Applied Operational Management Techniques for Sabermetrics
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Gether, Regardless Also Note That Rule Changes and Equipment Improve- of Type, Rather Than Having Three Or Four Separate AHP Ments Can Impact Records
Journal of Sports Analytics 2 (2016) 1–18 1 DOI 10.3233/JSA-150007 IOS Press Revisiting the ranking of outstanding professional sports records Matthew J. Liberatorea, Bret R. Myersa,∗, Robert L. Nydicka and Howard J. Weissb aVillanova University, Villanova, PA, USA bTemple University Abstract. Twenty-eight years ago Golden and Wasil (1987) presented the use of the Analytic Hierarchy Process (AHP) for ranking outstanding sports records. Since then much has changed with respect to sports and sports records, the application and theory of the AHP, and the availability of the internet for accessing data. In this paper we revisit the ranking of outstanding sports records and build on past work, focusing on a comprehensive set of records from the four major American professional sports. We interviewed and corresponded with two sports experts and applied an AHP-based approach that features both the traditional pairwise comparison and the AHP rating method to elicit the necessary judgments from these experts. The most outstanding sports records are presented, discussed and compared to Golden and Wasil’s results from a quarter century earlier. Keywords: Sports, analytics, Analytic Hierarchy Process, evaluation and ranking, expert opinion 1. Introduction considered, create a single AHP analysis for differ- ent types of records (career, season, consecutive and In 1987, Golden and Wasil (GW) applied the Ana- game), and harness the opinions of sports experts to lytic Hierarchy Process (AHP) to rank what they adjust the set of criteria and their weights and to drive considered to be “some of the greatest active sports the evaluation process. records” (Golden and Wasil, 1987). -

Tribute to Champions
HLETIC C AT OM M A IS M S O I C O A N T Tribute to Champions May 30th, 2019 McGavick Conference Center, Lakewood, WA FEATURING CONNELLY LAW OFFICES EXCELLENCE IN OFFICIATING AWARD • Boys Basketball–Mike Stephenson • Girls Basketball–Hiram “BJ” Aea • Football–Joe Horn • Soccer–Larry Baughman • Softball–Scott Buser • Volleyball–Peter Thomas • Wrestling–Chris Brayton FROSTY WESTERING EXCELLENCE IN COACHING AWARD Patty Ley, Cross Country Coach, Gig Harbor HS Paul Souza, Softball & Volleyball Coach, Washington HS FIRST FAMILY OF SPORTS AWARD The McPhee Family—Bill and Georgia (parents) and children Kathy, Diane, Scott, Colleen, Brad, Mark, Maureen, Bryce and Jim DOUG MCARTHUR LIFETIME ACHIEVEMENT AWARD Willie Stewart, Retired Lincoln HS Principal Dan Watson, Retired Lincoln HS Track Coach DICK HANNULA MALE & FEMALE AMATEUR ATHLETE OF THE YEAR AWARD Jamie Lange, Basketball and Soccer, Sumner/Univ. of Puget Sound Kaleb McGary, Football, Fife/Univ. of Washington TACOMA-PIERCE COUNTY SPORTS HALL OF FAME INDUCTEES • Baseball–Tony Barron • Basketball–Jim Black, Jennifer Gray Reiter, Tim Kelly and Bob Niehl • Bowling–Mike Karch • Boxing–Emmett Linton, Jr. and Bobby Pasquale • Football–Singor Mobley • Karate–Steve Curran p • Media–Bruce Larson (photographer) • Snowboarding–Liz Daley • Swimming–Dennis Larsen • Track and Field–Pat Tyson and Joel Wingard • Wrestling–Kylee Bishop 1 2 The Tacoma Athletic Commission—Celebrating COMMITTEE and Supporting Students and Amateur Athletics Chairman ������������������������������Marc Blau for 76 years in Pierce -

