Human ORC/MCM Density Is Low in Active Genes and Correlates with Replication Time but Does Not Delimit Initiation Zones
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Roots of Middle-Earth: William Morris's Influence Upon J. R. R. Tolkien
University of Tennessee, Knoxville TRACE: Tennessee Research and Creative Exchange Doctoral Dissertations Graduate School 12-2007 The Roots of Middle-Earth: William Morris's Influence upon J. R. R. Tolkien Kelvin Lee Massey University of Tennessee - Knoxville Follow this and additional works at: https://trace.tennessee.edu/utk_graddiss Part of the Literature in English, British Isles Commons Recommended Citation Massey, Kelvin Lee, "The Roots of Middle-Earth: William Morris's Influence upon J. R. R. olkien.T " PhD diss., University of Tennessee, 2007. https://trace.tennessee.edu/utk_graddiss/238 This Dissertation is brought to you for free and open access by the Graduate School at TRACE: Tennessee Research and Creative Exchange. It has been accepted for inclusion in Doctoral Dissertations by an authorized administrator of TRACE: Tennessee Research and Creative Exchange. For more information, please contact [email protected]. To the Graduate Council: I am submitting herewith a dissertation written by Kelvin Lee Massey entitled "The Roots of Middle-Earth: William Morris's Influence upon J. R. R. olkien.T " I have examined the final electronic copy of this dissertation for form and content and recommend that it be accepted in partial fulfillment of the equirr ements for the degree of Doctor of Philosophy, with a major in English. David F. Goslee, Major Professor We have read this dissertation and recommend its acceptance: Thomas Heffernan, Michael Lofaro, Robert Bast Accepted for the Council: Carolyn R. Hodges Vice Provost and Dean of the Graduate School (Original signatures are on file with official studentecor r ds.) To the Graduate Council: I am submitting herewith a dissertation written by Kelvin Lee Massey entitled “The Roots of Middle-earth: William Morris’s Influence upon J. -

Molecular Profile of Tumor-Specific CD8+ T Cell Hypofunction in a Transplantable Murine Cancer Model
Downloaded from http://www.jimmunol.org/ by guest on September 25, 2021 T + is online at: average * The Journal of Immunology , 34 of which you can access for free at: 2016; 197:1477-1488; Prepublished online 1 July from submission to initial decision 4 weeks from acceptance to publication 2016; doi: 10.4049/jimmunol.1600589 http://www.jimmunol.org/content/197/4/1477 Molecular Profile of Tumor-Specific CD8 Cell Hypofunction in a Transplantable Murine Cancer Model Katherine A. Waugh, Sonia M. Leach, Brandon L. Moore, Tullia C. Bruno, Jonathan D. Buhrman and Jill E. Slansky J Immunol cites 95 articles Submit online. Every submission reviewed by practicing scientists ? is published twice each month by Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts http://jimmunol.org/subscription Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html http://www.jimmunol.org/content/suppl/2016/07/01/jimmunol.160058 9.DCSupplemental This article http://www.jimmunol.org/content/197/4/1477.full#ref-list-1 Information about subscribing to The JI No Triage! Fast Publication! Rapid Reviews! 30 days* Why • • • Material References Permissions Email Alerts Subscription Supplementary The Journal of Immunology The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2016 by The American Association of Immunologists, Inc. All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. This information is current as of September 25, 2021. The Journal of Immunology Molecular Profile of Tumor-Specific CD8+ T Cell Hypofunction in a Transplantable Murine Cancer Model Katherine A. -

