18-12 August 2018
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

1 Chief Commissioner of Income
Sl. No. Name of the Office CPIO Appellate Authority DC/ACIT (HQ), O/O CCIT, HUBLI, CCIT, HUBLI Income-tax Campus, CHIEF COMMISSIONER Gandhi Nagar, Gokul 1 C.R. Building, Hubli OF INCOME TAX, HUBLI Road, Hubli Ph.No. 0836-2323481 Ph.No. 0836-2225012 Fax: 2223889 Fax: 2223889 DC/ACIT (HQ), O/O CIT, HUBLI CIT, HUBLI Naveen Park COMMISSIONER OF Gandhi Nagar, Gokul Kusugal Road, Hubli 2 INCOME TAX, HUBLI Road, Hubli Ph.No. 0836-2223044 Ph.No. 0836-2225012 Fax no 0836-2223122 Fax No. 2223889 COMMISSIONER OF INCOME TAX CCIT, HUBLI (APPEALS), HUBLI Income-tax Campus, COMMISSIONER OF C.R. Building, C.R. Building, Hubli 3 INCOME TAX (APPEALS), Navanagar, Ph.No. 0836-2323481 HUBLI Hubli – 580025 Fax: 2223889 Ph. No. 0836-2322260 Fax : 2225358 ADDL./JCIT, RANGE-1, CIT, HUBLI HUBLI Naveen Park IT Guest House, ADDL./JCIT, RANGE-1, Kusugal Road, Hubli 4 Navanagar,HUBLI HUBLI Ph.No. 0836-2323159 Ph.No. 0836-2211959 Fax:2223122 Fax: 2322895 ADDL./JCIT, RANGE-1, DC/ACIT, CIRCLE-1(1), IT Guest House, HUBLI DC/ACIT, CIRCLE-1(1), Navanagar, HUBLI 5 17 Vidyanagar, Hubli HUBLI Ph.No. 0836-2211959 Ph.No. 0836-2323313 Fax : 2322895 INCOME TAX OFFICER, ADDL./JCIT, RANGE-1, WARD-1(1), HUBLI IT Guest House, INCOME TAX OFFICER, 23, 1st Floor, Navanagar,HUBLI 6 WARD-1(1), HUBLI Aswamedha Plot, Ph.No. 0836-2211959 Navanagar, Hubli Fax : 2322895 Ph.No. 0836-2225601 INCOME TAX OFFICER, ADDL./JCIT, RANGE-1, WARD-1(2), HUBLI IT Guest House, INCOME TAX OFFICER, 21/A, ‘Kalikarupa’ , Navanagar,HUBLI 7 WARD-1(2), HUBLI Udayanagar, Bengeri Ph.No. -

Total Samples Positive for COVID-19 149 1395 *Mangaluru Sea Port – 52 & Dubai to Mangalore Airport - 178 **Data Reconciled with Labs
GOVERNMENT OF KARNATAKA DEPARTMENT OF HEALTH AND FAMILY WELFARE BENGALURU NOVEL CORONA VIRUS (COVID-19) MEDIA BULLETIN DATED: 19/05/2020 Evening Report World Health Organization has declared the recent Novel Corona Virus, COVID-19 as Public Health Emergency of International Concern (PHEIC) which has affected 216 Countries / Territories including India till date. WHO has characterized COVID-19 as a Pandemic on 11th March 2020. In this context, Karnataka State has strengthened all Surveillance and containment measures against the spread of infection and prevent morbidity and mortality. New Cases Reported 1 149 (from 18/05/2020, 5:00 PM to 5:00 PM today) 2 Total Active Cases 811 3 Total Discharges 543 4 Total Covid Deaths 40 5 Death of Covid +ve patient due to Non-Covid cause 01 6 Total Positive Cases 1395 7 Admitted in ICU (among total active cases) 06 Particulars Today Cumulative A Total Passengers screened at Air Ports and Sea Ports 230* 143349 Total number of contacts under observation 9996 B Primary 13191 Secondary C Total under observation 23187 D Persons In Isolation At Health Facilities 301 1828 E Total Samples Tested 6936 158599** F Total Samples reported as Negative 6681 156247** Total Samples Positive for COVID-19 149 1395 *Mangaluru Sea Port – 52 & Dubai to Mangalore Airport - 178 **Data reconciled with Labs. Page 1 of 13 Details of new COVID-19 positive cases reported today: Sl. Age Case Sex District History Isolated at No. Numbers (Years) Designated Hospital, 1 P-1247 35 Female Davanagere Contact of P-694 Davanagere Designated -

