Xtensa Instruction Set Architecture (ISA) Reference Manual Iii Contents
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Binary Counter
Systems I: Computer Organization and Architecture Lecture 8: Registers and Counters Registers • A register is a group of flip-flops. – Each flip-flop stores one bit of data; n flip-flops are required to store n bits of data. – There are several different types of registers available commercially. – The simplest design is a register consisting only of flip- flops, with no other gates in the circuit. • Loading the register – transfer of new data into the register. • The flip-flops share a common clock pulse (frequently using a buffer to reduce power requirements). • Output could be sampled at any time. • Clearing the flip-flop (placing zeroes in all its bit) can be done through a special terminal on the flip-flop. 1 4-bit Register I0 D Q A0 Clock C I1 D Q A1 C I D Q 2 A2 C D Q A I3 3 C Clear Registers With Parallel Load • The clock usually provides a steady stream of pulses which are applied to all flip-flops in the system. • A separate control system is needed to determine when to load a particular register. • The Register with Parallel Load has a separate load input. – When it is cleared, the register receives it output as input. – When it is set, it received the load input. 2 4-bit Register With Parallel Load Load D Q A0 I0 C D Q A1 C I1 D Q A2 I2 C D Q A3 I3 C Clock Shift Registers • A shift register is a register which can shift its data in one or both directions. -

The RISC-V Instruction Set Manual, Volume I: User- Level ISA, Version 2.0
The RISC-V Instruction Set Manual, Volume I: User- Level ISA, Version 2.0 Andrew Waterman Yunsup Lee David A. Patterson Krste Asanovic Electrical Engineering and Computer Sciences University of California at Berkeley Technical Report No. UCB/EECS-2014-54 http://www.eecs.berkeley.edu/Pubs/TechRpts/2014/EECS-2014-54.html May 6, 2014 Copyright © 2014, by the author(s). All rights reserved. Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. To copy otherwise, to republish, to post on servers or to redistribute to lists, requires prior specific permission. The RISC-V Instruction Set Manual Volume I: User-Level ISA Version 2.0 Andrew Waterman, Yunsup Lee, David Patterson, Krste Asanovi´c CS Division, EECS Department, University of California, Berkeley fwaterman|yunsup|pattrsn|[email protected] May 6, 2014 Preface This is the second release of the user ISA specification, and we intend the specification of the base user ISA plus general extensions (i.e., IMAFD) to remain fixed for future development. The following changes have been made since Version 1.0 [25] of this ISA specification. • The ISA has been divided into an integer base with several standard extensions. • The instruction formats have been rearranged to make immediate encoding more efficient. • The base ISA has been defined to have a little-endian memory system, with big-endian or bi-endian as non-standard variants. -

Cross Architectural Power Modelling
Cross Architectural Power Modelling Kai Chen1, Peter Kilpatrick1, Dimitrios S. Nikolopoulos2, and Blesson Varghese1 1Queen’s University Belfast, UK; 2Virginia Tech, USA E-mail: [email protected]; [email protected]; [email protected]; [email protected] Abstract—Existing power modelling research focuses on the processor are extensively explored using a cumbersome trial model rather than the process for developing models. An auto- and error approach after which a suitable few are selected [7]. mated power modelling process that can be deployed on different Such an approach does not easily scale for various processor processors for developing power models with high accuracy is developed. For this, (i) an automated hardware performance architectures since a different set of hardware counters will be counter selection method that selects counters best correlated to required to model power for each processor. power on both ARM and Intel processors, (ii) a noise filter based Currently, there is little research that develops automated on clustering that can reduce the mean error in power models, and (iii) a two stage power model that surmounts challenges in methods for selecting hardware counters to capture proces- using existing power models across multiple architectures are sor power over multiple processor architectures. Automated proposed and developed. The key results are: (i) the automated methods are required for easily building power models for a hardware performance counter selection method achieves compa- collection of heterogeneous processors as seen in traditional rable selection to the manual method reported in the literature, data centers that host multiple generations of server proces- (ii) the noise filter reduces the mean error in power models by up to 55%, and (iii) the two stage power model can predict sors, or in emerging distributed computing environments like dynamic power with less than 8% error on both ARM and Intel fog/edge computing [8] and mobile cloud computing (in these processors, which is an improvement over classic models. -

