ZNF146/OZF and ZNF507 Target LINE-1 Sequences Kevin M
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

A Flexible Microfluidic System for Single-Cell Transcriptome Profiling
www.nature.com/scientificreports OPEN A fexible microfuidic system for single‑cell transcriptome profling elucidates phased transcriptional regulators of cell cycle Karen Davey1,7, Daniel Wong2,7, Filip Konopacki2, Eugene Kwa1, Tony Ly3, Heike Fiegler2 & Christopher R. Sibley 1,4,5,6* Single cell transcriptome profling has emerged as a breakthrough technology for the high‑resolution understanding of complex cellular systems. Here we report a fexible, cost‑efective and user‑ friendly droplet‑based microfuidics system, called the Nadia Instrument, that can allow 3′ mRNA capture of ~ 50,000 single cells or individual nuclei in a single run. The precise pressure‑based system demonstrates highly reproducible droplet size, low doublet rates and high mRNA capture efciencies that compare favorably in the feld. Moreover, when combined with the Nadia Innovate, the system can be transformed into an adaptable setup that enables use of diferent bufers and barcoded bead confgurations to facilitate diverse applications. Finally, by 3′ mRNA profling asynchronous human and mouse cells at diferent phases of the cell cycle, we demonstrate the system’s ability to readily distinguish distinct cell populations and infer underlying transcriptional regulatory networks. Notably this provided supportive evidence for multiple transcription factors that had little or no known link to the cell cycle (e.g. DRAP1, ZKSCAN1 and CEBPZ). In summary, the Nadia platform represents a promising and fexible technology for future transcriptomic studies, and other related applications, at cell resolution. Single cell transcriptome profling has recently emerged as a breakthrough technology for understanding how cellular heterogeneity contributes to complex biological systems. Indeed, cultured cells, microorganisms, biopsies, blood and other tissues can be rapidly profled for quantifcation of gene expression at cell resolution. -
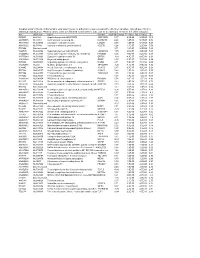
Supplementary File 2A Revised
Supplementary file 2A. Differentially expressed genes in aldosteronomas compared to all other samples, ranked according to statistical significance. Missing values were not allowed in aldosteronomas, but to a maximum of five in the other samples. Acc UGCluster Name Symbol log Fold Change P - Value Adj. P-Value B R99527 Hs.8162 Hypothetical protein MGC39372 MGC39372 2,17 6,3E-09 5,1E-05 10,2 AA398335 Hs.10414 Kelch domain containing 8A KLHDC8A 2,26 1,2E-08 5,1E-05 9,56 AA441933 Hs.519075 Leiomodin 1 (smooth muscle) LMOD1 2,33 1,3E-08 5,1E-05 9,54 AA630120 Hs.78781 Vascular endothelial growth factor B VEGFB 1,24 1,1E-07 2,9E-04 7,59 R07846 Data not found 3,71 1,2E-07 2,9E-04 7,49 W92795 Hs.434386 Hypothetical protein LOC201229 LOC201229 1,55 2,0E-07 4,0E-04 7,03 AA454564 Hs.323396 Family with sequence similarity 54, member B FAM54B 1,25 3,0E-07 5,2E-04 6,65 AA775249 Hs.513633 G protein-coupled receptor 56 GPR56 -1,63 4,3E-07 6,4E-04 6,33 AA012822 Hs.713814 Oxysterol bining protein OSBP 1,35 5,3E-07 7,1E-04 6,14 R45592 Hs.655271 Regulating synaptic membrane exocytosis 2 RIMS2 2,51 5,9E-07 7,1E-04 6,04 AA282936 Hs.240 M-phase phosphoprotein 1 MPHOSPH -1,40 8,1E-07 8,9E-04 5,74 N34945 Hs.234898 Acetyl-Coenzyme A carboxylase beta ACACB 0,87 9,7E-07 9,8E-04 5,58 R07322 Hs.464137 Acyl-Coenzyme A oxidase 1, palmitoyl ACOX1 0,82 1,3E-06 1,2E-03 5,35 R77144 Hs.488835 Transmembrane protein 120A TMEM120A 1,55 1,7E-06 1,4E-03 5,07 H68542 Hs.420009 Transcribed locus 1,07 1,7E-06 1,4E-03 5,06 AA410184 Hs.696454 PBX/knotted 1 homeobox 2 PKNOX2 1,78 2,0E-06 -

