3.5 Years of Augmented 4Chan Posts from the Politically Incorrect Board∗
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Changing Face of American White Supremacy Our Mission: to Stop the Defamation of the Jewish People and to Secure Justice and Fair Treatment for All
A report from the Center on Extremism 09 18 New Hate and Old: The Changing Face of American White Supremacy Our Mission: To stop the defamation of the Jewish people and to secure justice and fair treatment for all. ABOUT T H E CENTER ON EXTREMISM The ADL Center on Extremism (COE) is one of the world’s foremost authorities ADL (Anti-Defamation on extremism, terrorism, anti-Semitism and all forms of hate. For decades, League) fights anti-Semitism COE’s staff of seasoned investigators, analysts and researchers have tracked and promotes justice for all. extremist activity and hate in the U.S. and abroad – online and on the ground. The staff, which represent a combined total of substantially more than 100 Join ADL to give a voice to years of experience in this arena, routinely assist law enforcement with those without one and to extremist-related investigations, provide tech companies with critical data protect our civil rights. and expertise, and respond to wide-ranging media requests. Learn more: adl.org As ADL’s research and investigative arm, COE is a clearinghouse of real-time information about extremism and hate of all types. COE staff regularly serve as expert witnesses, provide congressional testimony and speak to national and international conference audiences about the threats posed by extremism and anti-Semitism. You can find the full complement of COE’s research and publications at ADL.org. Cover: White supremacists exchange insults with counter-protesters as they attempt to guard the entrance to Emancipation Park during the ‘Unite the Right’ rally August 12, 2017 in Charlottesville, Virginia. -
![Arxiv:2001.07600V5 [Cs.CY] 8 Apr 2021 Leged Crisis (Lilly 2016)](https://docslib.b-cdn.net/cover/6394/arxiv-2001-07600v5-cs-cy-8-apr-2021-leged-crisis-lilly-2016-86394.webp)
Arxiv:2001.07600V5 [Cs.CY] 8 Apr 2021 Leged Crisis (Lilly 2016)
The Evolution of the Manosphere Across the Web* Manoel Horta Ribeiro,♠;∗ Jeremy Blackburn,4 Barry Bradlyn,} Emiliano De Cristofaro,r Gianluca Stringhini,| Summer Long,} Stephanie Greenberg,} Savvas Zannettou~;∗ EPFL, Binghamton University, University of Illinois at Urbana-Champaign University♠ College4 London, Boston} University, Max Planck Institute for Informatics r Corresponding authors: manoel.hortaribeiro@epfl.ch,| ~ [email protected] ∗ Abstract However, Manosphere communities are scattered through the Web in a loosely connected network of subreddits, blogs, We present a large-scale characterization of the Manosphere, YouTube channels, and forums (Lewis 2019). Consequently, a conglomerate of Web-based misogynist movements focused we still lack a comprehensive understanding of the underly- on “men’s issues,” which has prospered online. Analyzing 28.8M posts from 6 forums and 51 subreddits, we paint a ing digital ecosystem, of the evolution of the different com- comprehensive picture of its evolution across the Web, show- munities, and of the interactions among them. ing the links between its different communities over the years. Present Work. In this paper, we present a multi-platform We find that milder and older communities, such as Pick longitudinal study of the Manosphere on the Web, aiming to Up Artists and Men’s Rights Activists, are giving way to address three main research questions: more extreme ones like Incels and Men Going Their Own Way, with a substantial migration of active users. Moreover, RQ1: How has the popularity/levels of activity of the dif- our analysis suggests that these newer communities are more ferent Manosphere communities evolved over time? toxic and misogynistic than the older ones. -