Soft Machines Targets Ipcbottleneck
SOFT MACHINES TARGETS IPC BOTTLENECK New CPU Approach Boosts Performance Using Virtual Cores By Linley Gwennap (October 27, 2014) ................................................................................................................... Coming out of stealth mode at last week’s Linley Pro- president/CTO Mohammad Abdallah. Investors include cessor Conference, Soft Machines disclosed a new CPU AMD, GlobalFoundries, and Samsung as well as govern- technology that greatly improves performance on single- ment investment funds from Abu Dhabi (Mubdala), Russia threaded applications. The new VISC technology can con- (Rusnano and RVC), and Saudi Arabia (KACST and vert a single software thread into multiple virtual threads, Taqnia). Its board of directors is chaired by Global Foun- which it can then divide across multiple physical cores. dries CEO Sanjay Jha and includes legendary entrepreneur This conversion happens inside the processor hardware Gordon Campbell. and is thus invisible to the application and the software Soft Machines hopes to license the VISC technology developer. Although this capability may seem impossible, to other CPU-design companies, which could add it to Soft Machines has demonstrated its performance advan- their existing CPU cores. Because its fundamental benefit tage using a test chip that implements a VISC design. is better IPC, VISC could aid a range of applications from Without VISC, the only practical way to improve single-thread performance is to increase the parallelism Application (sequential code) (instructions per cycle, or IPC) of the CPU microarchi- Single Thread tecture. Taken to the extreme, this approach results in massive designs such as Intel’s Haswell and IBM’s Power8 OS and Hypervisor that deliver industry-leading performance but waste power Standard ISA and die area. -

Experiment No
1 LIST OF EXPERIMENTS 1. Study of logic gates. 2. Design and implementation of adders and subtractors using logic gates. 3. Design and implementation of code converters using logic gates. 4. Design and implementation of 4-bit binary adder/subtractor and BCD adder using IC 7483. 5. Design and implementation of 2-bit magnitude comparator using logic gates, 8- bit magnitude comparator using IC 7485. 6. Design and implementation of 16-bit odd/even parity checker/ generator using IC 74180. 7. Design and implementation of multiplexer and demultiplexer using logic gates and study of IC 74150 and IC 74154. 8. Design and implementation of encoder and decoder using logic gates and study of IC 7445 and IC 74147. 9. Construction and verification of 4-bit ripple counter and Mod-10/Mod-12 ripple counter. 10. Design and implementation of 3-bit synchronous up/down counter. 11. Implementation of SISO, SIPO, PISO and PIPO shift registers using flip-flops. KCTCET/2016-17/Odd/3rd/ETE/CSE/LM 2 EXPERIMENT NO. 01 STUDY OF LOGIC GATES AIM: To study about logic gates and verify their truth tables. APPARATUS REQUIRED: SL No. COMPONENT SPECIFICATION QTY 1. AND GATE IC 7408 1 2. OR GATE IC 7432 1 3. NOT GATE IC 7404 1 4. NAND GATE 2 I/P IC 7400 1 5. NOR GATE IC 7402 1 6. X-OR GATE IC 7486 1 7. NAND GATE 3 I/P IC 7410 1 8. IC TRAINER KIT - 1 9. PATCH CORD - 14 THEORY: Circuit that takes the logical decision and the process are called logic gates. -
1 DIGITAL COUNTER and APPLICATIONS a Digital Counter Is
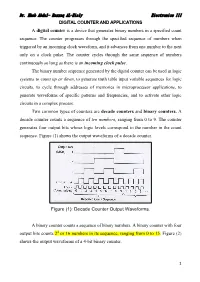
Dr. Ehab Abdul- Razzaq AL-Hialy Electronics III DIGITAL COUNTER AND APPLICATIONS A digital counter is a device that generates binary numbers in a specified count sequence. The counter progresses through the specified sequence of numbers when triggered by an incoming clock waveform, and it advances from one number to the next only on a clock pulse. The counter cycles through the same sequence of numbers continuously so long as there is an incoming clock pulse. The binary number sequence generated by the digital counter can be used in logic systems to count up or down, to generate truth table input variable sequences for logic circuits, to cycle through addresses of memories in microprocessor applications, to generate waveforms of specific patterns and frequencies, and to activate other logic circuits in a complex process. Two common types of counters are decade counters and binary counters. A decade counter counts a sequence of ten numbers, ranging from 0 to 9. The counter generates four output bits whose logic levels correspond to the number in the count sequence. Figure (1) shows the output waveforms of a decade counter. Figure (1): Decade Counter Output Waveforms. A binary counter counts a sequence of binary numbers. A binary counter with four output bits counts 24 or 16 numbers in its sequence, ranging from 0 to 15. Figure (2) shows-the output waveforms of a 4-bit binary counter. 1 Dr. Ehab Abdul- Razzaq AL-Hialy Electronics III Figure (2): Binary Counter Output Waveforms. EXAMPLE (1): Decade Counter. Problem: Determine the 4-bit decade counter output that corresponds to the waveforms shown in Figure (1). -