Supplementary Table S4. FGA Co-Expressed Gene List in LUAD
Supplementary Table S4. FGA co-expressed gene list in LUAD tumors Symbol R Locus Description FGG 0.919 4q28 fibrinogen gamma chain FGL1 0.635 8p22 fibrinogen-like 1 SLC7A2 0.536 8p22 solute carrier family 7 (cationic amino acid transporter, y+ system), member 2 DUSP4 0.521 8p12-p11 dual specificity phosphatase 4 HAL 0.51 12q22-q24.1histidine ammonia-lyase PDE4D 0.499 5q12 phosphodiesterase 4D, cAMP-specific FURIN 0.497 15q26.1 furin (paired basic amino acid cleaving enzyme) CPS1 0.49 2q35 carbamoyl-phosphate synthase 1, mitochondrial TESC 0.478 12q24.22 tescalcin INHA 0.465 2q35 inhibin, alpha S100P 0.461 4p16 S100 calcium binding protein P VPS37A 0.447 8p22 vacuolar protein sorting 37 homolog A (S. cerevisiae) SLC16A14 0.447 2q36.3 solute carrier family 16, member 14 PPARGC1A 0.443 4p15.1 peroxisome proliferator-activated receptor gamma, coactivator 1 alpha SIK1 0.435 21q22.3 salt-inducible kinase 1 IRS2 0.434 13q34 insulin receptor substrate 2 RND1 0.433 12q12 Rho family GTPase 1 HGD 0.433 3q13.33 homogentisate 1,2-dioxygenase PTP4A1 0.432 6q12 protein tyrosine phosphatase type IVA, member 1 C8orf4 0.428 8p11.2 chromosome 8 open reading frame 4 DDC 0.427 7p12.2 dopa decarboxylase (aromatic L-amino acid decarboxylase) TACC2 0.427 10q26 transforming, acidic coiled-coil containing protein 2 MUC13 0.422 3q21.2 mucin 13, cell surface associated C5 0.412 9q33-q34 complement component 5 NR4A2 0.412 2q22-q23 nuclear receptor subfamily 4, group A, member 2 EYS 0.411 6q12 eyes shut homolog (Drosophila) GPX2 0.406 14q24.1 glutathione peroxidase -