POPULAR SOCIAL MEDIA SITES Below Is a List of Some of the Most Commonly Used Youth and Teen Social Networking Sites and Tools
POPULAR SOCIAL MEDIA SITES Below is a list of some of the most commonly used youth and teen social networking sites and tools. Ask.fm (http://ask.fm) Participants log on, post a question anonymously and anyone may answer anonymously. “Do you think I am fat?” or “Would you date me?” are examples of questions posted in the past. There have also been examples in which individuals were encouraged to kill themselves. The site has courted controversy by not having workable reporting, tracking or parental control processes, which have become the norm on other social media websites. Twitter (https://twitter.com) An online social networking and microblogging service that enables users to send and read "tweets", which are text messages limited to 140 characters. Instagram (http://instagram.com) A photo-sharing app for iPhone. Kik (http://kik.com) Kik is as an alternative to email or text messaging and its popularity has grown in the last two years. Kik is accessible on smartphones and supports over 4 million users, called “Kicksters.” Users are not restricted to sending text messages with Kik. Images, videos, sketches, emoticions and more may be sent. A user can block users on Kik from contacting them. Wanelo (http://wanelo.com) Wanelo (from Want, Need, Love) sells unique products online, all posted by users. Products posted for sale range from dishes, clothing, intimate wear and other potentially “R-Rated” products. Vine (https://vine.co) Vine is used to create and share free and instant six-second videos. Topic and content ranges. Snapchat (http://www.snapchat.com) A photo messaging application. -

On the Emergence of Sinophobic Behavior on Web Communities In
“Go eat a bat, Chang!”: On the Emergence of Sinophobic Behavior on Web Communities in the Face of COVID-19 Fatemeh Tahmasbi Leonard Schild Chen Ling Binghamton University CISPA Boston University [email protected] [email protected] [email protected] Jeremy Blackburn Gianluca Stringhini Yang Zhang Binghamton University Boston University CISPA [email protected] [email protected] [email protected] Savvas Zannettou Max Planck Institute for Informatics [email protected] ABSTRACT KEYWORDS The outbreak of the COVID-19 pandemic has changed our lives in COVID-19, Sinophobia, Hate Speech, Twitter, 4chan unprecedented ways. In the face of the projected catastrophic conse- ACM Reference Format: quences, most countries have enacted social distancing measures in Fatemeh Tahmasbi, Leonard Schild, Chen Ling, Jeremy Blackburn, Gianluca an attempt to limit the spread of the virus. Under these conditions, Stringhini, Yang Zhang, and Savvas Zannettou. 2021. “Go eat a bat, Chang!”: the Web has become an indispensable medium for information ac- On the Emergence of Sinophobic Behavior on Web Communities in the quisition, communication, and entertainment. At the same time, Face of COVID-19. In Proceedings of the Web Conference 2021 (WWW ’21), unfortunately, the Web is being exploited for the dissemination April 19–23, 2021, Ljubljana, Slovenia. ACM, New York, NY, USA, 12 pages. of potentially harmful and disturbing content, such as the spread https://doi.org/10.1145/3442381.3450024 of conspiracy theories and hateful speech towards specific ethnic groups, in particular towards Chinese people and people of Asian 1 INTRODUCTION descent since COVID-19 is believed to have originated from China. -

"If You're Ugly, the Blackpill Is Born with You": Sexual Hierarchies, Identity Construction, and Masculinity on an Incel Forum Board
University of Dayton eCommons Joyce Durham Essay Contest in Women's and Gender Studies Women's and Gender Studies Program 2020 "If You're Ugly, the Blackpill is Born with You": Sexual Hierarchies, Identity Construction, and Masculinity on an Incel Forum Board Josh Segalewicz University of Dayton Follow this and additional works at: https://ecommons.udayton.edu/wgs_essay Part of the Other Feminist, Gender, and Sexuality Studies Commons, and the Women's Studies Commons eCommons Citation Segalewicz, Josh, ""If You're Ugly, the Blackpill is Born with You": Sexual Hierarchies, Identity Construction, and Masculinity on an Incel Forum Board" (2020). Joyce Durham Essay Contest in Women's and Gender Studies. 20. https://ecommons.udayton.edu/wgs_essay/20 This Essay is brought to you for free and open access by the Women's and Gender Studies Program at eCommons. It has been accepted for inclusion in Joyce Durham Essay Contest in Women's and Gender Studies by an authorized administrator of eCommons. For more information, please contact [email protected], [email protected]. "If You're Ugly, the Blackpill is Born with You": Sexual Hierarchies, Identity Construction, and Masculinity on an Incel Forum Board by Josh Segalewicz Honorable Mention 2020 Joyce Durham Essay Contest in Women's and Gender Studies "If You're Ugly, The Blackpill is Born With You": Sexual Hierarchies, Identity Construction, and Masculinity on an Incel Forum Board Abstract: The manosphere is one new digital space where antifeminists and men's rights activists interact outside of their traditional social networks. Incels, short for involuntary celibates, exist in this space and have been labeled as extreme misogynists, white supremacists, and domestic terrorists. -

