Proposal to Encode the Kaithi Script in Plane 1 of ISO/IEC 10646
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

On the Origin of the Indian Brahma Alphabet
- ON THE <)|{I<; IN <>F TIIK INDIAN BRAHMA ALPHABET GEORG BtfHLKi; SECOND REVISED EDITION OF INDIAN STUDIES, NO III. TOGETHER WITH TWO APPENDICES ON THE OKU; IN OF THE KHAROSTHI ALPHABET AND OF THK SO-CALLED LETTER-NUMERALS OF THE BRAHMI. WITH TIIKKK PLATES. STRASSBUKi-. K A K 1. I. 1 1M I: \ I I; 1898. I'lintccl liy Adolf Ilcil/.haiisi'ii, Vicniiii. Preface to the Second Edition. .As the few separate copies of the Indian Studies No. Ill, struck off in 1895, were sold very soon and rather numerous requests for additional ones were addressed both to me and to the bookseller of the Imperial Academy, Messrs. Carl Gerold's Sohn, I asked the Academy for permission to issue a second edition, which Mr. Karl J. Trlibner had consented to publish. My petition was readily granted. In addition Messrs, von Holder, the publishers of the Wiener Zeitschrift fur die Kunde des Morgenlandes, kindly allowed me to reprint my article on the origin of the Kharosthi, which had appeared in vol. IX of that Journal and is now given in Appendix I. To these two sections I have added, in Appendix II, a brief review of the arguments for Dr. Burnell's hypothesis, which derives the so-called letter- numerals or numerical symbols of the Brahma alphabet from the ancient Egyptian numeral signs, together with a third com- parative table, in order to include in this volume all those points, which require fuller discussion, and in order to make it a serviceable companion to the palaeography of the Grund- riss. -

Linguistic Survey of India Bihar
LINGUISTIC SURVEY OF INDIA BIHAR 2020 LANGUAGE DIVISION OFFICE OF THE REGISTRAR GENERAL, INDIA i CONTENTS Pages Foreword iii-iv Preface v-vii Acknowledgements viii List of Abbreviations ix-xi List of Phonetic Symbols xii-xiii List of Maps xiv Introduction R. Nakkeerar 1-61 Languages Hindi S.P. Ahirwal 62-143 Maithili S. Boopathy & 144-222 Sibasis Mukherjee Urdu S.S. Bhattacharya 223-292 Mother Tongues Bhojpuri J. Rajathi & 293-407 P. Perumalsamy Kurmali Thar Tapati Ghosh 408-476 Magadhi/ Magahi Balaram Prasad & 477-575 Sibasis Mukherjee Surjapuri S.P. Srivastava & 576-649 P. Perumalsamy Comparative Lexicon of 3 Languages & 650-674 4 Mother Tongues ii FOREWORD Since Linguistic Survey of India was published in 1930, a lot of changes have taken place with respect to the language situation in India. Though individual language wise surveys have been done in large number, however state wise survey of languages of India has not taken place. The main reason is that such a survey project requires large manpower and financial support. Linguistic Survey of India opens up new avenues for language studies and adds successfully to the linguistic profile of the state. In view of its relevance in academic life, the Office of the Registrar General, India, Language Division, has taken up the Linguistic Survey of India as an ongoing project of Government of India. It gives me immense pleasure in presenting LSI- Bihar volume. The present volume devoted to the state of Bihar has the description of three languages namely Hindi, Maithili, Urdu along with four Mother Tongues namely Bhojpuri, Kurmali Thar, Magadhi/ Magahi, Surjapuri. -

