Standards MPEG-4
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Microsoft Office Open XML Formats New File Formats for “Office 12”
The Microsoft Office Open XML Formats New File Formats for “Office 12” White Paper Published: June 2005 For the latest information, please see http://www.microsoft.com/office/wave12 Contents Introduction ...............................................................................................................................1 From .doc to .docx: a brief history of the Office file formats.................................................1 Benefits of the Microsoft Office Open XML Formats ................................................................2 Integration with Business Data .............................................................................................2 Openness and Transparency ...............................................................................................4 Robustness...........................................................................................................................7 Description of the Microsoft Office Open XML Format .............................................................9 Document Parts....................................................................................................................9 Microsoft Office Open XML Format specifications ...............................................................9 Compatibility with new file formats........................................................................................9 For more information ..............................................................................................................10 -

Why ODF?” - the Importance of Opendocument Format for Governments
“Why ODF?” - The Importance of OpenDocument Format for Governments Documents are the life blood of modern governments and their citizens. Governments use documents to capture knowledge, store critical information, coordinate activities, measure results, and communicate across departments and with businesses and citizens. Increasingly documents are moving from paper to electronic form. To adapt to ever-changing technology and business processes, governments need assurance that they can access, retrieve and use critical records, now and in the future. OpenDocument Format (ODF) addresses these issues by standardizing file formats to give governments true control over their documents. Governments using applications that support ODF gain increased efficiencies, more flexibility and greater technology choice, leading to enhanced capability to communicate with and serve the public. ODF is the ISO Approved International Open Standard for File Formats ODF is the only open standard for office applications, and it is completely vendor neutral. Developed through a transparent, multi-vendor/multi-stakeholder process at OASIS (Organization for the Advancement of Structured Information Standards), it is an open, XML- based document file format for displaying, storing and editing office documents, such as spreadsheets, charts, and presentations. It is available for implementation and use free from any licensing, royalty payments, or other restrictions. In May 2006, it was approved unanimously as an International Organization for Standardization (ISO) and International Electrotechnical Commission (IEC) standard. Governments and Businesses are Embracing ODF The promotion and usage of ODF is growing rapidly, demonstrating the global need for control and choice in document applications. For example, many enlightened governments across the globe are making policy decisions to move to ODF. -

MPEG-21 Overview
MPEG-21 Overview Xin Wang Dept. Computer Science, University of Southern California Workshop on New Multimedia Technologies and Applications, Xi’An, China October 31, 2009 Agenda ● What is MPEG-21 ● MPEG-21 Standards ● Benefits ● An Example Page 2 Workshop on New Multimedia Technologies and Applications, Oct. 2009, Xin Wang MPEG Standards ● MPEG develops standards for digital representation of audio and visual information ● So far ● MPEG-1: low resolution video/stereo audio ● E.g., Video CD (VCD) and Personal music use (MP3) ● MPEG-2: digital television/multichannel audio ● E.g., Digital recording (DVD) ● MPEG-4: generic video and audio coding ● E.g., MP4, AVC (H.24) ● MPEG-7 : visual, audio and multimedia descriptors MPEG-21: multimedia framework ● MPEG-A: multimedia application format ● MPEG-B, -C, -D: systems, video and audio standards ● MPEG-M: Multimedia Extensible Middleware ● ● MPEG-V: virtual worlds MPEG-U: UI ● (29116): Supplemental Media Technologies ● ● (Much) more to come … Page 3 Workshop on New Multimedia Technologies and Applications, Oct. 2009, Xin Wang What is MPEG-21? ● An open framework for multimedia delivery and consumption ● History: conceived in 1999, first few parts ready early 2002, most parts done by now, some amendment and profiling works ongoing ● Purpose: enable all-electronic creation, trade, delivery, and consumption of digital multimedia content ● Goals: ● “Transparent” usage ● Interoperable systems ● Provides normative methods for: ● Content identification and description Rights management and protection ● Adaptation of content ● Processing on and for the various elements of the content ● ● Evaluation methods for determining the appropriateness of possible persistent association of information ● etc. Page 4 Workshop on New Multimedia Technologies and Applications, Oct. -