Target Gene Gene Description Validation Diana Miranda
Supplemental Table S1. Mmu-miR-183-5p in silico predicted targets. TARGET GENE GENE DESCRIPTION VALIDATION DIANA MIRANDA MIRBRIDGE PICTAR PITA RNA22 TARGETSCAN TOTAL_HIT AP3M1 adaptor-related protein complex 3, mu 1 subunit V V V V V V V 7 BTG1 B-cell translocation gene 1, anti-proliferative V V V V V V V 7 CLCN3 chloride channel, voltage-sensitive 3 V V V V V V V 7 CTDSPL CTD (carboxy-terminal domain, RNA polymerase II, polypeptide A) small phosphatase-like V V V V V V V 7 DUSP10 dual specificity phosphatase 10 V V V V V V V 7 MAP3K4 mitogen-activated protein kinase kinase kinase 4 V V V V V V V 7 PDCD4 programmed cell death 4 (neoplastic transformation inhibitor) V V V V V V V 7 PPP2R5C protein phosphatase 2, regulatory subunit B', gamma V V V V V V V 7 PTPN4 protein tyrosine phosphatase, non-receptor type 4 (megakaryocyte) V V V V V V V 7 EZR ezrin V V V V V V 6 FOXO1 forkhead box O1 V V V V V V 6 ANKRD13C ankyrin repeat domain 13C V V V V V V 6 ARHGAP6 Rho GTPase activating protein 6 V V V V V V 6 BACH2 BTB and CNC homology 1, basic leucine zipper transcription factor 2 V V V V V V 6 BNIP3L BCL2/adenovirus E1B 19kDa interacting protein 3-like V V V V V V 6 BRMS1L breast cancer metastasis-suppressor 1-like V V V V V V 6 CDK5R1 cyclin-dependent kinase 5, regulatory subunit 1 (p35) V V V V V V 6 CTDSP1 CTD (carboxy-terminal domain, RNA polymerase II, polypeptide A) small phosphatase 1 V V V V V V 6 DCX doublecortin V V V V V V 6 ENAH enabled homolog (Drosophila) V V V V V V 6 EPHA4 EPH receptor A4 V V V V V V 6 FOXP1 forkhead box P1 V -
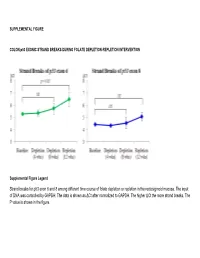
Strand Breaks for P53 Exon 6 and 8 Among Different Time Course of Folate Depletion Or Repletion in the Rectosigmoid Mucosa
SUPPLEMENTAL FIGURE COLON p53 EXONIC STRAND BREAKS DURING FOLATE DEPLETION-REPLETION INTERVENTION Supplemental Figure Legend Strand breaks for p53 exon 6 and 8 among different time course of folate depletion or repletion in the rectosigmoid mucosa. The input of DNA was controlled by GAPDH. The data is shown as ΔCt after normalized to GAPDH. The higher ΔCt the more strand breaks. The P value is shown in the figure. SUPPLEMENT S1 Genes that were significantly UPREGULATED after folate intervention (by unadjusted paired t-test), list is sorted by P value Gene Symbol Nucleotide P VALUE Description OLFM4 NM_006418 0.0000 Homo sapiens differentially expressed in hematopoietic lineages (GW112) mRNA. FMR1NB NM_152578 0.0000 Homo sapiens hypothetical protein FLJ25736 (FLJ25736) mRNA. IFI6 NM_002038 0.0001 Homo sapiens interferon alpha-inducible protein (clone IFI-6-16) (G1P3) transcript variant 1 mRNA. Homo sapiens UDP-N-acetyl-alpha-D-galactosamine:polypeptide N-acetylgalactosaminyltransferase 15 GALNTL5 NM_145292 0.0001 (GALNT15) mRNA. STIM2 NM_020860 0.0001 Homo sapiens stromal interaction molecule 2 (STIM2) mRNA. ZNF645 NM_152577 0.0002 Homo sapiens hypothetical protein FLJ25735 (FLJ25735) mRNA. ATP12A NM_001676 0.0002 Homo sapiens ATPase H+/K+ transporting nongastric alpha polypeptide (ATP12A) mRNA. U1SNRNPBP NM_007020 0.0003 Homo sapiens U1-snRNP binding protein homolog (U1SNRNPBP) transcript variant 1 mRNA. RNF125 NM_017831 0.0004 Homo sapiens ring finger protein 125 (RNF125) mRNA. FMNL1 NM_005892 0.0004 Homo sapiens formin-like (FMNL) mRNA. ISG15 NM_005101 0.0005 Homo sapiens interferon alpha-inducible protein (clone IFI-15K) (G1P2) mRNA. SLC6A14 NM_007231 0.0005 Homo sapiens solute carrier family 6 (neurotransmitter transporter) member 14 (SLC6A14) mRNA. -

Human Social Genomics in the Multi-Ethnic Study of Atherosclerosis
Getting “Under the Skin”: Human Social Genomics in the Multi-Ethnic Study of Atherosclerosis by Kristen Monét Brown A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy (Epidemiological Science) in the University of Michigan 2017 Doctoral Committee: Professor Ana V. Diez-Roux, Co-Chair, Drexel University Professor Sharon R. Kardia, Co-Chair Professor Bhramar Mukherjee Assistant Professor Belinda Needham Assistant Professor Jennifer A. Smith © Kristen Monét Brown, 2017 [email protected] ORCID iD: 0000-0002-9955-0568 Dedication I dedicate this dissertation to my grandmother, Gertrude Delores Hampton. Nanny, no one wanted to see me become “Dr. Brown” more than you. I know that you are standing over the bannister of heaven smiling and beaming with pride. I love you more than my words could ever fully express. ii Acknowledgements First, I give honor to God, who is the head of my life. Truly, without Him, none of this would be possible. Countless times throughout this doctoral journey I have relied my favorite scripture, “And we know that all things work together for good, to them that love God, to them who are called according to His purpose (Romans 8:28).” Secondly, I acknowledge my parents, James and Marilyn Brown. From an early age, you two instilled in me the value of education and have been my biggest cheerleaders throughout my entire life. I thank you for your unconditional love, encouragement, sacrifices, and support. I would not be here today without you. I truly thank God that out of the all of the people in the world that He could have chosen to be my parents, that He chose the two of you. -