Karnataka SG.Xlsx
Karnataka Salary Grant for New S.no file no organisation Address unique ID field Remarks Gujanur Mayanna Building, Kandodi, 1 KA(SG) N-1 Shri Sharada Kala Sangha Vill, Holalkere TQ, Chitradurga Dist, KA/2010/0038515 Dance Karnataka Jali Honi, Kamatagi Vill, Hunagund 2 KA(SG) N-2 Sarvodaya Natya Sangha KA/2013/0057313 Dance Tq, Bagalkot Dist, Karnataka # 71, R.H. Colony 1, Burma Camp, 3 KA(SG) N-3 Manukula Ashram Trust KA/2013/0060281 Theatre(Puppet) Sindhnoor Tq, Raichur Dist Peoples Charity Anjaneya Badavane Nittuvalli 4 KA(SG) N-4 KA/2009/0038430 Rare Art Form Association Davangere The world cultural and Maliyappanahally, Kurugal-Post, 5 KA(SG) N-5 Social Development Vemagal-Hobli, Kolar-Taluq, Kolar- KA/2013/069904 Theatre Organization District Nada Sarwati, Kala Ayyappa Nagar, Hubli Road, Sirsi, Dance/Music/The 6 KA(SG) N-6 KA/2011/0041978 Sangeeta and Sanskritika Karnataka atre C/o. P.S. Maruthi Pravision Stores Palkehalli Vill, Alagawadi Post, 7 KA(SG) N-7 Dinesh Foundation KA/2011/0038305 Dance Chitradurga Tq, Chitradurga Dist, Karnataka No.519, Maruthinilaya, 12th 'A' In Bond, grantee Abhinaya Ranga Kendra Theatre(Rare Art 8 KA(SG) N-8 Cross, Vigneshwaranagara, KA/2013/0070726 did not sign at Karnataka Form) Sunkadakatte, Bengaluru page no. 1 Sarva Mangala Kala Kalkere Vill, Holalkere Tq, 9 KA(SG) N-9 KA/2011/0065487 Dance Sangha Chitradurga Dist, Karnataka Sri Rajarajeshwari 85/11, 1st Cross, 1st Main, GD Park 10 KA(SG) N-10 KA/2011/0044379 Dance/Music Kalaniketan Extn, Vyalikaval, Bangalore Ningappa Ningamma 11 KA(SG) N-11 Umesh Foundation Ujjalappanavara Mane, Chitrahalli KA/2011/0026457 Dance Vill, Holalkere Tq, Chitragurga Dist Sri Guruguha Vaaggeya 53, Opposite to SAI Mandira, 3rd 12 KA(SG) N-12 KA/2013/0057091 Music Prathisthana Trust Cross, Basavangudi, Shimoa Opp. -

District Profile
Davanagere District Disaster Management Plan CHAPTER –1 DISTRICT PROFILE - 1 - Davanagere District Disaster Management Plan 1. INTRODUCTION A great Maratha warrior by name Appaji Rao had rendered great service to Hyder Ali Khan in capturing Chitradurga fort. Hyder Ali Khan was very much pleased with Appaji Rao, who had made great sacrifices in the wars waged by him. Davanagere was handed over to Appaji Rao as a Jahagir. It was a very small village of about 500 houses in its perview. Appaji Rao had to toil for the upliftment of this area by inviting Maratha businessmen from neighbouring Maharastra. A large number of Marathas arrived at this place to carry on business in silk, brasserie and other materials. In due course, due to the incessant efforts of Appaji Rao, the Davanagere village grew into a city. Businessmen from neigbouring areas also migrated to try their fortunes in the growing city were successful beyond imagination in earning and shaping their future careers. These circumstances created an opportunity for the perennial growth of the town in modern days. The word ‘Davanager’ is derived from “Davanagere”, which means a rope in kannada language which was used for tying the horses by the villages. Around 1811 A.D., this area came to be called as ‘Davanagere’. Davanagere district occupies 12th place in Karnataka State with a population of 17,89,693 as per the general census of 2001. The following table demonstrates the block wise population of Davanagere district and the rate of literacy. The DDMP has been formed keeping in view of past experiences, suiting to the needs under the able leadership of Deputy Commissioner and in co-operation of all other departments and public at large. -