The Festvox Indic Frontend for Grapheme-To-Phoneme Conversion
The Festvox Indic Frontend for Grapheme-to-Phoneme Conversion Alok Parlikar, Sunayana Sitaram, Andrew Wilkinson and Alan W Black Carnegie Mellon University Pittsburgh, USA aup, ssitaram, aewilkin, [email protected] Abstract Text-to-Speech (TTS) systems convert text into phonetic pronunciations which are then processed by Acoustic Models. TTS frontends typically include text processing, lexical lookup and Grapheme-to-Phoneme (g2p) conversion stages. This paper describes the design and implementation of the Indic frontend, which provides explicit support for many major Indian languages, along with a unified framework with easy extensibility for other Indian languages. The Indic frontend handles many phenomena common to Indian languages such as schwa deletion, contextual nasalization, and voicing. It also handles multi-script synthesis between various Indian-language scripts and English. We describe experiments comparing the quality of TTS systems built using the Indic frontend to grapheme-based systems. While this frontend was designed keeping TTS in mind, it can also be used as a general g2p system for Automatic Speech Recognition. Keywords: speech synthesis, Indian language resources, pronunciation 1. Introduction in models of the spectrum and the prosody. Another prob- lem with this approach is that since each grapheme maps Intelligible and natural-sounding Text-to-Speech to a single “phoneme” in all contexts, this technique does (TTS) systems exist for a number of languages of the world not work well in the case of languages that have pronun- today. However, for low-resource, high-population lan- ciation ambiguities. We refer to this technique as “Raw guages, such as languages of the Indian subcontinent, there Graphemes.” are very few high-quality TTS systems available. -
LAST FIRST EXP Updated As of 8/10/19 Abano Lu 3/1/2020 Abuhadba Iz 1/28/2022 If Athlete's Name Is Not on List Acevedo Jr
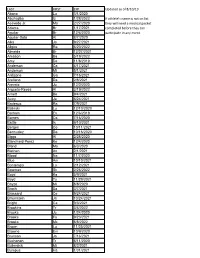
LAST FIRST EXP Updated as of 8/10/19 Abano Lu 3/1/2020 Abuhadba Iz 1/28/2022 If athlete's name is not on list Acevedo Jr. Ma 2/27/2020 they will need a medical packet Adams Br 1/17/2021 completed before they can Aguilar Br 12/6/2020 participate in any event. Aguilar-Soto Al 8/7/2020 Alka Ja 9/27/2021 Allgire Ra 6/20/2022 Almeida Br 12/27/2021 Amason Ba 5/19/2022 Amy De 11/8/2019 Anderson Ca 4/17/2021 Anderson Mi 5/1/2021 Ardizone Ga 7/16/2021 Arellano Da 2/8/2021 Arevalo Ju 12/2/2020 Argueta-Reyes Al 3/19/2022 Arnett Be 9/4/2021 Autry Ja 6/24/2021 Badeaux Ra 7/9/2021 Balinski Lu 12/10/2020 Barham Ev 12/6/2019 Barnes Ca 7/16/2020 Battle Is 9/10/2021 Bergen Co 10/11/2021 Bermudez Da 10/16/2020 Biggs Al 2/28/2020 Blanchard-Perez Ke 12/4/2020 Bland Ma 6/3/2020 Blethen An 2/1/2021 Blood Na 11/7/2020 Blue Am 10/10/2021 Bontempo Lo 2/12/2021 Bowman Sk 2/26/2022 Boyd Ka 5/9/2021 Boyd Ty 11/29/2021 Boyzo Mi 8/8/2020 Brach Sa 3/7/2021 Brassard Ce 9/24/2021 Braunstein Ja 10/24/2021 Bright Ca 9/3/2021 Brookins Tr 3/4/2022 Brooks Ju 1/24/2020 Brooks Fa 9/23/2021 Brooks Mc 8/8/2022 Brown Lu 11/25/2021 Browne Em 10/9/2020 Brunson Jo 7/16/2021 Buchanan Tr 6/11/2020 Bullerdick Mi 8/2/2021 Bumpus Ha 1/31/2021 LAST FIRST EXP Updated as of 8/10/19 Burch Co 11/7/2020 Burch Ma 9/9/2021 Butler Ga 5/14/2022 Byers Je 6/14/2021 Cain Me 6/20/2021 Cao Tr 11/19/2020 Carlson Be 5/29/2021 Cerda Da 3/9/2021 Ceruto Ri 2/14/2022 Chang Ia 2/19/2021 Channapati Di 10/31/2021 Chao Et 8/20/2021 Chase Em 8/26/2020 Chavez Fr 6/13/2020 Chavez Vi 11/14/2021 Chidambaram Ga 10/13/2019 -

Handwriting Recognition in Indian Regional Scripts: a Survey of Offline Techniques
1 Handwriting Recognition in Indian Regional Scripts: A Survey of Offline Techniques UMAPADA PAL, Indian Statistical Institute RAMACHANDRAN JAYADEVAN, Pune Institute of Computer Technology NABIN SHARMA, Indian Statistical Institute Offline handwriting recognition in Indian regional scripts is an interesting area of research as almost 460 million people in India use regional scripts. The nine major Indian regional scripts are Bangla (for Bengali and Assamese languages), Gujarati, Kannada, Malayalam, Oriya, Gurumukhi (for Punjabi lan- guage), Tamil, Telugu, and Nastaliq (for Urdu language). A state-of-the-art survey about the techniques available in the area of offline handwriting recognition (OHR) in Indian regional scripts will be of a great aid to the researchers in the subcontinent and hence a sincere attempt is made in this article to discuss the advancements reported in this regard during the last few decades. The survey is organized into different sections. A brief introduction is given initially about automatic recognition of handwriting and official re- gional scripts in India. The nine regional scripts are then categorized into four subgroups based on their similarity and evolution information. The first group contains Bangla, Oriya, Gujarati and Gurumukhi scripts. The second group contains Kannada and Telugu scripts and the third group contains Tamil and Malayalam scripts. The fourth group contains only Nastaliq script (Perso-Arabic script for Urdu), which is not an Indo-Aryan script. Various feature extraction and classification techniques associated with the offline handwriting recognition of the regional scripts are discussed in this survey. As it is important to identify the script before the recognition step, a section is dedicated to handwritten script identification techniques. -