Alone Together: Exploring Community on an Incel Forum
Alone Together: Exploring Community on an Incel Forum by Vanja Zdjelar B.A. (Hons., Criminology), Simon Fraser University, 2016 B.A. (Political Science and Communication), Simon Fraser University, 2016 Thesis Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Arts in the School of Criminology Faculty of Arts and Social Sciences © Vanja Zdjelar 2020 SIMON FRASER UNIVERSITY FALL 2020 Copyright in this work rests with the author. Please ensure that any reproduction or re-use is done in accordance with the relevant national copyright legislation. Declaration of Committee Name: Vanja Zdjelar Degree: Master of Arts Thesis title: Alone Together: Exploring Community on an Incel Forum Committee: Chair: Bryan Kinney Associate Professor, Criminology Garth Davies Supervisor Associate Professor, Criminology Sheri Fabian Committee Member University Lecturer, Criminology David Hofmann Examiner Associate Professor, Sociology University of New Brunswick ii Abstract Incels, or involuntary celibates, are men who are angry and frustrated at their inability to find sexual or intimate partners. This anger has repeatedly resulted in violence against women. Because incels are a relatively new phenomenon, there are many gaps in our knowledge, including how, and to what extent, incel forums function as online communities. The current study begins to fill this lacuna by qualitatively analyzing the incels.co forum to understand how community is created through online discourse. Both inductive and deductive thematic analyses were conducted on 17 threads (3400 posts). The results confirm that the incels.co forum functions as a community. Four themes in relation to community were found: The incel brotherhood; We can disagree, but you’re wrong; We are all coping here; and Will the real incel come forward. -

Doxxing, Swatting and the New Trends in Online Harassment 22 April 2015, by Andrew Quodling
Doxxing, swatting and the new trends in online harassment 22 April 2015, by Andrew Quodling citizens about "swatting" (see below) since 2008. It has become common to see articles about how these attacks have affected politicians (both Republican and Democrat in the US), celebrities, journalists, businesses, video game streamers and public servants. What is doxxing? Doxxing – named for "documents" or "docs" – is the act of release of someone's personal and/or When the SWAT team bursts into your bedroom, it’s not identifiable information without their consent. This only unpleasant but potentially deadly. Credit: Jason can include things like their full legal name, social Eppink/Flickr, CC BY security numbers, home or work addresses and contact information. There's no set format for a "dox"; the doxxer simply Imagine this: there's a knock at your door. "Pizza publishes whatever information they've managed to delivery!" It's the fifth time in the last hour that turn up in their searches. Sometimes this even you've had to say to a delivery-person: "No, I really includes the names and details of their target's didn't order anything." That's irritating. family or close friends. Half an hour later, there's another noise at the As a tactic of harassment, doxxing serves two door. This time it's forced open as your house is purposes: it intimidates the people targeted by stormed by the heavily armed and aggressive invading and disrupting their expectations of special response unit of your local police force. privacy; and it provides an avenue for the They're responding to a tip off that warned them of perpetuation of that person's harassment by a hostage situation at your address. -