Broad and Thematic Remodeling of the Surfaceome and Glycoproteome on Isogenic Cells Transformed with Driving Proliferative Oncogenes
Broad and thematic remodeling of the surfaceome and glycoproteome on isogenic cells transformed with driving proliferative oncogenes Kevin K. Leunga,1 , Gary M. Wilsonb,c,1, Lisa L. Kirkemoa, Nicholas M. Rileyb,c,d , Joshua J. Coonb,c, and James A. Wellsa,2 aDepartment of Pharmaceutical Chemistry, University of California, San Francisco, CA 94143; bDepartment of Chemistry, University of Wisconsin–Madison, Madison, WI 53706; cDepartment of Biomolecular Chemistry, University of Wisconsin–Madison, Madison, WI 53706; and dDepartment of Chemistry, Stanford University, Stanford, CA 94305 Edited by Benjamin F. Cravatt, Scripps Research Institute, La Jolla, CA, and approved February 24, 2020 (received for review October 14, 2019) The cell surface proteome, the surfaceome, is the interface for tumors. For example, lung cancer patients with oncogenic EGFR engaging the extracellular space in normal and cancer cells. Here mutations seldom harbor oncogenic KRAS or BRAF mutations we apply quantitative proteomics of N-linked glycoproteins to and vice versa (9). Also, recent evidence shows that oncogene reveal how a collection of some 700 surface proteins is dra- coexpression can induce synthetic lethality or oncogene-induced matically remodeled in an isogenic breast epithelial cell line senescence, further reinforcing that activation of one oncogene stably expressing any of six of the most prominent prolifera- without the others is preferable in cancer (10, 11). tive oncogenes, including the receptor tyrosine kinases, EGFR There is also substantial -

Dissecting the Genetics of Human Communication
DISSECTING THE GENETICS OF HUMAN COMMUNICATION: INSIGHTS INTO SPEECH, LANGUAGE, AND READING by HEATHER ASHLEY VOSS-HOYNES Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy Department of Epidemiology and Biostatistics CASE WESTERN RESERVE UNIVERSITY January 2017 CASE WESTERN RESERVE UNIVERSITY SCHOOL OF GRADUATE STUDIES We herby approve the dissertation of Heather Ashely Voss-Hoynes Candidate for the degree of Doctor of Philosophy*. Committee Chair Sudha K. Iyengar Committee Member William Bush Committee Member Barbara Lewis Committee Member Catherine Stein Date of Defense July 13, 2016 *We also certify that written approval has been obtained for any proprietary material contained therein Table of Contents List of Tables 3 List of Figures 5 Acknowledgements 7 List of Abbreviations 9 Abstract 10 CHAPTER 1: Introduction and Specific Aims 12 CHAPTER 2: Review of speech sound disorders: epidemiology, quantitative components, and genetics 15 1. Basic Epidemiology 15 2. Endophenotypes of Speech Sound Disorders 17 3. Evidence for Genetic Basis Of Speech Sound Disorders 22 4. Genetic Studies of Speech Sound Disorders 23 5. Limitations of Previous Studies 32 CHAPTER 3: Methods 33 1. Phenotype Data 33 2. Tests For Quantitative Traits 36 4. Analytical Methods 42 CHAPTER 4: Aim I- Genome Wide Association Study 49 1. Introduction 49 2. Methods 49 3. Sample 50 5. Statistical Procedures 53 6. Results 53 8. Discussion 71 CHAPTER 5: Accounting for comorbid conditions 84 1. Introduction 84 2. Methods 86 3. Results 87 4. Discussion 105 CHAPTER 6: Hypothesis driven pathway analysis 111 1. Introduction 111 2. Methods 112 3. Results 116 4. -

FOXP2 and Language Alterations in Psychiatric Pathology Salud Mental, Vol
Salud mental ISSN: 0185-3325 Instituto Nacional de Psiquiatría Ramón de la Fuente Muñiz Castro Martínez, Xochitl Helga; Moltó Ruiz, María Dolores; Morales Marin, Mirna Edith; Flores Lázaro, Julio César; González Fernández, Javier; Gutiérrez Najera, Nora Andrea; Alvarez Amado, Daniel Eduardo; Nicolini Sánchez, José Humberto FOXP2 and language alterations in psychiatric pathology Salud mental, vol. 42, no. 6, 2019, pp. 297-308 Instituto Nacional de Psiquiatría Ramón de la Fuente Muñiz DOI: 10.17711/SM.0185-3325.2019.039 Available in: http://www.redalyc.org/articulo.oa?id=58262364007 How to cite Complete issue Scientific Information System Redalyc More information about this article Network of Scientific Journals from Latin America and the Caribbean, Spain and Journal's webpage in redalyc.org Portugal Project academic non-profit, developed under the open access initiative REVIEW ARTICLE Volume 42, Issue 6, November-December 2019 doi: 10.17711/SM.0185-3325.2019.039 FOXP2 and language alterations in psychiatric pathology Xochitl Helga Castro Martínez,1 María Dolores Moltó Ruiz,2,3 Mirna Edith Morales Marin,1 Julio César Flores Lázaro,4 Javier González Fernández,2 Nora Andrea Gutiérrez Najera,1 Daniel Eduardo Alvarez Amado,5 José Humberto Nicolini Sánchez1 1 Laboratorio de Genómica de Enfer- ABSTRACT medades Psiquiátricas y Neurode- generativas, Instituto Nacional de From the first reports of the linguist Noam Chomsky it has become clear that the development Medicina Genómica, Ciudad de Background. México, México. of language has an important genetic component. Several reports in families have shown the relationship 2 Departamento de Genética. Univer- between language disorders and genetic polymorphisms. The FOXP2 gene has been a fundamental piece sitat de València. -