Sl No District CVC Name Category 1 Davanagere ALUR COVAXIN
ಕ ೋ풿蓍 ಲಕಾಕರಣ ಕ ೋᲂ飍ರಗಳು (COVID VACCINATION CENTRES) Sl No District CVC Name Category 1 Davanagere ALUR COVAXIN Government 2 Davanagere ALUR PHC-01 Government 3 Davanagere ALURHATTI PHC-01 Government 4 Davanagere Anaburu Subcenter Government 5 Davanagere ANAGODU COVAXIN Government 6 Davanagere ANAGODU PHC-01 Government 7 Davanagere ANAGODU-A Government 8 Davanagere ANAGODU-B Government 9 Davanagere ANAGODU-C Government 10 Davanagere ANAJI PHC-01 Government 11 Davanagere ANAJI-A Government 12 Davanagere ANAJI-B Government 13 Davanagere Arabagatte PHC Government 14 Davanagere Arabagatte Sub Center Government 15 Davanagere ARABAGHATTE COVAXIN Government 16 Davanagere ARAIKE HOSPITAL - 01 Private 17 Davanagere ARASAPURA COVAXIN Government 18 Davanagere ARASAPURA PHC-01 Government 19 Davanagere Arashinagatta COVISHIELD Government 20 Davanagere Arehalli COVISHIELD Government 21 Davanagere Arundi Sub Center Government 22 Davanagere ASAGODU PHC COVAXIN Government 23 Davanagere ASAGODU PHC COVISHIELD Government 24 Davanagere Asagodu Subcenter Government 25 Davanagere AZAD NAGAR UPHC -01 Government 26 Davanagere AZADNAGAR COVAXIN Government 27 Davanagere BADA COVAXIN Government 28 Davanagere BADA PHC-01 Government 29 Davanagere BAPUJI HOSPITAL - 01 Private 30 Davanagere Basavanakote PHC COVAXIN Government 31 Davanagere Basavanakote PHC COVISHIELD Government 32 Davanagere Basavanakote Subcenter Government 33 Davanagere Basavapattana PHC - 01 Government 34 Davanagere BASHA NAGAR UPHC Government 35 Davanagere Beeragondanahalli Subcenter Government 36 -

GI Journal No. 77 1 November 30, 2015
GI Journal No. 77 1 November 30, 2015 GOVERNMENT OF INDIA GEOGRAPHICAL INDICATIONS JOURNAL NO.77 NOVEMBER 30, 2015 / AGRAHAYANA 09, SAKA 1936 GI Journal No. 77 2 November 30, 2015 INDEX S. No. Particulars Page No. 1 Official Notices 4 2 New G.I Application Details 5 3 Public Notice 6 4 GI Applications Guledgudd Khana - GI Application No.210 7 Udupi Sarees - GI Application No.224 16 Rajkot Patola - GI Application No.380 26 Kuthampally Dhoties & Set Mundu - GI Application No.402 37 Waghya Ghevada - GI Application No.476 47 Navapur Tur Dal - GI Application No.477 53 Vengurla Cashew - GI Application No.489 59 Lasalgaon Onion - GI Application No.491 68 Maddalam of Palakkad (Logo) - GI Application No.516 76 Brass Broidered Coconut Shell Craft of Kerala (Logo) - GI 81 Application No.517 Screw Pine Craft of Kerala (Logo) - GI Application No.518 89 6 General Information 94 7 Registration Process 96 GI Journal No. 77 3 November 30, 2015 OFFICIAL NOTICES Sub: Notice is given under Rule 41(1) of Geographical Indications of Goods (Registration & Protection) Rules, 2002. 1. As per the requirement of Rule 41(1) it is informed that the issue of Journal 77 of the Geographical Indications Journal dated 30th November 2015 / Agrahayana 09th, Saka 1936 has been made available to the public from 30th November 2015. GI Journal No. 77 4 November 30, 2015 NEW G.I APPLICATION DETAILS App.No. Geographical Indications Class Goods 530 Tulaipanji Rice 31 Agricultural 531 Gobindobhog Rice 31 Agricultural 532 Mysore Silk 24, 25 and 26 Handicraft 533 Banglar Rasogolla 30 Food Stuffs 534 Lamphun Brocade Thai Silk 24 Textiles GI Journal No. -