What Role Has Social Media Played in Violence Perpetrated by Incels?
Chapman University Chapman University Digital Commons Peace Studies Student Papers and Posters Peace Studies 5-15-2019 What Role Has Social Media Played in Violence Perpetrated by Incels? Olivia Young Chapman University, [email protected] Follow this and additional works at: https://digitalcommons.chapman.edu/peace_studies_student_work Part of the Gender and Sexuality Commons, Peace and Conflict Studies Commons, Social Control, Law, Crime, and Deviance Commons, Social Influence and oliticalP Communication Commons, Social Media Commons, Social Psychology and Interaction Commons, and the Sociology of Culture Commons Recommended Citation Young, Olivia, "What Role Has Social Media Played in Violence Perpetrated by Incels?" (2019). Peace Studies Student Papers and Posters. 1. https://digitalcommons.chapman.edu/peace_studies_student_work/1 This Senior Thesis is brought to you for free and open access by the Peace Studies at Chapman University Digital Commons. It has been accepted for inclusion in Peace Studies Student Papers and Posters by an authorized administrator of Chapman University Digital Commons. For more information, please contact [email protected]. Peace Studies Capstone Thesis What role has social media played in violence perpetrated by Incels? Olivia Young May 15, 2019 Young, 1 INTRODUCTION This paper aims to answer the question, what role has social media played in violence perpetrated by Incels? Incels, or involuntary celibates, are members of a misogynistic online subculture that define themselves as unable to find sexual partners. Incels feel hatred for women and sexually active males stemming from their belief that women are required to give sex to them, and that they have been denied this right by women who choose alpha males over them. -

The Christchurch Attack Report: Key Takeaways on Tarrant’S Radicalization and Attack Planning
The Christchurch Attack Report: Key Takeaways on Tarrant’s Radicalization and Attack Planning Yannick Veilleux-Lepage, Chelsea Daymon and Amarnath Amarasingam i The Christchurch Attack Report: Key Takeaways on Tarrant’s Radicalization and Attack Planning Yannick Veilleux-Lepage, Chelsea Daymon and Amarnath Amarasingam ICCT Perspective December 2020 ii About ICCT The International Centre for Counter-Terrorism – The Hague (ICCT) is an independent think and do tank providing multidisciplinary policy advice and practical, solution- oriented implementation support on prevention and the rule of law, two vital pillars of effective counterterrorism. ICCT’s work focuses on themes at the intersection of countering violent extremism and criminal justice sector responses, as well as human rights-related aspects of counterterrorism. The major project areas concern countering violent extremism, rule of law, foreign fighters, country and regional analysis, rehabilitation, civil society engagement and victims’ voices. Functioning as a nucleus within the international counter-terrorism network, ICCT connects experts, policymakers, civil society actors and practitioners from different fields by providing a platform for productive collaboration, practical analysis, and exchange of experiences and expertise, with the ultimate aim of identifying innovative and comprehensive approaches to preventing and countering terrorism. Licensing and Distribution ICCT publications are published in open access format and distributed under the terms of the Creative Commons -

Covid-19 Disinformation Briefing No. 2 Far-Right Mobilisation
COVID-19 DISINFORMATION BRIEFING NO. 2 FAR-RIGHT MOBILISATION 9th April 2020 This is the second in a series of briefings from ISD’s Digital Research Unit on the information ecosystem around coronavirus (COVID-19). These briefings expose how technology platforms are being used to promote disinformation, hate, extremism and authoritarianism in the context of COVID-19. It is based on ISD’s mixture of natural language processing, network analysis and ethnographic online research. This briefing focuses on the way far-right groups and individuals are mobilising around COVID-19 in the US. The first briefing in the series can be found on ISD’s website. Top Lines Far-right groups and individuals are opportunistically using the ongoing pandemic to advance their movements and ideologies: - COVID-19 is an increasingly important topic within far-right communities. Mentions of ‘corona-chan’, a slang term for COVID-19 popular with far-right groups and individuals have increased significantly across mainstream and fringe social media platforms. - COVID-19 is being used as a ‘wedge issue’ to promote conspiracy theories, target minority communities, and call for extreme violence. COVID-19 is being used to advance calls for the ‘boogaloo’ – an extreme right-wing meme referring to an impending civil war: - While some of these calls appear to be ironic, others should be recognised as legitimate security threats. - Discussions of the ‘boogaloo’ are increasingly pivoting towards the ways the COVID- 19 pandemic provides an opportunity for violence. - This conversation is taking place across mainstream and fringe social media. - This trend has already manifested into real-world violence, with one alleged white supremacist terrorist dying after shootouts with the FBI. -