Sabermetrics: the Past, the Present, and the Future
Sabermetrics: The Past, the Present, and the Future Jim Albert February 12, 2010 Abstract This article provides an overview of sabermetrics, the science of learn- ing about baseball through objective evidence. Statistics and baseball have always had a strong kinship, as many famous players are known by their famous statistical accomplishments such as Joe Dimaggio’s 56-game hitting streak and Ted Williams’ .406 batting average in the 1941 baseball season. We give an overview of how one measures performance in batting, pitching, and fielding. In baseball, the traditional measures are batting av- erage, slugging percentage, and on-base percentage, but modern measures such as OPS (on-base percentage plus slugging percentage) are better in predicting the number of runs a team will score in a game. Pitching is a harder aspect of performance to measure, since traditional measures such as winning percentage and earned run average are confounded by the abilities of the pitcher teammates. Modern measures of pitching such as DIPS (defense independent pitching statistics) are helpful in isolating the contributions of a pitcher that do not involve his teammates. It is also challenging to measure the quality of a player’s fielding ability, since the standard measure of fielding, the fielding percentage, is not helpful in understanding the range of a player in moving towards a batted ball. New measures of fielding have been developed that are useful in measuring a player’s fielding range. Major League Baseball is measuring the game in new ways, and sabermetrics is using this new data to find better mea- sures of player performance. -
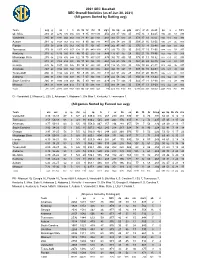
2021 SEC Baseball SEC Overall Statistics (As of Jun 30, 2021) (All Games Sorted by Batting Avg)
2021 SEC Baseball SEC Overall Statistics (as of Jun 30, 2021) (All games Sorted by Batting avg) Team avg g ab r h 2b 3b hr rbi tb slg% bb hp so gdp ob% sf sh sb-att po a e fld% Ole Miss . 2 8 8 67 2278 478 656 109 985 437 1038 . 4 5 6 295 87 570 45 . 3 8 5343 44-65 1759 453 57 . 9 7 5 Vanderbilt . 2 8 5 67 2291 454 653 130 21 92 432 1101 . 4 8 1 301 53 620 41 . 3 7 8 17 33 92-104 1794 510 65 . 9 7 3 Auburn . 2 8 1 52 1828 363 514 101 986 344 891 . 4 8 7 230 34 433 33 . 3 6 8 21 16 32-50 1390 479 45 . 9 7 6 Florida . 2 7 9 59 2019 376 563 105 13 71 351 907 . 4 4 9 262 47 497 32 . 3 7 0 30 4 32-48 1569 528 68 . 9 6 9 Tennessee . 2 7 9 68 2357 475 657 134 12 98 440 1109 . 4 7 1 336 79 573 30 . 3 8 3 27 23 72-90 1844 633 59 . 9 7 7 Kentucky . 2 7 8 52 1740 300 484 86 10 62 270 776 . 4 4 6 176 63 457 28 . 3 6 2 21 16 78-86 1353 436 39 . 9 7 9 Mississippi State . 2 7 8 68 2316 476 644 122 13 75 437 1017 . 4 3 9 306 73 455 50 . 3 7 5 31 13 74-92 1811 515 60 . -

This Week in Padres History
THIS WEEK IN PADRES HISTORY June 9, 1981 June 10, 1987 Tony Gwynn, 21, is drafted by the Former NL President Charles S. Padres in the third round of the “Chub” Feeney is named President June free agent draft. Gwynn was of the Padres. the fourth player selected by the Padres in the 1981 draft. That same day, Gwynn is drafted in the 10th round by the San Diego Clippers of the National Basketball Association. June 12, 1970 June 9, 1993 PIT’s Dock Ellis throws the first The Padres name Randy Smith no-hitter against the Padres in a their seventh general manager, 2-0 San Diego loss at San Diego replacing Joe McIlvaine. Smith, 29, Stadium. becomes the youngest general manager in Major League history. June 10, 1999 June 12, 2002 Trevor Hoffman strikes out the side RHP Brian Lawrence becomes the for his 200th save as the Padres 36th pitcher in MLB history to throw defeat Oakland 2-1 at Qualcomm an “immaculate inning,” striking out Stadium. the side on nine pitches in the third inning of the Padres’ 2-0 interleague win at Baltimore. Only one of the nine pitches was taken for a called strike. June 14, 2019 The Padres overcome a six-run deficit in the ninth for the first time in franchise history, scoring a 16-12 win @ COL in 12 innings. SS Fernando Tatis Jr. has two hits in the six-run ninth, including the game-tying, two-run single, and he later triples and scores the go-ahead run in the 12th. -