Javascript and the DOM
Javascript and the DOM 1 Introduzione alla programmazione web – Marco Ronchetti 2020 – Università di Trento The web architecture with smart browser The web programmer also writes Programs which run on the browser. Which language? Javascript! HTTP Get + params File System Smart browser Server httpd Cgi-bin Internet Query SQL Client process DB Data Evolution 3: execute code also on client! (How ?) Javascript and the DOM 1- Adding dynamic behaviour to HTML 3 Introduzione alla programmazione web – Marco Ronchetti 2020 – Università di Trento Example 1: onmouseover, onmouseout <!DOCTYPE html> <html> <head> <title>Dynamic behaviour</title> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> </head> <body> <div onmouseover="this.style.color = 'red'" onmouseout="this.style.color = 'green'"> I can change my colour!</div> </body> </html> JAVASCRIPT The dynamic behaviour is on the client side! (The file can be loaded locally) <body> <div Example 2: onmouseover, onmouseout onmouseover="this.style.background='orange'; this.style.color = 'blue';" onmouseout=" this.innerText='and my text and position too!'; this.style.position='absolute'; this.style.left='100px’; this.style.top='150px'; this.style.borderStyle='ridge'; this.style.borderColor='blue'; this.style.fontSize='24pt';"> I can change my colour... </div> </body > JavaScript is event-based UiEvents: These event objects iherits the properties of the UiEvent: • The FocusEvent • The InputEvent • The KeyboardEvent • The MouseEvent • The TouchEvent • The WheelEvent See https://www.w3schools.com/jsref/obj_uievent.asp Test and Gym JAVASCRIPT HTML HEAD HTML BODY CSS https://www.jdoodle.com/html-css-javascript-online-editor/ Javascript and the DOM 2- Introduction to the language 8 Introduzione alla programmazione web – Marco Ronchetti 2020 – Università di Trento JavaScript History • JavaScript was born as Mocha, then “LiveScript” at the beginning of the 94’s. -

Quadtree Based JBIG Compression
Quadtree Based JBIG Compression B. Fowler R. Arps A. El Gamal D. Yang ISL, Stanford University, Stanford, CA 94305-4055 ffowler,arps,abbas,[email protected] Abstract A JBIG compliant, quadtree based, lossless image compression algorithm is describ ed. In terms of the numb er of arithmetic co ding op erations required to co de an image, this algorithm is signi cantly faster than previous JBIG algorithm variations. Based on this criterion, our algorithm achieves an average sp eed increase of more than 9 times with only a 5 decrease in compression when tested on the eight CCITT bi-level test images and compared against the basic non-progressive JBIG algorithm. The fastest JBIG variation that we know of, using \PRES" resolution reduction and progressive buildup, achieved an average sp eed increase of less than 6 times with a 7 decrease in compression, under the same conditions. 1 Intro duction In facsimile applications it is desirable to integrate a bilevel image sensor with loss- less compression on the same chip. Suchintegration would lower p ower consumption, improve reliability, and reduce system cost. To reap these b ene ts, however, the se- lection of the compression algorithm must takeinto consideration the implementation tradeo s intro duced byintegration. On the one hand, integration enhances the p os- sibility of parallelism which, if prop erly exploited, can sp eed up compression. On the other hand, the compression circuitry cannot b e to o complex b ecause of limitations on the available chip area. Moreover, most of the chip area on a bilevel image sensor must b e o ccupied by photo detectors, leaving only the edges for digital logic. -