Autocrine IFN Signaling Inducing Profibrotic Fibroblast Responses By
Downloaded from http://www.jimmunol.org/ by guest on September 23, 2021 Inducing is online at: average * The Journal of Immunology , 11 of which you can access for free at: 2013; 191:2956-2966; Prepublished online 16 from submission to initial decision 4 weeks from acceptance to publication August 2013; doi: 10.4049/jimmunol.1300376 http://www.jimmunol.org/content/191/6/2956 A Synthetic TLR3 Ligand Mitigates Profibrotic Fibroblast Responses by Autocrine IFN Signaling Feng Fang, Kohtaro Ooka, Xiaoyong Sun, Ruchi Shah, Swati Bhattacharyya, Jun Wei and John Varga J Immunol cites 49 articles Submit online. Every submission reviewed by practicing scientists ? is published twice each month by Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts http://jimmunol.org/subscription Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html http://www.jimmunol.org/content/suppl/2013/08/20/jimmunol.130037 6.DC1 This article http://www.jimmunol.org/content/191/6/2956.full#ref-list-1 Information about subscribing to The JI No Triage! Fast Publication! Rapid Reviews! 30 days* Why • • • Material References Permissions Email Alerts Subscription Supplementary The Journal of Immunology The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2013 by The American Association of Immunologists, Inc. All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. This information is current as of September 23, 2021. The Journal of Immunology A Synthetic TLR3 Ligand Mitigates Profibrotic Fibroblast Responses by Inducing Autocrine IFN Signaling Feng Fang,* Kohtaro Ooka,* Xiaoyong Sun,† Ruchi Shah,* Swati Bhattacharyya,* Jun Wei,* and John Varga* Activation of TLR3 by exogenous microbial ligands or endogenous injury-associated ligands leads to production of type I IFN. -

Genome-Wide Analysis of Promoter Methylation Associated with Gene Expression Profile in Pancreatic Adenocarcinoma
Published OnlineFirst May 24, 2011; DOI: 10.1158/1078-0432.CCR-10-3431 Clinical Cancer Human Cancer Biology Research Genome-Wide Analysis of Promoter Methylation Associated with Gene Expression Profile in Pancreatic Adenocarcinoma Audrey Vincent1, Noriyuki Omura1, Seung-Mo Hong1, Andrew Jaffe4, James Eshleman1,2, and Michael Goggins1,2,3 Abstract Purpose: The goal of this study was to comprehensively identify CpG island methylation alterations between pancreatic cancers and normal pancreata and their associated gene expression alterations. Experimental Design: We employed methylated CpG island amplification followed by CpG island microarray, a method previously validated for its accuracy and reproducibility, to analyze the methylation profile of 27,800 CpG islands covering 21 MB of the human genome in nine pairs of pancreatic cancer versus normal pancreatic epithelial tissues and in three matched pairs of pancreatic cancer versus lymphoid tissues from the same individual. Results: This analysis identified 1,658 known loci that were commonly differentially methylated in pancreatic cancer compared with normal pancreas. By integrating the pancreatic DNA methylation status with the gene expression profiles of the same samples before and after treatment with the DNA methyltransferase inhibitor 5-aza-20-deoxycytidine, and the histone deacetylase inhibitor, trichostatin A, we identified dozens of aberrantly methylated and differentially expressed genes in pancreatic cancers including a more comprehensive list of hypermethylated and silenced genes that have not been previously described as targets for aberrant methylation in cancer. Conclusion: We expected that the identification of aberrantly hypermethylated and silenced genes will have diagnostic, prognostic, and therapeutic applications. Clin Cancer Res; 17(13); 4341–54.