Overview of the MPEG 4 Standard
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Microsoft Office Open XML Formats New File Formats for “Office 12”
The Microsoft Office Open XML Formats New File Formats for “Office 12” White Paper Published: June 2005 For the latest information, please see http://www.microsoft.com/office/wave12 Contents Introduction ...............................................................................................................................1 From .doc to .docx: a brief history of the Office file formats.................................................1 Benefits of the Microsoft Office Open XML Formats ................................................................2 Integration with Business Data .............................................................................................2 Openness and Transparency ...............................................................................................4 Robustness...........................................................................................................................7 Description of the Microsoft Office Open XML Format .............................................................9 Document Parts....................................................................................................................9 Microsoft Office Open XML Format specifications ...............................................................9 Compatibility with new file formats........................................................................................9 For more information ..............................................................................................................10 -

Why ODF?” - the Importance of Opendocument Format for Governments
“Why ODF?” - The Importance of OpenDocument Format for Governments Documents are the life blood of modern governments and their citizens. Governments use documents to capture knowledge, store critical information, coordinate activities, measure results, and communicate across departments and with businesses and citizens. Increasingly documents are moving from paper to electronic form. To adapt to ever-changing technology and business processes, governments need assurance that they can access, retrieve and use critical records, now and in the future. OpenDocument Format (ODF) addresses these issues by standardizing file formats to give governments true control over their documents. Governments using applications that support ODF gain increased efficiencies, more flexibility and greater technology choice, leading to enhanced capability to communicate with and serve the public. ODF is the ISO Approved International Open Standard for File Formats ODF is the only open standard for office applications, and it is completely vendor neutral. Developed through a transparent, multi-vendor/multi-stakeholder process at OASIS (Organization for the Advancement of Structured Information Standards), it is an open, XML- based document file format for displaying, storing and editing office documents, such as spreadsheets, charts, and presentations. It is available for implementation and use free from any licensing, royalty payments, or other restrictions. In May 2006, it was approved unanimously as an International Organization for Standardization (ISO) and International Electrotechnical Commission (IEC) standard. Governments and Businesses are Embracing ODF The promotion and usage of ODF is growing rapidly, demonstrating the global need for control and choice in document applications. For example, many enlightened governments across the globe are making policy decisions to move to ODF. -
Adaptive Quantization Matrices for High Definition Resolutions in Scalable HEVC
Original citation: Prangnell, Lee and Sanchez Silva, Victor (2016) Adaptive quantization matrices for HD and UHD display resolutions in scalable HEVC. In: IEEE Data Compression Conference, Utah, United States, 31 Mar - 01 Apr 2016 Permanent WRAP URL: http://wrap.warwick.ac.uk/73957 Copyright and reuse: The Warwick Research Archive Portal (WRAP) makes this work by researchers of the University of Warwick available open access under the following conditions. Copyright © and all moral rights to the version of the paper presented here belong to the individual author(s) and/or other copyright owners. To the extent reasonable and practicable the material made available in WRAP has been checked for eligibility before being made available. Copies of full items can be used for personal research or study, educational, or not-for profit purposes without prior permission or charge. Provided that the authors, title and full bibliographic details are credited, a hyperlink and/or URL is given for the original metadata page and the content is not changed in any way. Publisher’s statement: © 2016 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting /republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works. A note on versions: The version presented here may differ from the published version or, version of record, if you wish to cite this item you are advised to consult the publisher’s version. -

Dell 24 USB-C Monitor - P2421DC User’S Guide
Dell 24 USB-C Monitor - P2421DC User’s Guide Monitor Model: P2421DC Regulatory Model: P2421DCc NOTE: A NOTE indicates important information that helps you make better use of your computer. CAUTION: A CAUTION indicates potential damage to hardware or loss of data if instructions are not followed. WARNING: A WARNING indicates a potential for property damage, personal injury, or death. Copyright © 2020 Dell Inc. or its subsidiaries. All rights reserved. Dell, EMC, and other trademarks are trademarks of Dell Inc. or its subsidiaries. Other trademarks may be trademarks of their respective owners. 2020 – 03 Rev. A01 Contents About your monitor ......................... 6 Package contents . 6 Product features . .8 Identifying parts and controls . .9 Front view . .9 Back view . 10 Side view. 11 Bottom view . .12 Monitor specifications . 13 Resolution specifications . 14 Supported video modes . 15 Preset display modes . 15 MST Multi-Stream Transport (MST) Modes . 16 Electrical specifications. 16 Physical characteristics. 17 Environmental characteristics . 18 Power management modes . 19 Plug and play capability . 25 LCD monitor quality and pixel policy . 25 Maintenance guidelines . 25 Cleaning your monitor. .25 Setting up the monitor...................... 26 Attaching the stand . 26 │ 3 Connecting your monitor . 28 Connecting the DP cable . 28 Connecting the monitor for DP Multi-Stream Transport (MST) function . 28 Connecting the USB Type-C cable . 29 Connecting the monitor for USB-C Multi-Stream Transport (MST) function. 30 Organizing cables . 31 Removing the stand . 32 Wall mounting (optional) . 33 Operating your monitor ..................... 34 Power on the monitor . 34 USB-C charging options . 35 Using the control buttons . 35 OSD controls . 36 Using the On-Screen Display (OSD) menu . -