Review of Research
Review Of ReseaRch impact factOR : 5.7631(Uif) UGc appROved JOURnal nO. 48514 issn: 2249-894X vOlUme - 8 | issUe - 7 | apRil - 2019 __________________________________________________________________________________________________________________________ AN ANALYSIS OF CURRENT TRENDS FOR SANSKRIT AS A COMPUTER PROGRAMMING LANGUAGE Manish Tiwari1 and S. Snehlata2 1Department of Computer Science and Application, St. Aloysius College, Jabalpur. 2Student, Deparment of Computer Science and Application, St. Aloysius College, Jabalpur. ABSTRACT : Sanskrit is said to be one of the systematic language with few exception and clear rules discretion.The discussion is continued from last thirtythat language could be one of best option for computers.Sanskrit is logical and clear about its grammatical and phonetically laws, which are not amended from thousands of years. Entire Sanskrit grammar is based on only fourteen sutras called Maheshwar (Siva) sutra, Trimuni (Panini, Katyayan and Patanjali) are responsible for creation,explainable and exploration of these grammar laws.Computer as machine,requires such language to perform better and faster with less programming.Sanskrit can play important role make computer programming language flexible, logical and compact. This paper is focused on analysis of current status of research done on Sanskrit as a programming languagefor .These will the help us to knowopportunity, scope and challenges. KEYWORDS : Artificial intelligence, Natural language processing, Sanskrit, Computer, Vibhakti, Programming language. -

The Original Pronunciation of Sanskrit Devanàgará – Transliteration – IPA-Symbols
The Original Pronunciation of Sanskrit DevanÀgarÁ – Transliteration – IPA-Symbols $ a n$D À DØ i L Á LØ u X A Â XØ ? Ã `C C Å `CØ CØ Æ O C # e HØ #H ai DeØ, $DH o RØ $D( au DØe8 N{ k N R kh N+ J g J gh J+ Ç 1 F c WeÝ ' ch WeÝ+ M j GeÛ + jh GeÛ+ _ È × T Ê Þ 4 Êh Þ+ I Ë É ) Ëh É+ > É Ö W t W Z th W+ G{ d G [ dh G+ Q n Q S p S { ph S+ E b E bh E+ P m P \ y M U{ r `O l O Y v Y9 ] Ì Ý Í V s V K h Ù Drafted by Maciej Zieba and Ulrich Stiehl under the auspices of Manfred Mayrhofer. ! Ï [ Improvements by Jost Gippert, Madhav Deshpande, Sunder Hattangadi, John Smith and others. This chart is a compromise, since the original pronunciation of Sanskrit Î YDULRXV is not exactly known in every detail. – 06/09/2002/us. Notes: 1. $ seems to have been pronounced originally as [n] or as [], possibly never as [D]. Not even the pronunciation of this most often used letter $ is exactly known! 2. The original pronunciation of is not known. It occurs only in the verb dS(kÆp). 3. U{seems to have been pronounced as [`] or as [], and likewise the liquid seems to have been pronounced as syllabic [`C] (notation: [`]+ [ C]) or as syllabic [C]. 4. The pronunciation of the semi-vowel Y seems to have been either [Y] or [9]. -