Superh RISC Engine SH-1/SH-2
SuperH RISC Engine SH-1/SH-2 Programming Manual September 3, 1996 Hitachi America Ltd. Notice When using this document, keep the following in mind: 1. This document may, wholly or partially, be subject to change without notice. 2. All rights are reserved: No one is permitted to reproduce or duplicate, in any form, the whole or part of this document without Hitachi’s permission. 3. Hitachi will not be held responsible for any damage to the user that may result from accidents or any other reasons during operation of the user’s unit according to this document. 4. Circuitry and other examples described herein are meant merely to indicate the characteristics and performance of Hitachi’s semiconductor products. Hitachi assumes no responsibility for any intellectual property claims or other problems that may result from applications based on the examples described herein. 5. No license is granted by implication or otherwise under any patents or other rights of any third party or Hitachi, Ltd. 6. MEDICAL APPLICATIONS: Hitachi’s products are not authorized for use in MEDICAL APPLICATIONS without the written consent of the appropriate officer of Hitachi’s sales company. Such use includes, but is not limited to, use in life support systems. Buyers of Hitachi’s products are requested to notify the relevant Hitachi sales offices when planning to use the products in MEDICAL APPLICATIONS. Introduction The SuperH RISC engine family incorporates a RISC (Reduced Instruction Set Computer) type CPU. A basic instruction can be executed in one clock cycle, realizing high performance operation. A built-in multiplier can execute multiplication and addition as quickly as DSP. -

Computer Architecture Out-Of-Order Execution
Computer Architecture Out-of-order Execution By Yoav Etsion With acknowledgement to Dan Tsafrir, Avi Mendelson, Lihu Rappoport, and Adi Yoaz 1 Computer Architecture 2013– Out-of-Order Execution The need for speed: Superscalar • Remember our goal: minimize CPU Time CPU Time = duration of clock cycle × CPI × IC • So far we have learned that in order to Minimize clock cycle ⇒ add more pipe stages Minimize CPI ⇒ utilize pipeline Minimize IC ⇒ change/improve the architecture • Why not make the pipeline deeper and deeper? Beyond some point, adding more pipe stages doesn’t help, because Control/data hazards increase, and become costlier • (Recall that in a pipelined CPU, CPI=1 only w/o hazards) • So what can we do next? Reduce the CPI by utilizing ILP (instruction level parallelism) We will need to duplicate HW for this purpose… 2 Computer Architecture 2013– Out-of-Order Execution A simple superscalar CPU • Duplicates the pipeline to accommodate ILP (IPC > 1) ILP=instruction-level parallelism • Note that duplicating HW in just one pipe stage doesn’t help e.g., when having 2 ALUs, the bottleneck moves to other stages IF ID EXE MEM WB • Conclusion: Getting IPC > 1 requires to fetch/decode/exe/retire >1 instruction per clock: IF ID EXE MEM WB 3 Computer Architecture 2013– Out-of-Order Execution Example: Pentium Processor • Pentium fetches & decodes 2 instructions per cycle • Before register file read, decide on pairing Can the two instructions be executed in parallel? (yes/no) u-pipe IF ID v-pipe • Pairing decision is based… On data -

Performance of a Computer (Chapter 4) Vishwani D
ELEC 5200-001/6200-001 Computer Architecture and Design Fall 2013 Performance of a Computer (Chapter 4) Vishwani D. Agrawal & Victor P. Nelson epartment of Electrical and Computer Engineering Auburn University, Auburn, AL 36849 ELEC 5200-001/6200-001 Performance Fall 2013 . Lecture 1 What is Performance? Response time: the time between the start and completion of a task. Throughput: the total amount of work done in a given time. Some performance measures: MIPS (million instructions per second). MFLOPS (million floating point operations per second), also GFLOPS, TFLOPS (1012), etc. SPEC (System Performance Evaluation Corporation) benchmarks. LINPACK benchmarks, floating point computing, used for supercomputers. Synthetic benchmarks. ELEC 5200-001/6200-001 Performance Fall 2013 . Lecture 2 Small and Large Numbers Small Large 10-3 milli m 103 kilo k 10-6 micro μ 106 mega M 10-9 nano n 109 giga G 10-12 pico p 1012 tera T 10-15 femto f 1015 peta P 10-18 atto 1018 exa 10-21 zepto 1021 zetta 10-24 yocto 1024 yotta ELEC 5200-001/6200-001 Performance Fall 2013 . Lecture 3 Computer Memory Size Number bits bytes 210 1,024 K Kb KB 220 1,048,576 M Mb MB 230 1,073,741,824 G Gb GB 240 1,099,511,627,776 T Tb TB ELEC 5200-001/6200-001 Performance Fall 2013 . Lecture 4 Units for Measuring Performance Time in seconds (s), microseconds (μs), nanoseconds (ns), or picoseconds (ps). Clock cycle Period of the hardware clock Example: one clock cycle means 1 nanosecond for a 1GHz clock frequency (or 1GHz clock rate) CPU time = (CPU clock cycles)/(clock rate) Cycles per instruction (CPI): average number of clock cycles used to execute a computer instruction. -