2020 MLB Ump Media Guide
the 2020 Umpire media gUide Major League Baseball and its 30 Clubs remember longtime umpires Chuck Meriwether (left) and Eric Cooper (right), who both passed away last October. During his 23-year career, Meriwether umpired over 2,500 regular season games in addition to 49 Postseason games, including eight World Series contests, and two All-Star Games. Cooper worked over 2,800 regular season games during his 24-year career and was on the feld for 70 Postseason games, including seven Fall Classic games, and one Midsummer Classic. The 2020 Major League Baseball Umpire Guide was published by the MLB Communications Department. EditEd by: Michael Teevan and Donald Muller, MLB Communications. Editorial assistance provided by: Paul Koehler. Special thanks to the MLB Umpiring Department; the National Baseball Hall of Fame and Museum; and the late David Vincent of Retrosheet.org. Photo Credits: Getty Images Sport, MLB Photos via Getty Images Sport, and the National Baseball Hall of Fame and Museum. Copyright © 2020, the offiCe of the Commissioner of BaseBall 1 taBle of Contents MLB Executive Biographies ...................................................................................................... 3 Pronunciation Guide for Major League Umpires .................................................................. 8 MLB Umpire Observers ..........................................................................................................12 Umps Care Charities .................................................................................................................14 -

The Rules of Scoring
THE RULES OF SCORING 2011 OFFICIAL BASEBALL RULES WITH CHANGES FROM LITTLE LEAGUE BASEBALL’S “WHAT’S THE SCORE” PUBLICATION INTRODUCTION These “Rules of Scoring” are for the use of those managers and coaches who want to score a Juvenile or Minor League game or wish to know how to correctly score a play or a time at bat during a Juvenile or Minor League game. These “Rules of Scoring” address the recording of individual and team actions, runs batted in, base hits and determining their value, stolen bases and caught stealing, sacrifices, put outs and assists, when to charge or not charge a fielder with an error, wild pitches and passed balls, bases on balls and strikeouts, earned runs, and the winning and losing pitcher. Unlike the Official Baseball Rules used by professional baseball and many amateur leagues, the Little League Playing Rules do not address The Rules of Scoring. However, the Little League Rules of Scoring are similar to the scoring rules used in professional baseball found in Rule 10 of the Official Baseball Rules. Consequently, Rule 10 of the Official Baseball Rules is used as the basis for these Rules of Scoring. However, there are differences (e.g., when to charge or not charge a fielder with an error, runs batted in, winning and losing pitcher). These differences are based on Little League Baseball’s “What’s the Score” booklet. Those additional rules and those modified rules from the “What’s the Score” booklet are in italics. The “What’s the Score” booklet assigns the Official Scorer certain duties under Little League Regulation VI concerning pitching limits which have not implemented by the IAB (see Juvenile League Rule 12.08.08). -

MLB Statistics Feeds
Updated 07.17.17 MLB Statistics Feeds 2017 Season 1 SPORTRADAR MLB STATISTICS FEEDS Updated 07.17.17 Table of Contents Overview ....................................................................................................................... Error! Bookmark not defined. MLB Statistics Feeds.................................................................................................................................................. 3 Coverage Levels........................................................................................................................................................... 4 League Information ..................................................................................................................................................... 5 Team & Staff Information .......................................................................................................................................... 7 Player Information ....................................................................................................................................................... 9 Venue Information .................................................................................................................................................... 13 Injuries & Transactions Information ................................................................................................................... 16 Game & Series Information .................................................................................................................................. -

Chadwick Documentation Release 0.9.0
Chadwick Documentation Release 0.9.0 T. L. Turocy Jan 04, 2021 Contents 1 Introduction 1 2 Command-line tools 3 i ii CHAPTER 1 Introduction Chadwick is a collection of command-line utility programs for extracting information from baseball play-by-play and boxscore files in the DiamondWare format, as used by Retrosheet (http://www.retrosheet.org). 1.1 Author Chadwick is written, maintained, and Copyright 2002-2020 by Dr T. L. Turocy (ted.turocy <aht> gmail <daht> com) at Chadwick Baseball Bureau (http://www.chadwick-bureau.com). 1.2 License Chadwick is licensed under the terms of the GNU General Public License. If the GPL doesn’t meet your needs, contact the author for other licensing possibilities. 1.3 Development The Chadwick source code is managed using git, at https://github.com/chadwickbureau/chadwick. Bugs in Chadwick should be reported to the issue tracker on github at https://github.com/chadwickbureau/chadwick/ issues. Please be as specific as possible in reporting a bug, including the version of Chadwick you are using, the operating system(s) you’re using, and a detailed list of steps to reproduce the issue. 1.4 Community To get the latest news on the Chadwick tool suite, you can: • Subscribe to the Chadwick Baseball Bureau’s twitter feed (@chadwickbureau); 1 Chadwick Documentation, Release 0.9.0 • Like the Chadwick Baseball Bureau on Facebook; • Read the Chadwick Baseball Bureau’s blog at (http://www.chadwick-bureau.com/blog/) 1.5 Acknowledgments The author thanks Sports Reference, LLC, the Society for American Baseball Research, and XMLTeam, Inc. -