MSD FATFS Users Guide
Freescale MSD FATFS Users Guide Document Number: MSDFATFSUG Rev. 0 02/2011 How to Reach Us: Home Page: www.freescale.com E-mail: [email protected] USA/Europe or Locations Not Listed: Freescale Semiconductor Technical Information Center, CH370 1300 N. Alma School Road Chandler, Arizona 85224 +1-800-521-6274 or +1-480-768-2130 [email protected] Europe, Middle East, and Africa: Information in this document is provided solely to enable system and Freescale Halbleiter Deutschland GmbH software implementers to use Freescale Semiconductor products. There are Technical Information Center no express or implied copyright licenses granted hereunder to design or Schatzbogen 7 fabricate any integrated circuits or integrated circuits based on the 81829 Muenchen, Germany information in this document. +44 1296 380 456 (English) +46 8 52200080 (English) Freescale Semiconductor reserves the right to make changes without further +49 89 92103 559 (German) notice to any products herein. Freescale Semiconductor makes no warranty, +33 1 69 35 48 48 (French) representation or guarantee regarding the suitability of its products for any particular purpose, nor does Freescale Semiconductor assume any liability [email protected] arising out of the application or use of any product or circuit, and specifically disclaims any and all liability, including without limitation consequential or Japan: incidental damages. “Typical” parameters that may be provided in Freescale Freescale Semiconductor Japan Ltd. Semiconductor data sheets and/or specifications can and do vary in different Headquarters applications and actual performance may vary over time. All operating ARCO Tower 15F parameters, including “Typicals”, must be validated for each customer 1-8-1, Shimo-Meguro, Meguro-ku, application by customer’s technical experts. -

OSLC Architecture Management Specification 3.0 Project Specification Draft 01 17 September 2020
Standards Track Work Product OSLC Architecture Management Specification 3.0 Project Specification Draft 01 17 September 2020 This stage: https://docs.oasis-open-projects.org/oslc-op/am/v3.0/psd01/architecture-management-spec.html (Authoritative) https://docs.oasis-open-projects.org/oslc-op/am/v3.0/psd01/architecture-management-spec.pdf Previous stage: N/A Latest stage: https://docs.oasis-open-projects.org/oslc-op/am/v3.0/architecture-management-spec.html (Authoritative) https://docs.oasis-open-projects.org/oslc-op/am/v3.0/architecture-management-spec.pdf Latest version: https://open-services.net/spec/am/latest Latest editor's draft: https://open-services.net/spec/am/latest-draft Open Project: OASIS Open Services for Lifecycle Collaboration (OSLC) OP Project Chairs: Jim Amsden ([email protected]), IBM Andrii Berezovskyi ([email protected]), KTH Editor: Jim Amsden ([email protected]), IBM Additional components: This specification is one component of a Work Product that also includes: OSLC Architecture Management Version 3.0. Part 1: Specification (this document). architecture-management- spec.html OSLC Architecture Management Version 3.0. Part 2: Vocabulary. architecture-management-vocab.html OSLC Architecture Management Version 3.0. Part 3: Constraints. architecture-management-shapes.html OSLC Architecture Management Version 3.0. Machine Readable Vocabulary Terms. architecture-management- vocab.ttl OSLC Architecture Management Version 3.0. Machine Readable Constraints. architecture-management-shapes.ttl architecture-management-spec Copyright © OASIS Open 2020. All Rights Reserved. 17 September 2020 - Page 1 of 19 Standards Track Work Product Related work: This specification is related to: OSLC Architecture Management Specification Version 2.0. -

