Serpents of Wisdom By Edda Livingston [PDF] Just Because You’re Smart, Doesn’t Mean You’re Not Stupid By Neal Pollock Sorry, but your soul just died By Tom Wolfe Fictive Arcanum By Don Webb Aleister Crowley and the LAM statement By Ian Blake The Palimsest By Hakim Bey Of Other Spaces, Heterotopias By Michel Foucault On the Edge of Spaces: Blade Runner, Ghost in the Shell, and Hong Kong's Cityscape By Wong Kin Yuen [PDF] Embodied Evil By Dennis Wheatley Astral Projection in Theory and Practice By Francis King and Stephen Skinner Invisible Eagle The History of Nazi Occultism By Alan Baker [Excerpt] The All-in-One Global Village By Tom Wolfe The Lucifer Principle By Howard Bloom Home GLORidx Close Window Except where otherwise noted, Grey Lodge Occult Review™ is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 License. By Edda Livingston © All Rights Reserved A Grey Lodge Occult Review Publication PDF E-book 20©03 Antiquities of the Illuminati™ Serpents of Wisdom Part 1 "Seekers there are in plenty: but they are almost all seekers of personal advantage. I can find so very few Seekers after Truth." (Sa'adi) 1 The imitator gives expression to a hundred proofs, but he speaks from discursive reasoning, not direct vision. He is musk-scented but not musk; he smells like musk but is only dung. (Rumi) You have probably come to the realization that there are no listings of Masters and true Teachers in the Yellow Pages. -

Early System of Naks.Atras, Calendar and Antiquity of Vedic & Harappan
Indian Journal of History of Science, 50.1 (2015) 1-25 DOI: 10.16943/ijhs/2015/v50i1/48109 Early System of Naks. atras, Calendar and Antiquity of Vedic & Harappan Traditions A K Bag* (Received 01 February, 2015) Abstract The fixation of time for Fire-worships and rites was of prime importance in the Vedic traditions. The apparent movement of the Sun, Moon, and a Zodiacal system along the path of the Sun/Moon with nakatras (asterisms or a group of stars) were used to develop a reasonable dependable calendar maintaining a uniformity in observation of nakatras, from which the antiquity of these early traditions could be fixed up. The gvedic tradition recognized the northern and the southern (uttarāyana and dakiāyana) motions of the Sun, referred originally to six nakatras (raised to 28 or 27) including Aśvinī nakatra citing it about 52 times. It recommended the beginning of the Year and a calendric system with the heliacal rising of Aśvinī at the Winter solstice. When Aśvinī was no longer found at Winter solstice because of the anti- clockwise motion of the zodiacal nakatras due to precision (not known at the time), the Full-moon at Citrā nakatra in opposition to the Sun at Winter solstice was taken into account as a marker for the Year- beginning, resulting in the counting of the lunar months from Caitra at the Winter solstice during Yajurvedic Sahitā time. The same system continued during the Brāhmaic tradition with the exception that it changed the Year-beginning to the New-moon of the month of Māgha (when Sun and Moon were together after 15 days of Full-moon at Maghā nakatra), resulting in the corroboration of the statement, ‘Kttikā nakatra rises in the east’. -

Directions Kali Yuga Yoga
N 1 K 0 a Directions A 1 s h 1 L v F i I a l t l Y h e , e U T Kali Yuga r N l G a 3 n 7 A d 2 S 0 t Y 6 Yoga . O G A From Downtown: Take Broadway Northeast towards the river. Take a right on 1st Ave South. Turn left onto Gateway Blvd / Gateway Bridge. After crossing the bridge, Gateway Blvd turns into Shelby Ave. Continue on Shelby and take left onto 11th. At the first stop sign take a left onto Fatherland. From South & West Nashville: Take I-65 N to I-40 E. Merge onto I-24 W towards Clarksville. Take Exit 49 Shelby Ave/ Coliseum. Keep left at the fork to continue on 4th St. Turn right onto Shelby Ave. Turn left onto 11th St. At stop sign take left onto Fatherland. Yoga Therapy for Citizens of Kali Yuga Yoga 1011 Fatherland Street East Nashville, TN 37206 the Kali Yuga 615.260.5361 [email protected] www.kaliyugayoga.com Welcome to Our Schedule Fees & Packages Kali Yuga Yoga U M T W R F S Single Class $13 I Week Unlimited $45 A Yoga Therapy Studio 10 Class Series $120 9:30 + 15 Class Series $160 As desc ribed in Hindu scriptures, the 25 Class Series $225 Kali Yuga is one of the four stages of 4:30 1 Month Unlimited $135 development that the world goes 3 Month Unlimited $375 through as part of the cycle of Yugas. 6:30 + 1 Year Unlimited $1200 Each Yuga is like the season of a super- Mat/ Towel Rental $2 cosmic year, starting with the Golden Based on the principles of Ayurveda, the Vedic science of health and age of P urity or Satya Yuga and wellness, yoga styles are defined by the Doshic system.