How Shelterin Protects Mammalian Telomeres 303 ANRV361-GE42-15 ARI 3 October 2008 10:10 (See 3' 5' TRF2 S Mplex
ANRV361-GE42-15 ARI 3 October 2008 10:10 ANNUAL How Shelterin Protects REVIEWS Further Click here for quick links to Annual Reviews content online, Mammalian Telomeres including: • Other articles in this volume 1 • Top cited articles Wilhelm Palm and Titia de Lange • Top downloaded articles • Our comprehensive search Laboratory for Cell Biology and Genetics, The Rockefeller University, New York, NY 10021; email: [email protected] 1Current address: Max Planck Institute of Molecular Cell Biology and Genetics, 01307 Dresden, Germany Annu. Rev. Genet. 2008. 42:301–34 Key Words First published online as a Review in Advance on ATM, ATR, cancer, NHEJ, HR August 4, 2008 by Rockefeller University on 10/13/09. For personal use only. The Annual Review of Genetics is online at Abstract genet.annualreviews.org The genomes of prokaryotes and eukaryotic organelles are usually cir- This article’s doi: cular as are most plasmids and viral genomes. In contrast, the nuclear Annu. Rev. Genet. 2008.42:301-334. Downloaded from arjournals.annualreviews.org 10.1146/annurev.genet.41.110306.130350 genomes of eukaryotes are organized on linear chromosomes, which Copyright c 2008 by Annual Reviews. require mechanisms to protect and replicate DNA ends. Eukaryotes All rights reserved navigate these problemswith the advent of telomeres, protective nucle- 0066-4197/08/1201-0301$20.00 oprotein complexes at the ends of linear chromosomes, and telomerase, the enzyme that maintains the DNA in these structures. Mammalian telomeres contain a specific protein complex, shelterin, that functions to protect chromosome ends from all aspects of the DNA damage re- sponse and regulates telomere maintenance by telomerase. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

Minichromosome Maintenance Proteins Are Direct Targets of the ATM and ATR Checkpoint Kinases
Minichromosome maintenance proteins are direct targets of the ATM and ATR checkpoint kinases David Cortez*†, Gloria Glick*, and Stephen J. Elledge‡§ *Department of Biochemistry, Vanderbilt University, Nashville, TN 37232; and ‡Department of Genetics, Center for Genetics and Genomics, and Howard Hughes Medical Institute, Harvard University Medical School, Boston, MA 02115 Contributed by Stephen J. Elledge, May 13, 2004 The minichromosome maintenance (MCM) 2-7 helicase complex unclear how they could be reassembled because replication functions to initiate and elongate replication forks. Cell cycle licensing is not allowed once S phase has begun (26). Continued checkpoint signaling pathways regulate DNA replication to main- MCM activity at a stalled replication fork may also be delete- tain genomic stability. We describe four lines of evidence that rious because it would expose extensive regions of single- ATM/ATR-dependent (ataxia-telangiectasia-mutated͞ATM- and stranded DNA, precisely the phenotype observed in S. cerevisiae Rad3-related) checkpoint pathways are directly linked to three checkpoint mutants treated with hydroxyurea (HU) (9). Fur- members of the MCM complex. First, ATM phosphorylates MCM3 thermore, short stretches of single-stranded DNA that might on S535 in response to ionizing radiation. Second, ATR phosphor- accumulate at stalled forks because of MCM action may be ylates MCM2 on S108 in response to multiple forms of DNA damage essential to recruiting the ATR-ATRIP complex and activating and stalling of replication forks. Third, ATR-interacting protein the S-phase checkpoint. In this study, we found four direct (ATRIP)-ATR interacts with MCM7. Fourth, reducing the amount of connections between the ATR͞ATM checkpoint pathways and MCM7 in cells disrupts checkpoint signaling and causes an intra- the MCM proteins. -