Central Council for Research in Yoga & Naturopathy
Central Council for Research in Yoga & Naturopathy 61-65, Institutional Area, Janakpuri, New Delhi -110058 S. No. Name of the Applicant Address Application D D No. Bank Name Date of DD ID 1. Dr. B. V. Rao C-6 B/109, TF, Janakpuri, Y000003 534525 SBI 16.05.2017 New Delhi -110058 2. Dr. Vadiraja H. S C-4 H/97, GF, Janakpuri, Y000004 298974 SBI 17.05.2017 New Delhi -110058 3. Dr. B. Anasuya C-6 B/109, TF, Janakpuri, Y000005 694871 SBI 17.05.2017 New Delhi -110058 4. Dr. Sangeeth 61-65, Janakpuri, New Delhi - 110058 Y000006 391837 SBI 17.05.2017 5. Dr. Jyoti Pullan 61-65, Janakpuri, New Delhi - 110058 Y000007 391835 SBI 17.05.2017 6. Dr. Vikram Pai D 1-A/119, GF, Jankpuri Y000008 380708 SBI 17.05.2017 New Delhi -110058 7. S. Jeya Poornima JSS, INYS, Coimbatore, T.N., Y000030 708622 SBI 18.05.2017 Ph. 9677771459, 9445878107 8. F. Nithila Catherin JSS, INYS, Coimbatore, T.N., Y000031 708623 SBI 18.05.2017 Ph. 9159127669 9. Naresh Kumar P JSS Institute of Naturopathy Yogic Y000016 708620 SBI 18.05.2017 Sciences, Palakkad Highway, Navakkarai, Coimbatore - 641105 Tamil Nadu, Ph. 9976157398 10. N. Nagarajan JSS Institute of Naturopathy Yogic Y000017 708619 SBI 18.05.2017 Sciences, Palakkad Highway, Navakkarai, Coimbatore - 641105 Tamil Nadu, Ph. 9965555994 11. Dr. Umashankar Sharma 233, Ward No. 6, Ary Nagar, Bhind, Y000032 252021 SBI 18.05.2017 M.P. 12. Dr. M. Vaishnavi Thiru. VEE. KA. Nagar, Chinnalapatti, Y000037 960729 SBI 18.05.2017 Diwdigul Ph. -

Temple Art & Architecture of Davanagere District – a Study
Science, Technology and Development ISSN : 0950-0707 Temple Art & Architecture of Davanagere District – A Study *Dr.Thippeswamy.H, Associate Professor of History, Dept of History and Archaeology Vijayanagara Sri Krishnadevaraya University - Ballari Abstract Situated in the foothills of the Western Ghats, Davangere city lies in the state of Karnataka in India. Earlier this place was known for its textile business’ and cotton mills but now it’s famous for education and a prominent center for business and economy. Davangere district was established in 1997 after it separated itself from Chitradurga. A survey of the religious phenomenon in the Indian context from the perspective of space and time reveals that it was never static but constantly underwent modifications by assimilating and absorbing new features of practices and worship. Sanatanadharma, the forerunner of the later day Hinduism, advocated Jnana, Vairagya, Bhakti and Karma paths to reach God, while Jnana and Vairagya paths were followed by superior intellectual groups, the Karma and Bhakti paths are followed by common folk.It is a well-known fact of history that Vedic Yagnas, worship of primitive deities with offering of blood, meat and toddy, the domestic rituals and worship of icon in temples of Davangere, heterodox beliefs like Jainism and Buddhism flourished side by side, sometimes competing for space and sometimes adjusting, accommodating and absorbing other rituals into its fold.We have already noted that initiation of puranic dharma in the Gupta and post-Gupta era along with devotionalism of an individual God – Siva and Vishnu and Sakthi worship revived the age-old Bhakti Marga as a popular way to attain God and to achieve liberation. -