MPEG-21 Overview
MPEG-21 Overview Xin Wang Dept. Computer Science, University of Southern California Workshop on New Multimedia Technologies and Applications, Xi’An, China October 31, 2009 Agenda ● What is MPEG-21 ● MPEG-21 Standards ● Benefits ● An Example Page 2 Workshop on New Multimedia Technologies and Applications, Oct. 2009, Xin Wang MPEG Standards ● MPEG develops standards for digital representation of audio and visual information ● So far ● MPEG-1: low resolution video/stereo audio ● E.g., Video CD (VCD) and Personal music use (MP3) ● MPEG-2: digital television/multichannel audio ● E.g., Digital recording (DVD) ● MPEG-4: generic video and audio coding ● E.g., MP4, AVC (H.24) ● MPEG-7 : visual, audio and multimedia descriptors MPEG-21: multimedia framework ● MPEG-A: multimedia application format ● MPEG-B, -C, -D: systems, video and audio standards ● MPEG-M: Multimedia Extensible Middleware ● ● MPEG-V: virtual worlds MPEG-U: UI ● (29116): Supplemental Media Technologies ● ● (Much) more to come … Page 3 Workshop on New Multimedia Technologies and Applications, Oct. 2009, Xin Wang What is MPEG-21? ● An open framework for multimedia delivery and consumption ● History: conceived in 1999, first few parts ready early 2002, most parts done by now, some amendment and profiling works ongoing ● Purpose: enable all-electronic creation, trade, delivery, and consumption of digital multimedia content ● Goals: ● “Transparent” usage ● Interoperable systems ● Provides normative methods for: ● Content identification and description Rights management and protection ● Adaptation of content ● Processing on and for the various elements of the content ● ● Evaluation methods for determining the appropriateness of possible persistent association of information ● etc. Page 4 Workshop on New Multimedia Technologies and Applications, Oct. -

Quadtree Based JBIG Compression
Quadtree Based JBIG Compression B. Fowler R. Arps A. El Gamal D. Yang ISL, Stanford University, Stanford, CA 94305-4055 ffowler,arps,abbas,[email protected] Abstract A JBIG compliant, quadtree based, lossless image compression algorithm is describ ed. In terms of the numb er of arithmetic co ding op erations required to co de an image, this algorithm is signi cantly faster than previous JBIG algorithm variations. Based on this criterion, our algorithm achieves an average sp eed increase of more than 9 times with only a 5 decrease in compression when tested on the eight CCITT bi-level test images and compared against the basic non-progressive JBIG algorithm. The fastest JBIG variation that we know of, using \PRES" resolution reduction and progressive buildup, achieved an average sp eed increase of less than 6 times with a 7 decrease in compression, under the same conditions. 1 Intro duction In facsimile applications it is desirable to integrate a bilevel image sensor with loss- less compression on the same chip. Suchintegration would lower p ower consumption, improve reliability, and reduce system cost. To reap these b ene ts, however, the se- lection of the compression algorithm must takeinto consideration the implementation tradeo s intro duced byintegration. On the one hand, integration enhances the p os- sibility of parallelism which, if prop erly exploited, can sp eed up compression. On the other hand, the compression circuitry cannot b e to o complex b ecause of limitations on the available chip area. Moreover, most of the chip area on a bilevel image sensor must b e o ccupied by photo detectors, leaving only the edges for digital logic. -