Identification of Conserved Genes Triggering Puberty in European Sea
Blázquez et al. BMC Genomics (2017) 18:441 DOI 10.1186/s12864-017-3823-2 RESEARCHARTICLE Open Access Identification of conserved genes triggering puberty in European sea bass males (Dicentrarchus labrax) by microarray expression profiling Mercedes Blázquez1,2* , Paula Medina1,2,3, Berta Crespo1,4, Ana Gómez1 and Silvia Zanuy1* Abstract Background: Spermatogenesisisacomplexprocesscharacterized by the activation and/or repression of a number of genes in a spatio-temporal manner. Pubertal development in males starts with the onset of the first spermatogenesis and implies the division of primary spermatogonia and their subsequent entry into meiosis. This study is aimed at the characterization of genes involved in the onset of puberty in European sea bass, and constitutes the first transcriptomic approach focused on meiosis in this species. Results: European sea bass testes collected at the onset of puberty (first successful reproduction) were grouped in stage I (resting stage), and stage II (proliferative stage). Transition from stage I to stage II was marked by an increase of 11ketotestosterone (11KT), the main fish androgen, whereas the transcriptomic study resulted in 315 genes differentially expressed between the two stages. The onset of puberty induced 1) an up-regulation of genes involved in cell proliferation, cell cycle and meiosis progression, 2) changes in genes related with reproduction and growth, and 3) a down-regulation of genes included in the retinoic acid (RA) signalling pathway. The analysis of GO-terms and biological pathways showed that cell cycle, cell division, cellular metabolic processes, and reproduction were affected, consistent with the early events that occur during the onset of puberty. -
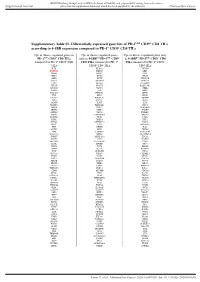
Supplementary Table S5. Differentially Expressed Gene Lists of PD-1High CD39+ CD8 Tils According to 4-1BB Expression Compared to PD-1+ CD39- CD8 Tils
BMJ Publishing Group Limited (BMJ) disclaims all liability and responsibility arising from any reliance Supplemental material placed on this supplemental material which has been supplied by the author(s) J Immunother Cancer Supplementary Table S5. Differentially expressed gene lists of PD-1high CD39+ CD8 TILs according to 4-1BB expression compared to PD-1+ CD39- CD8 TILs Up- or down- regulated genes in Up- or down- regulated genes Up- or down- regulated genes only PD-1high CD39+ CD8 TILs only in 4-1BBneg PD-1high CD39+ in 4-1BBpos PD-1high CD39+ CD8 compared to PD-1+ CD39- CD8 CD8 TILs compared to PD-1+ TILs compared to PD-1+ CD39- TILs CD39- CD8 TILs CD8 TILs IL7R KLRG1 TNFSF4 ENTPD1 DHRS3 LEF1 ITGA5 MKI67 PZP KLF3 RYR2 SIK1B ANK3 LYST PPP1R3B ETV1 ADAM28 H2AC13 CCR7 GFOD1 RASGRP2 ITGAX MAST4 RAD51AP1 MYO1E CLCF1 NEBL S1PR5 VCL MPP7 MS4A6A PHLDB1 GFPT2 TNF RPL3 SPRY4 VCAM1 B4GALT5 TIPARP TNS3 PDCD1 POLQ AKAP5 IL6ST LY9 PLXND1 PLEKHA1 NEU1 DGKH SPRY2 PLEKHG3 IKZF4 MTX3 PARK7 ATP8B4 SYT11 PTGER4 SORL1 RAB11FIP5 BRCA1 MAP4K3 NCR1 CCR4 S1PR1 PDE8A IFIT2 EPHA4 ARHGEF12 PAICS PELI2 LAT2 GPRASP1 TTN RPLP0 IL4I1 AUTS2 RPS3 CDCA3 NHS LONRF2 CDC42EP3 SLCO3A1 RRM2 ADAMTSL4 INPP5F ARHGAP31 ESCO2 ADRB2 CSF1 WDHD1 GOLIM4 CDK5RAP1 CD69 GLUL HJURP SHC4 GNLY TTC9 HELLS DPP4 IL23A PITPNC1 TOX ARHGEF9 EXO1 SLC4A4 CKAP4 CARMIL3 NHSL2 DZIP3 GINS1 FUT8 UBASH3B CDCA5 PDE7B SOGA1 CDC45 NR3C2 TRIB1 KIF14 TRAF5 LIMS1 PPP1R2C TNFRSF9 KLRC2 POLA1 CD80 ATP10D CDCA8 SETD7 IER2 PATL2 CCDC141 CD84 HSPA6 CYB561 MPHOSPH9 CLSPN KLRC1 PTMS SCML4 ZBTB10 CCL3 CA5B PIP5K1B WNT9A CCNH GEM IL18RAP GGH SARDH B3GNT7 C13orf46 SBF2 IKZF3 ZMAT1 TCF7 NECTIN1 H3C7 FOS PAG1 HECA SLC4A10 SLC35G2 PER1 P2RY1 NFKBIA WDR76 PLAUR KDM1A H1-5 TSHZ2 FAM102B HMMR GPR132 CCRL2 PARP8 A2M ST8SIA1 NUF2 IL5RA RBPMS UBE2T USP53 EEF1A1 PLAC8 LGR6 TMEM123 NEK2 SNAP47 PTGIS SH2B3 P2RY8 S100PBP PLEKHA7 CLNK CRIM1 MGAT5 YBX3 TP53INP1 DTL CFH FEZ1 MYB FRMD4B TSPAN5 STIL ITGA2 GOLGA6L10 MYBL2 AHI1 CAND2 GZMB RBPJ PELI1 HSPA1B KCNK5 GOLGA6L9 TICRR TPRG1 UBE2C AURKA Leem G, et al. -