The What and Why of Whole Number Arithmetic: Foundational Ideas from History, Language and Societal Changes
Portland State University PDXScholar Mathematics and Statistics Faculty Fariborz Maseeh Department of Mathematics Publications and Presentations and Statistics 3-2018 The What and Why of Whole Number Arithmetic: Foundational Ideas from History, Language and Societal Changes Xu Hu Sun University of Macau Christine Chambris Université de Cergy-Pontoise Judy Sayers Stockholm University Man Keung Siu University of Hong Kong Jason Cooper Weizmann Institute of Science SeeFollow next this page and for additional additional works authors at: https:/ /pdxscholar.library.pdx.edu/mth_fac Part of the Science and Mathematics Education Commons Let us know how access to this document benefits ou.y Citation Details Sun X.H. et al. (2018) The What and Why of Whole Number Arithmetic: Foundational Ideas from History, Language and Societal Changes. In: Bartolini Bussi M., Sun X. (eds) Building the Foundation: Whole Numbers in the Primary Grades. New ICMI Study Series. Springer, Cham This Book Chapter is brought to you for free and open access. It has been accepted for inclusion in Mathematics and Statistics Faculty Publications and Presentations by an authorized administrator of PDXScholar. Please contact us if we can make this document more accessible: [email protected]. Authors Xu Hu Sun, Christine Chambris, Judy Sayers, Man Keung Siu, Jason Cooper, Jean-Luc Dorier, Sarah Inés González de Lora Sued, Eva Thanheiser, Nadia Azrou, Lynn McGarvey, Catherine Houdement, and Lisser Rye Ejersbo This book chapter is available at PDXScholar: https://pdxscholar.library.pdx.edu/mth_fac/253 Chapter 5 The What and Why of Whole Number Arithmetic: Foundational Ideas from History, Language and Societal Changes Xu Hua Sun , Christine Chambris Judy Sayers, Man Keung Siu, Jason Cooper , Jean-Luc Dorier , Sarah Inés González de Lora Sued , Eva Thanheiser , Nadia Azrou , Lynn McGarvey , Catherine Houdement , and Lisser Rye Ejersbo 5.1 Introduction Mathematics learning and teaching are deeply embedded in history, language and culture (e.g. -

Tai Lü / ᦺᦑᦟᦹᧉ Tai Lùe Romanization: KNAB 2012
Institute of the Estonian Language KNAB: Place Names Database 2012-10-11 Tai Lü / ᦺᦑᦟᦹᧉ Tai Lùe romanization: KNAB 2012 I. Consonant characters 1 ᦀ ’a 13 ᦌ sa 25 ᦘ pha 37 ᦤ da A 2 ᦁ a 14 ᦍ ya 26 ᦙ ma 38 ᦥ ba A 3 ᦂ k’a 15 ᦎ t’a 27 ᦚ f’a 39 ᦦ kw’a 4 ᦃ kh’a 16 ᦏ th’a 28 ᦛ v’a 40 ᦧ khw’a 5 ᦄ ng’a 17 ᦐ n’a 29 ᦜ l’a 41 ᦨ kwa 6 ᦅ ka 18 ᦑ ta 30 ᦝ fa 42 ᦩ khwa A 7 ᦆ kha 19 ᦒ tha 31 ᦞ va 43 ᦪ sw’a A A 8 ᦇ nga 20 ᦓ na 32 ᦟ la 44 ᦫ swa 9 ᦈ ts’a 21 ᦔ p’a 33 ᦠ h’a 45 ᧞ lae A 10 ᦉ s’a 22 ᦕ ph’a 34 ᦡ d’a 46 ᧟ laew A 11 ᦊ y’a 23 ᦖ m’a 35 ᦢ b’a 12 ᦋ tsa 24 ᦗ pa 36 ᦣ ha A Syllable-final forms of these characters: ᧅ -k, ᧂ -ng, ᧃ -n, ᧄ -m, ᧁ -u, ᧆ -d, ᧇ -b. See also Note D to Table II. II. Vowel characters (ᦀ stands for any consonant character) C 1 ᦀ a 6 ᦀᦴ u 11 ᦀᦹ ue 16 ᦀᦽ oi A 2 ᦰ ( ) 7 ᦵᦀ e 12 ᦵᦀᦲ oe 17 ᦀᦾ awy 3 ᦀᦱ aa 8 ᦶᦀ ae 13 ᦺᦀ ai 18 ᦀᦿ uei 4 ᦀᦲ i 9 ᦷᦀ o 14 ᦀᦻ aai 19 ᦀᧀ oei B D 5 ᦀᦳ ŭ,u 10 ᦀᦸ aw 15 ᦀᦼ ui A Indicates vowel shortness in the following cases: ᦀᦲᦰ ĭ [i], ᦵᦀᦰ ĕ [e], ᦶᦀᦰ ăe [ ∎ ], ᦷᦀᦰ ŏ [o], ᦀᦸᦰ ăw [ ], ᦀᦹᦰ ŭe [ ɯ ], ᦵᦀᦲᦰ ŏe [ ]. -