Detectability Model for the Evaluation of Lossy Compression Methods on Radiographic Images Vivek Ramaswami Iowa State University
Iowa State University Capstones, Theses and Retrospective Theses and Dissertations Dissertations 1996 Detectability model for the evaluation of lossy compression methods on radiographic images Vivek Ramaswami Iowa State University Follow this and additional works at: https://lib.dr.iastate.edu/rtd Part of the Electrical and Electronics Commons Recommended Citation Ramaswami, Vivek, "Detectability model for the evaluation of lossy compression methods on radiographic images" (1996). Retrospective Theses and Dissertations. 250. https://lib.dr.iastate.edu/rtd/250 This Thesis is brought to you for free and open access by the Iowa State University Capstones, Theses and Dissertations at Iowa State University Digital Repository. It has been accepted for inclusion in Retrospective Theses and Dissertations by an authorized administrator of Iowa State University Digital Repository. For more information, please contact [email protected]. Detectability model for the evaluation of lossy compression methods on radiographic images by Vivek Ramaswami A thesis submitted to the graduate faculty in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE Major: Electrical Engineering Major Professors: Satish S. Udpa and Joseph N. Gray Iowa State University Ames, Iowa 1996 Copyright © Vivek Ramaswami, 1996. All rights reserved. 11 Graduate College Iowa State University This is to certify that the Master's thesis of Vivek Ramaswami has met the t hesis requirements of Iowa State University Signature redacted for privacy 111 TABLE OF CONTENTS ACKNOWLEDGEMENTS IX 1 INTRODUCTION . 1 2 IMAGE COMPRESSION METHODS 5 201 Introduction o 0 0 0 0 0 5 2o2 Vector quantization 0 0 ..... 5 20201 Classified vector quantizer 6 20202 Coding of shade blocks o ..... -

OASIS CGM Open Webcgm V2.1
WebCGM Version 2.1 OASIS Standard 01 March 2010 Specification URIs: This Version: XHTML multi-file: http://docs.oasis-open.org/webcgm/v2.1/os/webcgm-v2.1-index.html (AUTHORITATIVE) PDF: http://docs.oasis-open.org/webcgm/v2.1/os/webcgm-v2.1.pdf XHTML ZIP archive: http://docs.oasis-open.org/webcgm/v2.1/os/webcgm-v2.1.zip Previous Version: XHTML multi-file: http://docs.oasis-open.org/webcgm/v2.1/cs02/webcgm-v2.1-index.html (AUTHORITATIVE) PDF: http://docs.oasis-open.org/webcgm/v2.1/cs02/webcgm-v2.1.pdf XHTML ZIP archive: http://docs.oasis-open.org/webcgm/v2.1/cs02/webcgm-v2.1.zip Latest Version: XHTML multi-file: http://docs.oasis-open.org/webcgm/v2.1/latest/webcgm-v2.1-index.html PDF: http://docs.oasis-open.org/webcgm/v2.1/latest/webcgm-v2.1.pdf XHTML ZIP archive: http://docs.oasis-open.org/webcgm/v2.1/latest/webcgm-v2.1.zip Declared XML namespaces: http://www.cgmopen.org/schema/webcgm/ System Identifier: http://docs.oasis-open.org/webcgm/v2.1/webcgm21.dtd Technical Committee: OASIS CGM Open WebCGM TC Chair(s): Stuart Galt, The Boeing Company Editor(s): Benoit Bezaire, PTC Lofton Henderson, Individual Related Work: This specification updates: WebCGM 2.0 OASIS Standard (and W3C Recommendation) This specification, when completed, will be identical in technical content to: WebCGM 2.1 W3C Recommendation, available at http://www.w3.org/TR/webcgm21/. Abstract: Computer Graphics Metafile (CGM) is an ISO standard, defined by ISO/IEC 8632:1999, for the interchange of 2D vector and mixed vector/raster graphics. -

EN User Manual 1 Customer Care and Warranty 28 Troubleshooting & Faqs 32 Table of Contents
499P9 www.philips.com/welcome EN User manual 1 Customer care and warranty 28 Troubleshooting & FAQs 32 Table of Contents 1. Important ...................................... 1 1.1 Safety precautions and maintenance ................................. 1 1.2 Notational Descriptions ............ 3 1.3 Disposal of product and packing material .......................................... 4 2. Setting up the monitor .............. 5 2.1 Installation .................................... 5 2.2 Operating the monitor .............. 9 2.3 Built-in Windows Hello™ pop- up webcam .................................14 2.4 MultiClient Integrated KVM .....16 2.5 MultiView ..................................... 17 2.6 Remove the Base Assembly for VESA Mounting ..........................18 3. Image Optimization ..................19 3.1 SmartImage .................................19 3.2 SmartContrast ............................20 3.3 Adaptive Sync .............................21 4. HDR ............................................. 22 5. Technical Specifications ......... 23 5.1 Resolution & Preset Modes ...26 6. Power Management ................ 27 7. Customer care and warranty . 28 7.1 Philips’ Flat Panel Displays Pixel Defect Policy ..............................28 7.2 Customer Care & Warranty ...... 31 8. Troubleshooting & FAQs ......... 32 8.1 Troubleshooting ........................ 32 8.2 General FAQs ............................. 33 8.3 Multiview FAQs .........................36 1. Important discoloration and damage to the 1. Important monitor. This electronic -