ORC3 (1D6): Sc-23888
SANTA CRUZ BIOTECHNOLOGY, INC. ORC3 (1D6): sc-23888 BACKGROUND STORAGE The initiation of DNA replication is a multi-step process that depends on the Store at 4° C, **DO NOT FREEZE**. Stable for one year from the date of formation of pre-replication complexes, which trigger initiation. Among the shipment. Non-hazardous. No MSDS required. proteins required for establishing these complexes are the origin recognition complex (ORC) proteins. ORC proteins bind specifically to origins of replication DATA where they serve as scaffold for the assembly of additional initiation factors. A B Human ORC subunits 1-6 are expressed in the nucleus of proliferating cells AB C DE and tissues, such as the testis. ORC1 and ORC2 are both expressed at equiv- 113 K – 89 K – alent concentrations throughout the cell cycle; however, only ORC2 remains < ORC3 stably bound to chromatin. ORC4 and ORC6 are also expressed constantly throughout the cell cycle. ORC2, ORC3, ORC4 and ORC5 form a core complex 49 K – upon which ORC6 and ORC1 assemble. The formation of this core complex suggests that ORC proteins play a crucial role in the G1-S transition in mam- malian cells. ORC3 (1D6): sc-23888. Western blot analysis of ORC3 ORC3 (1D6): sc-23888. Immunoperoxidase staining of expression in HeLa (A), Raji (B), Jurkat (C), WI-38 (D) formalin fixed, paraffin-embedded human ovary tissue CHROMOSOMAL LOCATION and A-549 (E) whole cell lysates. showing nuclear localization (A,B). Genetic locus: ORC3L (human) mapping to 6q15. SELECT PRODUCT CITATIONS SOURCE 1. Braden, W.A., et al. 2006. Distinct action of the retinoblastoma pathway ORC3 (1D6) is a rat monoclonal antibody raised against partially purified on the DNA replication machinery defines specific roles for cyclin-depen- His-tagged bacterially expressed fusion protein corresponding to human ORC3. -

Systemic Analysis of the DNA Replication Regulators Origin Recognition Complex in Lung Adenocarcinomas Identifes Prognostic and Expression Signifcance
Systemic Analysis of the DNA Replication Regulators Origin Recognition Complex in Lung Adenocarcinomas Identies Prognostic and Expression Signicance Juan Chen University of South China Juan Zou University of South China Juan Zeng University of South China Tian Zeng University of South China Qi-hao Hu University of South China Jun-hui Bai University of South China Min Tang University of South China Yu-kun Li ( [email protected] ) University of South China https://orcid.org/0000-0002-8517-9075 Primary research Keywords: lung adenocarcinomas, ORC complex, public databases, prognostic value, comprehensive bioinformatics Posted Date: May 11th, 2021 DOI: https://doi.org/10.21203/rs.3.rs-487176/v1 License: This work is licensed under a Creative Commons Attribution 4.0 International License. Read Full License Page 1/24 Abstract Background: Origin recognition complex (ORC) 1, ORC2, ORC3, ORC4, ORC5 and ORC6, form a replication- initiator complex to mediate DNA replication, which play a key role in carcinogenesis, while their role in lung adenocarcinomas (LUAD) remains poorly understood. Methods: We conrmed the transcriptional and post-transcriptional levels, DNA alteration, DNA methylation, miRNA network, protein structure, PPI network, functional enrichment, immune inltration and prognostic value of ORCs in LUAD based on Oncomine, GEPIA, HPA, cBioportal, TCGA, GeneMANIA, Metascape, KM-plot, GENT2, and TIMER database. Results: ORC mRNA and protein were both enhanced obviously based on Oncomine, Ualcan, GEPIA, TCGA and HPA database. Furthermore, ORC1 and ORC6 have signicant prognostic values for LUAD patients based on GEPIA database. Protein structure, PPI network, functional enrichment and immune inltration analysis indicated that ORC complex cooperatively accelerate the LUAD development by promoting DNA replication, cellular senescence and metabolic process. -