Does Sabermetrics Have a Place in Amateur Baseball?
BaseballGB Full Article Does sabermetrics have a place in amateur baseball? Joe Gray 7 March 2009 he term “sabermetrics” is one of the many The term sabermetrics combines SABR (the acronym creations of Bill James, the great baseball for the Society for American Baseball Research) and theoretician (for details of the term’s metrics (numerical measurements). The extra “e” T was presumably added to avoid the difficult-to- derivation and usage see Box 1). Several tight pronounce sequence of letters “brm”. An alternative definitions exist for the term, but I feel that rather exists without the “e”, but in this the first four than presenting one or more of these it is more letters are capitalized to show that it is a word to valuable to offer an alternative, looser definition: which normal rules of pronunciation do not apply. sabermetrics is a tree of knowledge with its roots in It is a singular noun despite the “s” at the end (that is, you would say “sabermetrics is growing in the philosophy of answering baseball questions in as popularity” rather than “sabermetrics are growing in accurate, objective, and meaningful a fashion as popularity”). possible. The philosophy is an alternative to The adjective sabermetric has been back-derived from the term and is exemplified by “a sabermetric accepting traditional thinking without question. tool”, or its plural “sabermetric tools”. The adverb sabermetrically, built on that back- Branches of the sabermetric tree derived adjective, is illustrated in the phrase “she The metaphor of sabermetrics as a tree extends to approached the problem sabermetrically”. describing the various broad concepts and themes of The noun sabermetrician can be used to describe any practitioner of sabermetrics, although to some research as branches. -

"What Raw Statistics Have the Greatest Effect on Wrc+ in Major League Baseball in 2017?" Gavin D
1 "What raw statistics have the greatest effect on wRC+ in Major League Baseball in 2017?" Gavin D. Sanford University of Minnesota Duluth Honors Capstone Project 2 Abstract Major League Baseball has different statistics for hitters, fielders, and pitchers. The game has followed the same rules for over a century and this has allowed for statistical comparison. As technology grows, so does the game of baseball as there is more areas of the game that people can monitor and track including pitch speed, spin rates, launch angle, exit velocity and directional break. The website QOPBaseball.com is a newer website that attempts to correctly track every pitches horizontal and vertical break and grade it based on these factors (Wilson, 2016). Fangraphs has statistics on the direction players hit the ball and what percentage of the time. The game of baseball is all about quantifying players and being able give a value to their contributions. Sabermetrics have given us the ability to do this in far more depth. Weighted Runs Created Plus (wRC+) is an offensive stat which is attempted to quantify a player’s total offensive value (wRC and wRC+, Fangraphs). It is Era and park adjusted, meaning that the park and year can be compared without altering the statistic further. In this paper, we look at what 2018 statistics have the greatest effect on an individual player’s wRC+. Keywords: Sabermetrics, Econometrics, Spin Rates, Baseball, Introduction Major League Baseball has been around for over a century has given awards out for almost 100 years. The way that these awards are given out is based on statistics accumulated over the season. -

MEDIA GUIDE 2019 Triple-A Affiliate of the Seattle Mariners
MEDIA GUIDE 2019 Triple-A Affiliate of the Seattle Mariners TACOMA RAINIERS BASEBALL tacomarainiers.com CHENEY STADIUM /TacomaRainiers 2502 S. Tyler Street Tacoma, WA 98405 @RainiersLand Phone: 253.752.7707 tacomarainiers Fax: 253.752.7135 2019 TACOMA RAINIERS MEDIA GUIDE TABLE OF CONTENTS Front Office/Contact Info .......................................................................................................................................... 5 Cheney Stadium .....................................................................................................................................................6-9 Coaching Staff ....................................................................................................................................................10-14 2019 Tacoma Rainiers Players ...........................................................................................................................15-76 2018 Season Review ........................................................................................................................................77-106 League Leaders and Final Standings .........................................................................................................78-79 Team Batting/Pitching/Fielding Summary ..................................................................................................80-81 Monthly Batting/Pitching Totals ..................................................................................................................82-85 Situational