OASIS CGM Open Webcgm V2.1
WebCGM Version 2.1 OASIS Standard 01 March 2010 Specification URIs: This Version: XHTML multi-file: http://docs.oasis-open.org/webcgm/v2.1/os/webcgm-v2.1-index.html (AUTHORITATIVE) PDF: http://docs.oasis-open.org/webcgm/v2.1/os/webcgm-v2.1.pdf XHTML ZIP archive: http://docs.oasis-open.org/webcgm/v2.1/os/webcgm-v2.1.zip Previous Version: XHTML multi-file: http://docs.oasis-open.org/webcgm/v2.1/cs02/webcgm-v2.1-index.html (AUTHORITATIVE) PDF: http://docs.oasis-open.org/webcgm/v2.1/cs02/webcgm-v2.1.pdf XHTML ZIP archive: http://docs.oasis-open.org/webcgm/v2.1/cs02/webcgm-v2.1.zip Latest Version: XHTML multi-file: http://docs.oasis-open.org/webcgm/v2.1/latest/webcgm-v2.1-index.html PDF: http://docs.oasis-open.org/webcgm/v2.1/latest/webcgm-v2.1.pdf XHTML ZIP archive: http://docs.oasis-open.org/webcgm/v2.1/latest/webcgm-v2.1.zip Declared XML namespaces: http://www.cgmopen.org/schema/webcgm/ System Identifier: http://docs.oasis-open.org/webcgm/v2.1/webcgm21.dtd Technical Committee: OASIS CGM Open WebCGM TC Chair(s): Stuart Galt, The Boeing Company Editor(s): Benoit Bezaire, PTC Lofton Henderson, Individual Related Work: This specification updates: WebCGM 2.0 OASIS Standard (and W3C Recommendation) This specification, when completed, will be identical in technical content to: WebCGM 2.1 W3C Recommendation, available at http://www.w3.org/TR/webcgm21/. Abstract: Computer Graphics Metafile (CGM) is an ISO standard, defined by ISO/IEC 8632:1999, for the interchange of 2D vector and mixed vector/raster graphics. -

Towards the Second Edition of ISO 24707 Common Logic
Towards the Second Edition of ISO 24707 Common Logic Michael Gr¨uninger(with Tara Athan and Fabian Neuhaus) Miniseries on Ontologies, Rules, and Logic Programming for Reasoning and Applications January 9, 2014 Gr¨uninger ( Ontolog Forum) Common Logic (ISO 24707) January 9, 2014 1 / 20 What Is Common Logic? Common Logic (published as \ISO/IEC 24707:2007 | Information technology Common Logic : a framework for a family of logic-based languages") is a language based on first-order logic, but extending it in several ways that ease the formulation of complex ontologies that are definable in first-order logic. Gr¨uninger ( Ontolog Forum) Common Logic (ISO 24707) January 9, 2014 2 / 20 Semantics An interpretation I consists of a set URI , the universe of reference a set UDI , the universe of discourse, such that I UDI 6= ;; I UDI ⊆ URI ; a mapping intI : V ! URI ; ∗ a mapping relI from URI to subsets of UDI . Gr¨uninger ( Ontolog Forum) Common Logic (ISO 24707) January 9, 2014 3 / 20 How Is Common Logic Being Used? Open Ontology Repositories COLORE (Common Logic Ontology Repository) colore.oor.net stl.mie.utoronto.ca/colore/ontologies.html OntoHub www.ontohub.org https://github.com/ontohub/ontohub Gr¨uninger ( Ontolog Forum) Common Logic (ISO 24707) January 9, 2014 4 / 20 How Is Common Logic Being Used? Ontology-based Standards Process Specification Language (ISO 18629) Date-Time Vocabulary (OMG) Foundational UML (OMG) Semantic Web Services Framework (W3C) OntoIOp (ISO WD 17347) Gr¨uninger ( Ontolog Forum) Common Logic (ISO 24707) January 9, 2014 -
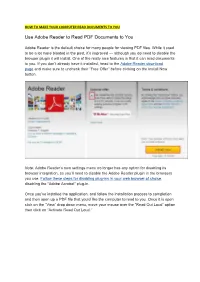
Use Adobe Reader to Read PDF Documents to You
HOW TO MAKE YOUR COMPUTER READ DOCUMENTS TO YOU Use Adobe Reader to Read PDF Documents to You Adobe Reader is the default choice for many people for viewing PDF files. While it used to be a lot more bloated in the past, it’s improved — although you do need to disable the browser plugin it will install. One of the really nice features is that it can read documents to you. If you don’t already have it installed, head to the Adobe Reader download page and make sure to uncheck their “Free Offer” before clicking on the Install Now button. Note: Adobe Reader’s own settings menu no longer has any option for disabling its browser integration, so you’ll need to disable the Adobe Reader plugin in the browsers you use. Follow these steps for disabling plug-ins in your web browser of choice, disabling the “Adobe Acrobat” plug-in. Once you’ve installed the application, and follow the installation process to completion and then open up a PDF file that you’d like the computer to read to you. Once it is open click on the “View” drop down menu, move your mouse over the “Read Out Loud” option then click on “Activate Read Out Loud.” Alternatively, you can click “Ctrl,” “Shift,” and “Y” (Ctrl+Shift+Y) on your keyboard to activate the feature. Once the feature is activated, you can click on a single paragraph to make windows read it back to you. Another option would be to navigate to the “View” menu, then “Read Out Loud” and select an option that fits your needs as shown in the Image below. -