The History of Middle-Earth: from a Mythology for England to a Recovery of the Real Earth Christopher Garbowski
Analysis The History of Middle-earth: from a Mythology for England to a Recovery of the Real Earth Christopher Garbowski ne of J.R.R. Tolkien's great Parallels with the pro joined with the fortunes and mis Oambitions was to have The fortunes of the elves, in their Lord of the Rings and The Silmar- cess of myth creation combined struggle with Sauron, illion published together. This in found in the work of for the remainder of the Second fact delayed the publication of the contemporary philoso Age. After their costly self- former, since Allen & Unwin, satisfaction with apparent victory, who had originally instigated the phers the struggle resumes for the full trilogy and were willing to risk extent of the Third Age, wherein the publication of this unusual are set The Hobbit and The Lord book, were not surprisingly un conflagration with Morgoth are o f the Rings. The former was prepared for the additional publi rewarded with an Eden-like is independently conceived, but cation of what seemed to be an land residence set between the turned out to be essential in the altogether obscure work. In an “uttermost West” - Valinor, the history of Middle-earth: undated letter (probably from late residence of the Valar - and As the high Legends o f the begin 1951) to Milton Waldman, a dif Middle-earth, while the elves ning are supposed to look at ferent potential publisher, the au who do not leave Middle-earth things through Elvish minds, so thor presented a vision of his exercise a kind of ‘antiquarian the middle tale o f the Hobbits mythology. -

Treasures of Middle Earth
T M TREASURES OF MIDDLE-EARTH CONTENTS FOREWORD 5.0 CREATORS..............................................................................105 5.1 Eru and the Ainur.............................................................. 105 PART ONE 5.11 The Valar.....................................................................105 1.0 INTRODUCTION........................................................................ 2 5.12 The Maiar....................................................................106 2.0 USING TREASURES OF MIDDLE EARTH............................ 2 5.13 The Istari .....................................................................106 5.2 The Free Peoples ...............................................................107 3.0 GUIDELINES................................................................................ 3 5.21 Dwarves ...................................................................... 107 3.1 Abbreviations........................................................................ 3 5.22 Elves ............................................................................ 109 3.2 Definitions.............................................................................. 3 5.23 Ents .............................................................................. 111 3.3 Converting Statistics ............................................................ 4 5.24 Hobbits........................................................................ 111 3.31 Converting Hits and Bonuses...................................... 4 5.25 -

The Journal of the Tolkien Society
Issue 50 • Autumn 2010 MallornThe Journal of the Tolkien Society Mallorn The Journal of the Tolkien Society Issue 50 • Autumn 2010 Editor: Henry Gee editorial Production & 4 Marcel Bülles looks to the future of Tolkien fandom design: Colin Sullivan letters Cover art: Lorenzo Daniele 7 Alex Lewis & Elizabeth Curie go back to the source Inside pages: Ruth Lacon (p. 2), Jef Murray (pp. 6, 7, reviews 25, 39, 48, 50, 52), Phyllis 8 Lynn Forest-Hill on Elves in Anglo-Saxon England Berka (p. 10), John Gilbey 9 Mike Foster on The Inheritance (pp. 14, 40, 44, 46), Colin 11 Chad Chisholm on Up Williams (p. 20), Teresa 13 Roberto Arduini & Claudio Testi on Tolkien and Philosophy Kirkpatrick (p. 47), Lorenzo Daniele (p. 51) commentary 15 Charles E Noad The Tolkien Society — the early days 26 Maggie Burns ‘… A local habitation and a name …’ Mallorn © The Tolkien 31 Simon Barrow The magic of fantasy: the traditional, the original and the Society. Printed and wonderful distributed by The Printed 34 Chad Chisholm The wizard and the rhetor: rhetoric and the ethos of Word, 7–9 Newhouse Middle-earth in The Hobbit Business Centre, Old 37 Vanessa Phillips-Zur-Linden Arwen and Edward: redemption and the fairy Crawley Road, Horsham bride/groom in the literary fairytale RH12 4RU, UK. interview 42 Mike Foster talks to Simon Tolkien poetry 46 Lynn Forest-Hill The Long Watch 46 Anne Forbes The Path To The Sea 46 Anne Forbes The End Of The Summer 47 Teresa Kirkpatrick Tuor And Ulmo fiction 48 Julia Fenton Blasphemy well, I’m back 50 Paul H Vigor takes a closer look at Thror’s map Mallorn is the Journal of the Tolkien Society, and appears twice a year, in the Spring (copy deadline 25 December) and Autumn (21 June).