Chap01: Computer Abstractions and Technology
CHAPTER 1 Computer Abstractions and Technology 1.1 Introduction 3 1.2 Eight Great Ideas in Computer Architecture 11 1.3 Below Your Program 13 1.4 Under the Covers 16 1.5 Technologies for Building Processors and Memory 24 1.6 Performance 28 1.7 The Power Wall 40 1.8 The Sea Change: The Switch from Uniprocessors to Multiprocessors 43 1.9 Real Stuff: Benchmarking the Intel Core i7 46 1.10 Fallacies and Pitfalls 49 1.11 Concluding Remarks 52 1.12 Historical Perspective and Further Reading 54 1.13 Exercises 54 CMPS290 Class Notes (Chap01) Page 1 / 24 by Kuo-pao Yang 1.1 Introduction 3 Modern computer technology requires professionals of every computing specialty to understand both hardware and software. Classes of Computing Applications and Their Characteristics Personal computers o A computer designed for use by an individual, usually incorporating a graphics display, a keyboard, and a mouse. o Personal computers emphasize delivery of good performance to single users at low cost and usually execute third-party software. o This class of computing drove the evolution of many computing technologies, which is only about 35 years old! Server computers o A computer used for running larger programs for multiple users, often simultaneously, and typically accessed only via a network. o Servers are built from the same basic technology as desktop computers, but provide for greater computing, storage, and input/output capacity. Supercomputers o A class of computers with the highest performance and cost o Supercomputers consist of tens of thousands of processors and many terabytes of memory, and cost tens to hundreds of millions of dollars. -

Thumb® 16-Bit Instruction Set Quick Reference Card
Thumb® 16-bit Instruction Set Quick Reference Card This card lists all Thumb instructions available on Thumb-capable processors earlier than ARM®v6T2. In addition, it lists all Thumb-2 16-bit instructions. The instructions shown on this card are all 16-bit in Thumb-2, except where noted otherwise. All registers are Lo (R0-R7) except where specified. Hi registers are R8-R15. Key to Tables § See Table ARM architecture versions. <loreglist+LR> A comma-separated list of Lo registers. plus the LR, enclosed in braces, { and }. <loreglist> A comma-separated list of Lo registers, enclosed in braces, { and }. <loreglist+PC> A comma-separated list of Lo registers. plus the PC, enclosed in braces, { and }. Operation § Assembler Updates Action Notes Move Immediate MOVS Rd, #<imm> N Z Rd := imm imm range 0-255. Lo to Lo MOVS Rd, Rm N Z Rd := Rm Synonym of LSLS Rd, Rm, #0 Hi to Lo, Lo to Hi, Hi to Hi MOV Rd, Rm Rd := Rm Not Lo to Lo. Any to Any 6 MOV Rd, Rm Rd := Rm Any register to any register. Add Immediate 3 ADDS Rd, Rn, #<imm> N Z C V Rd := Rn + imm imm range 0-7. All registers Lo ADDS Rd, Rn, Rm N Z C V Rd := Rn + Rm Hi to Lo, Lo to Hi, Hi to Hi ADD Rd, Rd, Rm Rd := Rd + Rm Not Lo to Lo. Any to Any T2 ADD Rd, Rd, Rm Rd := Rd + Rm Any register to any register. Immediate 8 ADDS Rd, Rd, #<imm> N Z C V Rd := Rd + imm imm range 0-255. -

CPU) the CPU Is the Brains of the Computer, and Is Also Known As the Processor (A Single Chip Also Known As Microprocessor)
Central processing unit (CPU) The CPU is the brains of the computer, and is also known as the processor (a single chip also known as microprocessor). This electronic component interprets and carries out the basic instructions that operate the computer. Cache as a rule holds data waiting to be processed and instructions waiting to be executed. The main parts of the CPU are: control unit arithmetic logic unit (ALU), and registers – also referred as Cache registers The CPU is connected to a circuit board called the motherboard also known as the system board. Click here to see more information on the CPU Let’s look inside the CPU and see what the different components actually do and how they interact Control unit The control unit directs and co-ordinates most of the operations in the computer. It is a bit similar to a traffic officer controlling traffic! It translates instructions received from a program/application and then begins the appropriate action to carry out the instruction. Specifically the control unit: controls how and when input devices send data stores and retrieves data to and from specific locations in memory decodes and executes instructions sends data to other parts of the CPU during operations sends data to output devices on request Arithmetic Logic Unit (ALU): The ALU is the computer’s calculator. It handles all math operations such as: add subtract multiply divide logical decisions - true or false, and/or, greater then, equal to, or less than Registers Registers are special temporary storage areas on the CPU. They are: used to store items during arithmetic, logic or transfer operations.