Sanskrit Alphabet
Sounds Sanskrit Alphabet with sounds with other letters: eg's: Vowels: a* aa kaa short and long ◌ к I ii ◌ ◌ к kii u uu ◌ ◌ к kuu r also shows as a small backwards hook ri* rri* on top when it preceeds a letter (rpa) and a ◌ ◌ down/left bar when comes after (kra) lri lree ◌ ◌ к klri e ai ◌ ◌ к ke o au* ◌ ◌ к kau am: ah ◌ं ◌ः कः kah Consonants: к ka х kha ga gha na Ê ca cha ja jha* na ta tha Ú da dha na* ta tha Ú da dha na pa pha º ba bha ma Semivowels: ya ra la* va Sibilants: sa ш sa sa ha ksa** (**Compound Consonant. See next page) *Modern/ Hindi Versions a Other ऋ r ॠ rr La, Laa (retro) औ au aum (stylized) ◌ silences the vowel, eg: к kam झ jha Numero: ण na (retro) १ ५ ॰ la 1 2 3 4 5 6 7 8 9 0 @ Davidya.ca Page 1 Sounds Numero: 0 1 2 3 4 5 6 7 8 910 १॰ ॰ १ २ ३ ४ ६ ७ varient: ५ ८ (shoonya eka- dva- tri- catúr- pancha- sás- saptán- astá- návan- dásan- = empty) works like our Arabic numbers @ Davidya.ca Compound Consanants: When 2 or more consonants are together, they blend into a compound letter. The 12 most common: jna/ tra ttagya dya ddhya ksa kta kra hma hna hva examples: for a whole chart, see: http://www.omniglot.com/writing/devanagari_conjuncts.php that page includes a download link but note the site uses the modern form Page 2 Alphabet Devanagari Alphabet : к х Ê Ú Ú º ш @ Davidya.ca Page 3 Pronounce Vowels T pronounce Consonants pronounce Semivowels pronounce 1 a g Another 17 к ka v Kit 42 ya p Yoga 2 aa g fAther 18 х kha v blocKHead -

Indic Loanwords In Tocharian B, Local Markedness, And The Animacy
Indic Loanwords in Tocharian B, Local Markedness, and the Animacy Hierarchy Francesco Burroni and Michael Weiss (Department of Linguistics, Cornell University) A question that is rarely addressed in the literature devoted to Language Contact is: how are nominal forms borrowed when the donor and the recipient language both possess rich inflectional morphology? Can nominal forms be borrowed from and in different cases? What are the decisive factors shaping the borrowing scenario? In this paper, we frame this question from the angle of a case study involving two ancient Indo-European languages: Tocharian and Indic (Sanskrit, Prakrit(s)). Most studies dedicated to the topic of loanwords in Tocharian B (henceforth TB) have focused on borrowings from Iranian (e.g. Tremblay 2005), but little attention has been so far devoted to forms borrowed from Indic, perhaps because they are considered uninteresting. We argue that such forms, however, are of interest for the study of Language Contact. A remarkable feature of Indic borrowings into TB is that a-stems are borrowed in TB as e-stems when denoting animate referents, but as consonant (C-)stems when denoting inanimate referents, a distribution that was noticed long ago by Mironov (1928, following Staёl-Holstein 1910:117 on Uyghur). In the literature, however, one finds no reaction to Mironov’s idea. By means of a systematic study of all the a-stems borrowed from Indic into TB, we argue that the trait [+/- animate] of the referent is, in fact, a very good predictor of the TB shape of the borrowing, e.g. male personal names from Skt. -

5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721
Internet Engineering Task Force (IETF) P. Faltstrom, Ed. Request for Comments: 5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721 The Unicode Code Points and Internationalized Domain Names for Applications (IDNA) Abstract This document specifies rules for deciding whether a code point, considered in isolation or in context, is a candidate for inclusion in an Internationalized Domain Name (IDN). It is part of the specification of Internationalizing Domain Names in Applications 2008 (IDNA2008). Status of This Memo This is an Internet Standards Track document. This document is a product of the Internet Engineering Task Force (IETF). It represents the consensus of the IETF community. It has received public review and has been approved for publication by the Internet Engineering Steering Group (IESG). Further information on Internet Standards is available in Section 2 of RFC 5741. Information about the current status of this document, any errata, and how to provide feedback on it may be obtained at http://www.rfc-editor.org/info/rfc5892. Copyright Notice Copyright (c) 2010 IETF Trust and the persons identified as the document authors. All rights reserved. This document is subject to BCP 78 and the IETF Trust's Legal Provisions Relating to IETF Documents (http://trustee.ietf.org/license-info) in effect on the date of publication of this document. Please review these documents carefully, as they describe your rights and restrictions with respect to this document. Code Components extracted from this document must include Simplified BSD License text as described in Section 4.e of the Trust Legal Provisions and are provided without warranty as described in the Simplified BSD License.