APL Literature Review
APL Literature Review Roy E. Lowrance February 22, 2009 Contents 1 Falkoff and Iverson-1968: APL1 3 2 IBM-1994: APL2 8 2.1 APL2 Highlights . 8 2.2 APL2 Primitive Functions . 12 2.3 APL2 Operators . 18 2.4 APL2 Concurrency Features . 19 3 Dyalog-2008: Dyalog APL 20 4 Iverson-1987: Iverson's Dictionary for APL 21 5 APL Implementations 21 5.1 Saal and Weiss-1975: Static Analysis of APL1 Programs . 21 5.2 Breed and Lathwell-1968: Implementation of the Original APLn360 25 5.3 Falkoff and Orth-1979: A BNF Grammar for APL1 . 26 5.4 Girardo and Rollin-1987: Parsing APL with Yacc . 27 5.5 Tavera and other-1987, 1998: IL . 27 5.6 Brown-1995: Rationale for APL2 Syntax . 29 5.7 Abrams-1970: An APL Machine . 30 5.8 Guibas and Wyatt-1978: Optimizing Interpretation . 31 5.9 Weiss and Saal-1981: APL Syntax Analysis . 32 5.10 Weigang-1985: STSC's APL Compiler . 33 5.11 Ching-1986: APL/370 Compiler . 33 5.12 Ching and other-1989: APL370 Prototype Compiler . 34 5.13 Driscoll and Orth-1986: Compile APL2 to FORTRAN . 35 5.14 Grelck-1999: Compile APL to Single Assignment C . 36 6 Imbed APL in Other Languages 36 6.1 Burchfield and Lipovaca-2002: APL Arrays in Java . 36 7 Extensions to APL 37 7.1 Brown and Others-2000: Object-Oriented APL . 37 1 8 APL on Parallel Computers 38 8.1 Willhoft-1991: Most APL2 Primitives Can Be Parallelized . 38 8.2 Bernecky-1993: APL Can Be Parallelized . -

Iso/Iec 14496-14
INTERNATIONAL ISO/IEC STANDARD 14496-14 First edition 2003-11-15 Information technology — Coding of audio-visual objects — Part 14: MP4 file format Technologies de l'information — Codage des objets audiovisuels — Partie 14: Format de fichier MP4 Reference number ISO/IEC 14496-14:2003(E) Licensed to WIMOBILIS DIGITAL TECHNOLOGIES/MARCOS MANENTE ISO Store order #:850777/Downloaded:2007-09-27 Single user licence only, copying and networking prohibited © ISO/IEC 2003 ISO/IEC 14496-14:2003(E) PDF disclaimer This PDF file may contain embedded typefaces. In accordance with Adobe's licensing policy, this file may be printed or viewed but shall not be edited unless the typefaces which are embedded are licensed to and installed on the computer performing the editing. In downloading this file, parties accept therein the responsibility of not infringing Adobe's licensing policy. The ISO Central Secretariat accepts no liability in this area. Adobe is a trademark of Adobe Systems Incorporated. Details of the software products used to create this PDF file can be found in the General Info relative to the file; the PDF-creation parameters were optimized for printing. Every care has been taken to ensure that the file is suitable for use by ISO member bodies. In the unlikely event that a problem relating to it is found, please inform the Central Secretariat at the address given below. © ISO/IEC 2003 All rights reserved. Unless otherwise specified, no part of this publication may be reproduced or utilized in any form or by any means, electronic or mechanical, including photocopying and microfilm, without permission in writing from either ISO at the address below or ISO's member body in the country of the requester.