Impact of Adaptation Dimensions on Video Quality
Impact of Adaptation Dimensions on Video Quality Jens Brandt and Lars Wolf Institute of Operating Systems and Computer Networks (IBR), Technische Universitat¨ Braunschweig, Germany [email protected] Abstract—The number and types of mobile devices which well as the network conditions, may vary more often over time are capable of presenting digital video streams is increasing compared to static devices. Thus, the experience of watching constantly. In most cases the devices are trade-offs between video streams on mobile devices differs to a great extent from powerful all-purpose computers and small mobile devices which are ubiquitously available and range from cellular phones to those scenarios related to static displays usually found in the notebooks. This great heterogeneity of mobile devices makes area of home entertainment. For sequences from soccer games video streaming to such devices a challenging task for content McCarthy et al. observed that potential users preferred lower providers. Each single device has its own capabilities and indi- frame rates but higher detail resolution on mobile devices [2]. vidual requirements, which need to be considered when sending For other genres similar findings were presented for scalable a video stream to it. Thus, to support a great range of different devices, the video streams need to be adapted to the requirements video coding by Eichhorn and Ni in [3]. Besides concentration of each device. To get an idea of how different adaptation methods solely on the temporal resolution of a video stream, in our may affect the experience of users watching a streamed video on a work we additionally investigated the effect of adapting the mobile device, we inspect the influence of three major adaptation spatial and the detail resolution as well. -
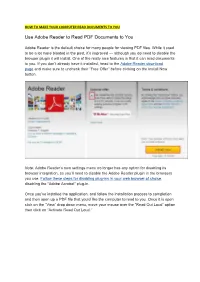
Use Adobe Reader to Read PDF Documents to You
HOW TO MAKE YOUR COMPUTER READ DOCUMENTS TO YOU Use Adobe Reader to Read PDF Documents to You Adobe Reader is the default choice for many people for viewing PDF files. While it used to be a lot more bloated in the past, it’s improved — although you do need to disable the browser plugin it will install. One of the really nice features is that it can read documents to you. If you don’t already have it installed, head to the Adobe Reader download page and make sure to uncheck their “Free Offer” before clicking on the Install Now button. Note: Adobe Reader’s own settings menu no longer has any option for disabling its browser integration, so you’ll need to disable the Adobe Reader plugin in the browsers you use. Follow these steps for disabling plug-ins in your web browser of choice, disabling the “Adobe Acrobat” plug-in. Once you’ve installed the application, and follow the installation process to completion and then open up a PDF file that you’d like the computer to read to you. Once it is open click on the “View” drop down menu, move your mouse over the “Read Out Loud” option then click on “Activate Read Out Loud.” Alternatively, you can click “Ctrl,” “Shift,” and “Y” (Ctrl+Shift+Y) on your keyboard to activate the feature. Once the feature is activated, you can click on a single paragraph to make windows read it back to you. Another option would be to navigate to the “View” menu, then “Read Out Loud” and select an option that fits your needs as shown in the Image below. -

Developed by the Consumer Technology Association Video Division
4K Ultra High-Definition TV A display system may be referred to as 4K Ultra High-Definition if it meets the following minimum performance attributes: Display Resolution – Has at least 8 million active pixels, with at least 3840 horizontally and at least 2160 vertically. Physical pixels shall be individually addressable such that the horizontal and vertical resolution above can be demonstrated over the full range of colors provided by the display. Aspect Ratio – The width to height ratio of the display’s native resolution is 16:9 or wider. Upconversion – The display is capable of upscaling HD video and displaying it at 4K Ultra High- Definition display resolution. Digital Input – Has one or more HDMI inputs supporting at least 3840x2160 native content resolution at 24p, 30p, & 60p frames per second. At least one of the 3840x2160 HDMI inputs shall support HDCP v2.2 or equivalent content protection. Colorimetry – Processes 2160p video inputs encoded according to ITU-R BT.709 color space, and may support wider colorimetry standards. Bit Depth – Has a minimum bit depth of 8 bits. Connected 4K Ultra High-Definition TV A display system may be referred to as Connected 4K Ultra High-Definition (or Connected 4K UHD) if it meets the following minimum performance attributes: 4K Ultra High-Definition Capability – Meets all of the requirements of CTA’s 4K Ultra High-Definition Display Characteristics V3. Video Codec – Decodes IP-delivered video of 3840x2160 resolution that has been compressed using HEVC* and may decode video from other standard encoders. Audio Codec – Receives and reproduces, and/or outputs multichannel audio.