Traffic Volume Count and Signal Optimisation at Mothi Circle Davanagere
International Journal of Engineering Research & Technology (IJERT) ISSN: 2278-0181 Vol. 4 Issue 09, September-2015 Traffic Volume Count and Signal Optimisation at Mothi Circle Davanagere Mohammed Yaseen1 Swamy L V2 Kirankumar H S3 Assistant Professor, Assistant Professor, Assistant Professor, Dept of Civil Engg, GMIT, Dept of Civil Engg, GMIT, Dept of Civil Engg, GMIT, Davangere, Karnataka, India Davangere, Karnataka, India Davangere, Karnataka, India Abstract—Traffic analysis is basically the process of is regularly increasing but the road area especially in the intercepting and examining the number of vehicles on the existing part of the cities and in city cores, remains the road and deducing the pattern of traffic movement. A traffic same, making the situation grim by increasing the survey on Mothi circle intersection of Davangere city has been congestion in central and the other important part of cities. carried out which includes calculation of present traffic Mass transportation systems are generally neglected or do density and analysis of traffic volume by adopting the Manual method of counting. PCU estimations are made and not provide regular, adequate, safe and reliable quality of appropriate design corrections are suggested for highway services there by people relying on the private vehicles, geometry. For the proposed design geometry the signal time is which leads to extreme congestion, increase in pollution, optimized. accidents and add to general deterioration of quality of life in cities. In metro cities there are about 15% car users and as Keywords— Signal Optimisation, Traffic volume Count, 75% of the transport budget is used for widening roads, PCU estimation and Geometric Design. -
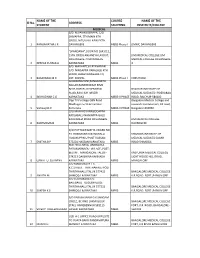
Sl No. NAME of the STUDENT ADDRESS COURSE STUDYING
NAME OF THE COURSE NAME OF THE Sl No. ADDRESS STUDENT STUDYING INSTITUTE/COLLEGE MEDICAL S/O. REVANASIDDAPPA, C/O. SHIVAPPA, 7TH MAIN 6TH CROSS, NITUVALLI NEW EXTN. 1 RANGANATHA J R DAVANGERE MBBS Phase-I JJMMC DAVANGERE "SPANDANA",DOOR NO 1643/12, 15TH CROSS ANJANEYA LAYOUT, JJM MEDICAL COLLEGE JJM DAVANGERE-4 DAVANGERE MEDICAL COLLEGE DAVANGERE- 2 DEEPAK KUMAR A KARNATAKA MBBS 4 S/O. MAHANTESH RYAVANAKI C/O. NINGAPPA VARALALLI 4TH WARD, BHAGYANAGARA TQ. 3 BASAVARAJ M R DST. KOPPAL MBBS Phase-I KIMS HUBLI GOLASANGI ONI,RANGANATH NAGAR,RANEBENNUR RIMS BOYS HOSTEL,HYDERABAD RAICHUR INSTITUTE OF ROAD,RAICHUR HAVERI MEDICAL SCIENCES HYDERABAD 4 INDHUDHAR C G KARNATAKA MBBS-II PHASE ROAD, RAICHUR-584102 Opp TVV college GBN Road Bangalore Medical College and Madhugiri-572132 Tumkur research Institute Fort, KR road, 5 Vishwajith K Karnataka MBBS-II PHASE Bangalore-560002 D/O MANI REVANASIDDAPPA KADLABALU NANJAPPA GALLI KALIKADEVI ROAD DAVANGERE JJM MEDICAL COLLEGE 6 RASHMI MANI KARNATAKA MBBS DAVANGERE D/O PUTTASWAMY B J WARD NO 35 BOMMANAYAKANAHALLI SHIMOGA INSTITUTE OF HOSAKOPPALU POST HASSAN MEDICAL SCIENCES SAGAR 7 SMITHA B P 573201 HASSAN KARNATAKA MBBS ROAD SHIMOGA MATHRUCHAYA, BANNADKA PADUMARNADU VILLAGE, POST: BELVAI , MANGALORE TALUK-- KASTURBA MEDICAL COLLEGE 574213 DAKSHINA KANNADA LIGHT HOUSE HILL ROAD, 8 UJWAL U SUVARNA KARNATAKA MBBS MANGALORE S/O MANJUNATH T K. K.C.STREET. THIRTHAHALLI POST THIRTHAHALLI TALUK 577432 BANGALORE MEDICAL COLLEGE 9 ANVITH M SHIMOGA KARNATAKA MBBS K.R.ROAD. FORT ,BANGALORE S/O SUDHAKARA K G BALEBAILU KUDUMALLIGE THIRTHAHALLI TALUK 577232 BANGALORE MEDICAL COLLEGE 10 SUKESH K S SHIMOGA KARNATAKA MBBS K.R.ROAD. -