Digital Social Media and Aggression: Memetic Rhetoric in 4Chanᅢ까タᅡルs Collective Identity
Available online at www.sciencedirect.com ScienceDirect Computers and Composition 45 (2017) 85–97 Digital Social Media and Aggression: Memetic Rhetoric in 4chan’s Collective Identity Erika M. Sparby Department of English, Illinois State University, 100 North Normal Street, Adlai E. Stevenson Building, Room 409, Normal, IL 61790, USA Abstract This article examines online aggression in digital social media. Using threads from 4chan’s /b/ board (an anonymous imageboard known for trolling and other aggressive behaviors) as a case study, the author illustrates how some aggressive behaviors online are memetic; that is, they are uncritical recapitulations of previous behaviors or of the way users believe they are “supposed” to behave. First, the author examines /b/’s technical design, ethos, and collective identity to understand the nature of the offensive content posted to the board. Then, she analyzes two threads wherein transwomen (the most vehemently denigrated identity on /b/) self-identified and how the collective identity employed its memetic responses; the first transwoman incited /b/’s memetic wrath, while the second employed identity rhetoric that ruptured the collective identity, thus effectively deterring /b/’s memetic behaviors and opening constructive dialog. This case study emphasizes the pressing need for more teacher-scholars to perform research and develop pedagogy centered on anonymous and pseudonymous social media spaces. It is imperative to disrupt negative memetic behaviors so that we can find, create, and seize more opportunities -
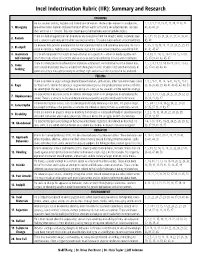
Incel Indoctrination Rubric (IIR): Summary and Research
Incel Indoctrination Rubric (IIR): Summary and Research THINKING He has an over-arching, negative and limited view of women. He describes women in an objective, 1, 2, 3, 5, 7-14, 18-25, 27, 29, 31-33, 35- 1. Misogyny one-dimensional manner and sees the heart of their worth as that of a sexual possession. He rates 43, 45-48, 50 their worth on a 1-10 scale. This item encompasses homophobic and transphobic beliefs. There is a lack of appreciation for diversity or any divergence from the straight, white, cisgender ideal 6, 7, 11, 18, 20, 21, 24, 27, 29, 37, 38, 41, 2. Racism and a sense of superiority of the white race over all others. This would also include antisemitic beliefs. 45, 49 He believes that genetics predetermine his status and desirability and cannot be overcome. He has a 1, 3-5, 9, 10, 13, 18, 19, 21, 24, 25, 29, 39, 3. Blackpill sense of inferiority, hopelessness, and growing rage at the lack of sexual prospects available to him. 41, 43, 45-47 4. Inaccurate This bi-bifurcated construct exists on two extremes on a spectrum – either an overly negative self- 2, 4, 10, 11, 14, 15, 18-22, 24, 25, 27-33, Self-Concept worth that leads to low self-esteem and value or an overly inflated sense of value and entitlement. 35, 37-39, 41, 43, 45, 47 There is a strong desire to achieve fame and make a statement. He thinks that he is the chosen one, 2, 5, 7, 8, 11, 13, 14, 18-21, 23-25, 27-33, 5.