Smart Cities Mission - India Opportunities for UK Businesses Analysis of Lighthouse Cities
Smart Cities Mission - India Opportunities for UK Businesses Analysis of Lighthouse cities June 2016 Table of contents Contents Page no. Smart Cities Mission in India – executive summary 5 Limitations of the study 22 List of abbreviations 23 Broad overview - analysis of opportunities in lighthouse cities 25 . Ranking and location 26 . Overall proposed investments 27 . Proposed sources of funding 28 . State-wise proposed capital investments 29 . City-wise capital investments 30 Detailed sectoral analysis of lighthouse cities 32 . Built Environment 33 . Transportation 37 . Water and Waste Management 42 . Energy 47 . Technology Infrastructure 52 Page 2 Table of contents Contents Page no. Public Services 57 Opportunities for UK businesses 61 . Opportunities for services and advisory based firms 62 . Opportunities for OEMs/vendor firms/suppliers 64 . Opportunities for implementation agencies/system 66 integrators/assembly firms Detailed opportunity analysis of the 20 lighthouse cities 68 . Ahmedabad 69 . Belagavi 81 . Bhopal 94 . Bhubaneshwar 103 . Chennai 116 . Coimbatore 124 . Davanagere 137 . Guwahati 147 Page 3 Table of contents Contents Page no. Indore 157 . Jabalpur 171 . Jaipur 185 . Kakinada 197 . Kochi 209 . Ludhiana 221 . New Delhi 232 . Pune 244 . Solapur 256 . Surat 267 . Udaipur 278 . Visakhapatnam 288 State-wise procurement policies 300 Annexures 305 Page 4 Smart Cities Mission Executive Summary Executive Summary Background to India’s Smart Cities Mission To sustain the rapid urbanisation India is witnessing, the Government of India / Ministry of Urban Development (MoUD) in 2015 had launched a bold and ambitious ‘Smart Cities Mission’. This mission focuses on improving quality of life of city dwellers through sustainable, citizen-centric and inclusive development, which aims at providing missing links in the urban infrastructure and to create replicable models for other aspiring cities in the country. -

The Political Construction of Caste in South India
The Political Construction of Caste in South India Vijayendra Rao ([email protected]) Development Research Group, The World Bank And Radu Ban ([email protected]) London School of Economics and Development Research Group, The World Bank August 2007 We thank seminar participants at the World Bank’s research department and Karla Hoff for helpful conversations and comments. Jillian Waid and Babu Srinivas Dasari provided excellent research assistance. This paper reflects the views of the authors and should not be attributed to the World Bank, its member countries or any affiliated organization. We are indebted to the Dutch government, and the Research Support Budget of the Development Economics Vice-Presidency of the World Bank, for financial support. Abstract Are social institutions endogenous? Can measures of social diversity (e.g. fractionalization) be treated as exogenous variables in assessing their impact on economic and political outcomes? The caste system, which categorizes Hindus into endogamous and stratified social groups, is considered to be the organizing institution of Indian society. It is widely thought to have stayed stable for hundreds if not thousands of years -- so deeply resistant to change that it has been blamed for everything from (formerly) anemic “Hindu” rates of growth, to persistent “inequality traps.” This paper uses a natural experiment -- the 1956 reorganization of Indian states along linguistic lines – to demonstrate that the number and nomenclature of castes has significantly changed in linguistically matched villages (i.e. “mistakes” in the reorganization) at the borders of these states. This shows that the caste system is not stable but a pliable institution - endogenous to political change.